使用 TensorFlow 约束优化库设置公平性目标
文 / Andrew Zaldivar,Google Research,代表 TFCO 团队
从发现疾病的早期迹象到过滤不当内容,利用监督式机器学习的技术正对人们的日常生活产生积极影响。然而,一个逐渐引起人们关注的问题是,这些技术通常使用可满足最小化单个损失函数单一要求的学习模型,难以解决公平性等更广泛的社会问题。
想解决这类问题需要权衡多个互相冲突的因素。但即使考虑到了这些因素,这些系统可能仍然无法满足如此复杂的设计要求,例如在某些情况下,假阴性 (False Negative) 可能比假阳性 (False Positive) 更“糟糕”,或者所训练的模型应与既有模型“类似”。
我们近日推出了 TensorFlow 约束优化库 (TensorFlow Constrained Optimization, TFCO),可根据多种不同指标(例如,某些特定群体成员的精度、某些国家/地区居民的真阳率 (True Positive),或者取决于年龄和性别的癌症诊断的召回率)来配置和训练机器学习问题。虽然此类指标从概念上看简单易懂,但通过为用户提供最小化和约束指标任意组合的功能,TFCO 可轻松阐述并解决公平性社区尤其是机器学习社区特别关注的诸多问题(例如均衡赔率和预测性平价等)。
TFCO 与我们的 AI 原则有何关系?
TFCO 的发布切实践行了我们的 AI 原则,将进一步帮助引导 AI 在研究和实践中的道德发展和运用。
通过为开发者提供 TFCO,我们希望能提高其识别自身模型可能存在风险和危害的能力,并设定约束条件以确保其模型获得理想结果。
目标具体指什么?
借用 Hardt 等人的文章中的一个示例,我们假设任务是学习某个分类器,该分类器能够根据某个群体能否偿还贷款的数据集(能,即阳性标签;否,即为阴性标签)决定某个人是否应该获得贷款(能,即为阳性预测值;否,即为阴性预测值)。
为在 TFCO 中设置此问题,我们将选择一个目标函数,如果模型向有能力偿还贷款的人发放贷款,该目标函数就会奖励模型,同时该函数 也会 施加公平性约束,以防止模型不公平地拒绝向某些受保护的群体提供贷款。在 TFCO 中,要最小化的目标和要施加的约束均表示为简单基本比率的代数表达式(使用普通 Python 运算符)。
指示 TFCO 最小化线性模型(无公平性约束)的学习分类器总误报率,可能会产生如下所示的决策边界:
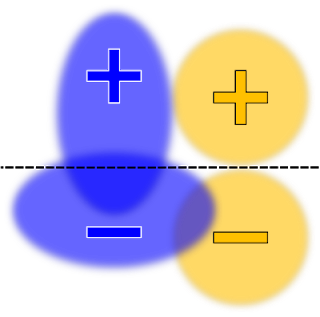
二元分类数据集示意图,包含两个受保护组:蓝色和橙色。为便于显示,未绘制每个单独的数据点,而是用椭圆形表示密度。阳性和阴性符号即为标签。决策边界用黑色虚线绘制,将阳性预测值(虚线上方区域)和阴性(虚线下方区域)标签隔开,最大程度地提高准确性
这是一个很好的分类器,但在某些应用中,可能会认为它是 不公平 的。例如,带有阳性标签的蓝色示例比带有阳性标签的橙色示例更有可能收到阴性预测值,这违背了“机会均等”原则。要纠正这一问题,可在约束列表中添加一个机会均等约束条件。此时生成的分类器看起来如下所示:
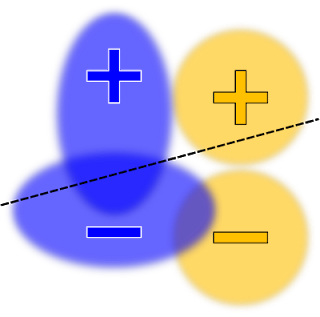
在这里,决策边界将在机会均等(或真阳率)的约束下,用以最大程度地提高准确度
我如何明确要设置哪些约束?
如何选择“正确”的约束条件,具体取决于问题和用户的策略目标或要求。因此,我们尽量避免强迫用户从精心设计的“原生”问题列表中进行选择。相反,我们尝试支持用户通过组合和操纵简单的基本比率来定义范围极其广泛的潜在问题,从而最大程度地提高灵活性。
这样的灵活性可能存在不利影响:如果不谨慎,用户可能会尝试施加矛盾约束,从而导致问题受限,无法给出好的解决方案。在上述示例的上下文中,除 真阳率 (TPR) 以外(即,“均等赔率”), 用户还可能会将假阳率 (FPR) 约束为均等。但是,这两组约束的潜在矛盾性质,再加上我们对线性模型的要求,可能迫使我们解决方案准确度极低。例如:
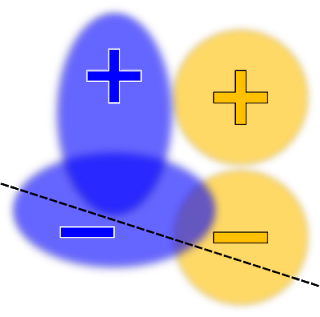
决策边界要同时在真阳率和假阳率的约束之下,最大程度地提高准确度
对于灵活性不足的模型, 两个组的 FPR 可能相同,但数值非常大(如上图所示), 或者 两个组的 TPR 相同,但数值非常小(未显示)。
是否会失败?
以比率约束表达多个公平性目标的能力有助于推动负责任的机器学习发展进程,但同时也要求开发者慎重考虑其试图解决的问题。例如,假设用户将训练约束为四个组具有相同的准确度,但是其中的某个组在分类时难度大得多。在这种情况下,满足约束条件的唯一方法可能是 降低 三个难度较低的组的准确度,以使其与第四组的低准确度相匹配,但这样做可能达不到理想结果。
一种“更安全的”替代方案是约束每个组独立满足某个绝对指标,例如,要求每个组至少达到 75% 的准确度。使用此类绝对约束,而非相对约束,通常可避免各组之间互相拖累。当然,用户也可能要求一个无法达到的最低准确度,因此仍然需要保持自觉。
小样本量的难题
使用约束优化的另一个普遍难题是,应用约束条件的组可能在数据集中未得到充分表现。因此,我们在训练期间计算的随机梯度将非常嘈杂,导致收敛变慢。在这种情况下,我们建议用户将约束施加到单独的重新平衡数据集上,该数据集包含的每个组的比例更高,并且仅使用原始数据集来最小化目标。
例如,在我们提供的 Wiki ”毒性“示例中,我们希望预测 Wiki 讨论页面上发布的讨论评论是否是”有毒的“(即,包含“粗鲁、不尊重他人或不合理”的内容)。仅 1.3% 的评论提到与“性”相关的词语,而这些评论中有很大比例被标记为“有毒”。因此,在该数据集上训练卷积神经网络 (CNN) 模型但不设置约束条件则可导致模型相信“性”是有毒的有力指标,并导致该组的假阳率很高。我们使用 TFCO 将四个敏感主题(性、性别认同、宗教和种族)的假阳率约束在 2% 以内。为了更好地处理小样本量的问题,我们使用“重新平衡”的数据集来施加约束,而原始数据集仅用于将目标最小化。如下所示,受约束的模型能够显著降低四个主题组的假阳率,同时维持与不受约束的模型几乎相同的准确度。
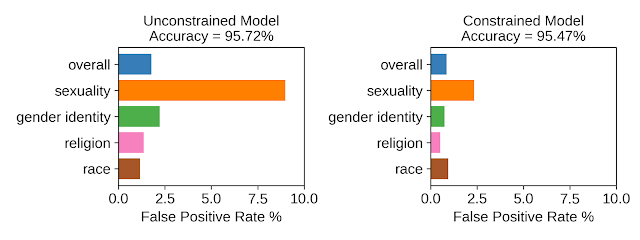
用于对 Wiki 讨论页面上有毒评论进行分类的无约束和有约束 CNN 模型的比较
交叉性——细粒度分组的挑战
重叠的约束条件有助于为长期被边缘化的群体和少数群体的多个类别创造公平的体验。除上述示例外,我们还提供了 CelebA 示例,该示例检查了一种检测图像中所包含笑脸的计算机视觉模型,我们希望该模型在多个非互斥受保护群体中有良好表现。假阳率在该示例中可作为适当指标,因为它可以评估在不包含笑脸的图像中被错误标记为包含笑脸的图像占比。通过根据可用的年龄组(年轻人和老年人)或性别(男性和女性)类别比较假阳率,我们可以检查是否存在不理想的模型偏差(例如,微笑的老年人的图像是否未得到正确的识别)。
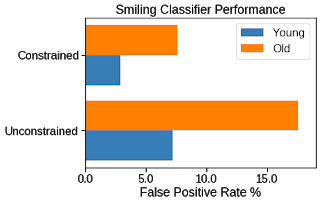
跨年龄组类别的无约束和有约束的笑脸检测器的比较
结语
正确处理比率约束具有挑战性,因为以 计数 (例如,准确率即正确预测数量除以示例数量得到的比值)方式考量时,约束函数是不可微分的函数。从算法上来看,TFCO 将受约束的问题转换为非零和的两方博弈(ALT’19,JMLR’19)。用户可扩展该框架,以处理排序和回归设置 (AAAI’20)、F-measure (NeurIPS’19a) 等更复杂的指标,或提高泛化性能 (ICML’19)。
我们认为,TFCO 库将有助于训练需要考量的社会和文化因素,以满足现实世界要求的 ML 模型。我们提供的示例(毒性分类和微笑检测)仅是一点浅显的探讨。我们希望 TFCO 的灵活性能帮助您应对问题的独特要求。
致谢
此项研究是 TFCO 及其相关研究论文的作者共同努力的成果,包括 Andrew Cotter、Maya R. Gupta、Heinrich Jiang、Harikrishna Narasimhan、Taman Narayan、Nathan Srebro、Karthik Sridharan、Serena Wang、Blake Woodworth 和 Seungil You。
如果您想详细了解 本文讨论 的相关内容,请参阅以下文档。这些文档深入探讨了这篇文章中提及的许多主题:
公平性约束等 机器学习词汇 请参考:
https://developers.google.com/machine-learning/glossary#fairness-constraint公平性
https://ai.google/responsibilities/responsible-ai-practices/?category=fairnessTensorFlow 约束优化库
https://github.com/google-research/tensorflow_constrained_optimization/blob/master/README.mdAI 原则
https://www.blog.google/technology/ai/ai-principles/Hardt 等人
https://ai.googleblog.com/2016/10/equality-of-opportunity-in-machine.htmlWiki 毒性示例
https://github.com/google-research/tensorflow_constrained_optimization/blob/master/examples/colab/Wiki_toxicity_fairness.ipynbCelebA 示例
https://github.com/google-research/tensorflow_constrained_optimization/blob/master/examples/colab/CelebA_fairness.ipynbALT’19
http://proceedings.mlr.press/v98/cotter19a.html
JMLR’19
http://jmlr.org/papers/v20/18-616.htmlAAAI’20
https://arxiv.org/abs/1906.05330NeurIPS’19a
https://papers.nips.cc/paper/9258-optimizing-generalized-rate-metrics-with-three-playersICML’19
https://icml.cc/Conferences/2019/ScheduleMultitrack?event=3659TFCO
https://github.com/google-research/tensorflow_constrained_optimization/blob/master/README.md毒性分类
https://github.com/google-research/tensorflow_constrained_optimization/blob/master/examples/colab/Wiki_toxicity_fairness.ipynb微笑检测
https://github.com/google-research/tensorflow_constrained_optimization/blob/master/examples/colab/CelebA_fairness.ipynb







