带你走近机器学习——机器学习基础知识及应用
云栖君导读:本文介绍了机器学习的基础知识以及在企业中的一些应用。通过本文的学习可以快速了解机器学习的基本概念、监督学习以及PAC学习理论,并了解机器学习在实际应用中现状。
演讲嘉宾介绍:淘宝技术部——永叔。
本次直播视频精彩回顾地址:
http://click.aliyun.com/m/45238/
本节课代码及讲义下载地址:
http://click.aliyun.com/m/45239/
本次分享主要分为以下四个部分:
ML技术都用在哪里?
最常用的LR是什么鬼?
ML工程师每天都在干什么?
DL在企业里都怎么玩?
一、ML技术都用在哪里?
以一次搜索引擎检索为例,在搜索框中输入关键词“承德旅游”。可以发现,在搜索结果中既有自然搜索的结果也有sponsored search的广告结果。在这样一次检索的背后发生了什么呢?
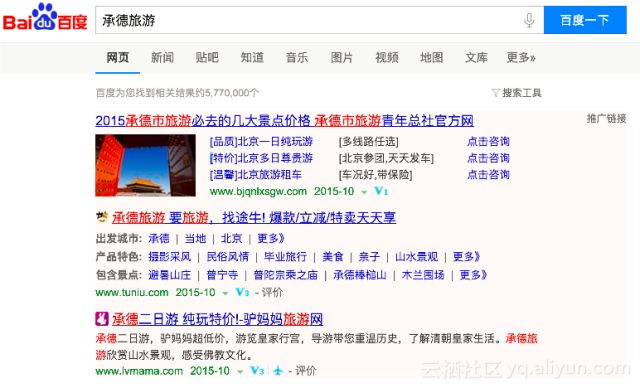
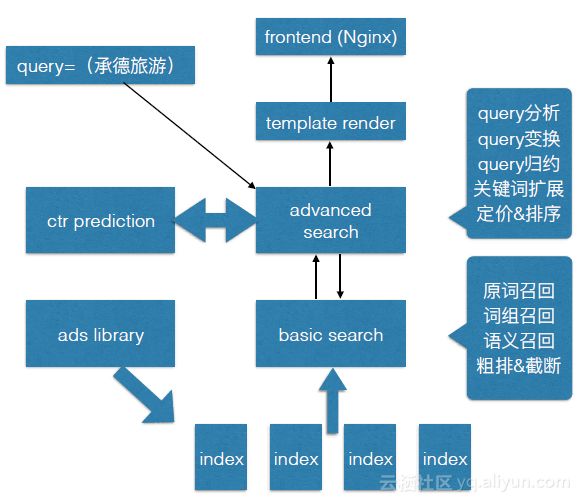
下图是一个检索的示意图。最前端是WEB服务的网关,比如Nginx,Tengine这样的服务器。输入的查询词是“承德旅游”。首先,它会进入高级检索模块,其中包含很多步骤,比如query分析、query变换、query规约、关键词扩展等。找到了query召回信号之后,进入基础检索进行召回,比如广告主文案的召回。下图最下部分是检索索引部分。众所周知,在sponsored search中,广告的排序是和广告在展示后是否会被用户点击是直接相关的。但决定广告在一个队列里时的先后顺序时,就需要用到机器学习。这是一个典型的二分类,即点击或不点击。点击率预估模块可以在下图的左侧找到。
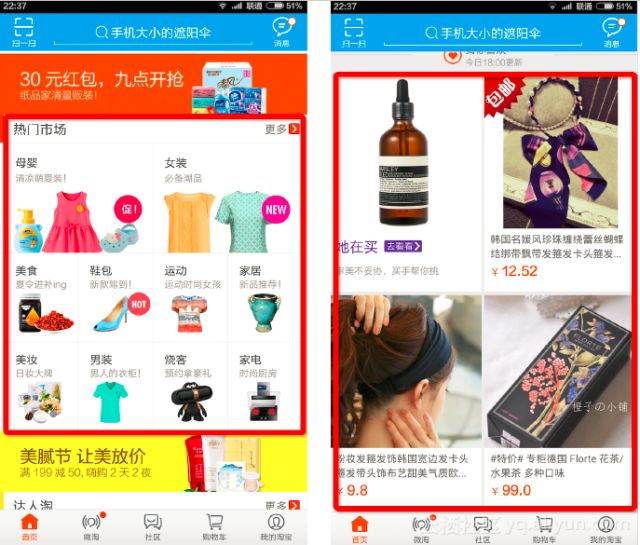
类似的机器学习的例子还有很多。比如,打开手机淘宝,在这一块区域中,每一个人看到的结果都不一样。右边是手机淘宝的首页下方的猜你喜欢商品推荐模块。这个模块会根据用户的长短期兴趣来推荐不同的商品。像这样的商品推荐应用中就大量地使用了机器学习相关的技术。
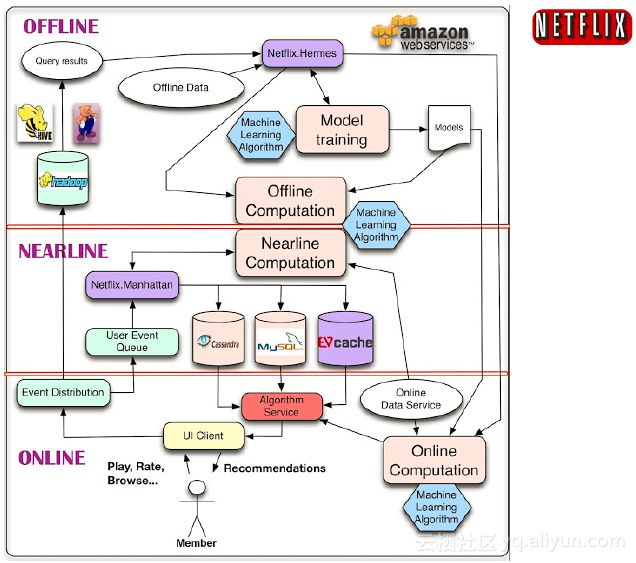
类似的系统有很多,比如Netflix,它曾是美国的一个租碟公司,现在主营网络视频和电视直播等等。下图是它的系统架构图。其中既有搜索也有推荐,大量的使用了机器学习的相关技术。
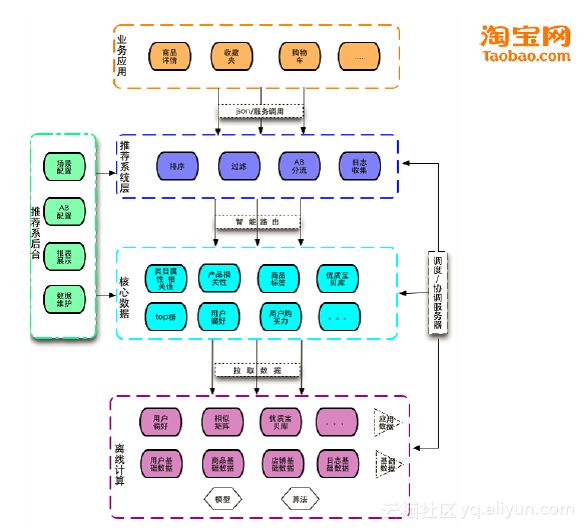
下图是一个简要的淘宝推荐示意图。可以从用户的行为日志中挖掘可能的商品和商品之间的关联,以及用户的喜好。在做出一些推荐之后,会对推荐进行排序、过滤等。这其中,商品展示后是否会被用户点击,用户点击后是否会购买,都是典型的二分类问题,都可以转化为机器学习问题来处理。
在做机器学习相关的应用时,只要我们识别出这些问题可以利用机器学习的相关技术去解决,那就可以使用相关的模型或算法去解决相应的问题。现在常用的机器学习中,统计机器学习的应用是比较广的。它有三个要素,首先是模型,即决策函数。第二,学习策略,即损失和风险是什么。第三,算法,就是要把模型中相应的权重求出来。下图右侧列了一些比较典型的问题,比如网页的主题聚类,查询词的意图识别、多个衡量网页与查询词相似度方法的结果的融合,包括经典的点击率预估和商品转化率的预估。这些问题都可以作为机器学习问题来做。

在现代后端商业系统中,一旦碰到分类类的机器学习,很多公司都会选择logistic回归,为什么大家都会选择LR呢?在企业级应用中有一些原则。
数据的丰富性比模型的选择更重要。数据干净,数据量大、数据的质量高时,用一些简单高效的模型就可以取得非常好的效果。
模型的吞吐能力。在企业级应用的时候,一般都会面临海量数据,模型求解对数据的吞吐能力就是大家关注的一个重点。
求解算法的并行化难度的高低。如果并行度很低,在大规模海量数据处理的时候,就很难运用集群的力量来达到加速的目的。
模型的迭代速度
特征的自解释性及badcase控制。Logistic回归在特征的自解释性上的表现很好,比如现在常用的深度学习,网络模型重权重与其物理含义之间有比较清晰的对应关系。相应的,如果在一些样本上学偏了或者是碰到了一些badcase,像logistic回归这样,天然具有自解释性的模型就能很好地控制这些情况。
二、 最常用的LR是什么鬼?
接下来给大家解释一下logistic回归的原理。
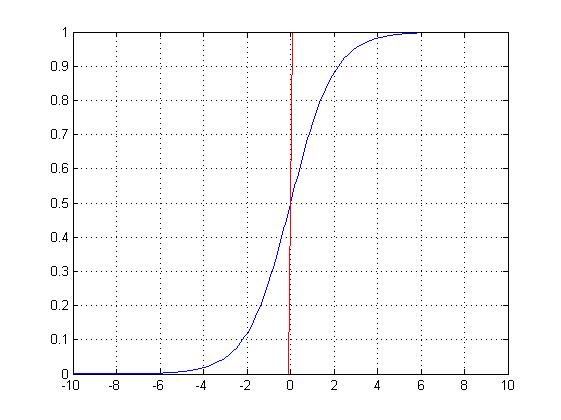
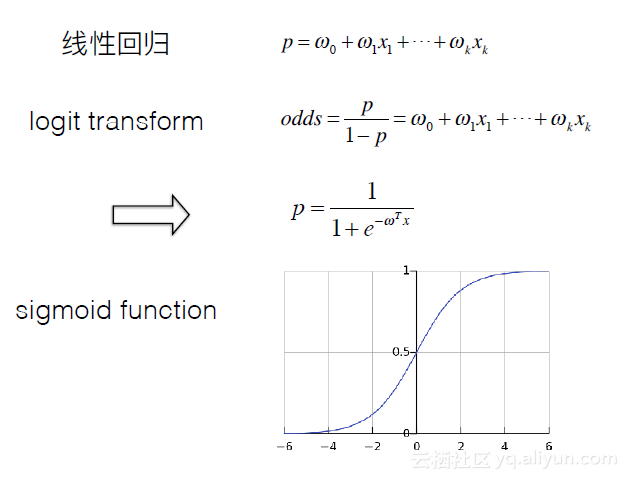
Logistic回归是广义线性回归中的一种。线性回归,如下图第一个公式所示,大家很容易理解。Logistic回归在线性回归的基础上进行了logit变换。如下图第二个公式所示。可以发现,当概率趋近于零时,权重就会发生剧烈的震荡。为了让求解的概率结果具有从0到1的物理含义,同时也避免一些震荡,因此进行logit变换,其概率的计算公式如下图第三个公式所示。Logistic回归在现代的深度学习中用较广,比如,sigmoid激活函数,其图像如下图所示。可以发现,它是一条0到1之间的光滑的函数曲线。
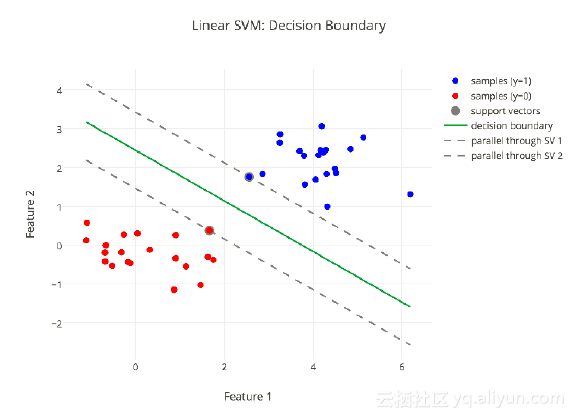
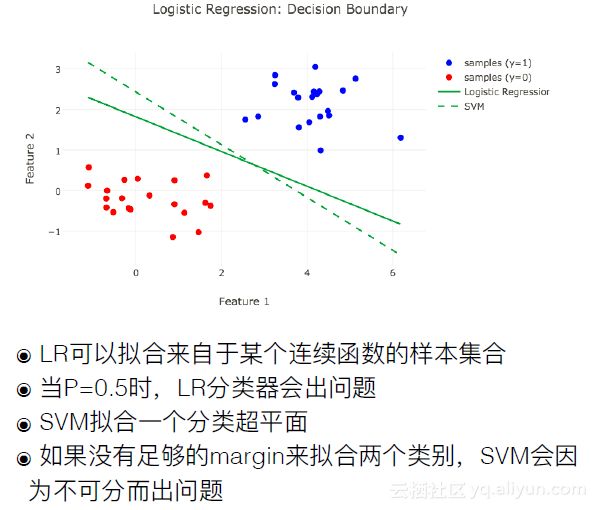
还有一些分类方法,比如线性SVM,也可以用于二分类,它的核心还是寻找一个分界面把样本分成两类。如下图所示。
下面是Logistic回归的一个例子。LR可以用来拟合来自于某个连续函数的样本集合。当P=0.5时,LR分类器也会出现问题,这时样本会被随机分配。
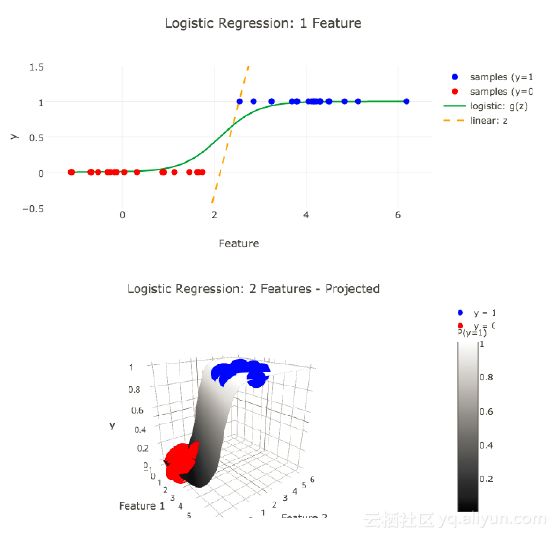
回归到之前提及的点击率预测问题,它是一个典型的0-1样本问题,这里把它称作logistic binary classifier。下图的第一个公式计算了y=1和y=0时的概率。构造Loss的方法有很多,这里我们采用的是极大似然估计。把所有的事件,包括正例和负例,全部发生的概率进行连乘,让全部发生的概率最大化,一般在计算Loss时会加一层log运算,将连乘运算变成加法,方便在后续进行优化处理。在构造损失函数时,通常分成两个部分。第一个部分是empirical loss,即经验风险,第二个部分是structure loss,即结构化风险。大家如果有时间的话,可以去看一下周志华老师的《机器学习》(西瓜书),在这本书中清楚地解释了这两种风险。下图最后一个公式计算了结构化风险,加上‖ω‖目的是避免模型在求解地过程中为了拟合某些特殊的点,让ω产生非常大的振幅,导致模型出现过拟合。

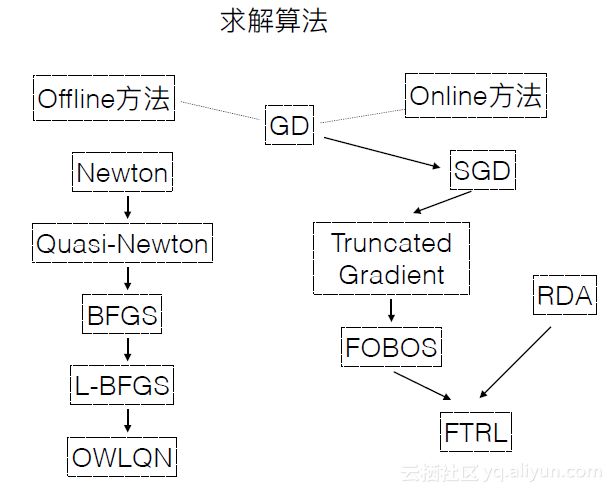
LR有很多求解方法,下图列出一部分。它们主要分成了两大类,第一类是左边这一支他们属于Newton法,之所以会产生这么多版本,核心都是为了在精度和计算速度中进行取舍。另一类方法是右边这一支,它们都属于梯度下降。现在机器学习算法中有针对梯度下降进行的很多优化算法。所有模型求解算法可以分成两个大类,Offline和Online。
下面讲解L1-LR优化问题最优解。如下图第一个公式,在结构化风险中加1范数,即把ω各维度的绝对值相加。这时,会出现一个问题,在做最优化问题时的KKD条件,是Loss function取到最小值点。需要要求它的一阶条件,即一阶导数为0。但使用1范数时,它的一阶导是不存在的。因此引入了虚梯度(次梯度)的概念,即分象限进行求解,如下图所示。

Offline求解算法包括以下几类。Gradient Descent:直接采用目标函数在当前w的梯度的反方向作为下降方向,它一般是线性收敛的。Newton Method:利用二次Taylor展开来近似目标函数,通过求解近似函数来获取下降方向。Newton法在求解多元Loss function时,需要求解一个复杂的高维的矩阵即Hessen矩阵以及矩阵的逆矩阵,时间复杂度很高。Quasi-Newton法通过拟合的方式找到Hessen矩阵的近似来加速计算下降方向,DFP、BFGS、L-BFGS以及OWLQN都属于此类算法。

DFP只利用了梯度来计算Hessen矩阵,但仍需要计算Hessen矩阵的逆来获取Newton方向。BFGS直接利用梯度来计算Hessen矩阵的逆,因此只需要求一阶导即可。

在迭代时,除了选择权重更新的方向之外还要选择步长。一种方法是固定步长,而通过line search等方法可以选择最优步长,使损失函数尽量小,接近全局最优点,避免陷入局部最优点。感兴趣的同学可以自行学习。
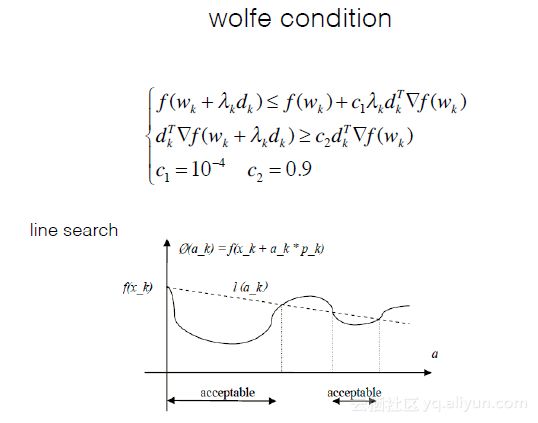
Quasi-Newton的求解过程。思路是用一阶导去逼近二阶导。


BFGS算法简介,见下图。

L-BFGS算法简介,见下图。


感兴趣的同学可以参考2003年微软研究院有关OWLQN的论文,也可以在网上查找到对应的算法实现。
OWLQN-象限限定的有限内存拟牛顿法。针对计算虚梯度时的分象限问题进行优化,在更新步长搜索时不会导致权重更新越界。同时解决了用1范式导致的求一阶导时的问题。有人可能会有疑问,为什么要用1范数而不是更平滑的2范数。因为在企业级预估模型中比较关注模型的稀疏性,这与性能相关。如2范数这样稀疏性较好的,其各阶导数均存在且曲线平滑,但当特征值很多比如一千亿个,那么就存在一千亿个权重值需要被计算。然而使用1范数就可以有效的使模型的size变小,在可接受的精度损失范围内起到提速的效果。

上述方法都属于Offline求解方法。在Offline求解方法中,大家可以在训练时看到整体的数据样本。比如昨天一整天产生了一千万的样本,在训练时,这一千万个样本都可以作为训练样本。Offline求解方法中有以下两个假设。一、在实际场景中,样本分为训练集和测试集,他们应该是近似同分布的。二、模型中所选择的特征具备良好的泛化性。因为在模型上线后,遇到的样本可能是在训练集甚至验证集中都未出现过的,如果模型没有良好的泛化性,那么预测结果可能比较差。需要注意的一点是,在实际情况中,训练集和测试机未必是近似同分布的。
三、ML工程师每天都在干什么?
工业界中需要的好模型有以下特征。
训练速度高,能够处理超大规模的样本;
能够捕获样本中重要的信息,并反映在权重里;
线上实时预测时性能高,满足高并发场景的需要(稀疏性);
对新数据反应及时。
BATCH问题的定义如下图。

BATCH训练和ONLINE训练的区别在于,BATCH跑的是整个样本集,而ONLINE的样本是一条一条的流式的。BATCH使用的是基础梯度下降方法,选中一个方法乘步长,选择下降最快的方向去迭代权重。下图右边的是随机梯度下降方法。“随机”体现在,它的方向是以每个样本为例做选择的,以整个样本来看,方向选择就具有很强的随机性。从BATCH 到ONLINE的转化使得模型更适合线上的流式数据。模型可以对外界刺激产生更为及时的反应,单样本也更利于加速计算。

下面给大家介绍LOSS function中常见的正则项(regularization term),包括L1正则项,L2正则项。正如前面介绍的,L1在0处不可导,而L2在0处可导。L1在BATCH模式下容易产生稀疏解。而ONLINE模式下即使L1也很难产生稀疏解,因为单样本更新时,在整个数据集上是很难产生稀疏解的。我们期望在ONLINE模式下模型的高反应速度,同时也希望能克服它所带来的问题
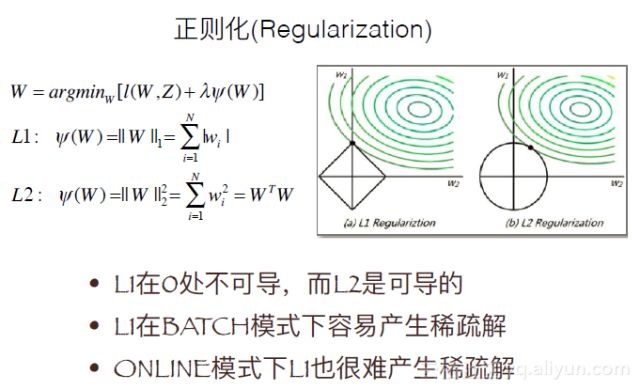
其解法分为以下几种分类:
提升训练精度,降低模型复杂度,引入稀疏性
SGD及其变种,L1简单截断法、TG(梯度截断)、FOBOS(前向后向切分)
对偶平均法,RDA(正则对偶平均)、FTRL
接下来给大家介绍损失函数中ONLINE的Regret Bound。在BATCH模式下,损失函数是比较容易定义的。但在ONLINE模式下,定义损失函数,是将先前学习到的模型与当前的损失作差,即Regret,其计算公式如下图。
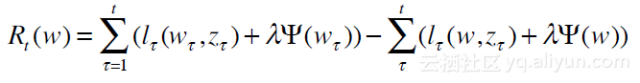
下面给大家介绍一下L1简单截断和TG梯度截断。如下图所示,L1截断中,当|vi|≤θ时,直接截断为0,即引入稀疏解。而梯度截断中,引入了α使其更柔性,可以利用α的值进行调节。
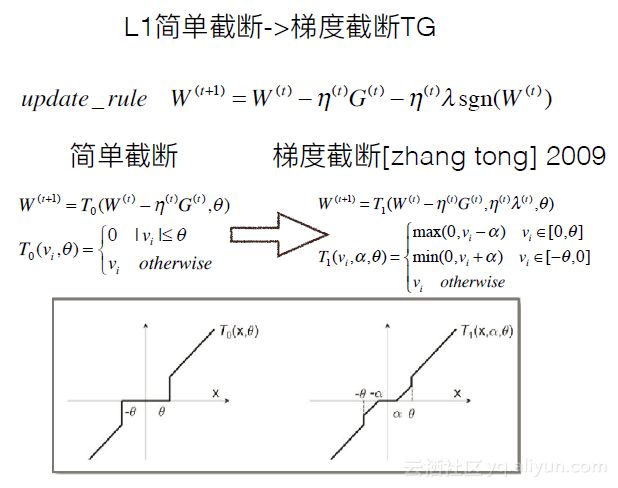
FOBOS也是在2009年提出的,它的求解分为两步。如下图所示。

RDA属于对偶平均法,其简介如下图。

FTRL结合了RDA和FOBOS的优点,其简介如下。这个模型在现在很多公司中应用很广。

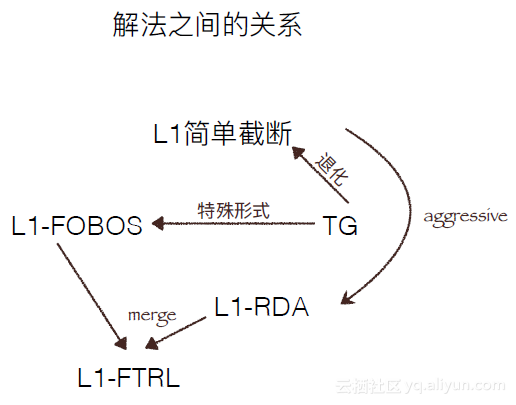
下图是解法之间的关系图。
由BATCH变换为ONLINE时,会引入一些问题。
Sampling是否有收益。BATCH中正负例的比例是与数据集中的比例差不多的,而ONLINE中,一段时间内的正负例比例会出现差异,因此要采用Sampling策略。

ONLINE训练的瓶颈。训练速度要跟得上样本产生的速度。

BATCH/ONLINE的Ensembling。
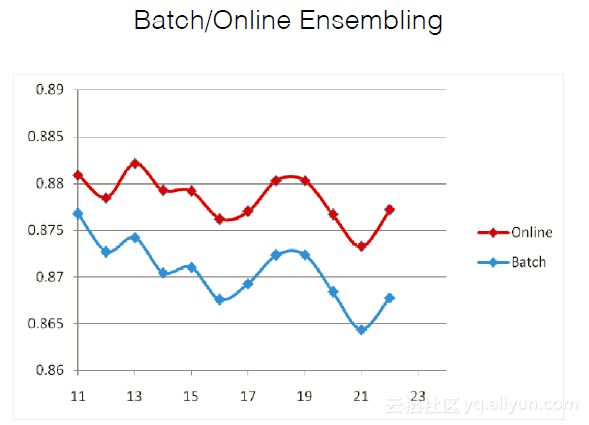
ONLINE场景下特征如何调研。

下面介绍如何选择ONLINE化的路线。ONLINE方式相较于BATCH有明显的提升,但如果要做到实时产生数据实时完成,还存在面临的挑战。因此在选择BATCH和ONLINE方式时要根据实际情况来定。

下图是一个Online Prediction System的例子。可以发现,在做点击率预估时,需要缓存机制,比如保存前几分钟的展示样本,当发生点击时再将点击与展示样本进行拼接。
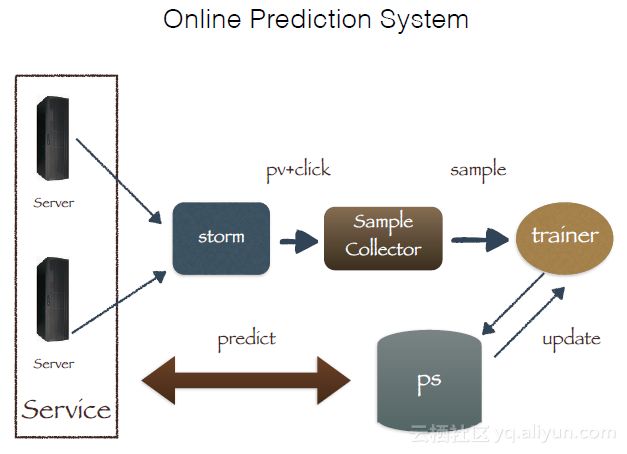
上面,解释了ONLINE相关的各种问题,以及一些解决方案。下面列出了一些挑战。
由延时点击带来的误差累计
秒级更新带来的压力
特征权重在累计新样本中变化太小
并行特征实验框架,支持在线特征实验
前面介绍了关于采样的方法,实际上,在采样时一定会引入一些bias,其实在训练系统中也会引入各种各样的偏差。这些偏差会导致预估值与真实值之间存在距离,如何使这两个值尽可能接近呢?这是机器学习中的一个经典问题:Predicator Calibration,即预估矫正。根据不同的bias可能会采用不同的方法进行矫正。

四、DL在企业里都怎么玩?
在企业中,算法工程师每天大量的工作都集中在数据部分,包括数据准备、数据清洗、数据分析、特征筛选等。在企业中,需要解决的问题通常是大规模的,当数据体量超过一定大小之后,很多在paper中适用的方法可能不再适用,需要对模型求解算法进行优化,比如分布式的训练程序的开发。现在Tensorflow、Parameter Server、MxNet等框架给编写分布式并行求解算法带来了很大的便利。
下面简单介绍以下企业中的深度学习应用。
下图展示了深度学习的发展情况。

深度学习的提出过程如下:
海量数据中蕴含了大量的信息,而机器学习的目的就是期望从中找出有价值的特征(也称概念)
模型的复杂程度(即自由度)反映了其理解数据的能力,一般而言,数据量越庞大、数据噪声越多就更加需要模型有强大的表达能力
传统机器学习的效果很大程度上取决于特征选择的好坏,即我们常说的特征工程(Feature Engineering)
2006年Geoffrey Hinton在美国Science杂志上提出的深度神经网络(逐层求解方法)大幅提升了效果以及模型求解的速度
Andrew NG:我们没有像往常做的那样框定一个边界,而是直接把算法应用到海量数据上,让数据自己说话,系统会自动从数据中学习。
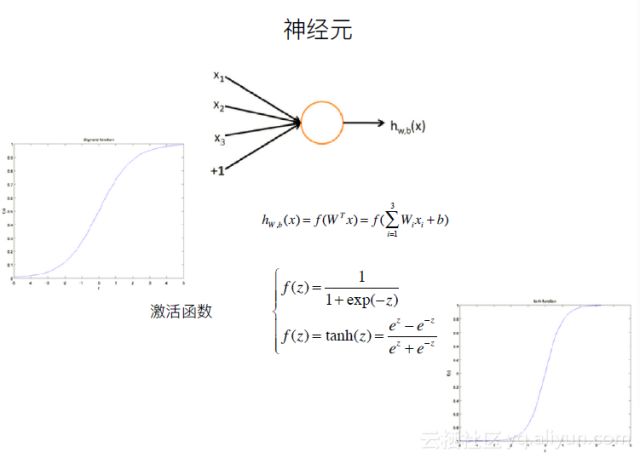
下面是深度学习中的一个神经元结构。其中有不同的的激活函数对应着不同的使用场景。
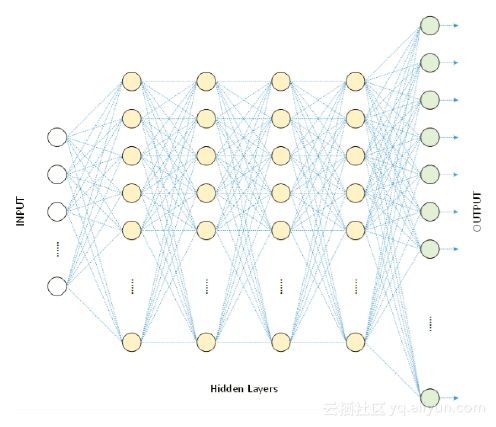
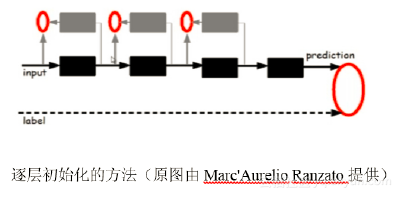
传统的神经网络的核心是前一层和后一层之间存在大量的参数之间的交叉联系。深度学习的提出了逐层求解神经网络的算法,便于大家在其中增加层数即Hidden Layer,在图像、语音等复杂数据的建模过程中有着很强的建模能力。
下图是逐层初始化的示意图。
在深度学习中应用的最好的两个方向是语音和图像。深度学习在NLP中的应用在近几年也有了一些进展。但对于一些经典的language model,深度学习仍没有取得明显的优势。
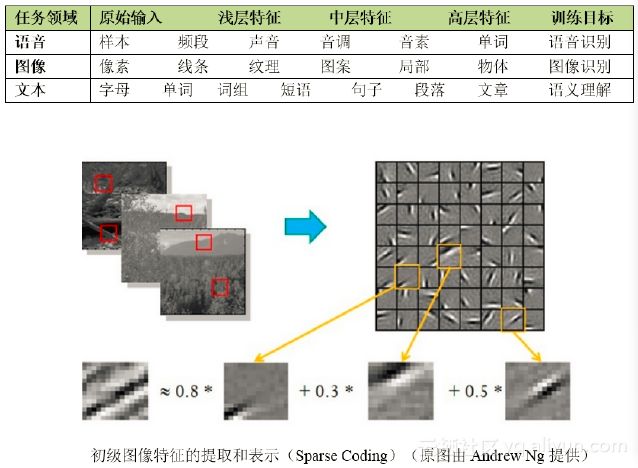
下图是浅层模型和深层模型的对比。
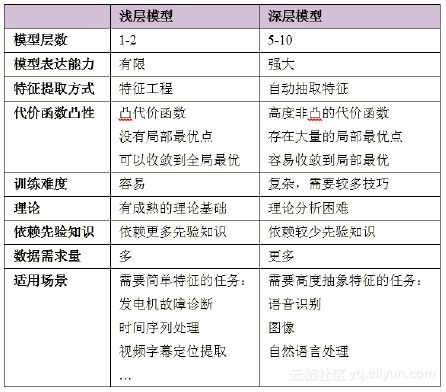
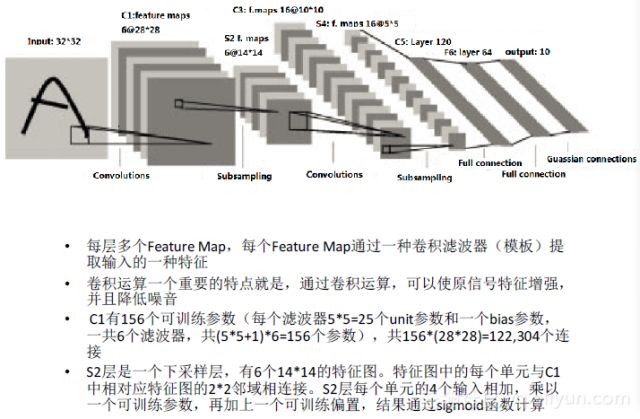
下图是卷积神经网络的示意图,它基于不用size的模板来提取同一张图像上的不同维度的抽象特征。CNN在图像处理中应用效果较好,也有人将CNN应用于NLP中,效果差强人意。
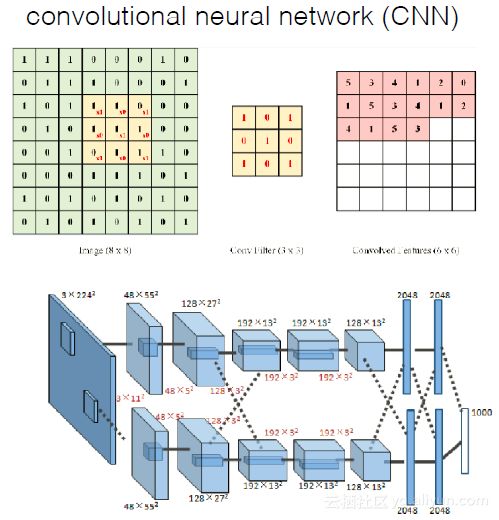
Deep learning简单可以理解为NN的发展。大约二三十年前,NN曾经是ML领域特别火热的一个方向,但是后来确慢慢淡出了,原因包括以下几个方面:
容易过拟合,参数比较难调,⽽而且需要不少trick;
训练速度慢,在层次比较少(<=3)的情况下效果并不比其它方法更优。
传统BP⽹网络:梯度扩散,误差校正变⼩;易收敛到局部值。
DL两步训练:down2top非监督一层层训练;top2down监督调整(fine-tune)。
深度模型的训练难度包含以下几个方面。
局部最优:与浅层模型的代价函数不不同,深层模型的每个神经元都是非线性变换,代价函数是高度非凸函数,采用梯度下降的方法容易陷入局部最优。
梯度弥散:使⽤反向传播算法传播梯度的时候,随着传播深度的增加,梯度的幅度会急剧减小,会导致浅层神经元的权重更新非常缓慢,不能有效学习。这样一来,深层模型也就变成了前几层相对固定,只能改变最后层的浅层模型。
数据获取:深层模型的表达能力强大,模型的参数也相应增加。对于训练如此多参数的模型,小训练数据集是不能实现的,需要海量的有标记的数据,否则只能导致严重的过拟合。
点击左下角【阅读原文】进入下载讲义!
end
SpringBoot开发案例之整合Spring-data-jpa进阶篇
更多精彩