TF-Ranking 中的 Keras API 让 LTR 模型构建更轻松


发布人:Google Research 软件工程师 Michael Bendersky 和 Xuanhui Wang
2018 年 12 月,我们推出了 TF-Ranking,这是一个基于 TensorFlow 的开源代码库,用于开发可扩容的 learning-to-rank (LTR) 神经模型。当用户期望收到有序的项目列表来辅助查询时,该模型可以发挥出色作用。LTR 模型与一次只对一个项目进行分类的标准分类模型不同,它会将整个项目列表接收输入,并学习排序,充分提升整个列表的效用。
TF-Ranking
https://github.com/tensorflow/ranking
虽然 LTR 模型最常用于搜索和推荐系统,但自其发布以来,我们已经看到 TF-Ranking 在除搜索以外的各领域,均有应用,其中包括电子商务、SAT 求解器和智能城市规划等。
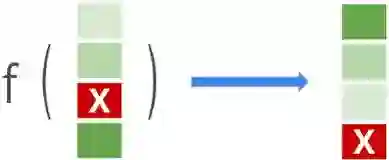
Learning-to-rank (LTR) 的目标是学习一个函数 f(),该函数会以项目列表(文件、产品、电影等)作为输入,并以最佳排序(相关性降序)输出项目列表。上图中,深浅不一的绿色表示项目的相关性水平,标有 “x” 的红色项目是不相关的
电子商务
https://dl.acm.org/doi/abs/10.1145/3308560.3316603
SAT 求解器
https://arxiv.org/abs/1904.12084
智能城市规划
https://dl.acm.org/doi/abs/10.1145/3450267.3450538
2021 年 5 月,我们发布了 TF-Ranking 的一个重要版本,实现了全面支持使用 Keras(TensorFlow 2 的一个高阶 API),以原生方式构建 LTR 模型。我们为原生 Keras 排序模型加入了全新的工作流设计,其中包括灵活的 ModelBuilder、用于设置训练数据的 DatasetBuilder, 以及利用给定数据集训练模型的 Pipeline。有了这些组件,构建自定义 LTR 模型会比以往更轻松,且有利于快速探索、生产和研究的新的模型结构。如果您选择的工具是 RaggedTensors,TF-Ranking 现在也可以和这些工具协作。
重要版本
https://github.com/tensorflow/ranking/releases/tag/v0.4.0
TensorFlow 2
http://tensorflow.google.cn/
也
https://github.com/tensorflow/ranking/blob/master/tensorflow_ranking/examples/keras/antique_ragged.py
此外,我们在最新版本中结合了 Orbit 训练库,其中包含了许多进展成果,而这些成果正是近两年半内,神经 LTR 研究结晶。下面我们分享一下 TF-Ranking 最新版本中的一些重要改进。
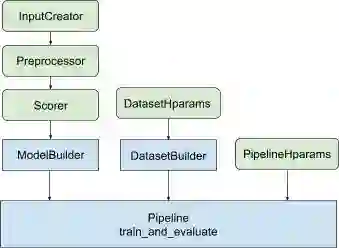
构建和训练原生 Keras 排序模型的工作流。蓝色模块由 TF-Ranking 提供,绿色模块支持自定义
最新版本
https://github.com/tensorflow/ranking/releases/tag/v0.4.2
Orbit
https://github.com/tensorflow/models/tree/master/orbit

最近,BERT 之类的预训练语言模型在各种语言理解任务中性能表现突出。为利用这些模型,TF-Ranking 实现了一个新颖的 TFR-BERT 架构——通过结合 BERT 与 LTR 的优势,来优化列表输入的排序过程。举个例子,假设有一个查询和一个由 n 个文件组成的列表,而人们想要在对此查询响应中的文件进行排序。LTR 模型并不会为每个 <query, document> 学习独立的 BERT 表示,而是会应用一个排序损失来共同学习 BERT 表示,充分提升整个排序列表相对于参照标准标签的效用。
这个过程如下图所示。首先,我们把查询响应中需要排序的 n 个文件组成的列表扁平化为一个 <query, document> 元组列表。把这些元组反馈至预训练的语言模型(例如 BERT)。然后用 TF-Ranking 中的专用排序损失,对整个文件列表的池化 BERT 输出进行联合微调。
排序损失
https://github.com/tensorflow/ranking/blob/master/tensorflow_ranking/python/losses.py
结果表明,这种 TFR-BERT 架构在预训练的语言模型性能方面有了明显改善,因此,可以在执行多个热门排序任务时体现出十分优越的性能。若将多个预训练的语言模型组合在一起,则效果更为突出。我们的用户现在可以通过这个简单的例子完成 TFR-BERT 入门。
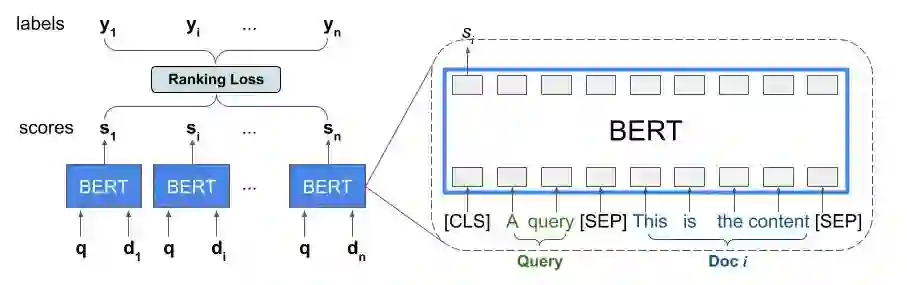
TFR-BERT 架构的说明,在这个架构中,通过使用单个 <query, document> 对的 BERT 表示,在包含 n 个文件的列表上构建了一个联合 LTR 模型
多个热门
https://arxiv.org/abs/2010.00200
简单的例子
https://github.com/tensorflow/ranking/blob/master/tensorflow_ranking/examples/keras/tfrbert_antique_train.py
透明度和可解释性是在排序系统中部署 LTR 模型的重要因素,在贷款资格评估、广告定位或指导医疗决定等过程中,用户可以利用这些系统来确定结果。在这种情况下,每个单独的特征对最终排序的贡献应具有可检查性和可理解性,以此确保结果的透明度、问责制和公正性。
实现这一目标的可用方法之一是使用广义加性模型 (Generalized additive model,GAM),这是一种具有内在可解释性的机器学习模型,由唯一特征的平滑函数线性组合而成。然而,我们虽然已经在回归 (Regression analysis) 和分类任务方面对 GAM 进行了广泛的研究,但将其应用于排序设置的方法却并不明确。举个例子,虽然可以直接利用 GAM 对列表中的每个单独项目进行建模,然而对项目的相互作用和这些项目的排序环境进行建模,仍是一个更具挑战性的研究问题。为此,我们开发了神经排序 GAM,这是可为排序问题的广义加性模型所用的扩展程序。
神经排序 GAM
https://arxiv.org/abs/2005.02553
与标准的 GAM 不同,神经排序 GAM 可以同时考虑到排序项目和背景特征(例如查询或用户资料),从而得出一个可解释的紧凑模型。这同时确保了各项目级别特征与背景特征的贡献具有可解释性。例如,在下图中,使用神经排序 GAM 可以看到在特定用户设备的背景下,距离、价格和相关性是如何对酒店最终排序作出贡献的。目前,神经排序 GAM 现已作为 TF-Ranking 的一部分发布。

为本地搜索应用神经排序 GAM 的示例。对于每个输入特征(例如价格、距离),子模型会产生可以检查的子分数,支持公开查看。背景特征(例如用户设备类型)可以用于推算子模型的重要性权重
发布
https://github.com/tensorflow/ranking/issues/202
神经模型虽然在多个领域展现出了十分优越的性能,但 LambdaMART 之类的专门梯度提升决策树 (Gradient Boosted Decision Trees, GBDT) 仍然是利用各种开放 LTR 数据集时的性能标杆。GBDT 在开放数据集中的成功可归结于几个原因。首先,由于其规模相对较小,神经模型在这些数据集上容易过度拟合 (Overfitting)。其次,由于 GBDT 使用决策树对其输入特征空间进行划分,它们自然更能适应待排序数据的数值尺度变化,这些数据通常包含具有 Zipfian (Zipf's law) 或其他偏斜分布的特征。然而,GBDT 在更为现实的排序场景中确实有其局限性,这些场景往往同时包含文本和数字特征。举个例子,GBDT 不能直接应用于像原始文档文本这种,较大的离散特征空间。一般来说,它们的可扩容性也要弱于神经排序模型。
因此,自 TF-Ranking 发布以来,我们团队大大加深了对于神经模型在数字特征排序中优势的理解。。最能充分体现出这种理解的是,ICLR 2021 的一篇论文中所描述的数据增强自觉潜在交叉 (DASALC) 模型,该模型首次在开放 LTR 数据集上建立了与强大的、与 LambdaMART 基线相同的神经排序模型,并且在某些方面取得了统计学上的重大改进。这一成就是通过各种技术的组合实现的,其中包括数据增强、神经特征转换、用于建模文档交互的自注意机制、列表式排序损失,以及类似 GBDT 中用于提升的模型组合。现在 DASALC 模型的架构完全由 TF-Ranking 库实现。
ICLR 2021
https://research.google/pubs/pub50030/
总而言之,我们相信基于 Keras 的 TF-Ranking 新版本能够让开展神经 LTR 研究和部署生产级排序系统变得更加轻松。我们鼓励大家试用最新版本,并按照这个引导例子进行实践体验。虽然这个新版本让我们感到非常激动,但我们的研发之旅远未结束,所以我们将继续深化对 learning-to-rank 问题的理解,并与用户分享这些进展。
最新版本
https://github.com/tensorflow/ranking/releases/tag/v0.4.0
这个引导例子
https://github.com/tensorflow/ranking/blob/master/tensorflow_ranking/examples/keras/keras_dnn_tfrecord.py
本项目的实现离不开 TF-Ranking 团队的现任和前任成员:Honglei Zhuang、Le Yan、Rama Pasumarthi、Rolf Jagerman、Zhen Qin、Shuguang Han、Sebastian Bruch、Nathan Cordeiro、Marc Najork 和 Patrick McGregor。另外要特别感谢 Tensorflow 团队的协作者:Zhenyu Tan、Goldie Gadde、Rick Chao、Yuefeng Zhou、Hongkun Yu 和 Jing Li。

推荐阅读



点击“阅读原文”访问 TensorFlow 官网
不要忘记“一键三连”哦~

分享

点赞

在看




