【AlphaGo Zero 核心技术-深度强化学习教程代码实战04】Agent类和SARSA算法实现
点击上方“专知”关注获取更多AI知识!
【导读】Google DeepMind在Nature上发表最新论文,介绍了迄今最强最新的版本AlphaGo Zero,不使用人类先验知识,使用纯强化学习,将价值网络和策略网络整合为一个架构,3天训练后就以100比0击败了上一版本的AlphaGo。Alpha Zero的背后核心技术是深度强化学习,为此,专知有幸邀请到叶强博士根据DeepMind AlphaGo的研究人员David Silver《深度强化学习》视频公开课进行创作的中文学习笔记,在专知发布推荐给大家!(关注专知公众号,获取强化学习pdf资料,详情文章末尾查看!)
叶博士创作的David Silver的《强化学习》学习笔记包括以下:
笔记序言:【教程】AlphaGo Zero 核心技术 - David Silver深度强化学习课程中文学习笔记
《强化学习》第七讲 策略梯度
《强化学习》第八讲 整合学习与规划
《强化学习》第九讲 探索与利用
以及包括也叶博士独家创作的强化学习实践系列!
强化学习实践四 Agent类和SARSA算法实现
强化学习实践五 SARSA(λ)算法实现
强化学习实践六 给Agent添加记忆功能
强化学习实践七 DQN的实现
今天实践四 Agent类和SARSA算法实现。
声明:本文及涉及代码为本人原创,代码适用协议MIT。
通过前几次强化学习实践讲解,我们基本上理解了个体与环境的建模思想,特别是对gym库有了一定的了解。在本讲中,我们将尝试编写一个简单的Agent类,并且使它能够和我们之前编写的格子世界环境类进行交互。然后我们将实现SARSA算法,确切地说是SARSA(0)。我们将看看它在简单格子世界中的训练效果。
由于蒙特卡洛学习和单纯的基于价值的TD学习实际应用不多,在实践环节我也不打算实现这两个算法,当然了SARSA也是TD学习的一种形式。掌握了SARSA算法,再去实现类似的Q学习算法、MC或单纯的TD算法也不会有什么难度。在下一讲中我们将实现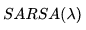
为了帮助加深强化学习的各种概念,我将按照解决问题的思路一步一步编写代码,希望这种写法可以让读者加深对强化学习基本概念的理解。当Agent编写完成后,我们可以不做任何修改地使用它训练各种格子世界的环境,这也体现了DeepMind公司一直所宣扬的通用智能算法(General Intelligent Algorithms)理念。
一个简单的Agent类
我们在实践二讲gym的建模思想中简单提到了个体类的建模。本讲我们将围绕SARSA(0)算法的实现来具体实现个体(Agent)类应该具备的功能。SARSA(0)算法流程如下:

我们暂且就用Agent给个体类命名,由于要使用到之前编写的格子世界环境类,我们需要导入相关的包:
from random import random # 随机策略时用到
from gym import Env
import gym
from gridworld import * # 可以导入各种格子世界环境我们已经知道强化学习中个体(Agent)遵循当前一个策略得到一个行为,通过施加这个行为给环境并分析环境(Environment)的反馈信息(个体观测值的变化和获得的即时奖励)来优化策略。同时SARSA算法要求个体类维护一个状态行为价值表 Q(s,a),也就是状态行为价值函数,针对一个状态 s ,在该状态下采取一个行为a,个体要能查得出该状态行为对的价值。因此Agent类要包括如下功能:
class Agent():
def __init__(self, env: Env):
self.env = env # 个体持有环境的引用
self.Q = {} # 个体维护一张行为价值表Q
self.state = None # 个体当前的观测,最好写成obs.
def performPolicy(self, state): pass # 执行一个策略
def act(self, a): # 执行一个行为
return self.env.step(a)
def learning(self): pass # 学习过程这里有两点要说明下:
对于Q表,我使用的是字典套字典的数据结构,即字典里的每一个键对应于状态名,其值对应于另一个新字典,这个新字典的键值是行为名,值则对应相应的行为价值。这么设计主要是为了体现个体与环境交互的特点:个体并不掌握环境的具体信息,从与环境交互过程中个体得到的只是一个观测,我们不能事先假定观测的数据格式,用字典比较稳妥。
我们把执行策略和执行行为分开成两个方法,是考虑到SARSA算法有两个地方需要使用个体的策略:一是执行一个动作前,另一处是用在观察新状态S'在遵循当前策略时产生的行为时,而后面这个行为不是马上执行的,有的算法里干脆就是不执行的,因此把执行策略生成行为和执行行为分开写也就比较合理了。执行行为方法很简单,调用环境的step方法就可以了,原封不动的把step的返回值作为自己的返回值,由于该方法的直接返回了个体需要额观测,我们就不需要单独写一个观测的方法了。
有了最基本的框架,事情就简单了。接下来我们设计几个辅助的私有方法。前面提到要把观测转化为一个字典的键,因此需要一个方法来完成此事:
def _get_state_name(self, state):
return str(state) 这里偷了个懒,仅仅把状态转化为字符串就完成了,不过这个仅适用离散观测空间的环境。
由于需要频繁检索和更新Q值,同时又要完成一些初始化工作,确保我们检索的时候避免发生键不存在的情况,因此我设计了以下几个私有方法:
def _is_state_in_Q(self, s): # 判断s的Q值是否存在
return self.Q.get(s) is not None
def _init_state_value(self, s_name, randomized = True): # 初始化某状态的Q值
if not self._is_state_in_Q(s_name):
self.Q[s_name] = {}
for action in range(self.env.action_space.n): # 针对其所有可能行为
default_v = random() / 10 if randomized is True else 0.0
self.Q[s_name][action] = default_v
def _assert_state_in_Q(self, s, randomized=True): # 确保某状态Q值存在
# cann't find the state
if not self._is_state_in_Q(s):
self._init_state_value(s, randomized)
def _get_Q(self, s, a): # 获取Q(s,a)
self._assert_state_in_Q(s, randomized=True)
return self.Q[s][a]
def _set_Q(self, s, a, value): # 设置Q(s,a)
self._assert_state_in_Q(s, randomized=True)
self.Q[s][a] = value外围工作基本就这么多,接下来我们为个体实现两个主要功能:一个是策略方法、一个是训练过程。SARSA遵循的策略是 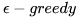
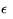
def performPolicy(self, s, episode_num, use_epsilon):
epsilon = 1.00 / (episode_num+1)
Q_s = self.Q[s]
str_act = "unknown"
rand_value = random()
action = None
if use_epsilon and rand_value < epsilon:
action = self.env.action_space.sample()
else:
str_act = max(Q_s, key=Q_s.get)
action = int(str_act)
return action 我们为执行策略方法增加了一个use_epsilon参数,使得我们可以随时切换是否使用
SARSA算法实现
SARSA的核心代码全部在learning方法里,我们为learning方法设计了几个参数来做适当的控制,具体代码如下,结合注释和算法流程,很容易理解:
# sarsa learning
def learning(self, gamma, alpha, max_episode_num):
# self.Position_t_name, self.reward_t1 = self.observe(env)
total_time, time_in_episode, num_episode = 0, 0, 0
while num_episode < max_episode_num: # 设置终止条件
self.state = self.env.reset() # 环境初始化
s0 = self._get_state_name(self.state) # 获取个体对于观测的命名
self.env.render() # 显示UI界面
a0 = self.performPolicy(s0, num_episode, use_epsilon = True)
time_in_episode = 0
is_done = False
while not is_done: # 针对一个Episode内部
# a0 = self.performPolicy(s0, num_episode)
s1, r1, is_done, info = self.act(a0) # 执行行为
self.env.render() # 更新UI界面
s1 = self._get_state_name(s1)# 获取个体对于新状态的命名
self._assert_state_in_Q(s1, randomized = True)
# 获得A'
a1 = self.performPolicy(s1, num_episode, use_epsilon=True)
old_q = self._get_Q(s0, a0)
q_prime = self._get_Q(s1, a1)
td_target = r1 + gamma * q_prime
#alpha = alpha / num_episode
new_q = old_q + alpha * (td_target - old_q)
self._set_Q(s0, a0, new_q)
if num_episode == max_episode_num: # 终端显示最后Episode的信息
print("t:{0:>2}: s:{1}, a:{2:2}, s1:{3}".\ format(time_in_episode, s0, a0, s1))
s0, a0 = s1, a1
time_in_episode += 1
print("Episode {0} takes {1} steps.".format(
num_episode, time_in_episode)) # 显示每一个Episode花费了多少步
total_time += time_in_episode
num_episode += 1
returnSARSA(0)算法这就这就完成了。我们拿一个简单格子世界来试试效果如何,为此可以添加如下代码:
def main():
env = SimpleGridWorld()
agent = Agent(env)
print("Learning...")
agent.learning(gamma=0.9,
alpha=0.1,
max_episode_num=800)if __name__ == "__main__":
main()设置衰减系数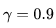

将所有代码保存在一个文件里,通过终端调用执行该文件,可以一边显示UI界面,一边在终端看到一些输出信息。
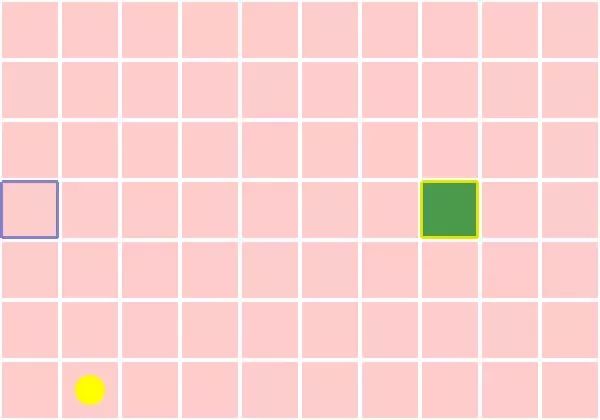
下图是训练早期的个体表现

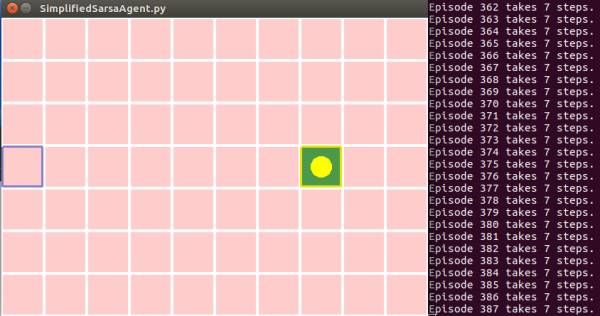
下图是个体训练了近400次完整Episodes的时候基本上已经锁定最优路径了。
下面是其中的一个Episode视频片段:
该程序完整的代码可从这里下载到。
至此,针对离散观测空间和离散行为空间的SARSA算法我们就完成了。在此基础上Q学习算法只要修改1-2行代码就可以了。下一次实践我们将很容易地实现
敬请关注专知公众号(扫一扫最下方二维码或者最上方专知蓝字关注),以及专知网站www.zhuanzhi.ai, 第一时间得到强化学习实践三 编写通用的格子世界环境类!
作者简介:
叶强,眼科专家,上海交通大学医学博士, 工学学士,现从事医学+AI相关的研究工作。
特注:
请登录www.zhuanzhi.ai或者点击阅读原文,
顶端搜索“强化学习” 主题,直接获取查看获得全网收录资源进行查看, 涵盖论文等资源下载链接,并获取更多与强化学习的知识资料!如下图所示。
此外,请关注专知公众号(扫一扫最下面专知二维码,或者点击上方蓝色专知),后台回复“强化学习” 就可以获取深度强化学习知识资料全集(论文/代码/教程/视频/文章等)的pdf文档!
欢迎转发到你的微信群和朋友圈,分享专业AI知识!
请感兴趣的同学,扫一扫下面群二维码,加入到专知-深度强化学习交流群!

请扫描小助手,加入专知人工智能群,交流分享~

获取更多关于机器学习以及人工智能知识资料,请访问www.zhuanzhi.ai, 或者点击阅读原文,即可得到!
-END-
欢迎使用专知
专知,一个新的认知方式!目前聚焦在人工智能领域为AI从业者提供专业可信的知识分发服务, 包括主题定制、主题链路、搜索发现等服务,帮你又好又快找到所需知识。
使用方法>>访问www.zhuanzhi.ai, 或点击文章下方“阅读原文”即可访问专知
中国科学院自动化研究所专知团队
@2017 专知
专 · 知
关注我们的公众号,获取最新关于专知以及人工智能的资讯、技术、算法、深度干货等内容。扫一扫下方关注我们的微信公众号。


点击“阅读原文”,使用专知!




