干货|用机器学习检测异常点击流

来源:腾讯云 作者:李军
本文内容是我学习ML时做的一个练手项目,描述应用机器学习的一般步骤。该项目的目标是从点击流数据中找出恶意用户的请求。点击流数据长下图这样子,包括请求时间、IP、平台等特征:

该项目从开始做到阶段性完成,大致可分为两个阶段:算法选择和工程优化。算法选择阶段挑选合适的ML模型,尝试了神经网络、高斯分布、Isolation Forest等三个模型。由于点击流数据本身的特性,导致神经网络和高斯分布并不适用于该场景,最终选择了Isolation Forest。工程优化阶段,最初使用单机训练模型和预测结果,但随着数据量的增加,最初的单机系统出现了性能瓶颈;然后开始优化性能,尝试了分布化训练,最终通过单机异步化达到了性能要求。
1 算法选择
1.1 神经网络
刚开始没经验,受TensorFlow热潮影响,先尝试了神经网络。选用的神经网络是MLP(Multilayer Perceptron,多层感知器),一种全连接的多层网络。MLP是有监督学习,需要带标签的样本,这里“带标签”的意思是样本数据标注了哪些用户请求是恶意的、哪些是正常的。但后台并没有现成带标签的恶意用户样本数据。后来通过安全侧的一些数据“间接”给用户请求打上了标签,然后选择IP、平台、版本号、操作码等数据作为MLP的输入数据。结果当然是失败,想了下原因有两个:
1, 样本的标签质量非常差,用这些样本训练出来的模型性能当然也很差;
2, 输入的特征不足以刻画恶意用户。
数据的质量问题目前很难解决,所以只能弃用MLP。
1.2 高斯分布
然后尝试其他模型。通过搜索发现,有一类ML模型专门用于异常检测,找到了Andrew Ng介绍的基于高斯分布的异常检测算法:https://www.coursera.org/learn/machine-learning/home/week/9 。高斯分布如下图所示:
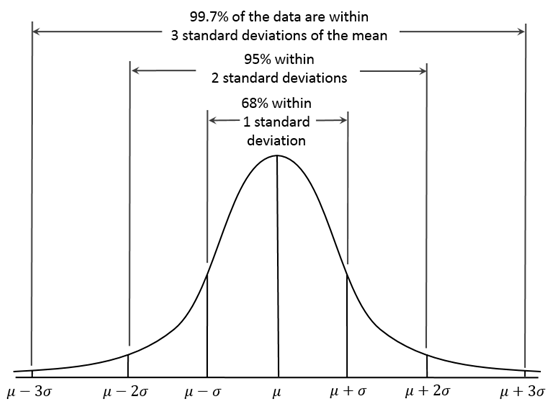
这个算法的思想比较简单:与大部分样本不一致的样本就是异常;通过概率密度量化“不一致”。具体做法是:选择符合高斯分布或能转换为高斯分布的特征,利用收集到的数据对高斯分布做参数估计,把概率密度函数值小于某个阈值的点判定为异常。
所谓的参数估计是指,给定分布数据,求分布的参数。对高斯分布来说,就是求μ和σ。用极大似然估计可以得到高斯分布参数的解析解:
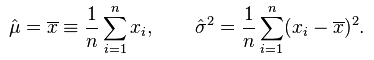
得到高斯分布参数后,用下式计算概率密度:
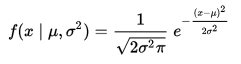
X表示一个特征输入。若有多个特征x0、x1、…、xn,一种简单的处理方法是将其结果连乘起来即可:f(x) = f(x0)f(x1)…f(xn)。
然后选定一个阈值ε,把f(x) < ε的样本判定为异常。ε值需根据实际情况动态调整,默认可设定ε = f(μ- 3σ)。
把这个模型初步应用于点击流异常检测时,效果还不错,但在进一步实施过程中碰到一个棘手问题:样本中最重要的一个特征是操作码,当前操作码在微信后台的取值范围是[101, 1000],每个操作码的请求次数是模型的基础输入,对900个特征计算概率密度再相乘,非常容易导致结果下溢出,以致无法计算出精度合适的概率密度值。这个现象被称为维度灾难(Dimension Disaster)。
解决维度灾难的一个常见做法是降维,降维的手段有多种,这里不展开讨论了。在点击流分析的实践中,降维的效果并不好,主要原因有两个:
1, 正常用户和恶意用户的访问模式并不固定,导致很难分解出有效的特征矩阵或特征向量;
2, 降维的本质是有损压缩,有损压缩必定导致信息丢失。但在本例中每一维的信息都是关键信息,有损压缩会极大破坏样本的有效性。
高斯分布模型的维度灾难在本例中较难解决,只能再尝试其他模型了。
1.3 Isolation Forest
Isolation Forest,可翻译为孤异森林,该算法的基本思想是:随机选择样本的一个特征,再随机选择该特征取值范围中的一个值,对样本集做拆分,迭代该过程,生成一颗Isolation Tree;树上叶子节点离根节点越近,其异常值越高。迭代生成多颗Isolation Tree,生成Isolation Forest,预测时,融合多颗树的结果形成最终预测结果。Isolation Forest的基础结构有点类似经典的随机森林(Random Forest)。算法的细节见这里:http://cs.nju.edu.cn/zhouzh/zhouzh.files/publication/icdm08b.pdf。
这个异常检测模型有效利用了异常样本“量少”和“与正常样本表现不一样”的两个特点,不依赖概率密度因此不会导致高维输入的下溢出问题。提取少量点击流样本测试,它在900维输入的情况下也表现良好,最终选择它作为系统的模型。
2 工程优化
工程实现经历了单机训练、分布式训练、单机异步化训练3个方案,下面内容介绍实现过程中碰到的问题和解决方法。
2.1 单机训练
整个系统主要包括收集数据、训练模型、预测异常、上报结果四个部分。
2.1.1 收集数据
刚开始尝试该模型时,是通过手工方式从mmstreamstorage获取样本的:
1,通过logid 11357,得到手工登录成功用户的uin和登录时间;
2,利用mmstreamstorage提供的接口,得到用户登录后10分钟的点击流;
但这样做有两个缺点:
1,上述步骤1是离线手工操作的,需要做成自动化;
2,mmstreamstorage的接口性能较差,只能提供2万/min的查询性能,上海IDC登录的峰值有9万/min。
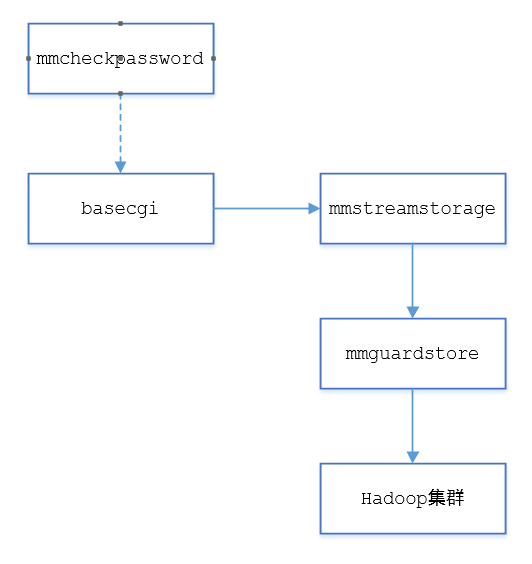
改进办法是复用点击流上报模块mmstreamstorage,增加一个旁路数据的逻辑:
1,手工登录时在presence中记录手工登录时间,mmstreamstorage基于该时间旁路一份数据给mmguardstore。由于mmstreamstorage每次只能提供单挑点击流数据,所以需要在mmguardstore中缓存;
2,mmguardstore做完数据清洗和特征提取,然后把样本数据落地,最后利用crontab定期将该数据同步到Hadoop集群中。
最终的数据收集模块结构图如下所示:
点击流数据提供了IP、平台、版本号、操作码等特征,经过多次试验,选定用户手工登录后一段时间内操作码的访问次数作为模型的输入。
上面我们提到过点击流的操作码有900个有效取值,所以一个显然的处理方法是,在mmguardstore中把用户的点击流数据转化为一个900维的向量,key是cgi id,value是对应cgi的访问次数。该向量刻画了用户的行为,可称为行为特征向量。
2.1.2 训练模型
初起为了控制不确定性,只输入1万/分钟的样本给模型训练和预测。系统的工作流程是先从Hadoop加载上一分钟的样本数据,然后用数据训练Isolation Forest模型,最后用训练好的模型做异常检测,并将检测结果同步到tdw。
在1万/分钟输入下取得较好的检测结果后,开始导入全量数据,全量数据数据的峰值为20万/分钟左右。出现的第一个问题是,一分钟内无法完成加载数据、训练模型、预测结果,单加载数据就耗时10分钟左右。这里先解释下为什么有“一分钟”的时间周期限制,主要原因有两个:
1, 想尽快获取检测结果;
2, 由于点击流异常检测场景的特殊性,模型性能有时效性,需要经常用最新数据训练新的模型。
解决性能问题的第一步是要知道性能瓶颈在哪里,抽样发现主要是加载数据和训练模型耗时较多,预测异常和上报结果的耗时并没有随数据量的增加而快速上涨。
加载数据的耗时主要消耗在网络通信上:样本文件太大了,导致系统从Hadoop同步样本数据时碰到网络带宽瓶颈。但由于样本是文本类数据,对数据先压缩再传输可极大减少通信量,这里的耗时比较容易优化。
训练模型的耗时增加源于输入数据量的增加。下图是1万样本/min的输入下,系统个阶段的耗时:
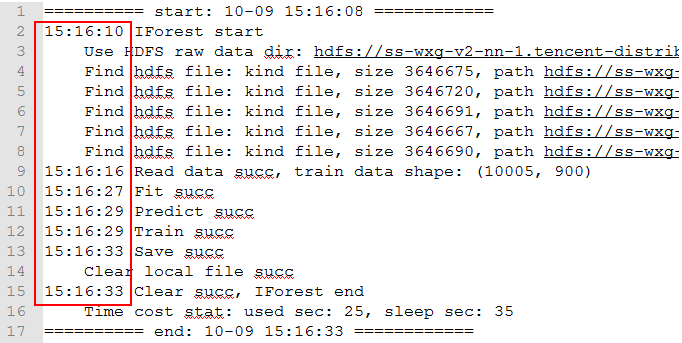
其中:
加载程序: 2s
加载数据: 6s
训练模型:11s
分类异常: 2s
保存结果: 4s
单轮总耗时:25s
需处理全量数据时,按线性关系换算,“训练模型”耗时为:11s * 24 = 264s,约为4.4分钟,单机下无法在1分钟内完成计算。
最先想到的优化训练模型耗时的办法是分布式训练。
2.2 分布式训练
由于scikit-learn只提供单机版的Isolation Forest实现,所以只能自己实现它的分布式版本。了解了下目前最常用的分布式训练方法是参数服务器(Parameter Server,PS)模式,其想法比较简单:训练模型并行跑在多机上,训练结果在PS合并。示意图如下所示:
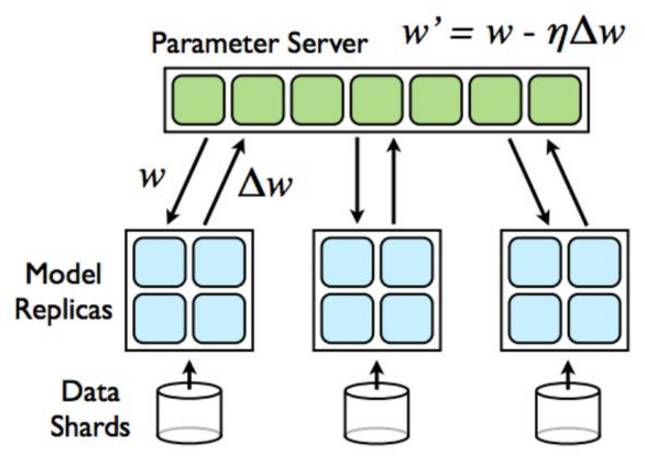
分布式训练对算法有一定要求,而Isolation Forest正好适用于分布式训练。
然后尝试在TensorFlow上实现Isolation Forest的分布式训练版本。选择TensorFlow的原因有主要两个:
1, TensorFlow已经实现了一个分布式训练框架;
2, TensorFlow的tf.contrib.learn包已经实现的Random Forest可作参考(Isolation Forest在结构上与Random Forest类似),只需对Isolation Forest定制一个Operation即可(Op的细节看这里:https://www.tensorflow.org/how_tos/adding_an_op/)。
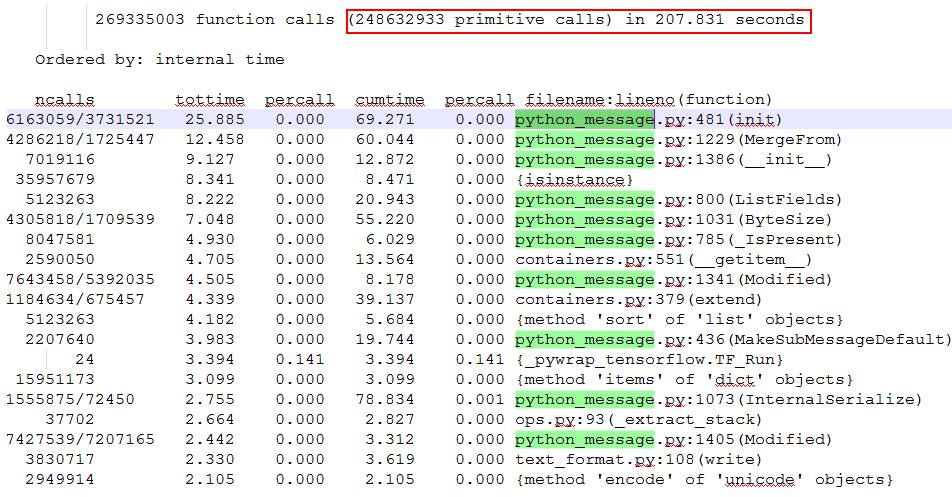
写完代码测试时,发现了个巨坑的问题:TenforFlow内部的序列化操作非常频繁、性能十分差。构造了110个测试样本,scikit-learn耗时只有0.340秒,29万次函数调用;而TensorFlow耗时达207.831秒,有2.48亿次函数调用。
TensorFlow性能抽样:
Scikit-learn性能抽样:
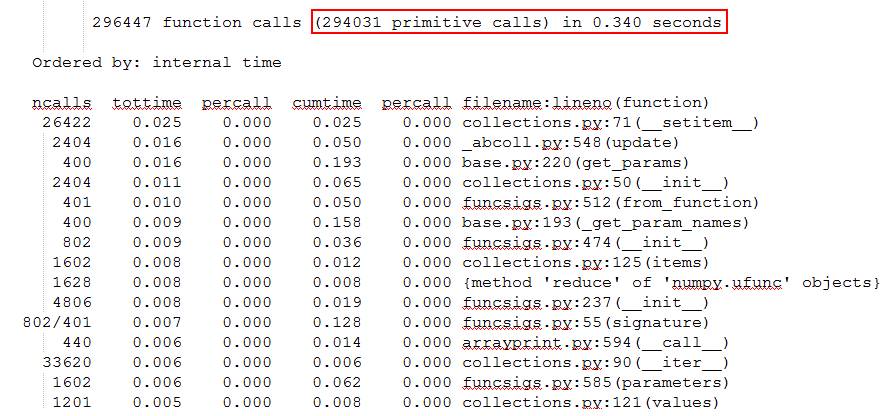
从TensorFlow的性能抽样数据可以看到,耗时排前排的函数都不是实现Isolation Forest算法的函数,其原因应该与TensorFlow基于Graph、Session的实现方式有关。感觉这里坑比较深,遂放弃填坑。
也了解了下基于Spark的spark-sklearn,该项目暂时还未支持Isolation Forest,也因为坑太深,一时半会搞不定而放弃了。
2.3 单机异步化训练
没搞定分布式训练,只能回到单机场景再想办法。单机优化有两个着力点:优化算法实现和优化系统结构。
首先看了下scikit-learn中Isoaltion Forest的实现,底层专门用Cython优化了,再加上Joblib库的多CPU并行,算法实现上的优化空间已经很小了,只能从系统结构上想办法。
系统结构上的优化有两个利器:并行化和异步化。之前的单机模型,加载数据、训练模型、预测异常、上报结果在单进程中串行执行,由此想到的办法是启动4个工作进程分别处理相应的四个任务:异步训练模型、预测异常和上报结果,并行加载数据。工作进程之间用队列通信,队列的一个优势是容易实现流量控制。
写完代码测试,却发现YARD环境中的Python HDFS库在多进程并发下直接抛异常。尝试多个方法发现这个问题较难解决,暂时只能想办法规避。经测试发现,直接从Hadoop同步所有压缩过的样本数据只需2秒左右,由此想到规避方法是:先单进程同步所有样本数据,再多进程并发解压、加载和预测。
按上述想法修改代码测试,效果较好,处理所有样本只需20秒左右,达到了1分钟处理完所有样本的要求。然后提交YARD作业线上跑,处理所有样本耗时却达到200~400秒:
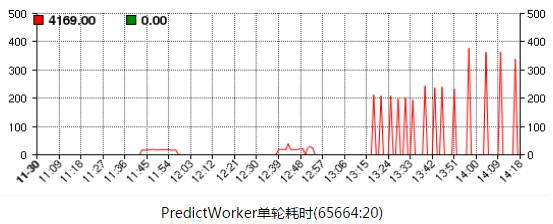
咨询YARD侧同学,得知YARD对提交的离线作业有CPU配额的硬限制,分时段配额如下表:
00:00~09:00 80%
09:00~19:00 50%
19:00~23:00 15%
23:00~24:00 50%
晚高峰时段的配额只有15%。
与YARD侧同学沟通,他们答应后续会支持scikit-learn库的在线服务。目前通过手工方式在一台有scikit-learn的mmguardstore机器上运行在线服务,晚高峰时段处理全量数据耗时为20秒左右。
最终的系统结构图如下图所示:
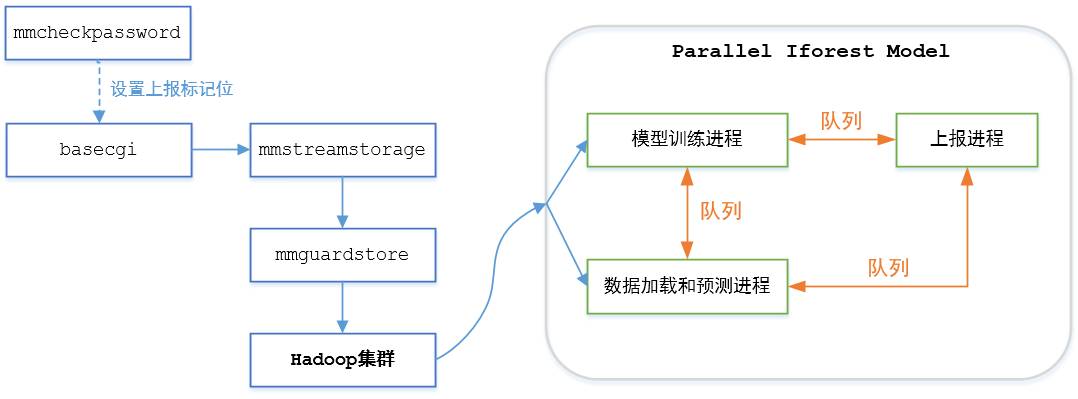
模型训练进程定期训练最新的模型,并把模型通过队列传给预测进程。预测进程每分钟运行一次,检查模型队列上是否有新模型可使用,然后加载数据、检测异常,将检测结果通过上报队列传给上报进程。上报进程block在上报队列上,一旦发现有新数据,就根据数据类型执行上报监控、上报tdw等操作。
2.4 评估性能
安全侧将异常用户分为以下几类:盗号、LBS/加好友、养号、欺诈、外挂/多开等。由于这些分类的异常打击是由不同同学负责,不便于对Isolation Forest的分类结果做评估,因此需要在Isolation Forest的基础上,再加一个分类器,标记“异常样本”的小类。利用操作码实现了该分类器。
接入全量数据后,每天准实时分析1亿量级的样本,检测出500万左右的异常,精确分类出15万左右的恶意请求。恶意请求的uin、类型、发生时间通过tdw中转给安全侧。安全侧通过线下人工分析和线上打击,从结果看检测效果较好。
2.5 持续优化
再回过头观察点击流数据,我们使用的Isolation Forest模型只利用了操作码的统计数据。可以明显看到,点击流是一个具备时间序列信息的时序数据。而自然语言处理(Natural Language Processing,NLP)领域已经积累了非常多的处理时序数据的理论和实战经验,如LSTM、word2vec等模型。后续期望能引入NLP的相关工具挖掘出更多恶意用户。





