二十一世纪计算 | 大图数据科学: 图数据中的推理
编者按:我们正淹没在大数据的河流里,数据之间的相互关系蕴含着丰富的信息,但也常常被我们忽略。本文中,加州大学圣克鲁兹分校计算机科学系教授、美国人工智能学会(AAAI)院士Lise Getoor讲述了图识别是如何依靠数据做出推理的,并给出了自己对于概率软性逻辑PSL优越性和可能应用的看法。Lise Getoor表示我们还需要对图进行更多的机器学习,考虑各种关联结点之间的复杂关系。

南加州大学圣克鲁兹分校计算机科学系教授Lise Getoor

(以下为Lise Getoor教授分享的精简版文字整理)
我们正淹没在大数据的河流里,大数据并非是平的,而是多模态、多关系、兼具时空、多媒体的。目前的AI技术,特别是机器学习,它将丰富复杂数据平放到矩阵的形式当中。我们当下所做的一些工作很可能忽视了数据当中的很多丰富信息,其中很重要的一点就是错误假设了数据之间的相互关系。作为研究者和开发者,我们需要考虑到这些图的结构和相关的环境因素。
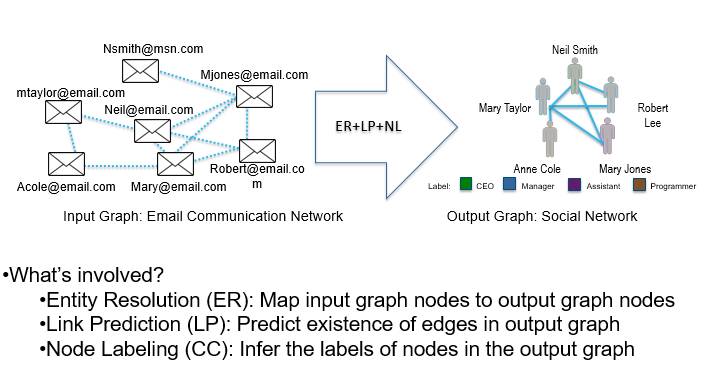
我想首先和大家说说三种常见的图数据推理模式,最简单的一种叫做协同分类。如果一个图的部分结点已经有标签,我们就可以推理出其结点的标签。社交网络就是很典型的例子,其中包含着非常丰富的信息和联系,通过信息和数据去做推理可以得出某位朋友的饮食习惯或其他偏好。基于数据在已有的信息,设置不同的权重,我们能够做一些简单的推理,充分利用本地信息和标签,再去推理出一些之前没有加入的标签信息。
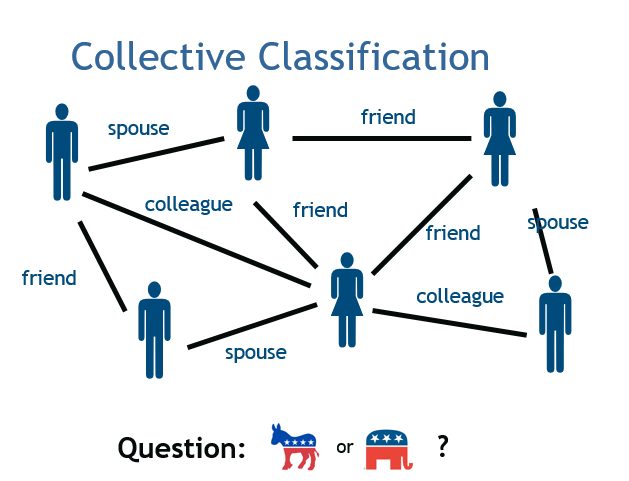
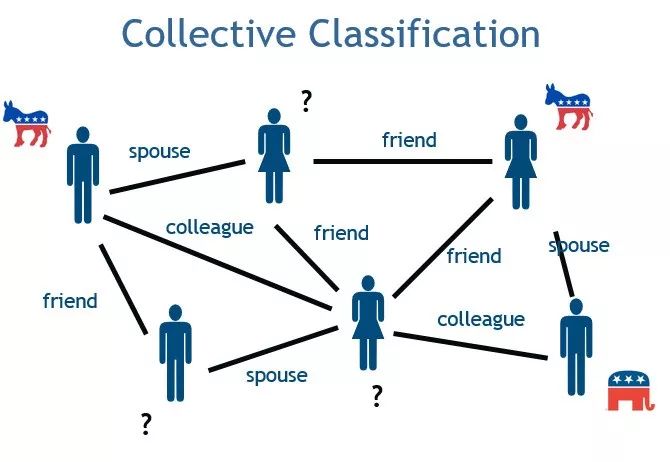
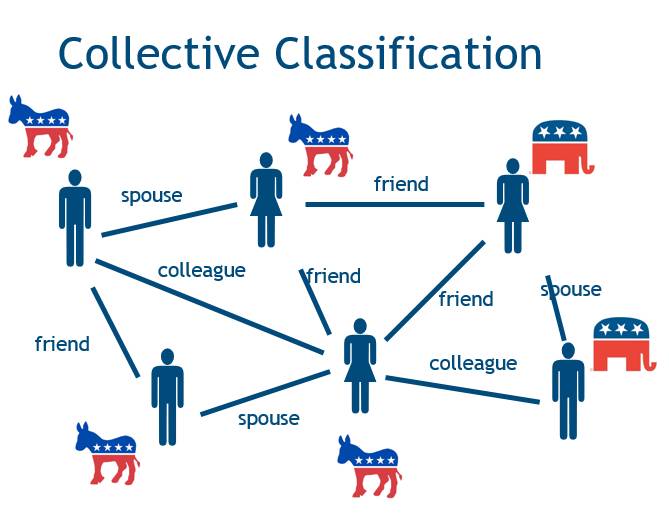
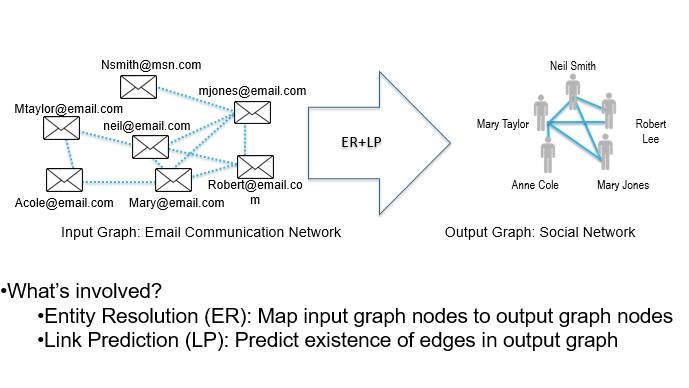
第二种叫做链接预测,我们不仅仅可以预测某一个结点的标签,还可以推断结点之间的链接。比如说有一个通讯网络,我们能够通过通讯信息推理出网络中所有人的层级,并通过不同种类的信息判断不同人之间的关系。
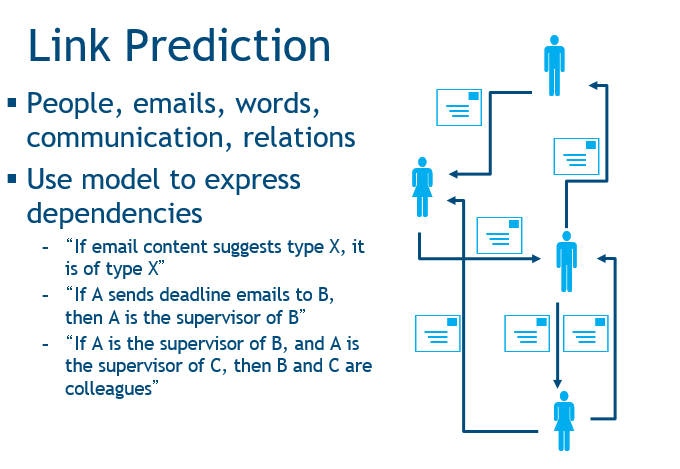
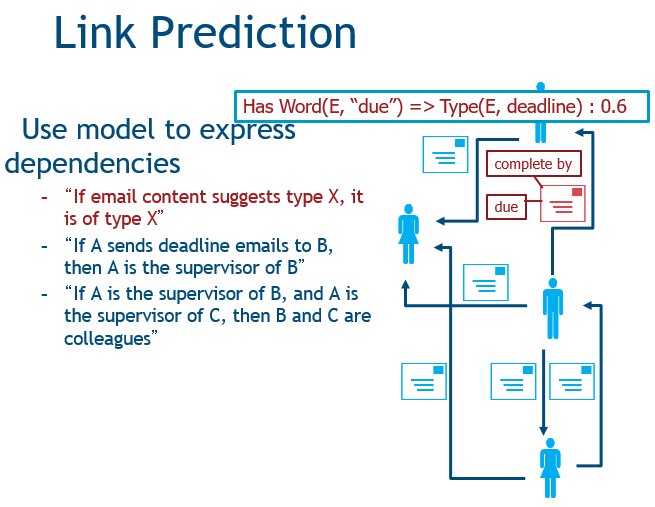
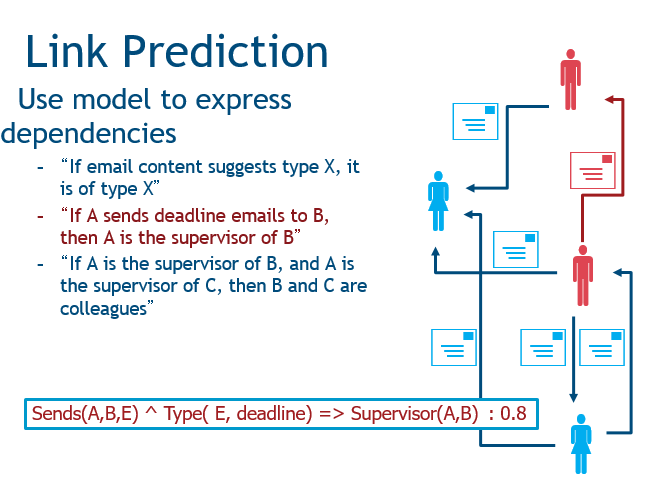
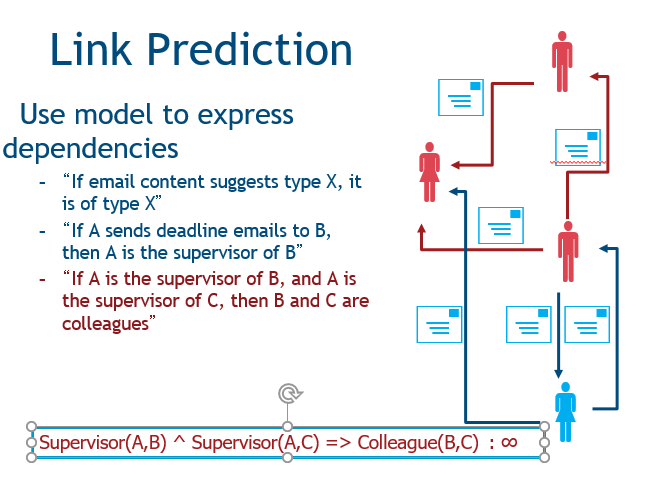
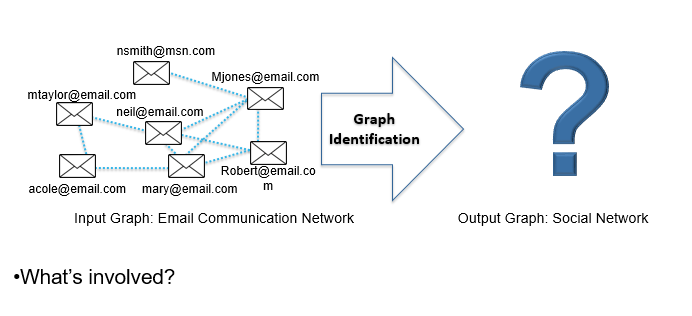
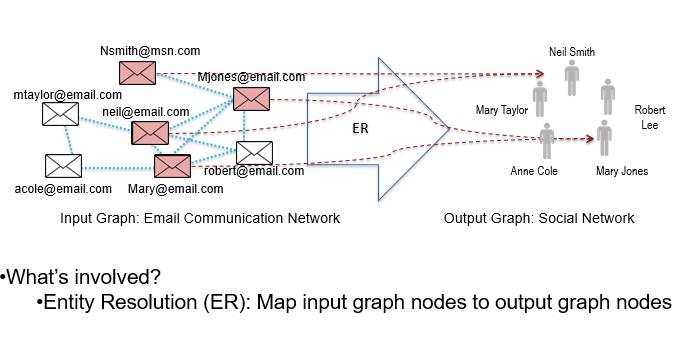
第三种是实体解析,任务是确定哪些结点指向同样的实体,我们就能从中获得一些信息。
对我个人而言,我最喜欢的图推理问题是图识别(发现可观察图结构所潜含的真实图结构),它能够把上面提到的的三个小模型结合到一起。还是以邮件通讯网络为例,通过对邮件信息进行推理就可以发现这几个人之间的关系及角色。我们需要对每一个信息进行研究,研究他们的实体状况和邮件状况。具体做法是首先对这些人进行分组,对之间的关系进行预测,并对实体身份做出判断。这其中也存在非常大的挑战,如何打造一个非常鲁棒的算法来理清其中的人物关系非常重要。
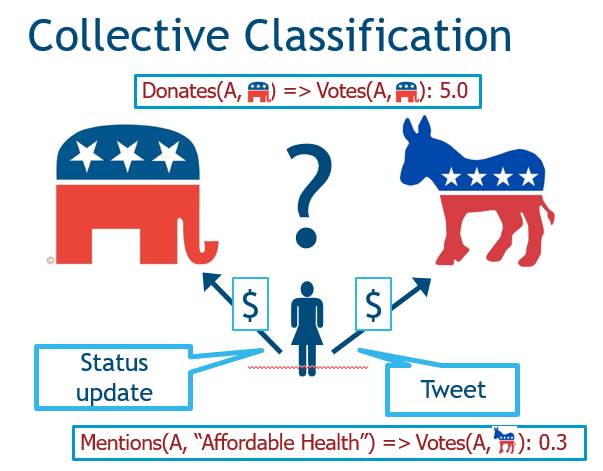
目前,统计学研究也在开发相应的算法,例如概率性推理和关系推理。有一个工具叫概率软性逻辑PSL,它是一种概率编程语言,即用描述性的语言对图上的问题进行描述。这个基础是,我们有属性、关系的逻辑表示,还有规则和约束来捕捉他们的依赖关系。PSL是一个这样的存在,它根据模板和数据来定义他们之间的概率分布用于推断。
PSL比较有意思的一点是,它通过将逻辑规则映射为凸函数,实现了大规模推断的可扩展性。更有意思的是,这个映射的合理性是用已有的理论计算机科学的结论证明的,用MAX SAT的近似随机算法结合统计学、机器学习、图模型方面的理论。之后我们就可以将从理论计算机科学当中的一些东西转化到实际的图识别应用当中去,最后将这种软性的逻辑和AI进行结合,在不同的情景下,很多时候你们会得到同样的优化结果。在我看来,我觉得我们现在能看到的这些东西仅仅是冰山一角,我们称之为叫Hinge-loss马尔科夫随机域。在这里有包含着很多具体微小的细节,每一个逻辑规则实际上都和某一个函数是相关的,相关的函数实际上都会造成一定的依赖损失。

在图识别领域,PSL在推理速度和准确度上的表现和离散的马尔科夫规则相比都要更好,且从数据当中学习权重和变量的效果也更加出色。由此PSL可以衍生出很多具体的应用,首先是分类问题。以在线讨论为例,PSL通过观察大家讨论的文字内容和行为数据,就能够很好地来预测用户的观点。再比如大数据和AI领域常常需要聚合信息做推荐、预测甚至打分,我们有来自社交互动、图像方面的各种信息,其实这些信息中存在一定的相似性。PSL的优势就在于它具有非常好的扩展性,特别是逻辑相似性较高的情况下扩展也会更加容易。
另外一个领域可能和安全相关,通过研究社交媒体当中的垃圾邮件可以进行协同推断,哪些可能是垃圾邮件。还有一个问题是如何把视觉的、文本的、关系的数据全部融合起来,去推测使用用户的个性。我们把所有的信息结合起来就能够预测一些人口学特征,比如性别、年龄,同时还可以预测人们在社交媒体当中的信任。
最后我想和大家分享有关知识图的建构,如何获取足够多的数据来实现知识的自动架构是一项长期以来的挑战。我们能够结合统计学的数据信息以及一些相对简单的语义信息,把它们和我开始提出的图识别问题结合起来,并在做图识别时找到它的结点、标签以及结点之间的关系,在此之上可以再融入一些本体的限制,同时还可以融入一些关于信息和其他来源的数据。把它们相结合能够产生比较好的效果,而且速度可以得到显著提升。
我们需要对图进行更多的机器学习,考虑各种关联结点之间的复杂关系。另外,当我们在做数据驱动技术时需要思考究竟什么才是负责任的数据科学,如何检查数据并通过算法做出决策。我个人对PSL感到兴奋的原因就在于它的逻辑规则确实比一大批权重或是参数的算法更加容易解释。这个领域会有一些隐私和安全性的问题,这值得我们进一步研究;相伴而生的还有很多机遇,有更多社会、商业、科学、安全以及其他方面的应用可以去发现、去探索。
想要了解Lise Getoor教授的演讲全文,请戳下方视频观看:
你也许还想看:
● 二十一世纪计算 | John Hopcroft:AI革命
感谢你关注“微软研究院AI头条”,我们期待你的留言和投稿,共建交流平台。来稿请寄:msraai@microsoft.com。



