CVPR 2020丨更准确的弱监督视频动作定位,从生成注意力模型出发

编者按:爆发式增长的海量热门视频正在对视频处理技术提出更高的要求,弱监督学习因此越来越重要。针对弱监督动作定位中的关键问题,微软亚洲研究院提出了一种新的思路,从特征表示的角度捕捉上下文和动作片段的区别,进一步提高了动作定位效果。
5月14日(下周四),微软亚洲研究院将在线上举办 CVPR 2020 论文分享会,微软亚洲研究院主管研究员戴琦也将作为嘉宾,与大家分享交流本篇论文的技术细节。
视频作为新兴媒体的流量担当,已成为人们获取外界信息的重要媒介之一。从 YouTube 等视频分享网站到各大短视频平台,每分钟视频的播放量、上传量正在经历爆炸式的增长。其对视频处理技术的要求也水涨船高,如何自动提取、理解视频的主要内容,对于下游的内容标注、推荐系统等一系列任务有着重要意义。其中,视频中人的动作和行为就是主要关注点之一。动作定位就是让机器自动识别视频中发生的动作和时间的一个任务。
目前很多算法都专注于全监督的动作定位,即依赖人工标注数据集中视频的动作类别与发生时间来监督模型的训练。然而,由于一段视频中动作数量很多,一一标注出起始与结束时间十分费力。
于是,弱监督动作定位愈发受到关注:如果只有视频的动作类别标签,而没有时间的标注,模型该如何学会定位动作对应的时间呢?微软亚洲研究院在 CVPR 2020 发表的最新研究成果 “Weakly-Supervised Action Localization by Generative Attention Modeling” 为解决该问题提出了一种全新的思路。

目前该领域的主要方法可以概括为用分类去监督定位。一个典型的框架分为定位模块(attention module)和分类模块(classification module),其中定位模块对视频的每一帧(假设是第 t 帧)输出一个注意力(attention) λ_t∈[0,1],代表该帧属于一个动作片段的可能性;而经过注意力加权后的各个帧平均起来,输入分类模块进行分类。分类结果产生的 loss 同时用来更新两个模块。一言以蔽之:定位模块需要努力挑选出关键帧,使得整个视频更容易被分为正确的类别。
然而,这种方法的一个弊端在于,定位模块会把一些不属于动作片段(action frame),但和该动作类别极其相关的帧(这里称为 context frame)也一同选中,因为这些帧对于分类任务同样很有帮助。这种问题可以称为动作-上下文混淆(action-context confusion)。
举个例子,如图1,一段跳远的动作包括三个阶段(stage 1/2/3),而其两端的内容(预备/结束阶段)虽然不属于整个动作片段,但是本身对于动作的类别有很强的暗示性(跑道、沙坑等)。这类帧很容易被定位模块选中。

图1:跳远动作片段以及上下文相关帧
将上下文和动作片段区分开的关键是找到两者之间的区别。上文中我们提到,由于两者在分类任务上提供的有效信息不相上下,所以从分类的角度来看,两者区别较小。然而,可以注意到,两者在 appearance 或者 motion 的方面有着显著的差别:比如,动作片段中人体的姿势相比上下文中更加舒展,或者动作片段中由于动作产生的模糊(motion blur)更为显著。而这方面的差别,其实就反映在 representation 层面上的差异。相关的想法在 CVPR 2019 的一篇工作中也有所展现 [1]。
实际上,representation 层面上的建模本身就是这个任务的优化目标的一部分。对于一段视频 X,如果已知动作类别 y,那么定位过程如下:
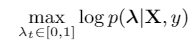
而在做一些简单的假设之后,这个优化目标可以分解成如下形式:
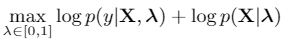
可以看到,其中第一项即之前的方法所关注的,通过分类来监督定位;而缺失的第二项,恰好就是前文所述的 representation modeling,即不同的注意力对应不同的 representation,而某个帧的 representation,要和其分配的注意力相匹配。这种关系可以用如下的概率图模型(graphical model)来理解:
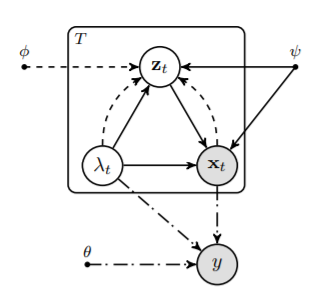
图2:动作定位的概率图模型
其中实线代表第二项,点划线代表第一项。
第一项的优化(我们称之为 Discriminative Attention Modeling)借鉴了 ICCV 2019 的一篇工作 [2];而如何引入第二项的优化(我们称为 Generative Attention Modeling,GAM),作为这篇工作主要贡献,将在下文详细介绍。
优化 log p(X│λ) 的方法有很多种,一种比较直接的方法是直接对 X 进行聚类,再根据 X 和各个 cluster 的相对位置来确定 λ。但这种方法有两个问题:第一是 λ 本身是0到1之间的连续值,无法对不同的 λ 都找到一个 cluster;第二是 X 本身是 multimodal 的分布,而单独的一个 cluster 无法对其很好地建模。基于这些考虑,我们采用 CVAE(Conditional Variational Autoencoder)去建模 log p(X│λ) 。CVAE 对于连续的 conditional variable,引入一个隐变量 z,并用一个 Infinite Mixture Model(IMM)去拟合目标条件概率:
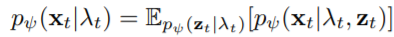
其中下标 t 指第 t 帧,ψ 是 decoder 的参数。IMM 的引入,能较好地解决 multimodal distribution 的拟合问题。因此,固定 CVAE 的参数,我们可以通过从 prior 中采样 z ,用上式估计出 p_ψ (x_t│λ_t ),并通过更新定位模块来对其优化。
那么 CVAE 的参数应该如何确定呢?如果我们有 X 和 λ 的成对数据,可以直接去优化 CVAE 的 ELBO(Evidence Lower Bound),从而确定其参数。但由于缺少动作的时间标注信息,故我们只好用定位模块自动预测的 λ 作为 pseudo label,去优化 CVAE 的 ELBO:
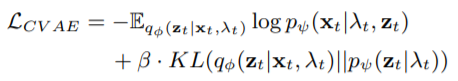
其中 q_ϕ (z_t│x_t,λ_t ) 是 encoder。具体地,我们交替地对网络进行优化:首先固定 CVAE,对定位模块以及分类模块进行优化;然后固定这两个模块,并用定位模块产生的 pseudo label 去优化 CVAE。在实验中发现,由于 discriminative attention modeling 的约束,产生的 pseudo label 质量较高,最后网络可以较好收敛。网络的整体训练过程如下:
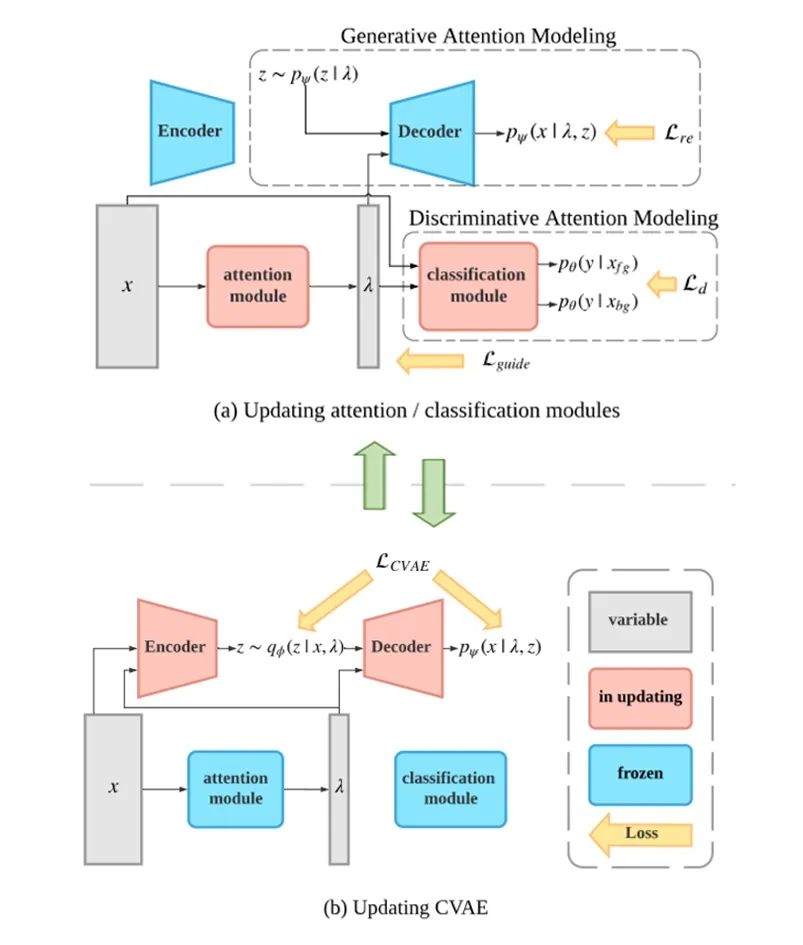
图3:网络训练过程
首先,为了探究 GAM 到底是不是学习到了更准确的注意力,我们进行了简单的消融实验:由于在 inference 的时候,定位模块和分类模块是分开运算的,即首先由定位模块预测注意力,再由分类模块进行分类,故可以将 baseline model 的两个模块和我们模型的两个模块一一组合,譬如,将 baseline model 的定位模块和我们的分类模块结合在一起,测试其性能。实验结果如下表:
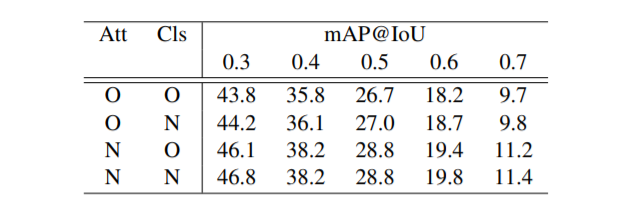
表1:baseline model 定位模块与 GAM 分类模块的组合实验结果
其中 O(old)指 baseline model 的模块,N(new)指我们模型的模块。可以看到,带来效果提升的主要是定位模块的更新,这说明我们的模型确实主要是在学习一个更好的注意力。
接下来,为了更细致地考察学得的注意力究竟准确在哪里,我们统计了如下几个变量:
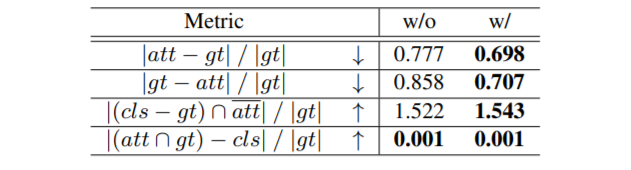
表2:baseline model 与 GAM 的对比实验结果
其中 att、cls 分别代表注意力高和分类分数高的帧的集合,gt 代表 ground truth 的动作帧集合,运算符都是集合间运算。比如说,第一个 metric 代表定位模块错选的帧数量与 ground truth 帧的数量之比。右侧第一列代表 baseline model 的统计数据,第二列是我们的模型。
表格的前两行说明我们的定位模块可以同时减少 false positive 和 false negative 的数量,而第三行则表示我们的定位模块可以更有效地过滤分类分数高的帧(比如context frame),这与我们的出发点是一致的。
除此之外,我们也做了其它的消融实验,对模型中各个参数的作用进行了分析。最后我们在 benchmark 数据集 THUMOS14 与 ActivityNet1.2 上也超越了之前的最好结果,这里作为例子,展示了 THUMOS14 数据集上的结果:
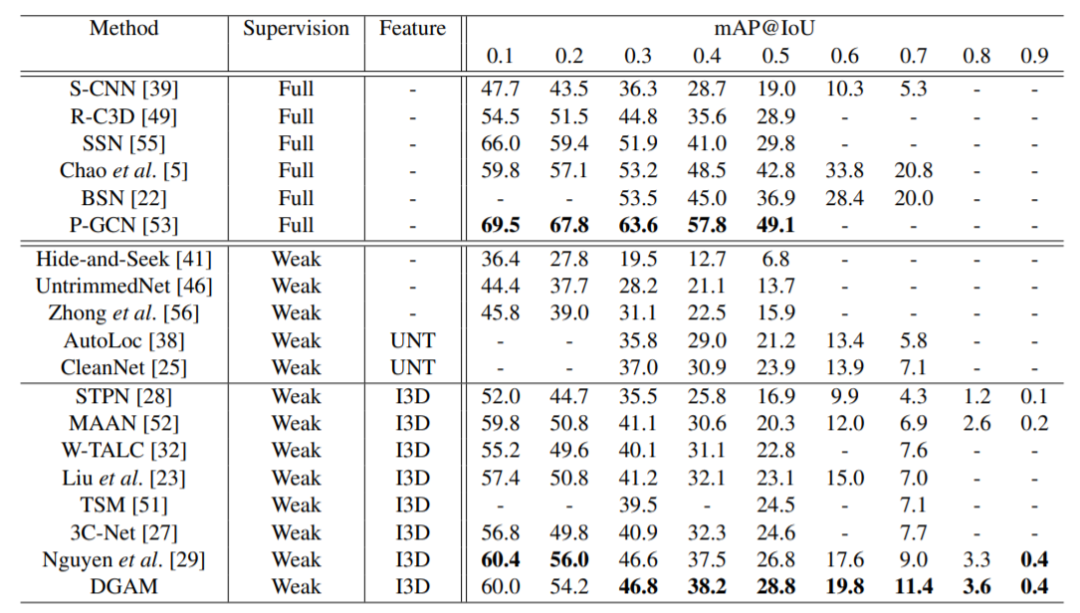
表3:THUMOS14 数据集上的实验结果
这篇工作着重于解决弱监督视频动作定位任务中一个关键问题:动作-上下文混淆(action-context confusion)。通过分析整个优化问题以及它的 graphical model,我们提出要分开上下文和动作片段,不能从分类的角度,而要从它们特征表示的角度捕捉两者的差别。具体地,我们提出用 CVAE 去建模视频帧的特征条件与注意力的分布,并与整个模型交替优化,最后得到更准确的注意力值。通过实验,我们验证了模型的结果与最初的出发点一致,并可以在现有最好方法的基础上进一步提高定位效果。
更多技术细节以及代码,请参考论文:
Weakly-Supervised Action Localization by Generative Attention Modeling
arXiv 链接:https://arxiv.org/abs/2003.12424
GitHub 链接:https://github.com/bfshi/DGAM-Weakly-Supervised-Action-Localization
参考文献
[1] Daochang Liu, Tingting Jiang, and Yizhou Wang. "Completeness modeling and context separation for weakly supervised temporal action localization." Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition. 2019.
[2] Phuc Xuan Nguyen, Deva Ramanan, and Charless C. Fowlkes. "Weakly-supervised action localization with background modeling." Proceedings of the IEEE International Conference on Computer Vision. 2019.
你也许还想看:









