数据科学是什么?数据科学是从数据中发掘价值的研究,这里面的关键词就是价值。价值取决于终端用户的解释。对于科学家来说,价值就是发现新知识;对于天文学家来说,仰望星空就是为了发现新的行星;对于企业家来说,价值就是利润。刚刚说到的人工智能、机器学习、深度学习都是孕育价值的工具。
哥伦比亚大学数据科学研究所有300多位老师,遍布于17个系,涵盖了所有的学科,涉及医疗、法律、商业等专业;有几大研究中心,包含金融分析、医疗分析、传感等研究方向。我们非常欢迎中国学生,也会一直欢迎中国学生。
我们的数据科学研究一共有三个使命:一是推动数据科学前沿领域的发展。数据科学是一个全新的领域,数据科学的基石是计算机科学、统计和云研究。二是通过数据科学转变各个领域和行业,实际上数据科学家遍布我们的学校,这种转型也涉及各个学科。第三个使命是保证数据被负责任地使用,使其造福社会。我们要解决气候变化、医疗卫生、社会公正等带来的各种挑战,同时还要负责任地使用数据,关注数据道德和隐私的问题。总结一下,如果今天大家要从我的演讲里收获什么,或者大家想从我的演讲中记住一点,那就是 Data for Good——数据要用来做好事,要负责任地使用数据。
接下来介绍一个我们的数据科学研究。它来自一个融合了统计学、计算机科学和社会科学的全新领域——因果推理。这对计算机科学、数据科学还有人工智能都有很重要的意义。我们想要解决的问题叫做多因果推理(Multiple
Causal Inference)。传统的因果推理是单向的,一个原因带来一个结果,而在这里我们关注的是多个因果的联系。举个例子,假设导演想要拍电影,在挑选演员的时候他们想先预测一下用哪个演员能带来多少收入。我们现在有一个数据库,包含电影名、演员还有票房等数据,我们想通过统计的方式知道每个演员能转化成多少票房。这个工作的难点在于,这里面有不少混杂因子,既影响因,又影响果。比如说,电影的类别就是一个混杂因子,因为大部分时候动作片就比艺术片票房要高;还有电影的叙事方式也对票房有影响。这些混杂因子会影响建模。
传统的方法可能会先列出所有的影响因子,计算一下可能结果,但是否已经测量了所有的混杂因子是不可证伪的。于是我们提出了一个想法——去除混杂因子(Deconfounder)。这是一种结合了无监督机器学习和预测模型检测的算法,推断潜在变量将其作为未观察到的混杂因子的替代,然后用这个替代来执行因果推断,估计“接近真实”的因果效应。Deconfounder 有三个特点:比经典因果推断更弱的假设;对混杂因子的替代效果是可以检测的;无偏推断。
回到电影选角的例子,我们通过 Deconfounder 的方法测量了007系列电影中演员的票房影响力,发现经过去除混杂因子后,Sean Connery(James Bond)的价值比没有去除混杂因子前提高了不少,而另外两个演员 Bernard Lee(M)和 Desmond Llewelyn(Q)的价值却下降了。事实上,多因果推断在现实生活中有很多应用,比如基因分析、挑选运动员还有商品定价等,有助于解决很多现实问题。
数据科学的第二个使命是将其应用在各个不同领域中,譬如生物学、经济学、金融学、天体物理学等学科,推动各行各业的转型。
我们和微软合作了一项研究,将机器学习与经济学结合,研究人工智能众包平台 Amazon Mechanical Turk 这样的劳动力市场,是否是一种买方垄断(即只有一个买方而有多个卖方,此时买方具有垄断性,可以付出较低的价格),它可能不是一个公平的劳动力市场。
另一个例子是强化学习在金融工程中的应用。现在很多金融机构都会用机器人投资顾问,不用花几个月的时间,几分钟就可以通过强化学习学到你的风险偏好,而且现在和机器人交流越来越能够像与真人交流一样流畅。
还有一个完全不同的领域——历史。哥大历史系正在用机器学习模型、舆情分析等方式去分析历史文本,例如,每年历史系教授都会在美国政府发布的文件中搜集文本,比如搜集70年代外交官相互发的外交传电,通过分析和可视化这些文件,来理解70年代发生的历史事件。
如何以负责任的方式使用数据,并以数据为方式应对社会挑战?
前面沈向洋博士讲到了微软的人工智能六大原则,我把它们调整顺序重新组合,变成这样一个缩写“FATES”,分别是公平(Fairness),负责任(Accountability),透明(Transparency),道德(Ethics),安全、保障与隐私(Safety,Security,and Privacy)。
数据助力安全与保障
我想重点谈一下“S”,安全、保障与隐私。这个项目叫 DeepXplore,它是用编程语言和软件工程的方式去测试深度学习系统的一个白箱框架,通过神经元覆盖(neuron
coverage)和差分测试(differential testing)去发现 DNN 的很多意想不到的缺陷。什么是神经元覆盖?在软件工程中,测试程序会用到代码覆盖,为软件每一个路径创建一个测试,神经元覆盖的思路与之类似,比如创建一些输入的事件实例去覆盖每一个神经元,然后我们就会发现很多错误。这项工作也获得了 SOSP 的最佳论文奖。
![]()
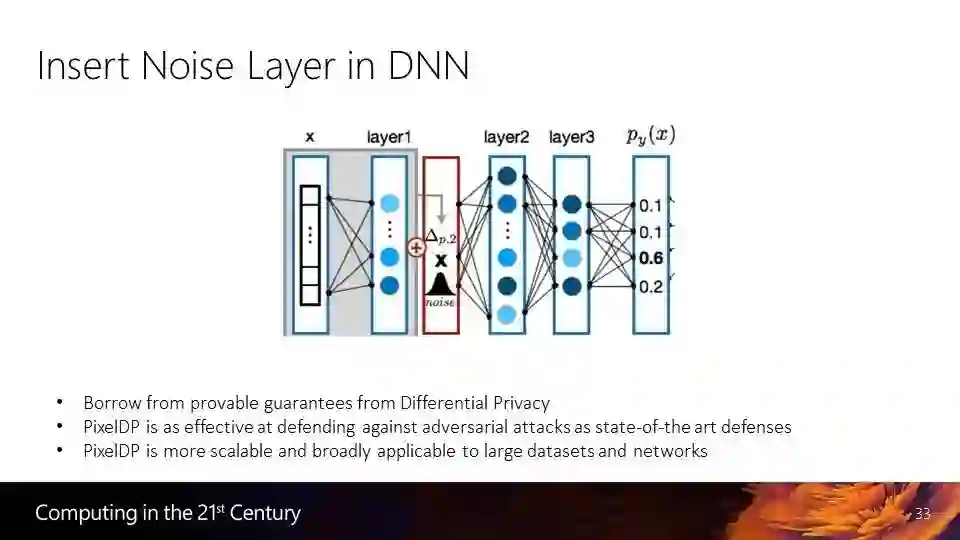
另一个项目 PixelDP,现在有很多研究都揭示出 DNN 的脆弱性,连非常简单的涂鸦都会改变 DNN 的分类结果,而在自动驾驶时如果认错了交通标识,可能会导致非常严重的后果。这个研究工作受到了差分隐私(differential privacy)的启发,这个理念来自于密码学,我们把它嫁接到机器学习中,试图使 DNN 更加强大,以应对图像中的污染等情况。我们给 DNN 增加了一个噪声层,可以确保将输入中污染的影响控制在一定范围内,让分类器不会认错。
![]()
用数据应对广泛的社会挑战
虽然这方面的研究还处于初期阶段,我们希望数据能帮助人类应对许多社会挑战,比如下面展示的两个气候和医疗的例子。
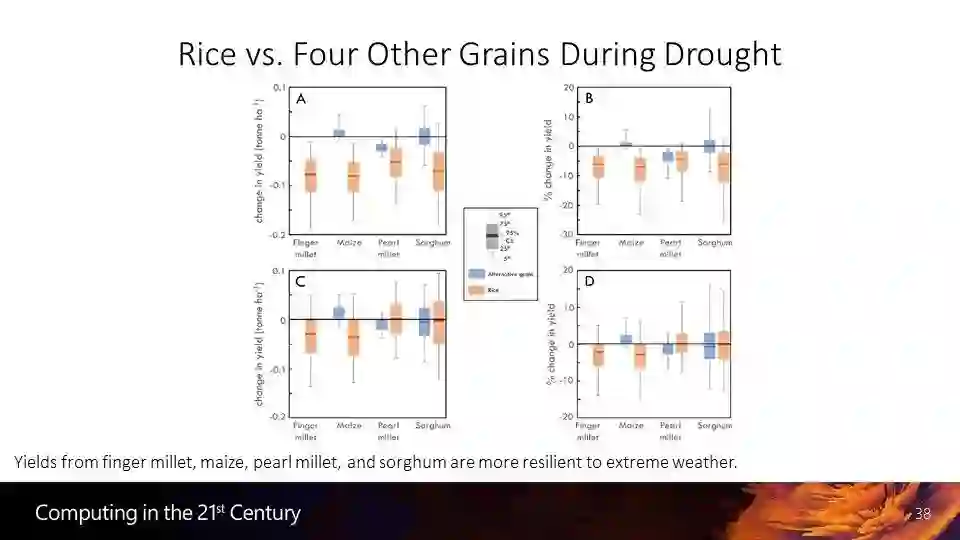
大数据和机器学习可以帮助农民选择更合适的播种作物,来减少多变的气候对农业产量的威胁。研究者研究了印度种植的5种农作物的数据,小米、玉米、水稻、珍珠米和高粱。很多农民会大范围种植水稻,但是水稻对降水、气温、土壤等条件的变化都比较敏感,在遇到频繁气候变化时,在一种稻米上孤注一掷就可能导致国家的农业总产量下降,使得粮食供应受到影响。因此我们的研究对印度的作物种植多元化给出了一些建议,有助于抵御气候变化的不利影响。
![]()
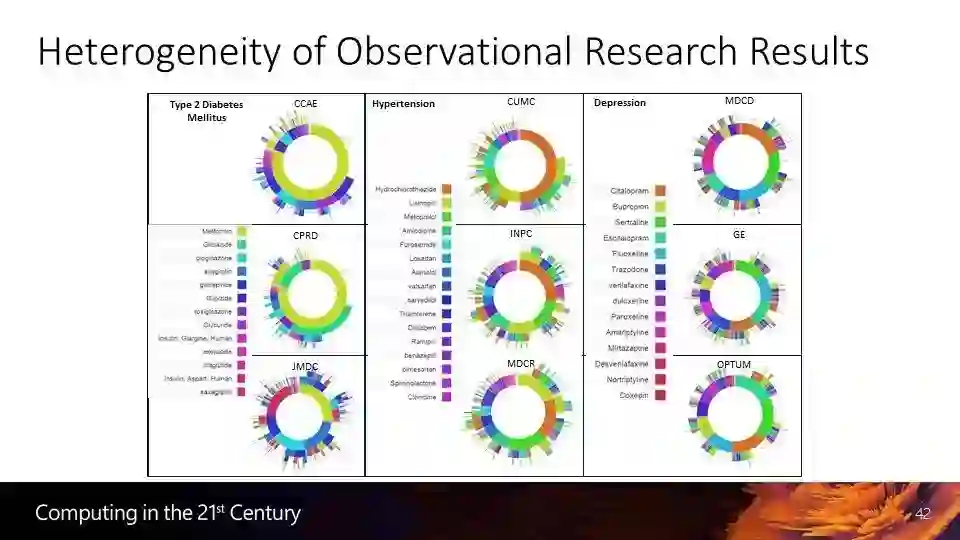
下面这个例子是一个全球性的医疗项目 OHDSI(Observational Health Data Sciences and Informatics),我们看到的是来自25个国家的6亿患者的电子病例数据,都用同样的格式对数据进行收集整理,这些数据令人惊叹,可以使我们深入了解仅靠临床了解不到的医疗情况。
![]()
之前讲到探究多因果的关系是一个去混杂因子的过程,如果只用简单的线性回归的模型看某种药物的效果,可能会无法发现这种药物到底是因是果,不能有效地找到因果关系。在多因果关系的推理框架下,去混杂因子是非常有前景的,比如在梳理这些病例数据的时候。
最后请大家记住“Data for Good”,谢谢。
![]()
你也许还想看:
![]()
![]()
![]()
![]()
感谢你关注“微软研究院AI头条”,我们期待你的留言和投稿,共建交流平台。来稿请寄:msraai@microsoft.com。
![]()