Kaggle Deepfake检测挑战赛 Top2% 解决方案
点击上方“CVer”,选择加"星标"或“置顶”
重磅干货,第一时间送达

今天这篇文章算是对自己参加过的比赛进行一个复盘,包括整理自己在这个比赛中的收获以及介绍我们的解决方案,同时也可以让没时间参加但是感兴趣的朋友对比赛有个更加详细感性的了解。本文中的观点、数据均是结合了Kaggle上该比赛中的开源notebook或者讨论区以及我们团队内部的讨论、实践得出,欢迎大家拍砖交流。
在进入正题之前,还是先来大致介绍一下这个比赛背景吧。

近年来越来越多的AI换脸算法极其应用大范围地在互联网上传播,导致数字信息公信力下降,给未来更加数据驱动的互联网、物联网产业进一步发展蒙上了阴影。为了解决这个问题,Amazon, Facebook, MicroSoft, PAI等一众一线互联网公司以及研究机构一同发起,在Kaggle平台上举办了DeepFake Detection Chanllenge(DFDC)假脸识别挑战赛,更是豪掷重金100万美元奖励比赛的前五名。DFDC挑战赛主办方的豪华配置也吸引到全球近2300支对AI技术(jin qian)痴迷的团队参加。
https://www.kaggle.com/c/deepfake-detection-challenge/overview
比赛的基本情况介绍完毕,来看看数据长啥样。
DFDC数据集包括了119,197个视频,每个视频时长都为10秒,但是帧率从15~30fps不等,分辨率也从320x240~3840x2160不等。训练视频中有19,197个视频是由大约430名演员真实拍摄的片段,剩余100,000个视频是由真实视频生成的假脸视频。假脸生成使用了DeepFakes, Face2Face等多种主流假脸生成算法,使得数据集包含尽可能多的假脸视频。
1. 正负样本比例大约为1:5, 需要解决样本不均衡问题。
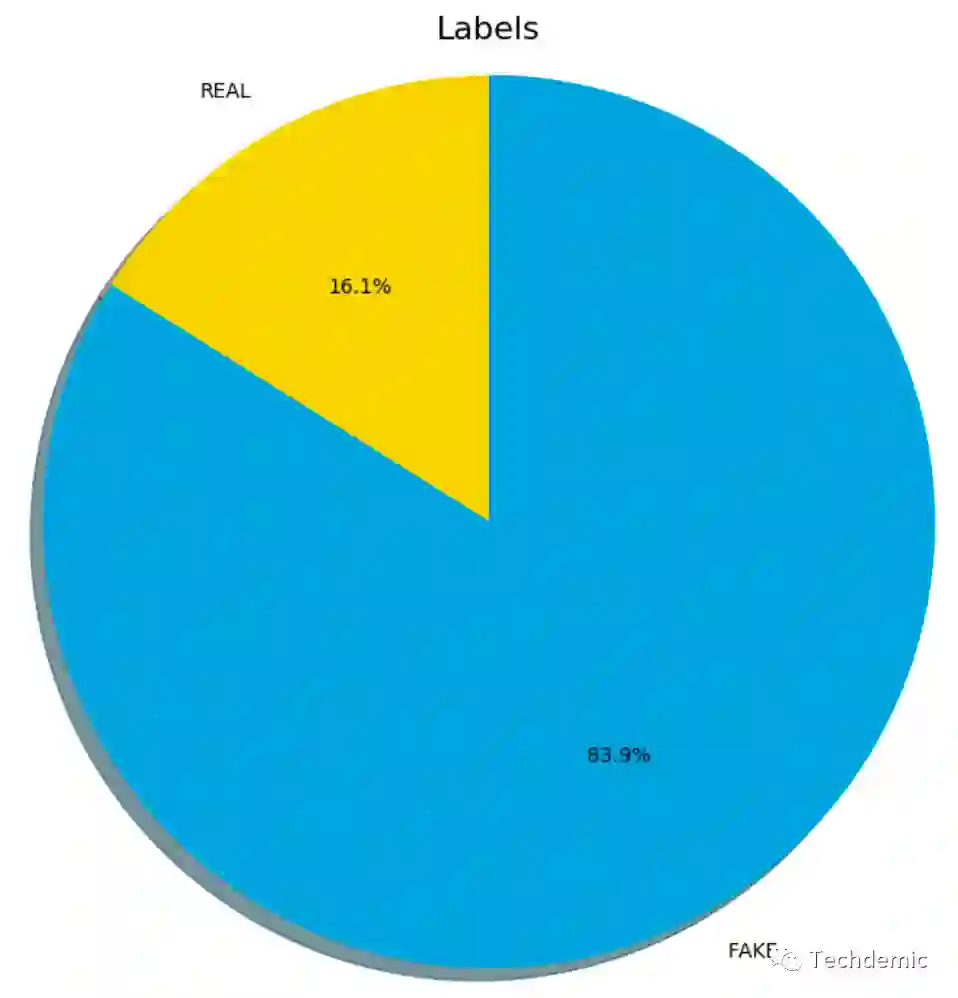
2. 平均每个真视频生成5个假视频,但有的真视频只生成了1个假视频,而有的生成30+个假视频,具体分布如下:
3. 5%~10%的视频会出现2个人,绝大部分视频中只有1个人。

4. 有的假脸非常明显。

5. 有的假脸肉眼也很难分辨,不妨猜猜下面的视频中哪些是假脸,哪些是真脸。



6. 演员的男女,种族,年龄都在合理的分布范围内。

数据集的基本情况就是如此了,挑战的目标就是识别这些视频里的人脸是真人脸还是AI生成的假人脸。
由于主流的视频分类方案都是将视频逐帧分解成图片,然后从图片中提取特征进行后续的分类器建模。所以数据处理的第一步,自然是视频帧的抽取。这一部分与模型无关,我们只需要确定好,视频帧抽取的频率以及确保能够稳定快速地对视频进行处理。对于python来说,有很多packages可以实现抽针的功能,例如opencv-python, FFmpeg, Decord, DALI 以及 moviepy等等。
视频帧提取
不用多说,最经典,使用最广泛的图像处理package之一,可以完成各种图像处理的同时,也提供了稳定的视频读取的功能。
优点
稳定。
python下操作,调用非常方便。
缺点
运行在CPU上,速度偏慢。
经典的视频处理开源软件包,在视频领域跟opencv在图像领域的地位相当。基于C++编写,提供了完整的视频读取、处理的功能。Opencv 视频IO后端其实用的是FFmpeg,因此如果仅仅是视频帧抽取任务,二者在稳定性和速度上相差无几。FFmpeg更加适合视频层面的处理和编辑任务。
优点
稳定。
缺点
底层是C++, python接口实质上是调用shell命令的方式,因此在错误收集,返回值灵活性上来说,不是很方便。
运行在CPU上,速度偏慢。
dmlc出品的Decord是一个专门为深度学习提供视频读取,抽帧等功能的package。底层基于C++和CUDA,接口为python,可以同时在CPU和GPU上运行。
优点
优秀的python接口
可以运行在GPU上,速度是所有视频加载抽帧package中最快的。
缺点
稳定性相比FFmpeg,opencv略差一点,目前正在活跃更新中,未来可期。
DALI全称NVIDIA Data Loading Library,是英伟达专门为各种(图像、视频、音频等)高性能数据预处理提供的package。在视频这块,依然用到了部分FFmpeg的后端(足见FFmpeg在视频处理领域的统治地位了)。英伟达出品当然也是提供了GPU版本。
优点
优秀的python接口及文档
可以运行在GPU上,速度仅次于Decord。
缺点
稳定性相比FFmpeg,opencv略差一点,目前正在活跃更新中,未来可期。
是一个基于python的视频编辑package,速度比较慢,但是可以很方便地将视频做成GIF,本文中展示的GIF都是利用这个package制作的。
人脸检测
在之前发表的一些工作中证明了加入人脸检测后,会大幅提高假脸检测的准确率。因此在预处理中还需要加入人脸检测。人脸检测是一个已经相对成熟的cv任务了,有很多表现很好的开源模型,可以直接拿来使用。但是需要注意的是,观察数据集后发现,数据集中的人脸普遍比较明显,且人脸占视频较大的区域,所以对于人脸检测的模型,我们应该更偏重考察Precision而非Recall,一个高precision的人脸检测模型可以让后续的训练数据噪音降低很多。
MTCNN是非常经典的开源人脸检测框架,模型采用了多级联结构,可以实现精准的人脸检测和5个特征点的标定。精准度是完全足以应对DFDC数据集。不过由于模型的多级联结构导致模型推理速度比较慢,在单GPU且没有任何加速的情况下只有~20fps的推理速度(一些超参设置不同,速度也会不同)。比赛中对模型的推理速度是有限制的,所以要尽可能使用更快的人脸检测,哪怕以牺牲一部分精度为代价。
BlazeFace 是Google Research 2019年提出的轻量级移动端人脸检测框架。Google并没有开源这部分代码,不过放出了部分pre-trained的model。kaggle讨论区有人用了一个非官方实现测试了该框架的效果,速度确实飞快(~100fps),但是精度也确实不是很高。原因是BlazeFace有前置摄像头和后置摄像头2个版本,而Google只提供了前置摄像头版本的pre-trained的model,训练数据分布和DFDC中的数据分布相差比较大,所以精度下降很多。
这个是基于Wider Face数据集训练的基于MobileNet和SSD的人脸检测模型,推理速度相对于MTCNN快了很多,但是在DFDC数据集上的精度几乎与MTCNN差不多,precision表现甚至还略好。因此我看到很多队伍包括我们,最后也选择了MobleNet SSD Face Detection作为人脸检测模型。这次也是让我体会到了数据科学需要深入到实践中,精确分析不同任务的需求,为需求量身定做合理的方案,而不仅仅是依赖论文中声称的指标。具体问题具体分析,用实践来确定方案带给我们的增益远比简单套用方法大得多。
最后来对比一下,不同模型在DFDC数据集上的表现,图片来源:
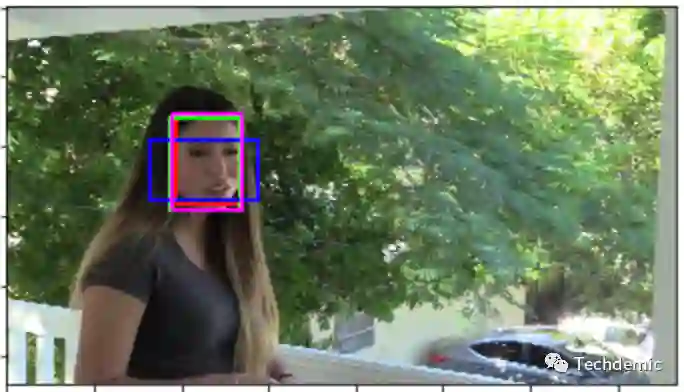



其中,蓝色的box是BlazeFace的检测结果,可以看到检测框的位置不是很准确,而且在环境比较暗的场景中,会直接出现漏检。在可视化地查看了一些例子后,我们认为MTCNN和MobilenetSSD的精度可以满足我们的需求,而在对所有训练数据进行处理后,发现MTCNN的漏检率约为2%,而MobilenetSSD的漏检率为0.2%。而且MobilenetSSD的推理速度是MTCNN的5倍之多。
到此为止,关于图像层面的预处理就全部做完了,也有队伍做了音频,但是因为我们没有对音频做任何处理,加之开源音频处理方案的队伍很少,所以本文就不涉及音频方面的预处理了。之后的事情,统统交给模型吧。
以下是一些经过我们讨论以及在kaggle讨论区中看到的一些可行的方案。
2D-CNN + average
2D-CNN + DNN
2D-CNN + 3D-Conv/1D-Conv
2D-CNN + Sequential Network(LSTM/GRU)
CRNN
3D-CNN
其中的大部分我们都做了尝试,效果有好有坏,多数的结论也与其他队伍的开源方案中所提到的差不多。虽然这个任务上各种方案的效果可能会受到不同预处理方法的影响,但是大家出乎意料地一致发现3D-conv在这个任务上几乎没有帮助。我们认为原因是这个任务在视频层面的特征没有静态图片层面的特征明显,大部分场景,人脸的变动不是很大,仅仅是讲话,或者摇头。而之前3D-conv经常被用来做视频动作识别,动作识别数据集中,视频层面的特征比静态图片更加重要,与此同时3D-conv在对静态图片的特征提取能力不如2D-conv,其长处主要在于能够捕捉帧与帧之间的特征。因此3D-conv在动作识别任务中有所建树,但是在DFDC这种动作幅度较小的数据集上难有表现。
在我们的实验中,2D-CNN + Sequential Network(LSTM/GRU)给出了最好的表现。因此我们采用了如下所示的解决方案作为单模型方案。
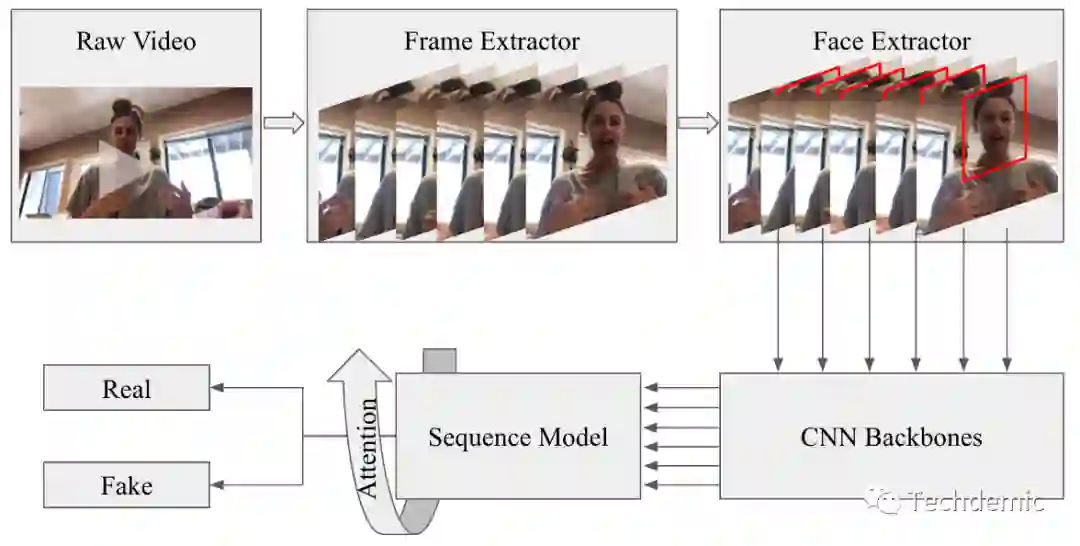
每个视频中抽取20帧,每帧选出1个得分最高的人脸区域,并且适当放大人脸区域,输入Backbone+attention LSTM end to end训练。
Backbone网络我们测试了ResNet, ResNext, Xception 以及 EfficientNet,实验数据表明EfficientNet表现最好,其次是Xception。
一些有用的Trick:
Augmentation with JPEG compression,blur会有2%左右的提升。
Attention机制会有2%左右的提升。
视频帧从10到20,会有一定提升。
人脸区域在一定范围内越大,模型表现越好。
正负样本一定要平衡,即使只使用19197个真视频以及随机挑选的19197个假视频的训练效果也远远好于使用不平衡的全量样本(那样会导致严重的过拟合)。
合理的融合模型。
这是我第一次参加kaggle的比赛,也是第一次真正参与到视频相关的任务中来。所以这一个月以来收获非常大,整理了主流的视频处理packages,学到了很多视频处理和视频分类任务的实用方案。特别感谢我的大佬队友XY和KK,一起合作彼此学习,非常愉快地完成了这个比赛。也感谢kaggle讨论区的大佬们无私的分享,从中受益匪浅,也让我掌握了一个新的学习渠道。最后,欢迎大家一起讨论,欢迎拍砖!
[1] Rossler, Andreas, et al. "Faceforensics++: Learning to detect manipulated facial images." Proceedings of the IEEE International Conference on Computer Vision. 2019.
[2] Wang, Sheng-Yu, et al. "CNN-generated images are surprisingly easy to spot... for now." arXiv preprint arXiv:1912.11035 (2019).
[3] DeepFake Challenge EDA
[4] Basic EDA Face Detection, split video and ROI
[5] Looking at the full train set metadata
[6] EDA - Faces statistics
[7] mobilenet face extractor (comparison) VideoReaders Benchmark
重磅!CVer-人脸相关 微信交流群已成立
扫码添加CVer助手,可申请加入CVer-人脸相关 微信交流群,目前已满800人,具体涵盖人脸检测、识别、关键点检测、表情识别、活体检测等人脸方向。
同时也可申请加入CVer大群和细分方向技术群,细分方向已涵盖:目标检测、图像分割、目标跟踪、人脸检测&识别、OCR、姿态估计、超分辨率、SLAM、医疗影像、Re-ID、GAN、NAS、深度估计、自动驾驶、强化学习、车道线检测、模型剪枝&压缩、去噪、去雾、去雨、风格迁移、遥感图像、行为识别、视频理解、图像融合、图像检索、论文投稿&交流等群。
一定要备注:研究方向+地点+学校/公司+昵称(如人脸检测+上海+上交+卡卡),根据格式备注,可更快被通过且邀请进群

▲长按加群

▲长按关注我们
麻烦给我一个在看!




