从 Word2Vec 到 BERT

作者丨张寒
学校丨复旦大学硕士生
研究方向丨自然语言处理
如果读完本文你觉得对数学公式很懵,强烈建议去 Jay Alammar 的博客看一下,他的博客主要是对每个概念做可视化的,看了会茅塞顿开,简直是宝藏!每篇文章我也会放上他相对应的概念的地址。
Word2Vec
The Illustrated Word2Vec:
“You shall know a word by the company it keeps” (J. R. Firth 1957: 11)
Language Models
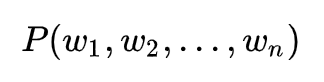
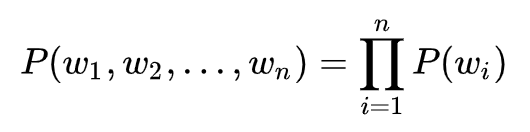
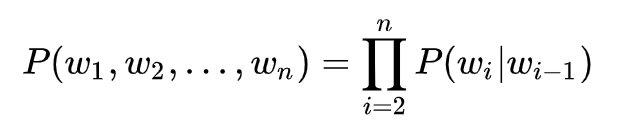
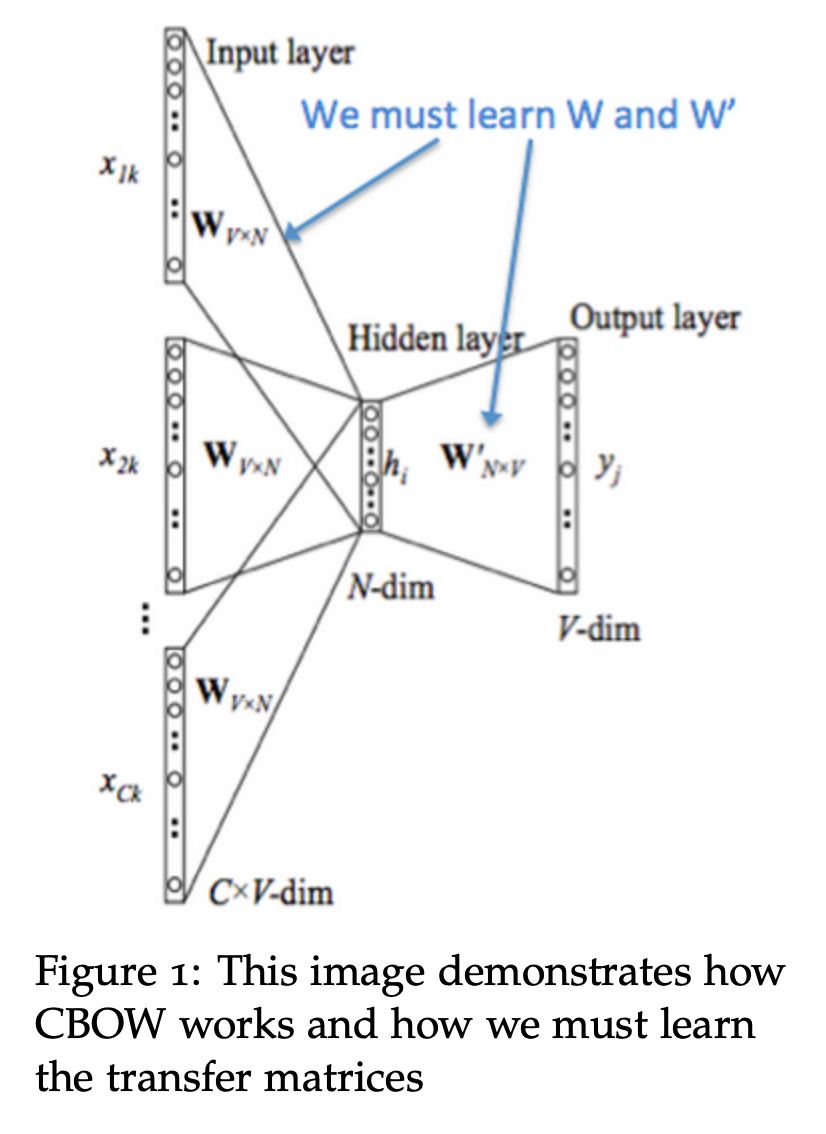
CBOW
在前面举的例子中,对于句子“The cat jumped over the puddle”,我们把 {“The", "cat","over","the","puddle"} 当作上下文,把“jumped”当作中心词,这样的一种模型叫做 Continuous Bag of Words (CBOW) Model。
我们创建两个矩阵,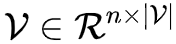
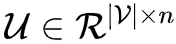
下面我们来具体看看 CBOW 是怎么做的:
1. 首先我们生成大小为 m 的上下文词的 one-hot 向量表示: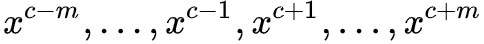
2. 通过与 V 矩阵相乘,得到每一个上下文词的词向量表示,即:
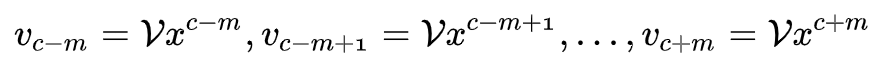
3. 对所有的上述向量做平均,得到:
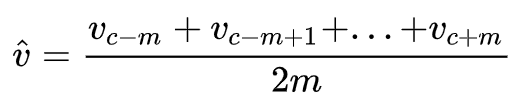
4. 通过这个均值向量和 U 矩阵相乘,去得到一个”分数向量“,即,因为相似向量的点乘结果是很高的,所以优化模型时就会把相似词的向量表示越来越靠近,去得到一个高的分数;
5. 把分数转变成概率表示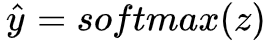
6. 我们希望产生的这个概率分布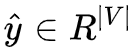
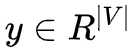
以上就是在我们如果有 V, U 矩阵时,模型是如何工作的,那么怎么得到这个两个矩阵呢?首先建立一个目标函数,这里使用交叉熵:
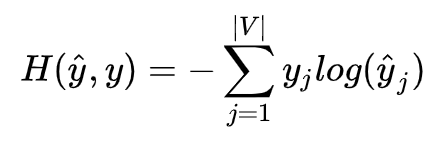
实际上 y 是 One-hot 向量,所以可以简化为:
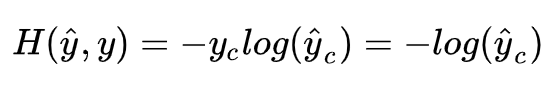
而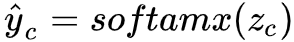
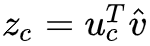
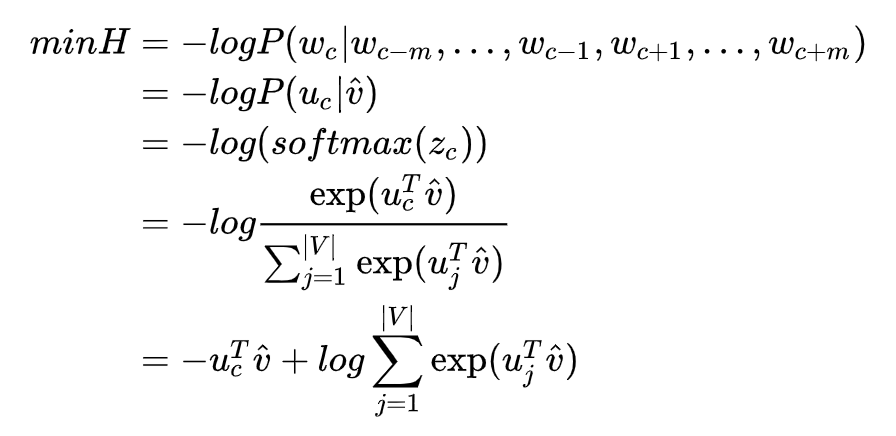
接下来用 SGD 优化目标函数,去更新所有相关的词向量和
:
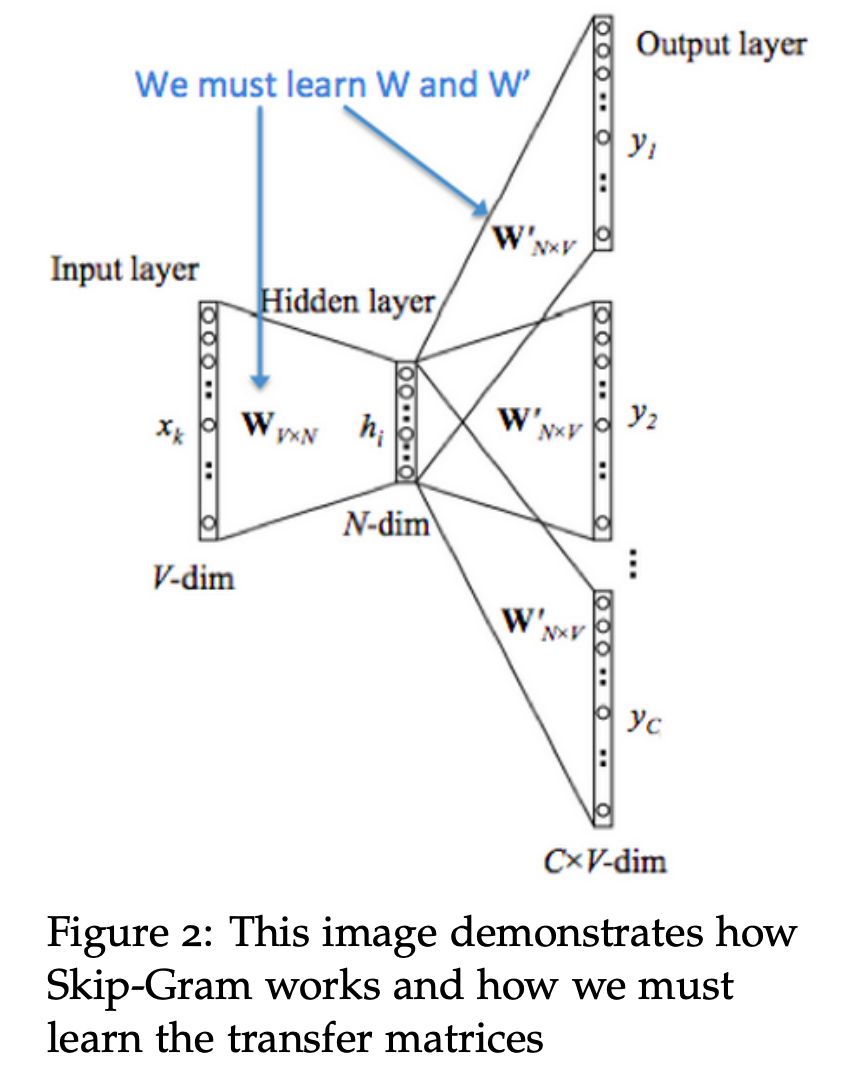
Skip-gram
另一种方法是给定中心词"jumped",模型会去预测或者生成周围的上下文词,这种模型叫做 Skip-gram model,SG 和 CBOW 是完全反过来的模型,我们首先有一个中心词的 one-hot 向量表示 x,然后输出词的向量表示是,U, V 矩阵和前面 CBOW 中一样:
1. 首先生成中心词的 ont-hot 向量,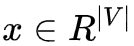
2. 通过和 V 矩阵相乘得到中心词的词向量表示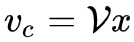
3. 通过和 U 矩阵相乘得到“分数向量”,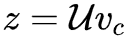
4. 把“分数”转变成概率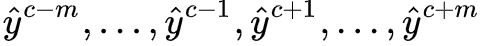
5. 我们希望以上结果,跟真实概率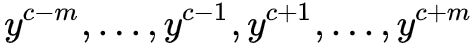
不同于 CBOW,SG 在生成目标函数的时候用了一个假设,假设给定中心词,所有输出的词都是完全独立的。
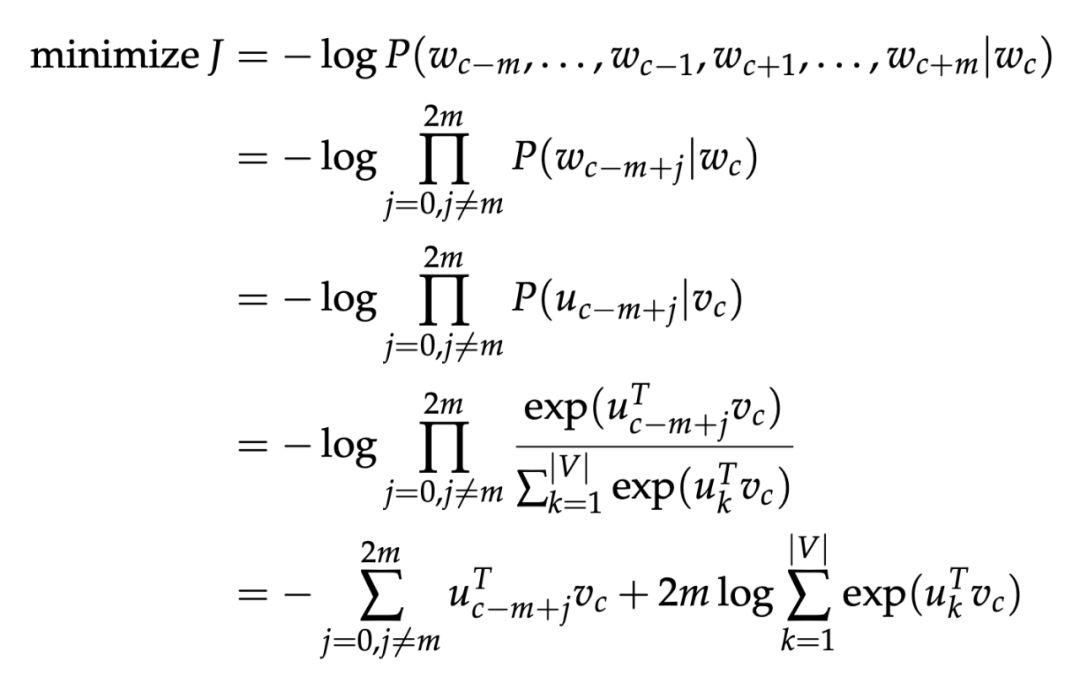
通过这样的目标函数,用 SGD 去迭代更新参数,同时目标函数也可以记为:
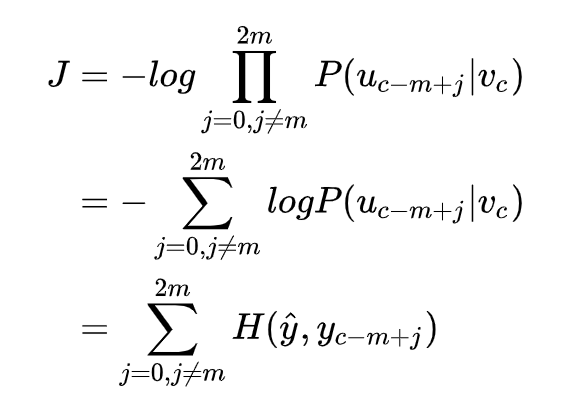
Optimization Method
Mikolov 对于 SG 的评价是这些公式是“impractical”的,他的言下之意是计算复杂度依然和词典大小有关,而这通常都意味着非常非常大,于是在论文 [2] 中首先提到了 Hierachical Softmax,基本思想就是首先将词典中的每个词按照词频大小构建出一棵 Huffman 树,保证词频较大的词处于相对比较浅的层,词频较低的词相应的处于 Huffman 树较深层的叶子节点,每一个词都处于这棵 Huffman 树上的某个叶子节点。
接着提出了 Negative Sampling 负采样的思想,普通 softmax 的计算量太大就是因为它把词典中所有其他非目标词都当做负例了,而负采样的思想特别简单,就是每次按照一定概率随机采样一些词当做负例,从而就只需要计算这些负采样出来的负例了。
对于 SG,新的目标函数变成了:
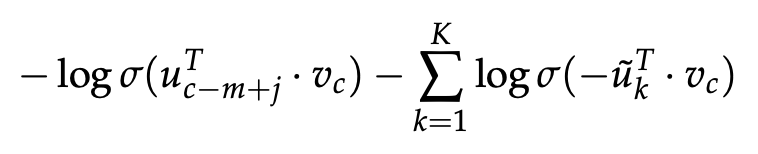
对于 CBOW,新的目标函数变成了:
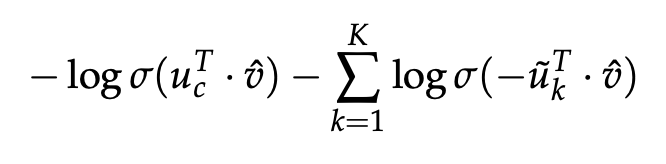
仔细和普通 softmax 进行比较便会发现,将原来的 |V| 分类问题变成了 K 分类问题,这便把词典大小对时间复杂度的影响变成了一个常数项。
GloVe
上述 word2vec 方法,缺点是基于固定大小的窗口,对局部的语料进行特征提取,其实在 word2ve c出现之前, LSA(Latent Semantic Analysis)是一种比较早的 count-based 的词向量表征工具,它也是基于 co-occurance matrix 的,只不过采用了基于奇异值分解(SVD)的矩阵分解技术对大矩阵进行降维,而我们知道 SVD 的复杂度是很高的,所以它的计算代价比较大。还有一点是它对所有单词的统计权重都是一致的 ,而 GloVe 就结合了两者的优点。
GloVe 的实现:
1. 首先根据语料库去构建一个 co-ocurrence matrix 共现矩阵,其中每一个元素代表单词和上下文词在特定的上下文窗口内共同出现的次数,并且 GloVe 还提出了一个 decreasing weighting ,就是基于两个词在上下文窗口中的距离 d,去给一个权重 1/d,也就是说距离远的两个词,占总计数的权重就小;
2. 构建词向量和共现矩阵之间的近似关系,目标函数为:
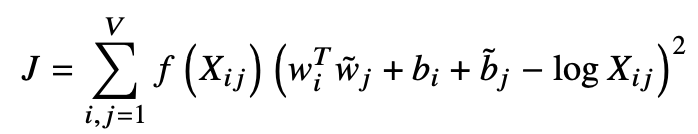
其中:
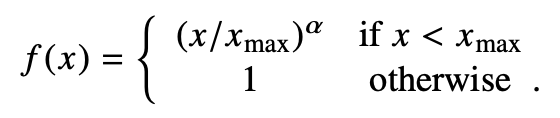
这个目标函数基本形式就是简单的 mean square loss,只不过多了一个权重函数,感兴趣的话 [3] 中可以看下作者是怎么得到这个公式的。
word2vec 的方法极大的促进了 NLP 的发展,利用预训练好的词向量来初始化网络结构的第一层几乎已经成了标配,尤其是在只有少量监督数据的情况下,如果不拿预训练的 embedding 初始化第一层,要么你是土豪,可以有大量的人工去标注数据,要么就是在蛮干。word2vec 开启了一种全新的 NLP 模型训练方式,迁移学习。
Reference
Transformer
The Illustrated Transformer:
Seq2Seq + Attention
在说明 Transformer 之前,还是有必要简述一下 attention 机制,RNN, LSTM, Seq2Seq 就不再赘述。
我们知道 Seq2Seq 是由一个 encoder 和一个 decoder 构成, 编码器负责把源序列编码成向量,解码器是一个语言模型,负责根据编码的信息生成目标序列 。这个结构的问题在于,编码器需要把整个 Source sentence 的信息全部编码起来,这是 seq2seq 架构的瓶颈所在,attention 机制就是解决这个瓶颈的一种方法,Attention 机制的核心想法就是:在解码器的每一个时间步,都和编码器直接连接,然后只关注 source sentence 中的特定的一部分。
假设编码器的 hidden states 分别为
,我们通过点乘得到当前时间步的 attention scores:
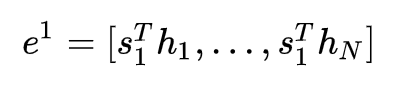
再通过 softmax 转换成 attention distribution(是一个概率分布,和为 1):
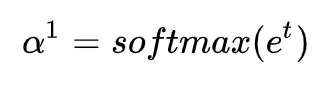
然后用这个概率分布去和编码器的所有 hidden states 加权求和,得到 attention output:
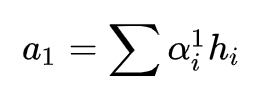
最后把 attention output 和解码器的 hidden state 合并起来得到,然后去执行不用 attention 机制的 seq2seq 一样的做法就好了。
这样就得到了解码器的第一个时间步的输出,后面以此类推,每一个时间步都会去“看一下”source sentence,去决定对哪一部分给予比较大的 attention。
这就是 seq2seq+attention 机制的概念,然后这样的结构终归是要按照序列顺序去 encoding 的,不好做分布式的计算,于是有了直接抛弃 RNN,LSTM 的 self-attention 机制,以及应用了这个机制的 Transformer [1]。
Transformer Architecture
大多数有效的处理序列的模型都是基于 encoder-decoder 架构的,给定序列 x,经过 encoder 编码成隐藏向量 z,再通过 decoder 每个时间步的去生成序列 y,Transformer 通过在 encoder 和 decoder 中都使用堆叠的 self-attention 和 point-wise 和全连接层,来延续了这样的整体架构:
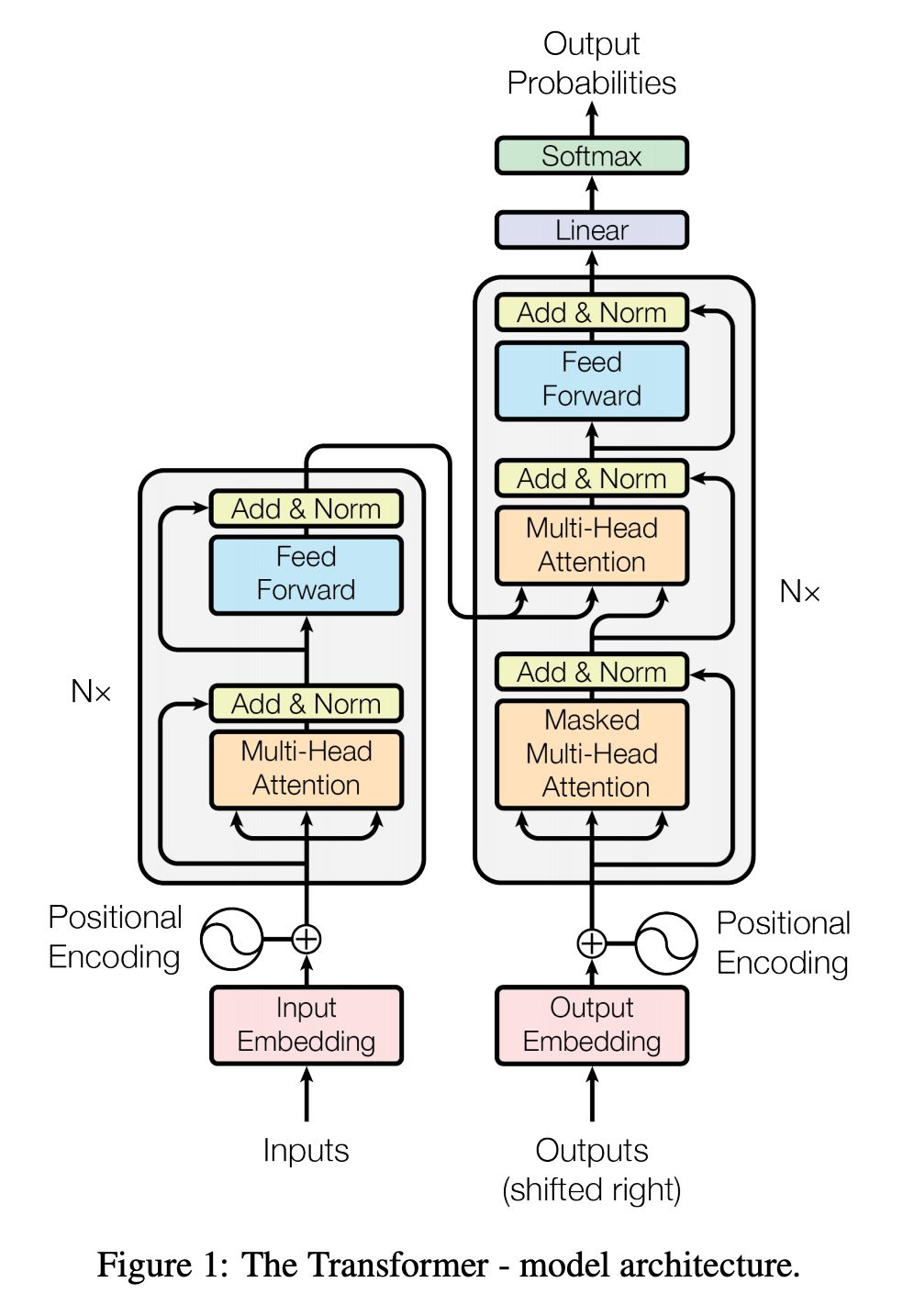
Encoder and Decoder Stacks
Encoder:编码器是由 6 个相同的层组成,每一层有两个子层,第一个子层是一个 Multi-head self-attention 机制,第二层是一个简单的,位置对应的全连接神经网络,还加入了每一个子层都加入了残差网络 + normalization 层,所以每一个子层的输出其实可以看作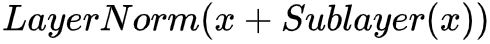
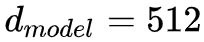
Decoder:解码器也是由 6 个相同的层组成,在编码器的那两个子层的基础上又加入了一个层,用于对 encoder 的输出做 multi-head attention,和 encoder 一样,每一个子层也都加入了残差结构和标准化层,还加入 mask 操作。
Decoder 的 attention 实际上包含两部分,第一部分是带有 mask 的 Self-attention,通过 mask 的作用将 decode 阶段的 attention 限定只会 attention 到已经生成过的词上,因此叫做 Mask Self-attention;第二部分是普通的 Self-attention 操作,不过这个时候的 K 和 V 矩阵已经替换为 Encoder 的输出结果,所以本质上并不是一个 Self-attention 了,self-attention 的 Q, K, V 都来自于自身。
不懂没关系,下面来详细剖析下 Transformer 的结构:
首先把 input sentence 做 input embedding 后的结果当作输入给第一个 encoder,这里有一个 positional encoding 稍后再说,那么到达第一个 encoder 的第一个 sub-layer,下面我们先说下什么是 Self-Attention。
Self-Attention in Detail
一个 attention 内部机制可以看作一个 query,应用到一组 key-value 对上的操作,其中一个 query 和所有 keys, values 都是向量,结果可以看作是对 values 的加权求和,其中每个 value 的权重是通过当前 query 和对应的 key 做点乘得到的(Scaled Dot-Product Attention), 而 Multi-Head Attention 就是多个 attention layer 并行计算的。
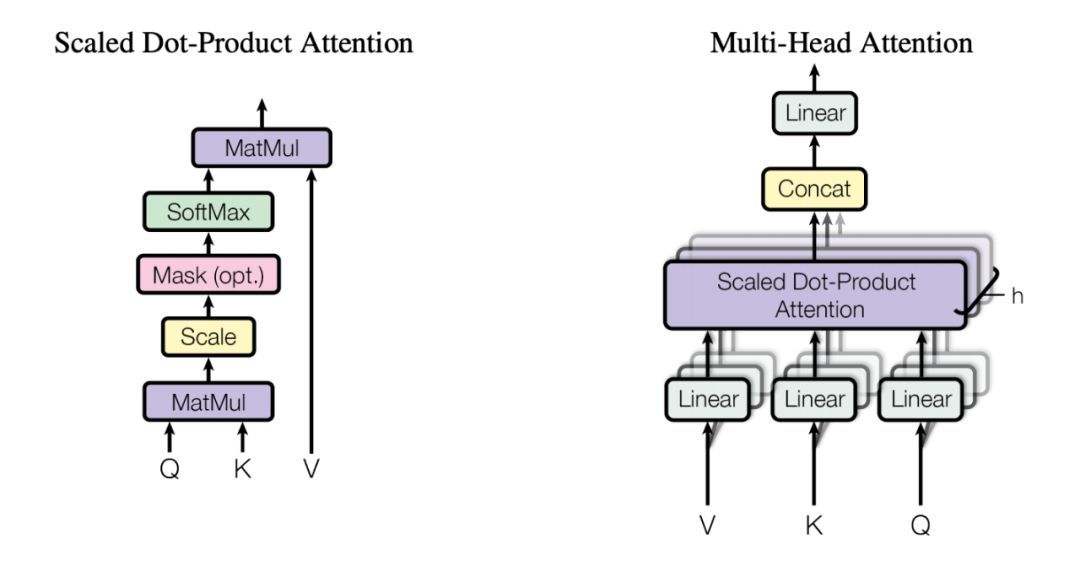
接下来首先看单个 self-attention 如何使用这些向量去计算:
1. 第 1 步,为每一个 encoder 的输入向量 x 创建 3 个向量,分别为 query, key, value,怎么来的呢?就是用输入向量和三个权重矩阵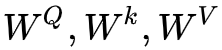
2. 第 2 步是计算“分数”,假设我们在计算 self-attention 中的第一个词,这时我们要计算输入序列中所有其他词和第一个词之间的“分数”,“分数”决定了我们在 encode 第一个词的时候,对其他词分别给多少的“关注度”,“分数”是通过 q, k 的点乘计算的,比如当在 encode 第一个词时,就需要把 q1 和每一个位置的 k 点乘,得到“分数”矩阵,如第一个分数是 q1k1,第二个分数是 q1k2......;
3. 第 3、4 步是把分数除以,即除以 k 向量的维度开根号,paper 中用的
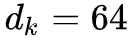
4. 第 5 步,把 softmax score 和每一个 value 向量相乘,目的是保留一些想要关注的部分,抛弃不相关的部分,比如乘 0.0001;
5. 第 6 步,把上述加权 value 向量求和,这样就得到了 self-attention 层的在当前位置的输出(比如第一个词)。
实际的使用中,往往输入的是一个矩阵 X,那么把 q, k, v 都换成矩阵就好了记一组 queries 为矩阵 Q,keys 和 values 也表示成矩阵和,我们的输出可以记为:
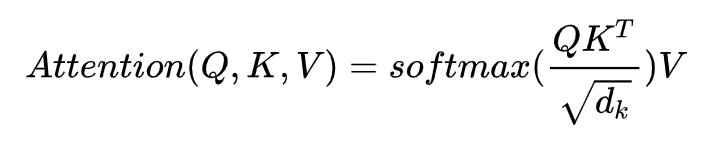
Multi-Head Attention
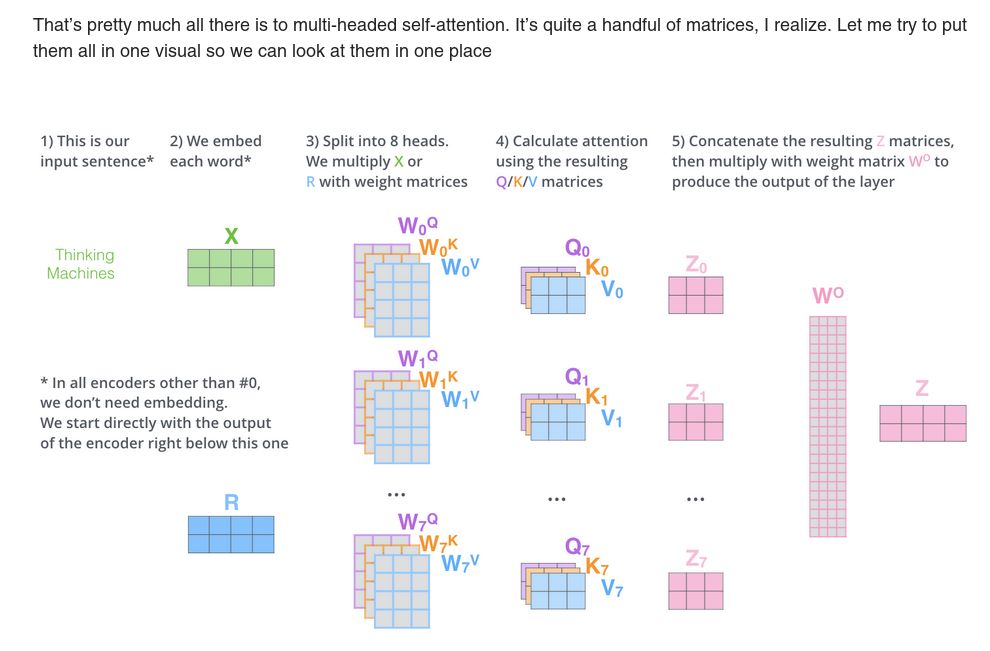
作者还介绍了一种 Multi-head attention 机制,这个机制在两个方面提升了表现:
1. 它扩展了模型关注不同的位置的能力。确实,在前面单个词的例子中已经说过,对第一个词得到的结果 z1,虽然也能给每一个词一些权重,但是显然是它自己的权重最大,这个在翻译比如:“ The animal didn’t cross the street because it was too tired ”时有用,我们想知道“it”指代的是谁;
2. 它给了 attention layer 多个“表示子空间”,Multi-head attention 不是一组,而是多组
用这样的机制,我们得到了 8 个不同的 Z 输出矩阵,然后下一个 deed-forward layer 只接受一个矩阵(每一行是一个词的向量),所以我们这样处理:
直接把 8 个输出矩阵拼接起来,再与一个权重矩阵 WO 相乘,得到一个输出矩阵,这个句子收集到了所有 attention heads 的信息,我们把这个发给后面的 FFNN。
整个流程如下图:
The Residuals and Normalization Layer
至此我们以及知道第一个 encoder 的第一个 sub-layer 里 Multi-head attention 是怎么回事,接下来以上生成的 Z 矩阵还要通过一个残差 + normalization 层,所以第一个子层的输出其实可以看作 LayerNorm (x+MultiHead(x))。
再接下来到第二个 sub-layer,是一个 Feed Forward Neural Netword,加上跟第一个子层相同的残差 + normalization 层,所以第二个子层可以看作 LayerNorm (x+FFNN(x)),这里值得注意的是,全连接层对于 Z 矩阵中的每一个向量是分布式进行的,不过权重是一样的,下图很好的说明了这一点:
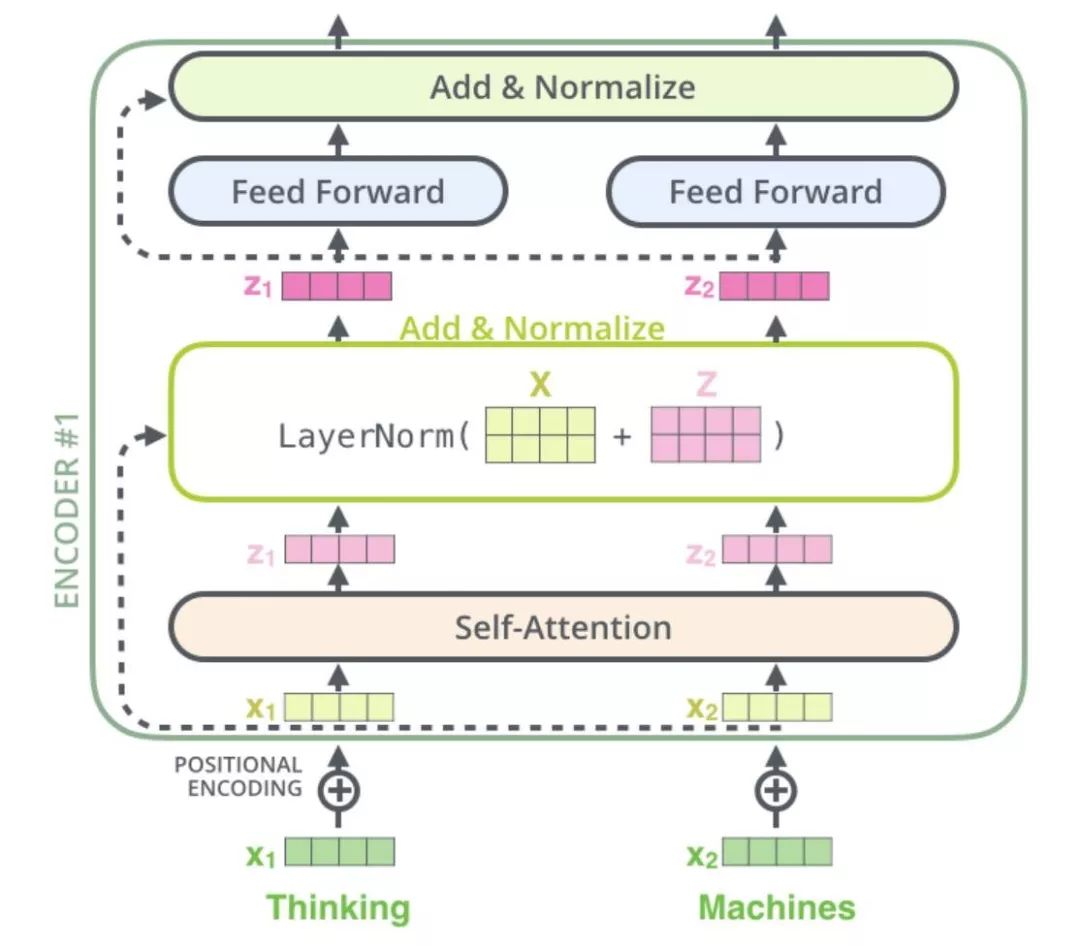
现在我们已经完全缕清第一个 encoder 是怎么样进行的,后面的 5 个 encoder 都以此类推,到最后一个 encoder 产生的结果,会被 decoder 使用,至此 encoding 部分结束,接下来看 decoding 才是重头戏。
decoder 首先接受第一个输入,一般是一个起始符例如 </s>,这是来到第一个 decoder 的第一个 sub-layer,这里跟前面说的 encoder 的 Multi-Head Attention,都属于 self-attention,区别是这里加了一个 Mask 操作,让输出序列只能基于当前位置的前面的序列做预测,具体做法是给后面序列一个负无穷的分数,这样在计算 softmax 时就是 0。
到了第一个 decoder 的第二个 sub-layer,这里的“Encoder-Decoder Attention”layer,实际上不属于 self attention,因为它的 queries 来自下面的 sub-layer 的输出,而 keys 和 values 来自 encoder 的输出 Z,Z 会 transformed into a set of K, V,提供给 6 个的每一个 decoder 中间的“Encoder-Decoder Attention”layer 使用。
接下来第一个 decoder 的 FFNN 层,和前面 encoder 的一样,不再赘述。
至此一个 decoder 的内部结构结束,重复 6 个一样的 decoder 后,来到了最后的 Linear and Softmax Layer。
The Final Linear and Softmax Layer
The Linear layer 是一个简单的全连接神经网络,把 decoders 生成的输出,映射到一个很大的向量,叫做 Logits vector。
假设模型训练集有 10000 个唯一的英文单词,那 Logits vector 就有 10000 个单元,每个单元表示唯一单词的分数,再经过一个 softmax 层,把分数转变成概率,最高概率的单词将被选择出来,作为当前时间步的输出。
Positional Encoding
补充一点前面没说的,已我们前面叙述的做法,input sentence 的顺序信息被完全忽略了,然而往往这个信息还是很有用的,所以加入了一个 positional encoding 机制,即给每个 input embedding 在额外加上一个位置向量,位置向量会在词向量中加入了单词的位置信息,这样 Transformer 就能区分不同位置的单词了。
这个位置向量怎么来呢?有两种办法:1)基于数据去学习;2)自己设计编码规则,作者采用的是第二种,给出的是如下公式:
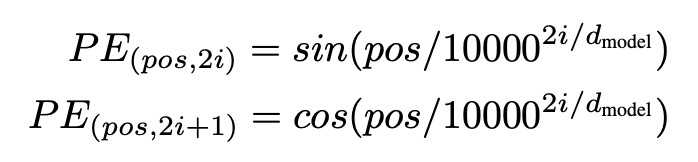
至于实现可以去 Google 开源的 tensor2tensor 里的 get_timing_signal_1d() 函数去找:
https://github.com/tensorflow/tensor2tensor/blob/23bd23b9830059fbc349381b70d9429b5c40a139/tensor2tensor/layers/common_attention.py
结论
Reference
BERT
The Illustrated BERT:
Introduction
BERT
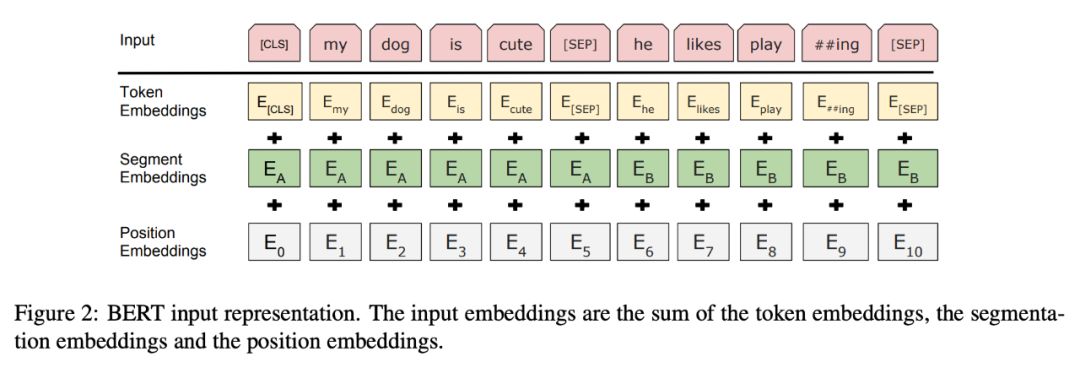
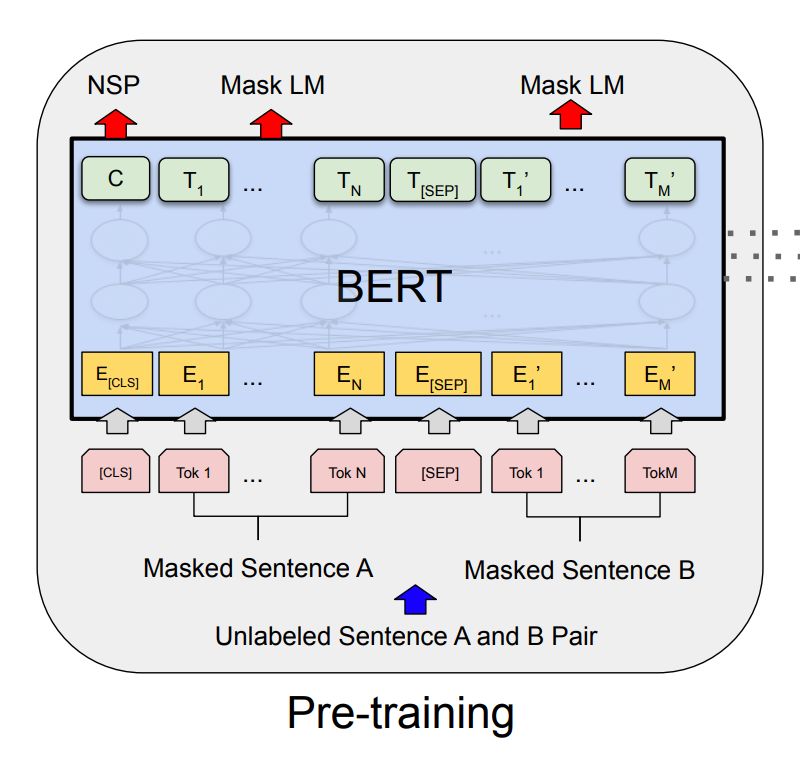
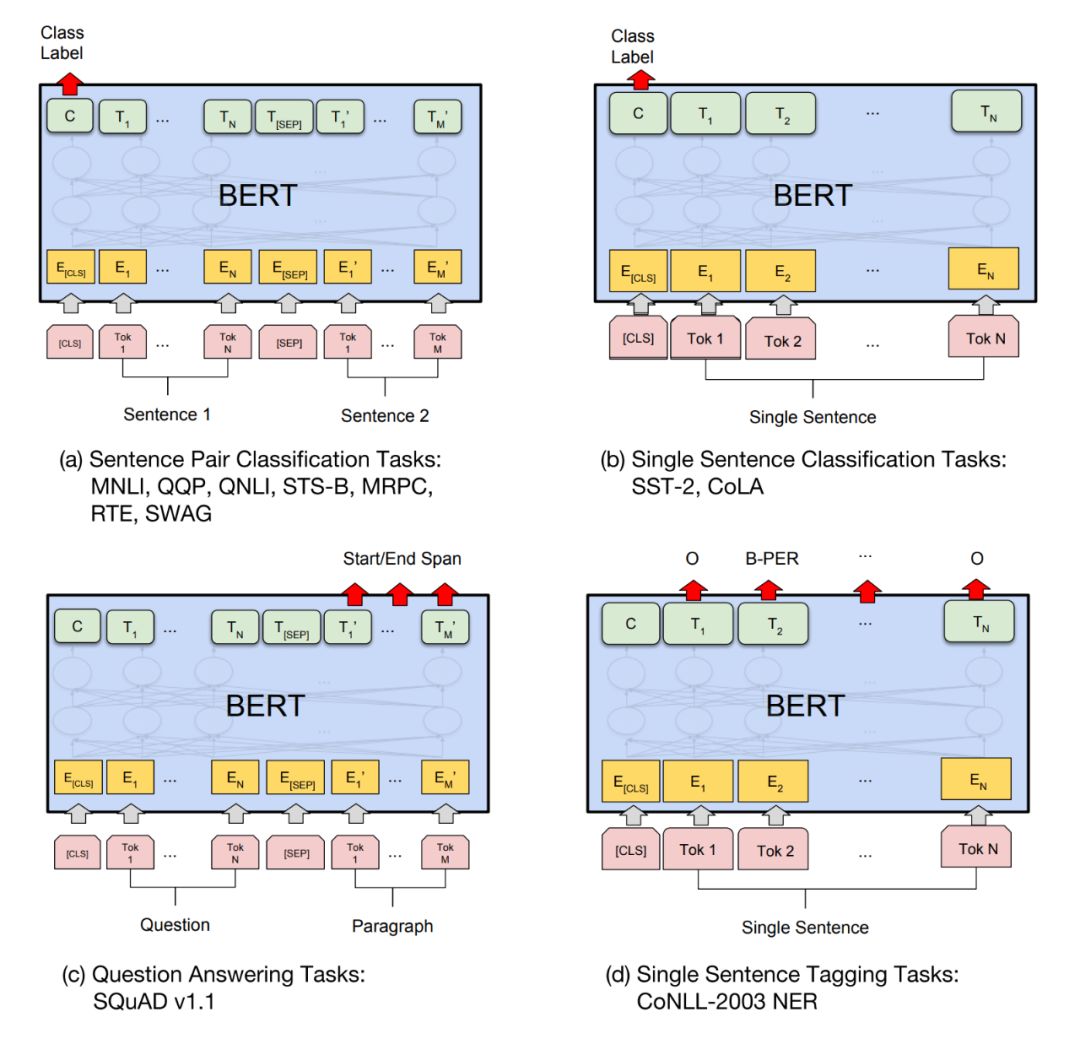
然后微调很简单,因为 Transformer 中的 self-attention 机制允许 BERT 通过改变适当的输入和输出来对许多下游任务(无论它们涉及单个文本还是文本对)进行建模。
结论

点击以下标题查看更多往期内容:

让你的论文被更多人看到
如何才能让更多的优质内容以更短路径到达读者群体,缩短读者寻找优质内容的成本呢?答案就是:你不认识的人。
总有一些你不认识的人,知道你想知道的东西。PaperWeekly 或许可以成为一座桥梁,促使不同背景、不同方向的学者和学术灵感相互碰撞,迸发出更多的可能性。
PaperWeekly 鼓励高校实验室或个人,在我们的平台上分享各类优质内容,可以是最新论文解读,也可以是学习心得或技术干货。我们的目的只有一个,让知识真正流动起来。
📝 来稿标准:
• 稿件确系个人原创作品,来稿需注明作者个人信息(姓名+学校/工作单位+学历/职位+研究方向)
• 如果文章并非首发,请在投稿时提醒并附上所有已发布链接
• PaperWeekly 默认每篇文章都是首发,均会添加“原创”标志
📬 投稿邮箱:
• 投稿邮箱:hr@paperweekly.site
• 所有文章配图,请单独在附件中发送
• 请留下即时联系方式(微信或手机),以便我们在编辑发布时和作者沟通
🔍
现在,在「知乎」也能找到我们了
进入知乎首页搜索「PaperWeekly」
点击「关注」订阅我们的专栏吧
关于PaperWeekly
PaperWeekly 是一个推荐、解读、讨论、报道人工智能前沿论文成果的学术平台。如果你研究或从事 AI 领域,欢迎在公众号后台点击「交流群」,小助手将把你带入 PaperWeekly 的交流群里。

▽ 点击 | 阅读原文 | 获取最新论文推荐




