
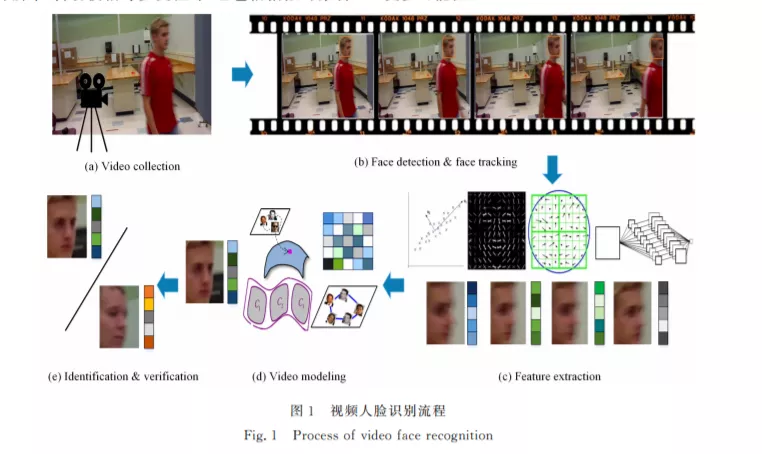
摘要: 人脸识别是生物特征识别领域的一项关键技术,长期以来得到研究者的广泛关注。视频人脸识别任务特指从一段视频中提取出人脸的关键信息,从而完成身份识别。相较于基于图像的人脸识别任务来说,视频数据中的人脸变化模式更为多样且视频帧之间存在较大差异,如何从冗长而复杂的视频中抽取到人脸的关键特征成为当前的研究重点。以视频人脸识别技术为研究对象,首先介绍了该技术的研究价值和存在的挑战;接着对当前研究工作的发展脉络进行了系统的梳理,依据建模方式将传统基于图像集合建模的方法分为线性子空间建模、仿射子空间建模、非线性流形建模、统计建模四大类,同时对深度学习背景下基于图像融合的方法进行了介绍;另外对现有视频人脸识别数据集进行分类整理并简要介绍了常用的评价指标;最后分别采用灰度特征和深度特征在YTC数据集及IJB-A数据集上对代表性工作进行评测。实验结果表明:神经网络可以从大规模数据中提取到鲁棒的视频帧特征,从而带来识别性能的大幅提升,而有效的视频数据建模能够挖掘出人脸潜在的变化模式,从视频序列包含的大量样本中找到更具判别力的关键信息,排除噪声样本的干扰,因此基于视频的人脸识别具有广泛的通用性和实用价值。
成为VIP会员查看完整内容
相关内容


相关资讯