本文对当前基于深度学习的行为识别方法进行了全面的综述。
人
类行为识别旨在了解人类的行为,并为行为指定标签,例如,握手、吃东西、跑步等。
它具有广泛的应用前景,在计算机视觉领域受到越来越多的关注。
人类行为可以使用各种数据模态来表示,如 RGB、骨架、深度、红外序列、点云、事件流、音频、加速信号、雷达和 WiFi,这些数据模态在不同的场景下具有不同的优势。本文研究者
基于主流深度学习,对当前基于深度学习的行为识别方法进行了全面的综述,涉及多种数据模态。
![]()
论文链接:https://arxiv.org/pdf/2012.11866
(1)该论文回顾了基于单模态的行为识别方法,这些模态包括 RGB、骨架、深度、红外序列、点云、事件流、音频、加速信号、雷达和 WiFi。
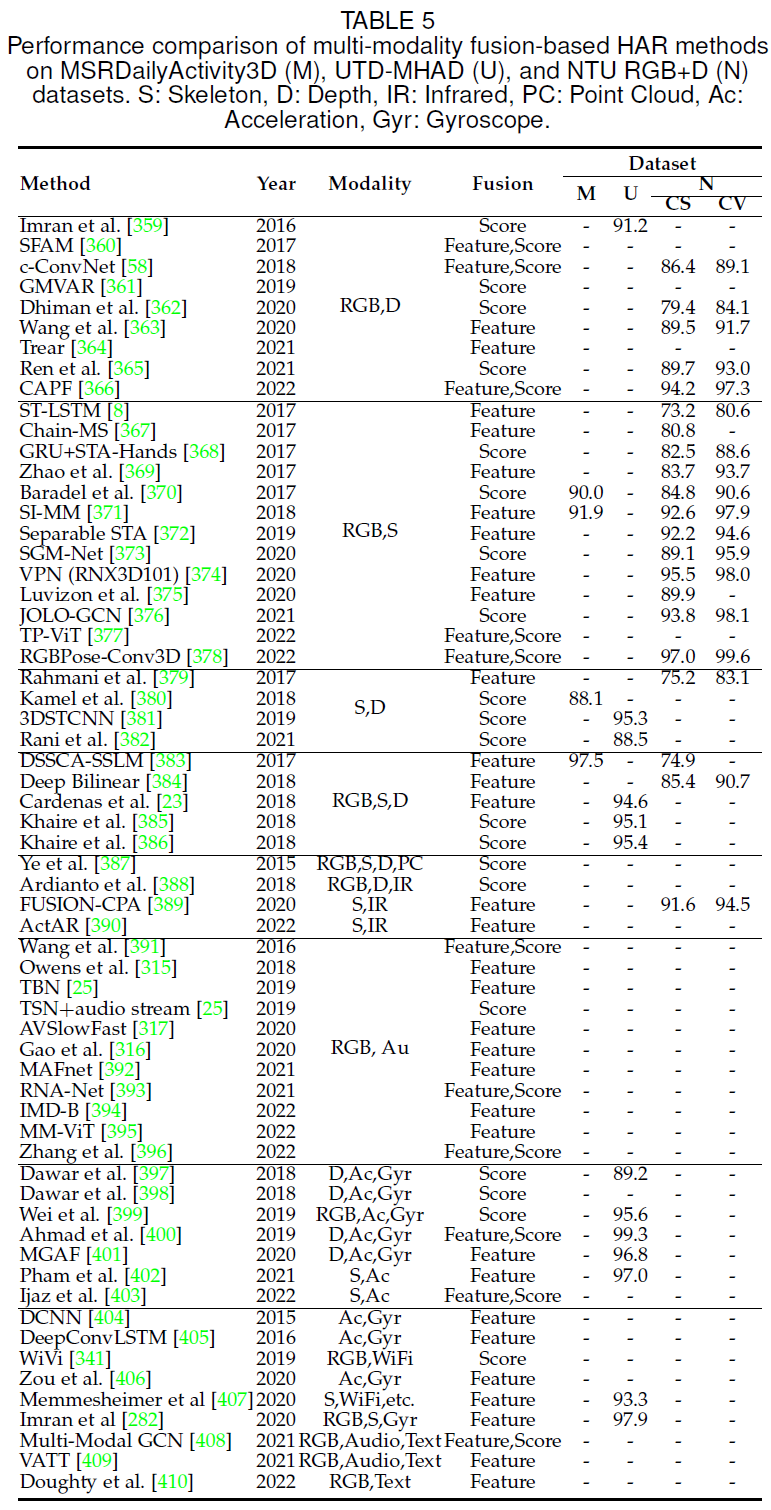
(2)该论文回顾了基于多模态的行为识别方法,并将其分为多模态融合和跨模态协同学习两种类型。
(3)该论文回顾了最新和最先进的深度学习方法,包括 CNN、RNN、GCN 和 Transformer,并在几个基准数据集上对现有方法及其性能进行了全面比较。
本文主要回顾了基于 RGB、骨架、深度、红外序列、点云、事件流、音频、加速信号、雷达和 WiFi 模态的行为识别方法。此外,角速度、射频、肌电图等数据模态也可被用于行为识别。
![]()
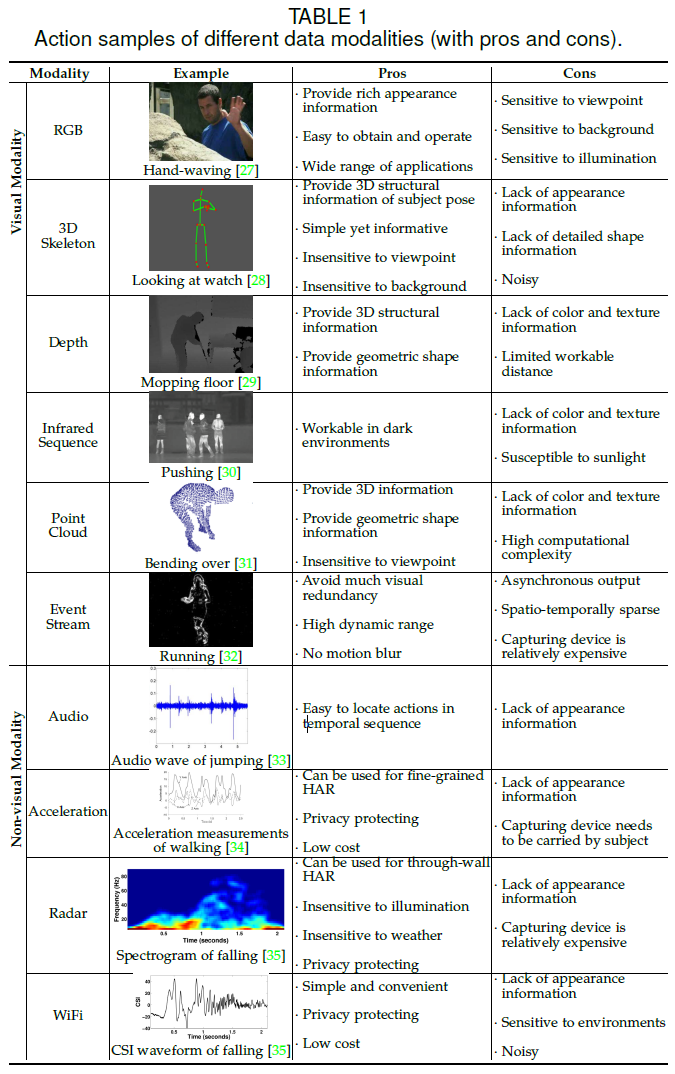
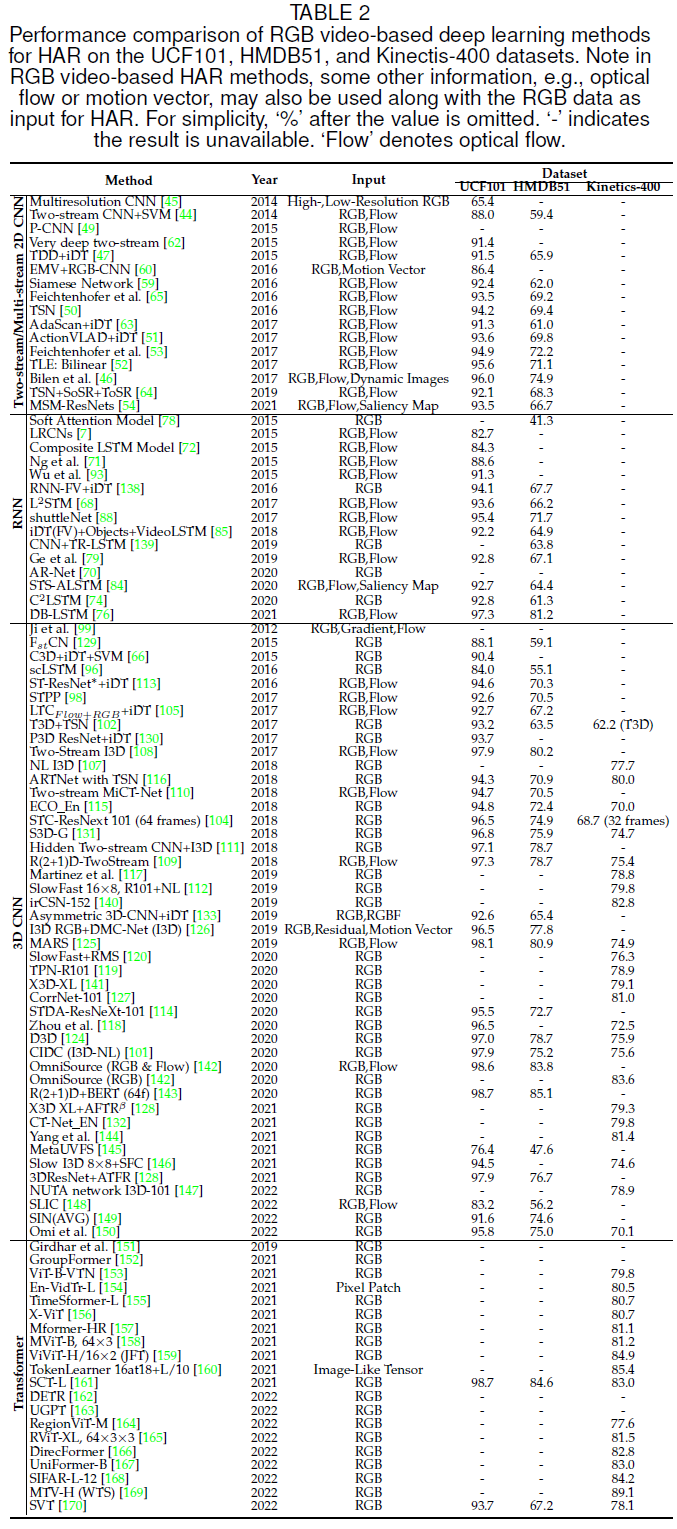
(1)RGB 视频:行为识别领域中最常见的数据模态,被广泛地应用于视觉监视、自主导航等应用中。RGB 模态包含了丰富的场景上下文外观信息,但易于受到背景、视角、人体尺度和照明条件变化的影响。对于 RGB 模态,最常见的四类深度学习网络是双流 2D CNN,RNN,3D CNN,和 Transformer。
![]()
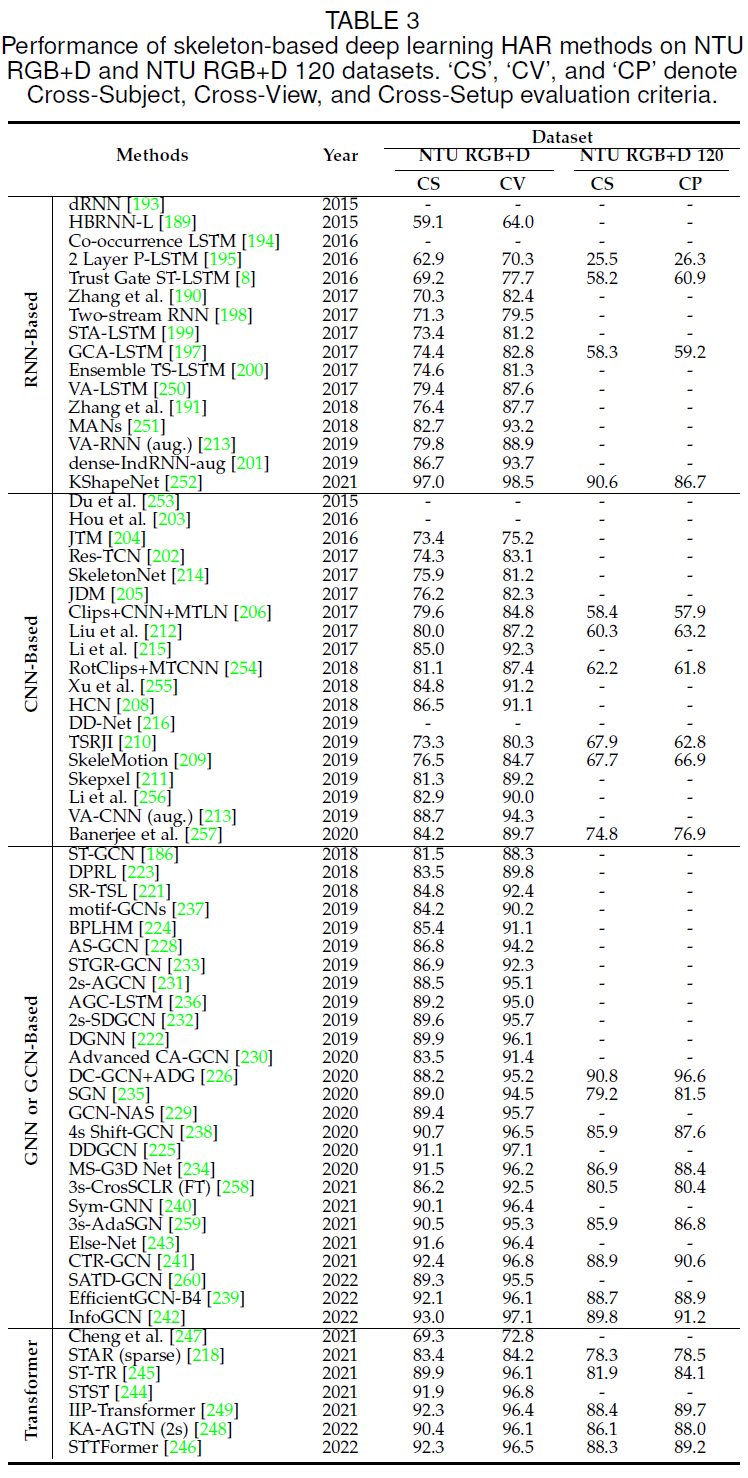
(2)骨架序列:编码人体关节的轨迹,当动作执行不涉及物体或场景上下文时简洁高效,具有尺度不变性、对纹理和背景变化的鲁棒性。对于骨架模态,最常见的四类深度学习网络是 CNN,RNN,GCN,和 Transformer。
![]()
(3)深度图:本质是将 3D 数据转换为 2D 图像,提供了可靠的人体三维结构和几何形状信息,对颜色和纹理的变化具有鲁棒性。
(4)红外序列:不依赖外部环境光,适用于黑暗环境中的行为识别。
(5)点云:获取目标的三维结构和距离信息,在机器人导航和自动驾驶中得到广泛应用。点云由大量的点集合组成,这些点代表了在空间参考系统下目标的空间分布和表面特征,具有很强的空间轮廓和三维几何形状表征能力,因此适用于行为识别研究。
(6)事件流:事件相机,也被称为神经形态相机或动态视觉传感器,可以捕捉光照变化,并独立地为每个像素产生异步事件输出。因此,事件流数据保留了主体的运动信息,避免过多的背景视觉冗余。
(7)音频:是视频数据任务十分流行的辅助模态。由于视觉和音频流之间的同步,音频数据可以提供额外信息,并且可以用于定位动作,以减少人类标记工作和减少计算成本。
(8)加速信号:通常由 IMU 传感器获取,用于细粒度和多模态的行为识别。
(9)雷达:雷达高频率和短波长的信号使得其可用于细粒度的感知任务。雷达频谱图对光照和天气条件变化具有鲁棒性,保护隐私,可用于穿越墙壁的行为识别。
(10)WiFi:最常见室内无线信号类型之一,主要利用信道状态信息 (CSI) 的变化进行行为识别的感知任务。
在现实生活中,人们往往以多种认知方式感知环境。同样,多模态机器学习是一种旨在处理和关联来自多个模态信息的建模方法。通过综合各种数据模态的优势和能力,多模态机器学习通常可以提供更健壮和更准确的行为识别结果。多模态学习方法主要分为两种,即融合和协同学习。
融合是指将来自两种或两种以上模态的信息整合进行训练和推理,例如,音频数据可以作为骨架模态的补充信息来区分 “拍盘子” 和“拍袋子”动作。
![]()
协同学习是指不同数据模态之间的知识迁移,例如,骨架数据可以作为辅助模态,使模型能够从 RGB 视频中为行为识别提取更多的判别特征。同时,协同学习还适用于现实生活中某些模态缺失的情况。
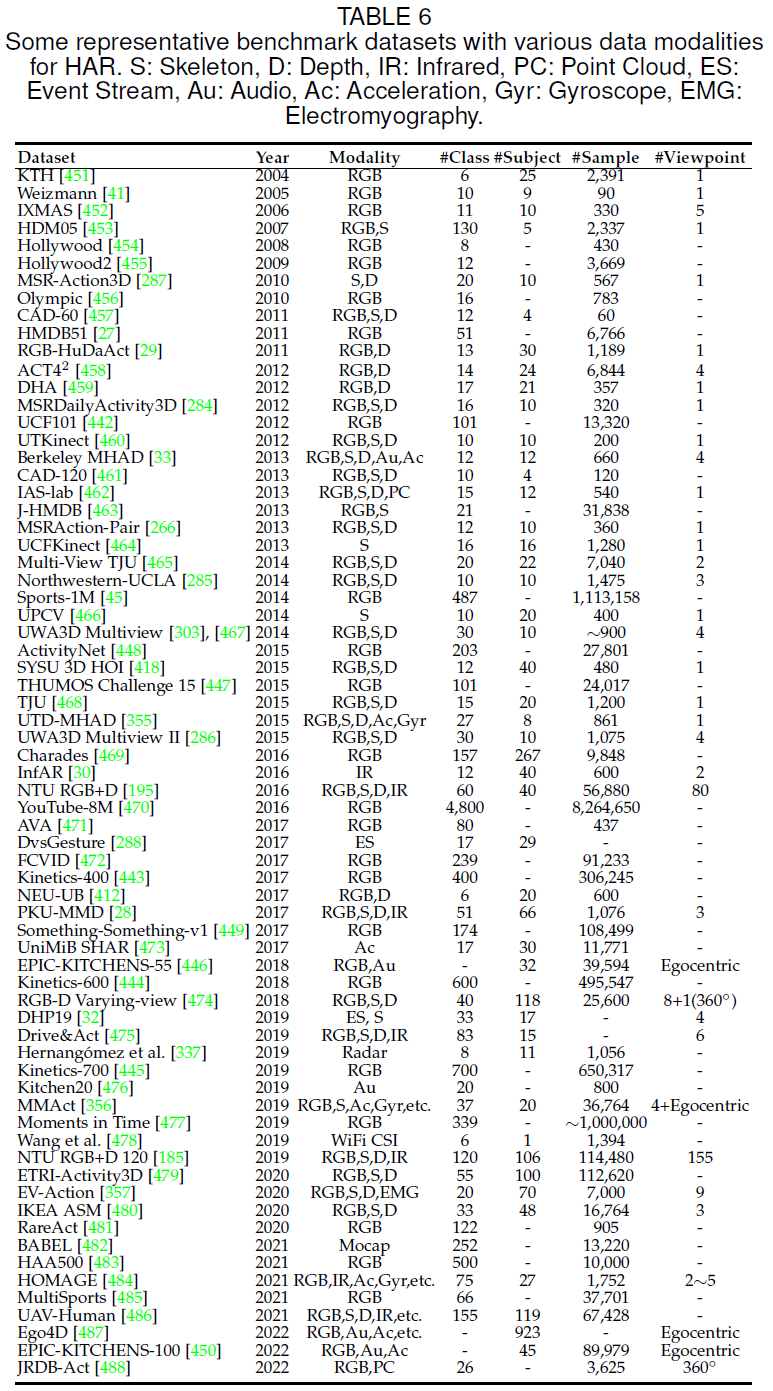
近些年来,大量的行为识别数据集被提出以训练和评估各种方法,该论文总结了适用于不同模态的基准数据集,并提供了其相关属性。
![]()
行为识别是近些年来备受关注的重要研究领域,各种具有不同特征的数据模态被研究使用。虽然已有大量的行为识别工作被提出,但在(1)数据集、(2)多模态学习、(3)低成本计算、(4)动作预测、(5)小样本学习、(6)非监督和半监督学习等方面仍需要进一步的探索,坚信行为识别将在未来发挥更加关键的作用。
作者拟对此论文的 arXiv 版本每年进行定期更新,以覆盖人类行为识别领域的最新进展。
![]()
© THE END
转载请联系本公众号获得授权
投稿或寻求报道:content@jiqizhixin.com