令人困惑的TensorFlow!
选自jacobbuckman.com
作者:Jacob Buckman
机器之心编译
虽然对于大多数人来说 TensorFlow 的开发语言是 Python,但它并不是一个标准的 Python 库。这个神经网络框架通过构建「计算图」来运行,对于很多新手来说,在理解其逻辑时会遇到很多困难。本文中,来自谷歌大脑的工程师 Jacob Buckman 将试图帮你解决初遇 TensorFlow 时你会遇到的麻烦。
导论
这是什么?我是谁?
我叫 Jacob,是 Google AI Resident 项目的研究学者。我是在 2017 年夏天加入该项目的,尽管已经拥有了丰富的编程经验,并且对机器学习的理解也很深刻,但此前我从未使用过 TensorFlow。当时我觉得凭我的能力应该很快就能上手。但让我没想到的是,学习曲线相当的陡峭,甚至在加入该项目几个月后,我还偶尔对如何使用 TensorFlow 代码来实现想法感到困惑。我把这篇博文当作瓶中信写给过去的自己:一篇我希望在学习之初能被给予的入门介绍。我希望这篇博文也能帮助到其他人。
以往的教程缺少了哪些内容?
自 TensorFlow 发布的三年以来,其已然成为深度学习生态系统中的一块基石。然而对于初学者来说,它可能并不直观,特别是与 PyTorch 或 DyNet 这样运行即定义的神经网络库相比。
市面上有许多 TensorFlow 的入门教程,包含从线性回归到 MNIST 分类和机器翻译的内容。这些具体实用的指南是使 TensorFlow 项目启动并运行的良好资源,同时可以作为类似项目的切入点。但对于有些应用开发人员而言,他们开发的应用并没有好的教程,或对于那些想打破常规的人(在研究中很常见)而言,刚接触 TensorFlow 肯定是让人沮丧的。
我试图通过这篇文章去填补这个空白。我没有专注于某个特定的任务,而是提出更一般的方法,并解析 TensorFlow 背后基础的抽象概念。掌握好这些概念之后,用 TensorFlow 进行深度学习就会变得直观易懂。
目标受众
本教程适用于那些在编程和机器学习方面有一定经验,并想要学习 TensorFlow 的人。例如:一位想在机器学习课程的最后一个项目中使用 TensorFlow 的计算机科学专业的学生;一位刚被分配到涉及深度学习项目的软件工程师;或是一位处于困惑中的新的 Google AI Resident 新手(向过去的 Jacob 大声打招呼)。如果你想进一步了解基础知识,请参阅以下资源:
https://ml.berkeley.edu/blog/2016/11/06/tutorial-1/
http://colah.github.io/
https://www.udacity.com/course/intro-to-machine-learning—ud120
https://www.coursera.org/learn/machine-learning
我们就开始吧!
理解 TensorFlow
TensorFlow 不是一个标准的 Python 库
大多数 Python 库被编写为 Python 的自然扩展形式。当你导入一个库时,你得到的是一组变量、函数和类,他们扩展并补充了你的代码「工具箱」。当你使用它们时,你能预期到返回的结果是怎样的。在我看来,当谈及 TensorfFlow 时,应该把这种认知完全抛弃。思考什么是 TensorFlow 及其如何与其他代码进行交互从根本上来说就是错误的。
Python 和 TensorFlow 之间的关系可以类比 Javascript 和 HTML 之间的关系。Javascript 是一种全功能的编程语言,可以做各种美妙的事情。HTML 是用于表示某种类型的实用计算抽象(此处指可由 Web 浏览器呈现的内容)的框架。Javascript 在交互式网页中的作用是组装浏览器看到的 HTML 对象,然后在需要时通过将其更新为新的 HTML 来与其交互。
与 HTML 类似,TensorFlow 是用于表示某种类型的计算抽象(称为「计算图」)的框架。但我们用 Python 操作 TensorFlow 时,我们用 Pyhton 代码做的第一件事就是构建计算图。一旦完成,我们做的第二件事就是与它进行交互(启动 TensorFlow 的「会话」)。但重要的是,要记住计算图不在变量内部;而是处在全局命名空间中。正如莎士比亚所说:「所有的 RAM 都是一个阶段,所有的变量都仅仅是指针」
第一个关键抽象:计算图
当你在浏览 TensorFlow 文档时,可能会发现对「图形」和「节点」的间接引用。如果你仔细阅读,你甚至可能已经发现了这个页面(https://www.tensorflow.org/programmers_guide/graphs),该页面涵盖了我将以更准确和技术化的方式去解释的内容。本节是一篇高级攻略,把握重要的直觉概念,同时忽略一些技术细节。
那么:什么是计算图?它本质上是一个全局数据结构:是一个有向图,用于捕获有关如何计算的指令。
让我们来看看构建计算图的一个示例。在下图中,上半部分是我们运行的代码及其输出,下半部分是生成的计算图。
import tensorflow as tf计算图:

可见,仅仅导入 TensorFlow 并不会给我们生成一个有趣的计算图。而只是一个单独的,空白的全局变量。但当我们调用一个 TensorFlow 操作时,会发生什么?
代码:
import tensorflow as tf
two_node = tf.constant(2)
print two_node输出:
Tensor("Const:0", shape=(), dtype=int32)计算图:
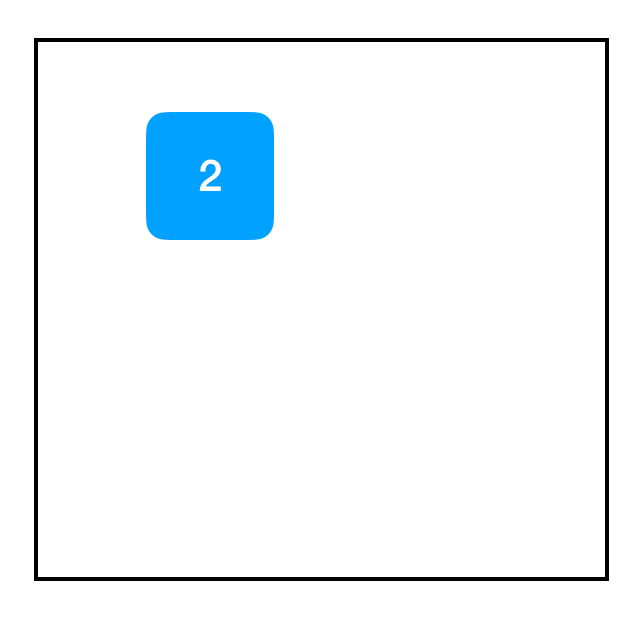
快看!我们得到了一个节点。它包含常量 2。很惊讶吧,这来自于一个名为 tf.constant 的函数。当我们打印这个变量时,我们看到它返回一个 tf.Tensor 对象,它是一个指向我们刚刚创建的节点的指针。为了强调这一点,以下是另外一个示例:
代码:
import tensorflow as tf
two_node = tf.constant(2)
another_two_node = tf.constant(2)
two_node = tf.constant(2)
tf.constant(3)计算图:
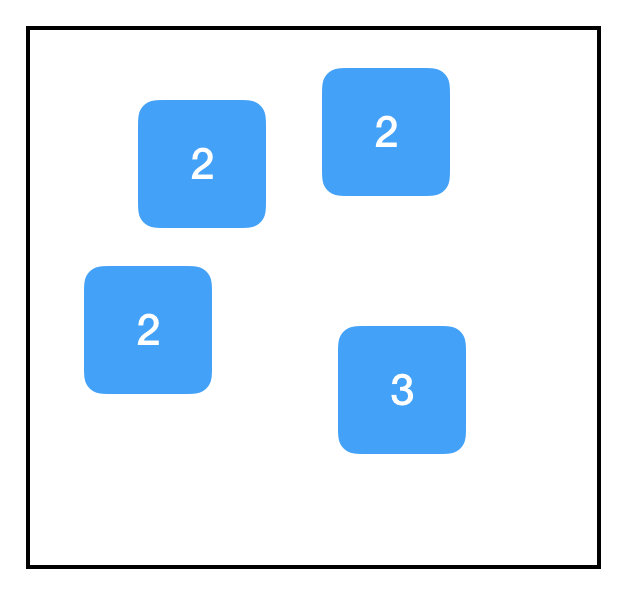
每次我们调用 tf.constant 时,我们都会在图中创建一个新的节点。即使该节点的功能与现有节点相同,即使我们将节点重新分配给同一个变量,或者即使我们根本没有将其分配给一个变量,结果都是一样的。
代码:
import tensorflow as tf
two_node = tf.constant(2)
another_pointer_at_two_node = two_node
two_node = None
print two_node
print another_pointer_at_two_node输出:
None
Tensor("Const:0", shape=(), dtype=int32)计算图:

好啦,让我们更进一步:
代码:
import tensorflow as tf
two_node = tf.constant(2)
three_node = tf.constant(3)
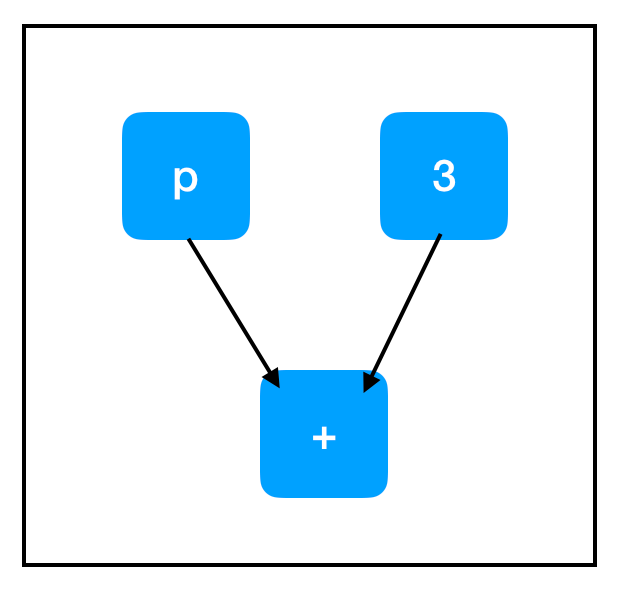
sum_node = two_node + three_node ## equivalent to tf.add(two_node, three_node)计算图:
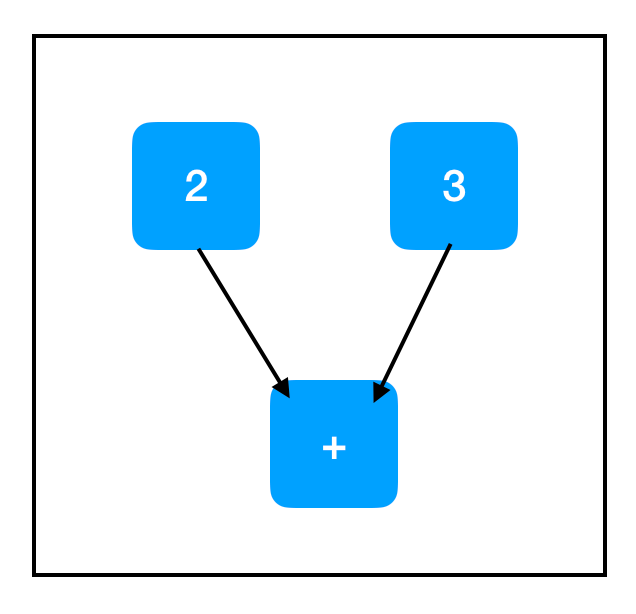
现在我们正谈论—这才是我们真正想要的计算图!请注意,+ 操作在 TensorFlow 中过载,因此同时添加两个张量会在图中增加一个节点,尽管它表面上看起来不像是 TensorFlow 操作。
那好,所以 two_node 指向包含 2 的节点,three_node 指向包含 3 的节点,同时 sum_node 指向包含 ...+ 的节点?怎么回事?它不是应该包含 5 吗?
事实证明,并没有。计算图只包含计算步骤;不包含结果。至少……现在还没有!
第二个关键抽象: 会话
如果错误地理解 TensorFlow 抽象概念也有个「疯狂三月」(NCAA 篮球锦标赛,大部分在三月进行),那么会话将成为每年的一号种子选手。会话有着那样令人困惑的殊荣是因为其反直觉的命名却又普遍存在—几乎每个 TensorFlow 呈现都至少一次明确地调用 tf.Session()。
会话的作用是处理内存分配和优化,使我们能够实际执行由计算图指定的计算。你可以将计算图想象为我们想要执行的计算的「模版」:它列出了所有步骤。为了使用计算图,我们需要启动一个会话,它使我们能够实际地完成任务;例如,遍历模版的所有节点来分配一堆用于存储计算输出的存储器。为了使用 TensorFlow 进行各种计算,你既需要计算图也需要会话。
会话包含一个指向全局图的指针,该指针通过指向所有节点的指针不断更新。这意味着在创建节点之前还是之后创建会话都无所谓。
创建会话对象后,可以使用 sess.run(node) 返回节点的值,并且 TensorFlow 将执行确定该值所需的所有计算。
代码:
import tensorflow as tf
two_node = tf.constant(2)
three_node = tf.constant(3)
sum_node = two_node + three_node
sess = tf.Session()
print sess.run(sum_node)输出:
5计算图:
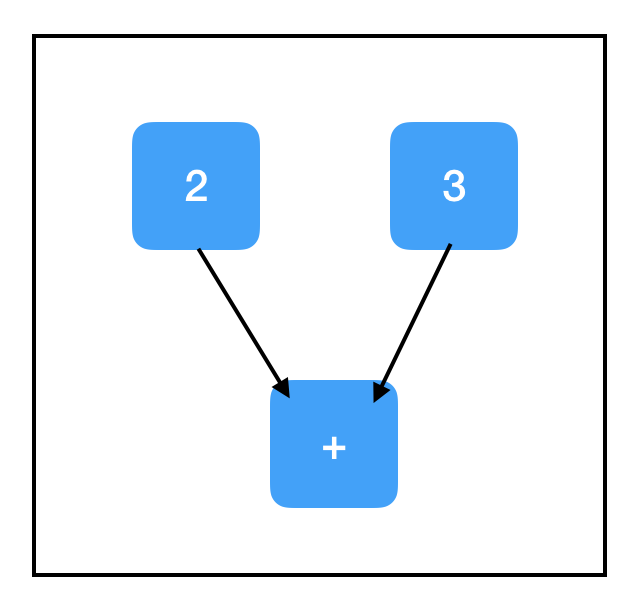
太好了!我们也可以传递一个列表,sess.run([node1, node2, ...]),并让它返回多个输出:
代码:
import tensorflow as tf
two_node = tf.constant(2)
three_node = tf.constant(3)
sum_node = two_node + three_node
sess = tf.Session()
print sess.run([two_node, sum_node])
输出:
[2, 5]计算图:
一般来说,sess.run() 的调用往往是 TensorFlow 最大的瓶颈之一,因此调用它的次数越少越好。如果可以的话,在一个 sess.run() 的调用中返回多个项目,而不是进行多个调用。
占位符和 feed_dict
迄今为止,我们所做的计算一直很乏味:没有机会获得输入,所以它们总是输出相同的东西。一个更有价值的应用可能涉及构建一个计算图,它接受输入,以某种(一致)方式处理它,并返回一个输出。
最直接的方法是使用占位符。占位符是一种用于接受外部输入的节点。
代码:
import tensorflow as tf
input_placeholder = tf.placeholder(tf.int32)
sess = tf.Session()
print sess.run(input_placeholder)输出:
Traceback (most recent call last):
...
InvalidArgumentError (see above *for* traceback): You must feed a value *for* placeholder tensor 'Placeholder' *with* dtype int32
[[Node: Placeholder = Placeholder[dtype=DT_INT32, shape=<unknown>, _device="/job:localhost/replica:0/task:0/device:CPU:0"]()]]计算图:

... 这是一个糟糕的例子,因为它引发了一个异常。占位符预计会被赋予一个值。但我们没有提供一个值,所以 TensorFlow 崩溃了。
为了提供一个值,我们使用 sess.run() 的 feed_dixt 属性。
代码:
import tensorflow as tf
input_placeholder = tf.placeholder(tf.int32)
sess = tf.Session()
print sess.run(input_placeholder, feed_dict={input_placeholder: 2})输出:
2计算图:

这就好多了。注意传递给 feed_dict 的 dict 格式,其关键应该是与图中的占位符节点相对应的变量(如前所述,它实际上意味着指向图中占位符节点的指针)。相应的值是要分配给每个占位符的数据元素——通常是标量或 Numpy 数组。
第三个关键抽象:计算路径
让我们看看另一个使用占位符的示例:
代码:
import tensorflow as tf
input_placeholder = tf.placeholder(tf.int32)
three_node = tf.constant(3)
sum_node = input_placeholder + three_node
sess = tf.Session()
print sess.run(three_node)
print sess.run(sum_node)输出:
3
Traceback (most recent call last):
...
InvalidArgumentError (see above for traceback): You must feed a value *for* placeholder tensor 'Placeholder_2' with dtype int32
[[Node: Placeholder_2 = Placeholder[dtype=DT_INT32, shape=<unknown>, _device="/job:localhost/replica:0/task:0/device:CPU:0"]()]]
计算图:
为什么第二次调用 sess.run() 会失败?即使我们没有评估 input_placeholder,为什么仍会引发与 input_placeholder 相关的错误?答案在于最终的关键 TensorFlow 抽象:计算路径。幸运的是,这个抽象非常直观。
当我们在依赖于图中其他节点的节点上调用 sess.run() 时,我们也需要计算那些节点的值。如果这些节点具有依赖关系,那么我们需要计算这些值(依此类推……),直到达到计算图的「顶端」,即节点没有父节点时。
sum_node 的计算路径:
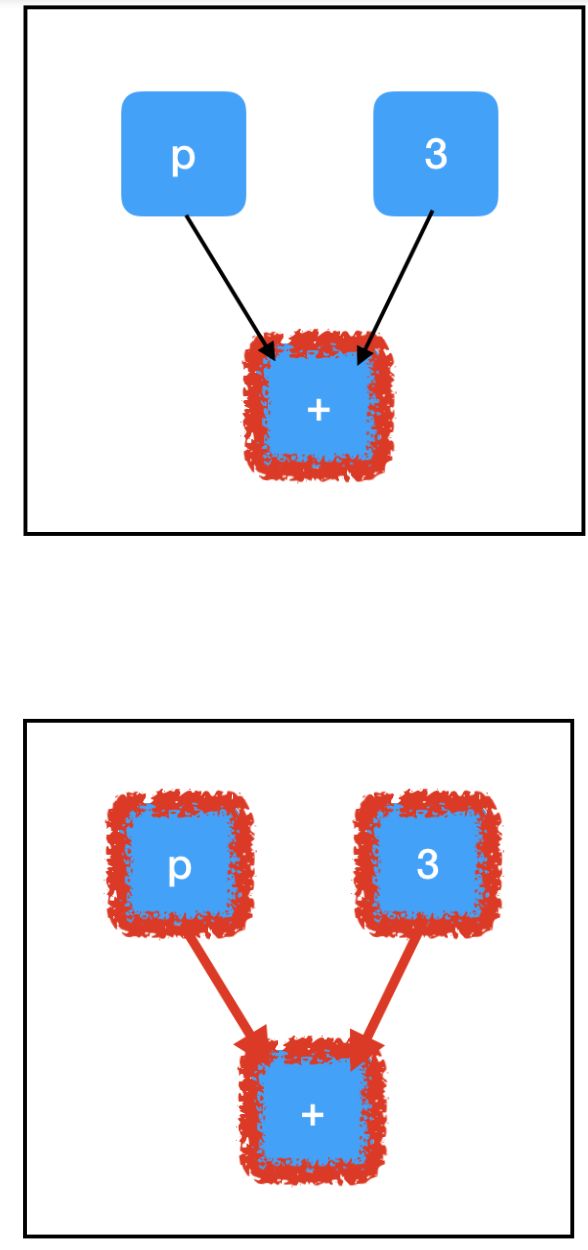
所有三个节点都需要进行求值以计算 sum_node 的值。最重要的是,这包含了我们未填充的占位符,并解释了异常!
现在来看 three_node 的计算路径:
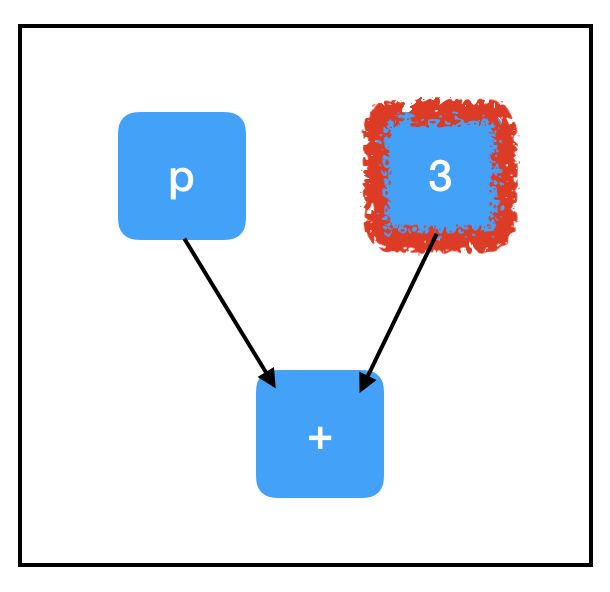
根据图结构,我们不需要计算所有节点才能评估我们想要的节点!因为我们在评估 three_node 时不需要评估 placehoolder_node,所以运行 sess.run(three_node) 不会引发异常。
TensorFlow 仅通过必需的节点自动进行计算这一事实是该框架的一个巨大优势。如果计算图非常大并且有许多不必要的节点,那么它可以节省大量调用的运行时间。它允许我们构建大型的「多用途」计算图,这些计算图使用单个共享的核心节点集合,并根据所采取的不同计算路径去做不同的事情。对于几乎所有应用而言,根据所采取的计算路径考虑 sess.run() 的调用是很重要的。
变量 & 副作用
至此,我们已经看到两种类型的「无祖先」节点(no-ancestor node):每次运行都一样的 tf.constant 和每次运行都不一样的 tf.placeholder。我们常常要考虑第三种情况:一个通常在运行时保持值不变的节点也可以被更新为新值。
这时就需要引入变量。
变量对于使用 TensorFlow 进行深度学习是至关重要的,因为模型的参数就是变量。在训练期间,你希望通过梯度下降在每个步骤更新参数;但在评估时,你希望保持参数不变,并将大量不同的测试集输入模型。通常,模型所有可训练参数都是变量。
要创建变量,就需要使用 tf.get_variable()。tf.get_variable() 的前两个参数是必需的,其余参数是可选的。它们是 tf.get_variable(name,shape)。name 是一个唯一标识这个变量对象的字符串。它必须相对于全局图是唯一的,所以要明了你使用过的所有命名,确保没有重复。shape 是与张量形状对应的整数数组,它的语法非常直观:按顺序,每个维度只有一个整数。例如,一个 3x8 矩阵形状是 [3, 8]。要创建一个标量,就需要使用形状为 [] 的空列表。
代码:
import tensorflow as tf
count_variable = tf.get_variable("count", [])
sess = tf.Session()
print sess.run(count_variable)输出:
Traceback (most recent call last):
...
tensorflow.python.framework.errors_impl.FailedPreconditionError: Attempting to use uninitialized value count
[[Node: _retval_count_0_0 = _Retval[T=DT_FLOAT, index=0, _device="/job:localhost/replica:0/task:0/device:CPU:0"](count)]]计算图:

噫,另一个异常。当首次创建变量节点时,它的值基本上为「null」,并且任何试图对它求值的操作都会引发这个异常。我们只能在将值放入变量之后才能对其求值。主要有两种将值放入变量的方法:初始化器和 tf.assign()。我们先看看 tf.assign():
代码:
import tensorflow as tf
count_variable = tf.get_variable("count", [])
zero_node = tf.constant(0.)
assign_node = tf.assign(count_variable, zero_node)
sess = tf.Session()
sess.run(assign_node)
print sess.run(count_variable)输出:
0计算图:
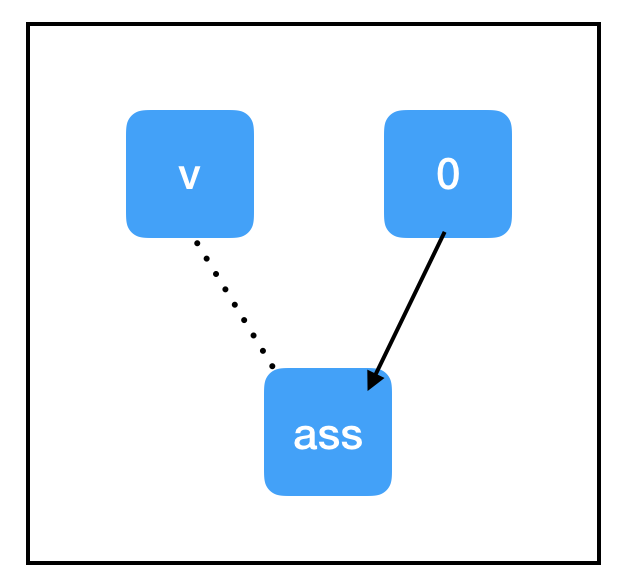
与我们迄今为止见过的节点相比,tf.assign(target, value) 是具备一些独特属性:
恒等运算。tf.assign(target, value) 不做任何有趣的运算,通常与 value 相等。
副作用。当计算「流经」assign_node 时,副作用发生在图中的其他节点上。此时,副作用是用存储在 zero_node 中的值替换 count_variable 的值。
非依赖边。即使 count_variable 节点和 assign_node 在图中是相连的,但它们彼此独立。这意味着计算任一节点时,计算不会通过边回流。然而,assign_node 依赖于 zero_node,它需要知道分配了什么。
「副作用」节点支撑着大部分 Tensorflow 深度学习工作流程,所以请确保自己真正理解了在该节点发生的事情。当我们调用 sess.run(assign_node) 时,计算路径会通过 assign_node 和 zero_node。
计算图:
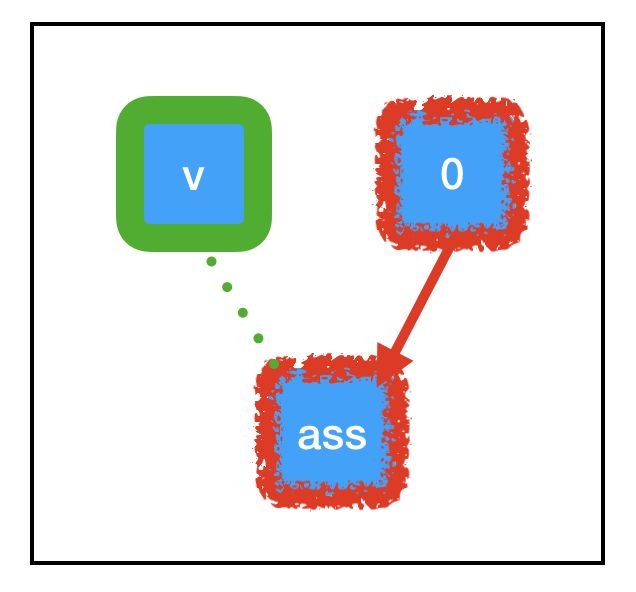
当计算流经图中的任何节点时,它还会执行由该节点控制的任何副作用,如图中绿色所示。由于 tf.assign 的特殊副作用,与 count_variable(之前为「null」)关联的内存现在被永久设置为 0。这意味着当我们下一次调用 sess.run(count_variable) 时,不会引发任何异常。相反,我们会得到 0 值。成功!
接下来,让我们看看初始化器:
代码:
import tensorflow as tf
const_init_node = tf.constant_initializer(0.)
count_variable = tf.get_variable("count", [], initializer=const_init_node)
sess = tf.Session()
print sess.run([count_variable])输出:
Traceback (most recent call last):
...
tensorflow.python.framework.errors_impl.FailedPreconditionError: Attempting to use uninitialized value count
[[Node: _retval_count_0_0 = _Retval[T=DT_FLOAT, index=0, _device="/job:localhost/replica:0/task:0/device:CPU:0"](count)]]计算图:
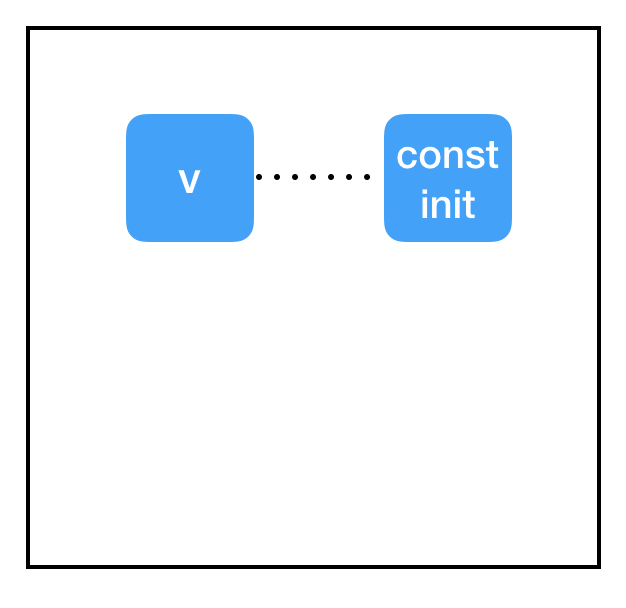
那好,这里发生了什么?为什么初始化器不工作?
问题出现在会话和图之间的分离。我们已将 get_variable 的 initializer 属性设置为指向 const_init_node,但它只是在图中的节点之间添加了一个新的连接。我们还没有做任何解决异常根源的事:与变量节点(存储在会话中,而不是计算图中)相关联的内存仍然设置为「null」。我们需要通过会话使 const_init_node 去更新变量。
代码:
import tensorflow as tf
const_init_node = tf.constant_initializer(0.)
count_variable = tf.get_variable("count", [], initializer=const_init_node)
init = tf.global_variables_initializer()
sess = tf.Session()
sess.run(init)
print sess.run(count_variable)输出:
0计算图:
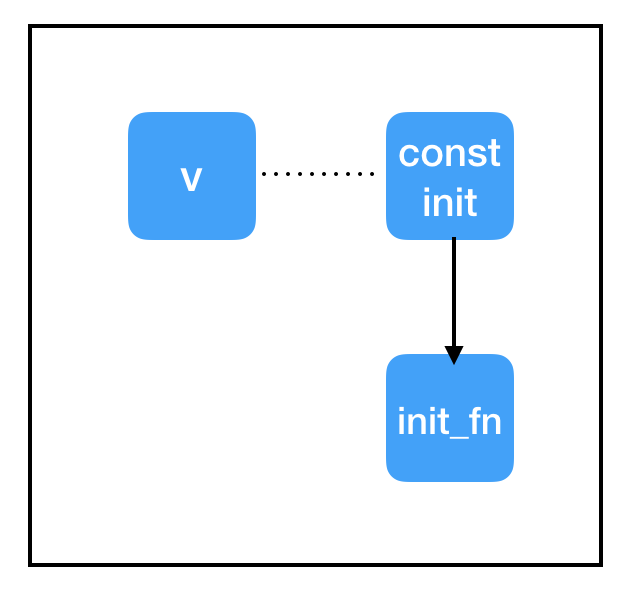
为此,我们添加另一个特殊的节点:init = tf.global_variables_initializer()。与 tf.assign() 类似,这是一个带有副作用的节点。与 tf.assign() 相反,实际上我们不需要指定它的输入是什么!tf.global_variables_initializer() 将在其创建时查看全局图并自动将依赖关系添加到图中的每个 tf.initializer。当我们在之后使用 sess.run(init) 对它求值时,它会告诉每个初始化程序执行变量初始化,并允许我们运行 sess.run(count_variable) 而不出错。
变量共享
你可能会遇到带有变量共享的 Tensorflow 代码,其涉及创建作用域并设置「reuse = True」。我强烈建议不要在自己的代码中使用变量共享。如果你想在多个地方使用单个变量,只需以编程方式记录指向该变量节点的指针,并在需要时重新使用它。换言之,对于想要保存在内存中的每个变量,你只需要调用一次 tf.get_variable()。
优化器
最后:进行真正的深度学习!如果你跟上我的节奏,那么其余概念对你来说应该非常简单。
在深度学习中,典型的「内循环」训练如下:
1. 获取输入和 true_output
2. 根据输入和参数计算「推测」值
3. 根据推测与 true_output 之间的差异计算「损失」
4. 根据损失的梯度更新参数
让我们把所有东西放在一个快速脚本里,解决简单的线性回归问题:
代码:
import tensorflow as tf
### build the graph## first set up the parameters
m = tf.get_variable("m", [], initializer=tf.constant_initializer(0.))
b = tf.get_variable("b", [], initializer=tf.constant_initializer(0.))
init = tf.global_variables_initializer()
## then set up the computations
input_placeholder = tf.placeholder(tf.float32)
output_placeholder = tf.placeholder(tf.float32)
x = input_placeholder
y = output_placeholder
y_guess = m * x + b
loss = tf.square(y - y_guess)
## finally, set up the optimizer and minimization node
optimizer = tf.train.GradientDescentOptimizer(1e-3)
train_op = optimizer.minimize(loss)
### start the session
sess = tf.Session()
sess.run(init)
### perform the training loop*import* random
## set up problem
true_m = random.random()
true_b = random.random()
*for* update_i *in* range(100000):
## (1) get the input and output
input_data = random.random()
output_data = true_m * input_data + true_b
## (2), (3), and (4) all take place within a single call to sess.run()!
_loss, _ = sess.run([loss, train_op], feed_dict={input_placeholder: input_data, output_placeholder: output_data})
*print* update_i, _loss
### finally, print out the values we learned for our two variables*print* "True parameters: m=%.4f, b=%.4f" % (true_m, true_b)*print* "Learned parameters: m=%.4f, b=%.4f" % tuple(sess.run([m, b]))输出:
0 2.32053831 0.57927422 1.552543 1.57332594 0.64356485 2.40612656 1.07462567 2.19987158 1.67751169 1.646242310 2.441034
...99990 2.9878322e-1299991 5.158629e-1199992 4.53646e-1199993 9.422685e-1299994 3.991829e-1199995 1.134115e-1199996 4.9467985e-1199997 1.3219648e-1199998 5.684342e-1499999 3.007017e-11*True* parameters: m=0.3519, b=0.3242
Learned parameters: m=0.3519, b=0.3242就像你看到的一样,损失基本上变为零,并且我们对真实参数进行了很好的估计。我希望你只对代码中的以下部分感到陌生:
## finally, set up the optimizer and minimization node
optimizer = tf.train.GradientDescentOptimizer(1e-3)
train_op = optimizer.minimize(loss)但是,既然你对 Tensorflow 的基本概念有了很好的理解,这段代码就很容易解释!第一行,optimizer = tf.train.GradientDescentOptimizer(1e-3) 不会向计算图中添加节点。它只是创建一个包含有用的帮助函数的 Python 对象。第二行,train_op = optimizer.minimize(loss) 将一个节点添加到图中,并将一个指针存储在变量 train_op 中。train_op 节点没有输出,但是有一个十分复杂的副作用:
train_op 回溯输入和损失的计算路径,寻找变量节点。对于它找到的每个变量节点,计算该变量对于损失的梯度。然后计算该变量的新值:当前值减去梯度乘以学习率的积。最后,它执行赋值操作更新变量的值。
因此基本上,当我们调用 sess.run(train_op) 时,它对我们的所有变量做了一个梯度下降的步骤。当然,我们也需要使用 feed_dict 填充输入和输出占位符,并且我们还希望打印损失的值,因为这样方便调试。
用 tf.Print 调试
当你用 Tensorflow 开始做更复杂的事情时,你需要进行调试。一般来说,检查计算图中发生了什么是相当困难的。因为你永远无法访问你想打印的值—它们被锁定在 sess.run() 的调用中,所以你不能使用常规的 Python 打印语句。具体来说,假设你是想检查一个计算的中间值。在调用 sess.run() 之前,中间值还不存在。但是,当你调用的 sess.run() 返回时,中间值又不见了!
让我们看一个简单的示例。
代码:
import tensorflow as tf
two_node = tf.constant(2)
three_node = tf.constant(3)
sum_node = two_node + three_node
sess = tf.Session()
print sess.run(sum_node)输出:
5这让我们看到了答案是 5。但是,如果我们想要检查中间值,two_node 和 three_node,怎么办?检查中间值的一个方法是向 sess.run() 中添加一个返回参数,该参数指向要检查的每个中间节点,然后在返回后,打印它的值。
代码:
import tensorflow as tf
two_node = tf.constant(2)
three_node = tf.constant(3)
sum_node = two_node + three_node
sess = tf.Session()
answer, inspection = sess.run([sum_node, [two_node, three_node]])
print inspection
print answer
输出:
[2, 3]5这通常是有用的,但当代码变得越来越复杂时,这可能有点棘手。一个更方便的方法是使用 tf.Print 语句。令人困惑的是,tf.Print 实际上是一种具有输出和副作用的 Tensorflow 节点!它有两个必需参数:要复制的节点和要打印的内容列表。「要复制的节点」可以是图中的任何节点;tf.Print 是一个与「要复制的节点」相关的恒等操作,意味着输出的是输入的副本。但是,它的副作用是打印出「打印列表」里的所有当前值。
代码:
import tensorflow as tf
two_node = tf.constant(2)
three_node = tf.constant(3)
sum_node = two_node + three_node
print_sum_node = tf.Print(sum_node, [two_node, three_node])
sess = tf.Session()
print sess.run(print_sum_node)
输出:
[2][3]5计算图:
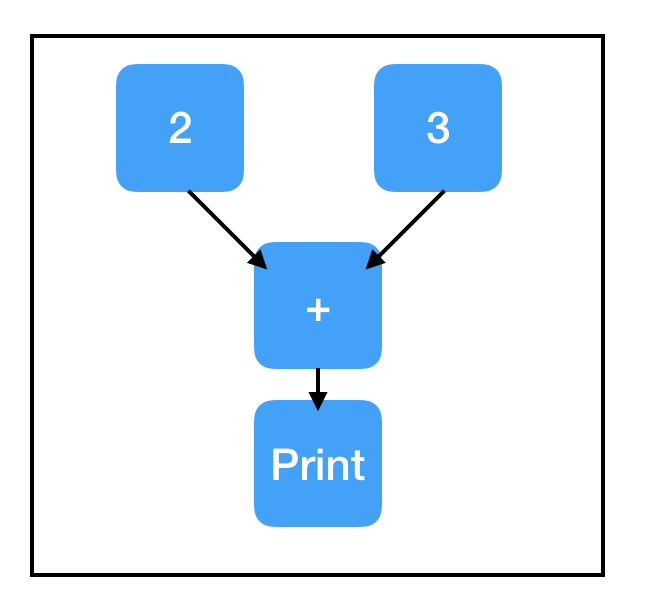
有关 tf.Print 一个重要且有点微妙的点:打印是一个副作用。像所有其他副作用一样,只要在计算流经 tf.Print 节点时才会进行打印。如果 tf.Print 节点不在计算路径上,则不会打印任何内容。特别的是,即使 tf.Print 节点正在复制的原始节点位于计算路径上,但 tf.Print 节点本身可能不在。请注意这个问题!当这种情况发生时(总会发生的),如果你没有明确地找到问题所在,它会让你感到十分沮丧。一般来说,最好在创建要复制的节点后,立即创建你的 tf.Print 节点。
代码:
import tensorflow as tf
two_node = tf.constant(2)
three_node = tf.constant(3)
sum_node = two_node + three_node### this new copy of two_node is not on the computation path, so nothing prints!
print_two_node = tf.Print(two_node, [two_node, three_node, sum_node])
sess = tf.Session()
print sess.run(sum_node)
输出:
5计算图:

这里有一个很好的资源(https://wookayin.github.io/tensorflow-talk-debugging/#1),它提供了其他一些实用的调试建议。
结论
希望这篇博文可以帮助你更好地理解什么是 Tensorflow,它是如何工作的以及怎么使用它。总而言之,本文介绍的概念对所有 Tensorflow 项目都很重要,但只是停留在表面。在你探索 Tensorflow 的旅程中,你可能会遇到其他各种你需要的有趣概念:条件、迭代、分布式 Tensorflow、变量作用域、保存和加载模型、多图、多会话和多核、数据加载器队列等等。我将在未来的博文中讨论这些主题。但如果你使用官方文档、一些代码示例和一点深度学习的魔力来巩固你在本文学到的思想,我相信你一定可以弄明白 Tensorflow!

原文链接:https://jacobbuckman.com/post/tensorflow-the-confusing-parts-1/
当地时间 7 月 14 日,腾讯将在斯德哥尔摩举办 Tencent Academic and Industrial Conference (TAIC),诚邀全球顶尖 AI 学者、青年研究员与腾讯七大事业群专家团队探讨最前沿 AI 研究与应用。点击阅读原文,参与报名。




