文本分类综述 | 迈向NLP大师的第一步(下)

NewBeeNLP公众号原创出品
公众号专栏作者 @lucy
北航博士在读 · 文本挖掘/事件抽取方向
本系列文章总结自然语言处理(NLP)中最基础最常用的「文本分类」任务,主要包括以下几大部分:
-
综述(Surveys) -
深度网络方法(Deep Learning Models) -
浅层网络模型(Shallow Learning Models) -
数据集(Datasets) -
评估方式(Evaluation Metrics) -
展望研究与挑战(Future Research Challenges) -
实用工具与资料(Tools and Repos)
-
https://arxiv.org/abs/2008.00364
-
https://github.com/xiaoqian19940510/text-classification-surveys
文本分类综述
A Survey on Text Classification: From Shallow to Deep Learning,2020[1]
文本分类是自然语言处理中最基本,也是最重要的任务。由于深度学习的成功,在过去十年里该领域的相关研究激增。鉴于已有的文献已经提出了许多方法,数据集和评估指标,因此更加需要对上述内容进行全面的总结。
本文通过回顾1961年至2020年的最新方法填补来这一空白,主要侧重于从浅层学习模型到深度学习模型。我们首先根据方法所涉及的文本,以及用于特征提取和分类的模型,构建了一个对不同方法进行分类的规则。然后我们将详细讨论每一种类别的方法,涉及该方法相关预测技术的发展和基准数据集。
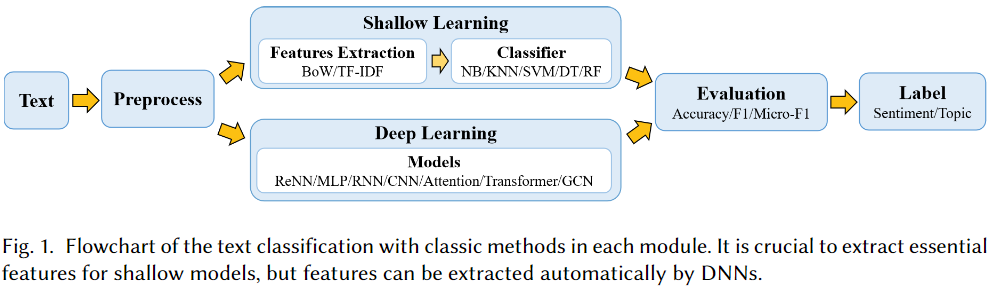
此外,本综述还提供了不同方法之间的全面比较,并确定了各种评估指标的优缺点。最后,我们总结了该研究领域的关键影响因素,未来研究方向以及所面临的挑战。
数据集
情感分析数据集
情感分析(Sentiment Analysis,SA)是在情感色彩中对主观文本进行分析和推理的过程。通过分析文本来判断作者是否支持特定观点的信息至关重要,这与分析文本客观内容的传统文本分类任务不同。
SA可以是二分类也可以是多分类,
-
Binary SA将文本分为两类,包括肯定和否定; -
多类SA将文本分类为多级或细粒度更高的不同标签。
Movie Review (MR) 电影评论数据集[2]
MR是电影评论数据集, 其中每个样本对应一个句子。语料库有5,331个积极样本和5,331个消极样本。该数据集通常通过随机划分的10折交叉验证来验证模型效果。
Stanford Sentiment Treebank (SST) 斯坦福情感库[3]
SST是MR的扩展,它有两个不同版本。
-
SST-1带有五类细粒度标签。它分别具有8,544个训练文本和2,210个测试文本。 -
SST-2则有两类标签,9,613个的文本,这些文本被分为6,920个训练文本,872个开发文本和1,821个测试文本。
The Multi-Perspective Question Answering (MPQA)多视角问答数据集[4]
MPQA是意见数据集。它有两个类别标签,还有一个MPQA意见极性检测子任务数据集。MPQA包括从各种来源的新闻文章中提取的10606个句子。应当指出的是,它包含3,311个积极文本和7,293个消极文本,每个文本没有标签。
IMDB reviews IMDB评论[5]
IMDB评论专为电影评论的二元情感分类而开发,每个类别中的评论数量相同。可以将其平均分为培训和测试组,每组25,000条评论。
Yelp reviews Yelp评论[6]
Yelp评论数据集总结自2013、2014和2015年的Yelp数据集挑战。此数据集有两个版本。
-
Yelp-2被用于消极和积极情绪分类任务,包括560,000个训练文本和38,000测试文本。 -
Yelp-5用于细粒度情感多分类任务,包含650,000个训练文本和50,000测试文本。
Amazon Reviews (AM) 亚马逊评论数据集[7]
AM是通过收集亚马逊网站的产品评论而形成的流行语料库。该数据集有两个不同版本。
-
具有两个类别的Amazon-2包括3,600,000个训练样本和400,000个测试样本。 -
Amazon-5具有五个类别,包括3,000,000个训练样本和650,000个测试样本。
新闻分类数据集
新闻内容是最关键的信息来源之一,对人们的生活具有重要的影响。数控系统方便用户实时获取重要知识。新闻分类应用主要包括:识别新闻主题并根据用户兴趣推荐相关新闻。新闻分类数据集包括20NG,AG,R8,R52,Sogou等。在这里,我们详细介绍了一些主要数据集。
20 Newsgroups (20NG)[8]
20NG是新闻组文本数据集。它有20个类别,每个类别样本数目相同,一共包含18,846篇文本。
AG News (AG)[9]
AG新闻是搜索学术界新闻的搜索引擎,它选择了四个规模最大的类别。它使用每个新闻的标题和描述字段。AG包含用于训练的120,000个文本和用于测试的7,600个文本。
R8 and R52[10]
R8和R52是路透社新闻的两个子集。R8有8个类别,分为2189个测试样本和5485个训练样本。R52有52个类别,分为6,532个训练样本和2,568个测试样本。
Sogou News (Sogou) 搜狗新闻[11]
搜狗新闻数据集包含搜狗CA新闻集和搜狗CS新闻集。每个文本的标签是URL中的域名。
话题标签数据集
DBpedia[12]
DBpedia是使用Wikipedia最常用的信息框生成的大规模多语言知识库。每个月都会发布新版本的DBpedia,并在每个版本中添加或删除类和属性。DBpedia最流行的版本有14个类别,包含560,000个训练数据和70,000个测试数据。
Ohsumed[13]
Ohsumed隶属于MEDLINE数据库。它包括7,400个文本,并有23种心血管疾病类别。所有文本均为医学摘要,并被标记为一个或多个类。
Yahoo answers (YahooA) 雅虎问答[14]
YahooA是具有10个类的话题标记数据集。它包括140,000个训练数据和5,000个测试数据。所有文本均包含三个元素,分别是问题标题,问题上下文和最佳答案。
Question Answering (QA) 问答数据集
问答任务可以分为两种:抽取式问答(extractiveQA)和生成式问答(extractiveQA)。抽取式问答为每个问题提供了多个候选答案,以选择哪个是正确答案。因此,文本分类模型可以用于抽取式问答任务。
QA系统可以使用文本分类模型来识别正确答案,并将其他答案设置为候选答案。问答数据集包括SQuAD,MS MARCO,TREC-QA,WikiQA和Quora [209]。这里我们详细介绍了几个主要数据集。
Stanford Question Answering Dataset (SQuAD) 斯坦福问答数据集[15]
SQuAD是由从Wikipedia文章获得的问题和答案对构成的数据集。SQuAD有两个版本。SQuAD1.1包含536对,107,785个问答项目。SQuAD2.0将SQuAD1.1中的100,000个问题与超过50,000个无法回答的问题组合在一起。
MS MARCO[16]
MS MARCO包含问题和答案。Bing搜索引擎从实际的网络文本中抽取了问题和部分答案。其他则是生成的。该数据集用于开发Microsoft发布的生成质量保证系统。
TREC-QA[17]
TREC-QA包括5,452个训练文本和500个测试文本。它有两个版本。TREC-6包含6个类别,TREC-50包含50个类别。
WikiQA[18]
WikiQA数据集包含没有正确答案的问题,需要对答案进行评估。
自然语言推理数据集
NLI用于预测一个文本的含义是否可以从另一个文本推论得出。释义是NLI的一种广义形式。它使用测量句子对语义相似性的任务来确定一个句子是否是另一句子的解释。NLI数据集包括SNLI,MNLI,SICK,STS,RTE,SciTail,MSRP等。在这里,我们详细介绍了所有主要数据集。
The Stanford Natural Language Inference (SNLI)[19]
SNLI通常应用于NLI任务。它包含570,152个人工注释的句子对,包括训练,发展和测试集,并用三类注释:中立,包含和矛盾。
Multi-Genre Natural Language Inference (MNLI)[20]
Multi-NLI是SNLI的扩展,涵盖了更大范围的书面和口头文字类型。它包括433,000个句子对,并带有文本是否蕴含的标签。
Sentences Involving Compositional Knowledge (SICK)[21]
SICK包含将近10,000个英语句子对。它由中立,包含和矛盾的标签组成。
Microsoft Research Paraphrase (MSRP)[22]
MSRP由句子对组成,通常用于文本相似性任务。每对都用二进制标签注释,以区分它们是否由蕴含关系。它包括1,725个训练样本和4,076个测试样本。
对话行为分类数据集
对话行为基于语义,语用和句法标准来描述对话中的话语。DAC根据其含义类别标记一个对话框,并帮助理解讲话者的意图。它是根据对话框给标签。在这里,我们详细介绍了所有主要数据集,包括DSTC 4,MRDA和SwDA。
Dialog State Tracking Challenge 4 (DSTC 4)[23]
DSTC 4用于对话行为分类。它有89个类别,24,000个训练文本和6,000个测试文本。
CSI Meeting Recorder Dialog Act (MRDA)[24]
MRDA用于对话行为分类。它有5个样本类别,51,000个训练文本,11,000个测试文本和11,000个验证文本。
Switchboard Dialog Act (SwDA)[25]
SwDA用于对话行为分类。它拥有43个训练类别,1,003,000个训练文本,19,000个测试文本和112,000个验证文本。
多标签数据集
在多标签分类中,一个实例具有多个标签,并且每个la-bel只能采用多个类之一。有许多基于多标签文本分类的数据集。它包括路透社,Education,Patent,RCV1,RCV1-2K,AmazonCat-13K,BlurbGen-reCollection,WOS-11967,AAPD等。这里我们详细介绍了一些主要数据集。
Reuters news[26]
路透社新闻数据集是路透社金融新闻服务进行文本分类的常用数据集。它具有90个训练类别,7,769个训练文本和3,019个测试文本,其中包含多个标签和单个标签。它还有一些子数据集,例如R8,BR52,RCV1和RCV1-v2。
Patent Dataset[27]
专利数据集是从USPTO1获得的,USPTO1是美国的专利系统,包含文字详细信息(例如标题和摘要)的专利。它包含在现实世界中授予的100,000种美国专利,具有多个层次类别。
Reuters Corpus Volume I (RCV1) and RCV1-2K[28]
RCV1是从1996-1997年的《路透社新闻》文章中收集的, 带有103个类别的人工标注标签。它分别由23,149个训练和784,446个测试文本组成。RCV1-2K数据集具有与RCV1相同的功能。但是,RCV1-2K的标签集已经扩展了一些新标签。它包含2456个标签。
Web of Science (WOS-11967)[29]
WOS-11967是从Web of Science爬取的,它由已发表论文的摘要组成,每个示例带有两个标签。该数据集样本数较少,但覆盖面明显更广泛,总共有较少的类。
Arxiv Academic Paper Dataset (AAPD)[30]
AAPD是计算机科学领域中的大型数据集,用于来自website2的多标签文本分类。它拥有55,840篇论文,包括摘要和相应的主题,共有54个标签。目的是根据摘要预测每篇论文的主题。
评估方式
在评估文本分类模型方面,准确率和F1分数是评估文本分类方法最常用的指标。随着分类任务难度的增加或某些特定任务的存在,评估指标也得到了改进。例如P @ K和Micro-F1评估指标用于评估多标签文本分类性能,而MRR通常用于评估QA任务的性能。
单标签评价指标
单标签文本分类将文本划分为NLP任务(如QA,SA和对话系统)中最相似的类别之一。对于单标签文本分类,一个文本仅属于一个目录,这使得不考虑标签之间的关系成为可能。在这里,我们介绍一些用于单标签文本分类任务的评估指标。
Accuracy and Error Rate
准确性和错误率是文本分类模型的基本指标。准确度和错误率分别定义为:
Precision, Recall and F1
无论标准类型和错误率如何,这些都是用于不平衡测试集的重要指标。例如,大多数测试样本都具有类别标签。F1是Precision和Recall的谐波平均值。准确性,召回率和F1分数定义为:
当准确率、F1和recall值达到1时,就可以得到预期的结果。相反,当值为0时,得到的结果最差。对于多类分类问题,可以分别计算各类的查准率和查全率,进而分析个体和整体的性能。
Exact Match (EM)
EM是QA任务的度量标准,用于测量精确匹配所有正确答案的预测。它是SQuAD数据集上使用的主要指标。
Mean Reciprocal Rank (MRR)
MRR通常用于评估在问答(QA)和信息检索(IR)任务中排序算法的性能。
Hamming-loss (HL)
HL评估被错误分类的实例-标签对的得分,其中相关的标签被省略或不相关的标签被预测。
多标签评价指标
与单标签文本分类相比,多标签文本分类将文本分为多个类别标签,并且类别标签的数量是可变的。然而上述的度量标准是为单标签文本分类设计的,不适用于多标签任务。因此,存在一些为多标签文本分类而设计的度量标准。
Micro−F1
Micro-F1是一种考虑所有标签的整体精确率和召回率的措施。Micro-F1定义为:
Macro−F1
Marco-F1计算所有标签的平均F1分数。与Micro-F1(每个示例都设置权重)不同,Macro-F1在平均过程中为所有标签设置相同的权重。形式上,Macro-F1定义为
除了上述评估指标外,还有一些针对极端多标签分类任务的基于排序的评估指标,包括P @ K和NDCG @ K。
Precision at Top K (P@K)
其中P@K为排名第k处的准确率。P@K,每个文本有一组L个全局真标签Lt={l0,l1,l2...,lL−1}, 为了减少概率Pt=�p0,p1,p2...,pQ−1�。第k处的准确率为
Normalized Discounted Cummulated Gains (NDCG@K)
排名第k处的NDCG值
展望研究与挑战
文本分类作为有效的信息检索和挖掘技术-在管理文本数据中起着至关重要的作用。它使用NLP,数据挖掘,机器学习和其他技术来自动分类和发现不同的文本类型。
文本分类将多种类型的文本作为输入,并且文本由预训练模型表示为矢量。然后将向量馈送到DNN中进行训练,直到达到终止条件为止,最后,下游任务验证训练模型的性能。
现有的模型已经显示出它们在文本分类中的有用性,但是仍有许多可能的改进需要探索。尽管一些新的文本分类模型反复擦写了大多数分类任务的准确性指标,但它无法指示模型是否像人类一样从语义层面“理解”文本。
此外,随着噪声样本的出现,小的样本噪声可能导致决策置信度发生实质性变化,甚至导致决策逆转。因此,需要在实践中证明该模型的语义表示能力和鲁棒性。此外,由词向量表示的预训练语义表示模型通常可以提高下游NLP任务的性能。关于上下文无关单词向量的传输策略的现有研究仍是相对初步的。
因此,我们从数据,模型和性能的角度得出结论,文本分类主要面临以下挑战:
数据层面
对于文本分类任务,无论是浅层学习还是深度学习方法,数据对于模型性能都是必不可少的。研究的文本数据主要包括多篇章,短文本,跨语言,多标签,少样本文本。针对于这些数据的特质,现有的技术挑战如下:
零样本/少样本学习
用于文本分类的零样本或少样本学习旨在对没有或只有很少的相同标签类数据的文本进行分类。然而,当前模型过于依赖大量标记数据,它们的性能受零样本或少样本学习的影响很大。
因此,一些工作着重于解决这些问题,其主要思想是通过学习各种语义知识来推断特征,例如学习类之间的关系和合并类描述。此外,潜在特征生成、元学习和动态记忆力机制也是有效的方法。
尽管如此,由于少量未知类型的数据的限制以及已知和未知类别数据之间不同的数据分布,要达到与人类相当的学习能力还有很长的路要走。
引入外部知识
众所周知,将更多有益的信息输入到DNN中,其性能会更好。因此,添加外部知识(知识库或知识图谱)是提高模型性能的有效方法。现有知识包括概念信息,常识知识,知识库信息,通用知识图谱等,这些知识增强了文本的语义表示。然而,由于投入规模的限制,如何为不同任务增加知识以及增加什么样的外部知识仍然是一个挑战。
多标签文本分类任务
多标签文本分类需要充分考虑标签之间的语义关系,而模型的嵌入和编码是有损的压缩过程。因此,如何减少训练过程中层次语义的丢失以及如何保留丰富而复杂的文档语义信息仍然是一个亟待解决的问题。
具有许多术语的特殊领域的文本分类
特定领域的文本(例如金融和医学文本)包含许多特定的单词或领域专家才可理解的词汇,缩写等,这使得现有的预训练词向量难以使用。
模型层面
大多数现有的浅层和深度学习模型的结构可以用于文本分类,包括集成方法。BERT学习了一种可用于微调许多下游NLP任务语言表征形式。主要方法是增加数据,提高计算能力以及设计训练程序以获得更好的结果。如何在数据与计算资源以及预测性能之间进行权衡值得研究。
性能评估层面
浅层学习模型和深度学习模型可以在大多数文本分类任务中实现良好的性能,但是需要提高其结果的抗干扰能力。如何实现对深度模型的解释也是一个技术挑战。
模型的语义鲁棒性
近年来,研究人员设计了许多模型来增强文本分类模型的准确性。但是,如果数据集中有一些对抗性样本,则模型的性能会大大降低。因此,如何提高模型的鲁棒性是当前研究的热点和挑战。
模型的可解释性
DNN在特征提取和语义挖掘方面具有独特的优势,并且已经出色地完成了文本分类任务。但是,深度学习是一个黑盒模型,训练过程难以重现,隐层的语义和输出可解释性很差。尽管它对模型进行了改进和优化,但是却缺乏明确的指导。此外,我们无法准确解释为什么该模型可以提高性能。
本文是文本分类综述系列终结篇,我们整理好了全部的PDF版本以及 综述内涉及的所有文本分类必读论文清单,订阅号后台回复 『文本分类』 即可获取喔~
本文参考资料
A Survey on Text Classification: From Shallow to Deep Learning,2020: https://arxiv.org/pdf/2008.00364.pdf
[2]Movie Review (MR) 电影评论数据集: http://www.cs.cornell.edu/people/pabo/movie-review-data/
[3]Stanford Sentiment Treebank (SST) 斯坦福情感库: http://www.cs.uic.edu/∼liub/FBS/sentiment-analysis.html
[4]The Multi-Perspective Question Answering (MPQA)多视角问答数据集: http://www.cs.pitt.edu/mpqa/
[5]IMDB reviews IMDB评论: https://dblp.org/rec/bib/conf/kdd/DiaoQWSJW14
[6]Yelp reviews Yelp评论: https://dblp.org/rec/bib/conf/emnlp/TangQL15
[7]Amazon Reviews (AM) 亚马逊评论数据集: https://www.kaggle.com/datafiniti/consumer-reviews-of-amazon-products
[8]20 Newsgroups (20NG): http://ana.cachopo.org/datasets-for-single-label-text-categorization
[9]AG News (AG): http://www.di.unipi.it/~gulli/AG_corpus_of_news_articles.html
[10]R8 and R52: https://www.cs.umb.edu/~smimarog/textmining/datasets/
[11]Sogou News (Sogou) 搜狗新闻: https://dblp.org/rec/conf/cncl/SunQXH19.bib
[12]DBpedia: https://dblp.org/rec/journals/semweb/LehmannIJJKMHMK15.bib
[13]Ohsumed: http://davis.wpi.edu/xmdv/datasets/ohsumed.html
[14]Yahoo answers (YahooA) 雅虎问答: https://dblp.org/rec/bib/conf/nips/ZhangZL15
[15]Stanford Question Answering Dataset (SQuAD) 斯坦福问答数据集: https://dblp.org/rec/bib/conf/nips/ZhangZL15
[16]MS MARCO: https://dblp.org/rec/bib/conf/nips/ZhangZL15
[17]TREC-QA: https://dblp.org/rec/bib/conf/nips/ZhangZL15
[18]WikiQA: https://dblp.org/rec/bib/conf/nips/ZhangZL15
[19]The Stanford Natural Language Inference (SNLI): https://dblp.org/rec/bib/conf/nips/ZhangZL15
[20]Multi-Genre Natural Language Inference (MNLI): https://dblp.org/rec/bib/conf/nips/ZhangZL15
[21]Sentences Involving Compositional Knowledge (SICK): https://dblp.org/rec/bib/conf/nips/ZhangZL15
[22]Microsoft Research Paraphrase (MSRP): https://dblp.org/rec/bib/conf/nips/ZhangZL15
[23]Dialog State Tracking Challenge 4 (DSTC 4): https://dblp.org/rec/bib/conf/nips/ZhangZL15
[24]CSI Meeting Recorder Dialog Act (MRDA): https://dblp.org/rec/bib/conf/nips/ZhangZL15
[25]Switchboard Dialog Act (SwDA): https://dblp.org/rec/bib/conf/nips/ZhangZL15
[26]Reuters news: https://dblp.org/rec/bib/conf/nips/ZhangZL15
[27]Patent Dataset: https://dblp.org/rec/bib/conf/nips/ZhangZL15
[28]Reuters Corpus Volume I (RCV1) and RCV1-2K: https://dblp.org/rec/bib/conf/nips/ZhangZL15
[29]Web of Science (WOS-11967): https://dblp.org/rec/bib/conf/nips/ZhangZL15
[30]Arxiv Academic Paper Dataset (AAPD): https://dblp.org/rec/bib/conf/nips/ZhangZL15
- END -

由于微信平台算法改版,公号内容将不再以时间排序展示,如果大家想第一时间看到我们的推送,强烈建议星标我们和给我们多点点【在看】。星标具体步骤为:
(1)点击页面最上方"AINLP",进入公众号主页。
(2)点击右上角的小点点,在弹出页面点击“设为星标”,就可以啦。
感谢支持,比心

推荐阅读
征稿启示| 200元稿费+5000DBC(价值20个小时GPU算力)
完结撒花!李宏毅老师深度学习与人类语言处理课程视频及课件(附下载)
模型压缩实践系列之——bert-of-theseus,一个非常亲民的bert压缩方法
文本自动摘要任务的“不完全”心得总结番外篇——submodular函数优化
斯坦福大学NLP组Python深度学习自然语言处理工具Stanza试用
关于AINLP
AINLP 是一个有趣有AI的自然语言处理社区,专注于 AI、NLP、机器学习、深度学习、推荐算法等相关技术的分享,主题包括文本摘要、智能问答、聊天机器人、机器翻译、自动生成、知识图谱、预训练模型、推荐系统、计算广告、招聘信息、求职经验分享等,欢迎关注!加技术交流群请添加AINLPer(id:ainlper),备注工作/研究方向+加群目的。

阅读至此了,分享、点赞、在看三选一吧🙏




