深度学习文本分类方法综述(代码)
【导读】本文是数据科学家Ahmed BESBES的一篇博文,主要内容是探索不同NLP模型在文本分类的性能,围绕着文本分类任务,构建当前主流的七种不同模型:用词ngrams进行逻辑回归、用字符ngrams进行逻辑回归、用词和字符ngrams的逻辑回归、没有预先训练embeddings的循环神经网络(双向GRU)、基于GloVe预训练embeddings的循环神经网络(双向GRU)、多通道卷积神经网络、RNN(双向GRU)+ CNN模型。最后并且附上作者自己的经验总结,博文附完整详细代码,建议大家收藏学习!
作者 | Ahmed BESBES
编译 | 专知
翻译 | Desheng, Hujun
Overview and benchmark of traditional and deep learning models in text classification
本文是我之前用Twitter数据进行情感分析时写的一篇文章的扩展。在那个时候,我探索了一个简单的模型:一个在keras上训练的两层前馈神经网络【1】。 输入推文被表示为由组成推文的单词的embeddings进行加权平均得到的文档向量。
我使用的是word2vec模型,我使用gensim从头开始训练语料库。 该任务是一个二元分类,我能够使用此设置达到79%的准确性。
本文的目标是探索在同一数据集上训练的不同的NLP模型,然后在给定的测试集上测试它们各自的性能。
我们将讨论不同的模型:从依赖词袋表示的简单模型,到部署卷积/周期性网络的复杂模型:我们将看看我们的准确率能否超过79% !

我将从简单的模型开始,逐步增加复杂性。我的目标是想要表明简单的模型也能很好地工作。
所以我会试试这些:
用词ngrams进行逻辑回归
用字符ngrams进行逻辑回归
用词和字符ngrams的逻辑回归
没有预先训练embeddings的循环神经网络(双向GRU)
基于GloVe预训练embeddings的循环神经网络(双向GRU)
多通道卷积神经网络
RNN(双向GRU)+ CNN模型
在这篇文章的最后,你将会获得每种NLP技术的示例代码。 它将帮助你进行你的NLP项目并获得目前最好的效果(其中一些模型非常强大)。
我们还将提供一个综合基准(benchmark),从中我们可以判断哪种模型最适合预测推文所表达的情感。
在相关的git repo中,我将发布不同的模型、它们的预测结果以及测试集。你可以自己尝试一下。
让我们开始吧!
import os
import re
import warnings
warnings.simplefilter("ignore", UserWarning)
from matplotlib import pyplot as plt
% matplotlib
inline
import pandas as pd
pd.options.mode.chained_assignment = None
import numpy as np
from string import punctuation
from nltk.tokenize import word_tokenize
from sklearn.model_selection import train_test_split
from sklearn.feature_extraction.text import TfidfVectorizer
from sklearn.linear_model import LogisticRegression
from sklearn.metrics import accuracy_score, auc, roc_auc_score
from sklearn.externals import joblib
import scipy
from scipy.sparse import hstack
0 - 数据预处理
数据集可以从这个链接下载。
http://thinknook.com/twitter-sentiment-analysis-training-corpus-dataset-2012-09-22/
它包含1578614个已经标记类别的推文,每行标记为1或0, 1表示积极情绪,0表示消极情绪。
作者建议使用1/10来测试算法,剩下的则用于训练。
data = pd.read_csv('./data/tweets.csv', encoding='latin1', usecols=['Sentiment',
'SentimentText'])
data.columns = ['sentiment', 'text']
data = data.sample(frac=1, random_state=42)
print(data.shape)
(1578614, 2)
for row in data.head(10).iterrows():
print(row[1]['sentiment'], row[1]['text'])
1 http://www.popsugar.com/2999655 keep voting for robert pattinson
in the popsugar100 as well!!
1 @GamrothTaylor I am starting to worry about you, only I have Navy
Seal type sleep hours.
0 sunburned...no sunbaked! ow. it hurts to sit.
1 Celebrating my 50th birthday by doing exactly the same as I do
every other day - working on our websites. It's just another day.
1 Leah and Aiden Gosselin are the cutest kids on the face of the Earth
1 @MissHell23 Oh. I didn't even notice.
0 WTF is wrong with me?!!! I'm completely miserable. I need to snap
out of this
0 Was having the best time in the gym until I got to the car and
had messages waiting for me... back to the down stage!
1 @JENTSYY oh what happened??
0 @catawu Ghod forbid he should feel responsible for anything!
推文是有噪声的,让我们通过删除url(网址)、hashtag(主题标签)和user mentions(用户提及)来清除它们。
def tokenize(tweet):
tweet = re.sub(r'http\S+', '', tweet)
tweet = re.sub(r"#(\w+)", '', tweet)
tweet = re.sub(r"@(\w+)", '', tweet)
tweet = re.sub(r'[^\w\s]', '', tweet)
tweet = tweet.strip().lower()
tokens = word_tokenize(tweet)
return tokens
一旦数据清理完毕,我们将其保存在磁盘上。
data['tokens'] = data.text.progress_map(tokenize)
data['cleaned_text'] = data['tokens'].map(lambda tokens: ' '.join(tokens))
data[['sentiment', 'cleaned_text']].to_csv('./data/cleaned_text.csv')
data = pd.read_csv('./data/cleaned_text.csv')
print(data.shape)
(1575026, 2)
data.head()

现在已经清理了数据集,让我们准备一个train/test 分割来构建模型。
我们将在整个notebook中使用这种分割方式。
x_train, x_test, y_train, y_test = train_test_split(data['cleaned_text'],
data['sentiment'],
test_size=0.1,
random_state=42,
stratify=data['sentiment'])
print(x_train.shape, x_test.shape, y_train.shape, y_test.shape)
(1417523,)(157503, )(1417523, )(157503, )
我将测试标签保存在磁盘上供以后使用。
pd.DataFrame(y_test).to_csv('./predictions/y_true.csv', index=False, encoding='utf-8')
现在开始应用机器学习:
1 - 基于词ngrams的词袋模型
所以什么是n-gram?
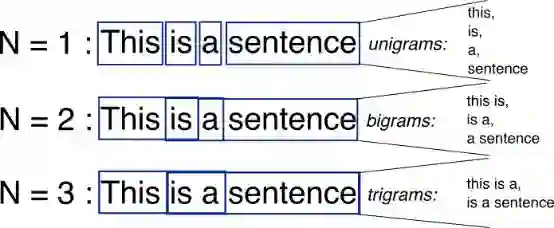
正如我们在图中看到的那样,n-gram是您可以在源文本中找到的长度为n的相邻单词的所有组合(在本例中为n)。
在我们的模型中,我们将使用unigrams(n = 1)和bigrams(n = 2)作为特征。
因此数据集将被表示为一个矩阵,其中每行表示一条推文,每一列表示从文本中提取的特征(单词或双字母)(在标记和清理之后)。 每个单元格将是tf-idf分数。 (我们也可以使用简单的计数,但tf-idf更常用,通常效果更好)。 我们称这个矩阵为文档项矩阵。
正如你可以想象的那样,150万个推文语料库中独特的unigrams和bigrams的数量是巨大的。 在实践中,出于计算原因,我们将此数字设置为固定值。 您可以使用交叉验证来确定此值。
这是语料库在矢量化之后的样子:
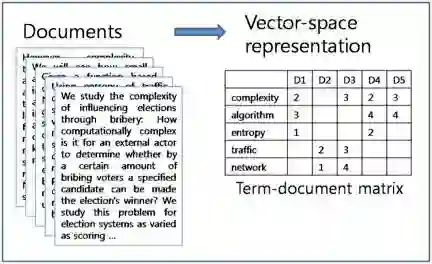
I like pizza a lot
假设我们希望使用上述特征将此句子提供给预测模型。鉴于我们使用的是unigrams和bigrams,该模型将提取以下特征:
i, like, pizza, a, lot, i like, like pizza, pizza a, a lot
因此,这个句子将由一个大小为N的向量组成,其中包含许多0和tf-idf分数。你可以清楚地看到,我们要处理的是大而稀疏的向量。
处理大量稀疏数据时,线性模型通常表现相当好。 此外,他们比其他类型的模型(例如基于树的模型)训练的速度更快。
从过去的经验中可知,逻辑回归在稀疏tfidf矩阵的基础上运行良好。
vectorizer_word = TfidfVectorizer(max_features=40000,
min_df=5,
max_df=0.5,
analyzer='word',
stop_words='english',
ngram_range=(1, 2))
vectorizer_word.fit(x_train, leave=False)
tfidf_matrix_word_train = vectorizer_word.transform(x_train)
tfidf_matrix_word_test = vectorizer_word.transform(x_test)
在为训练集和测试集生成tfidf矩阵之后,我们可以构建第一个模型并对其进行测试。tifidf矩阵是逻辑回归的特征。
lr_word = LogisticRegression(solver='sag', verbose=2)
lr_word.fit(tfidf_matrix_word_train, y_train)
一旦模型训练完成,我们将其应用于测试数据以获得预测结果。 然后我们将这些值以及模型保存在磁盘上。
joblib.dump(lr_word, './models/lr_word_ngram.pkl')
y_pred_word = lr_word.predict(tfidf_matrix_word_test)
pd.DataFrame(y_pred_word, columns=['y_pred']).to_csv('./predictions/lr_word_ngram.csv',
index=False)
让我们看看我们的准确度得分:
y_pred_word = pd.read_csv('./predictions/lr_word_ngram.csv')
print(accuracy_score(y_test, y_pred_word))
0.782042246814
第一个模型的准确率为78.2%! 相当不错。 我们转到下一个模型。
2 -基于字符ngrams的词袋模型
我们从来没有说过ngram只能用在word上。我们也可以在字符层面上应用它们。

你看到了吗?我们将把上面的代码应用到字符 ngrams上,我们将会变成4-gram。
这基本上意味着像“I like this movie”这样的句子将具有以下特征:
I, l, i, k, e, ..., I li, lik, like, ..., this, ... , is m, s mo, movi, ...
字符ngram非常有效。它们甚至可以在建模语言任务时胜过单词标记(tokens)。例如,垃圾邮件过滤器或母语识别就很依赖字符ngram。(这里有两个链接)
与以前学习单词组合的模型不同,该模型学习字母的组合,可以处理单词的形态构成问题。
基于字符的表示的优点之一是更好地处理拼写错误的单词。
让我们运行相同的pipeline:
vectorizer_char = TfidfVectorizer(max_features=40000,
min_df=5,
max_df=0.5,
analyzer='char',
ngram_range=(1, 4))
vectorizer_char.fit(tqdm_notebook(x_train, leave=False));
tfidf_matrix_char_train = vectorizer_char.transform(x_train)
tfidf_matrix_char_test = vectorizer_char.transform(x_test)
lr_char = LogisticRegression(solver='sag', verbose=2)
lr_char.fit(tfidf_matrix_char_train, y_train)
y_pred_char = lr_char.predict(tfidf_matrix_char_test)
joblib.dump(lr_char, './models/lr_char_ngram.pkl')
pd.DataFrame(y_pred_char, columns=['y_pred']).to_csv('./predictions/lr_char_ngram.csv',
index=False)
y_pred_char = pd.read_csv('./predictions/lr_char_ngram.csv')
print(accuracy_score(y_test, y_pred_char))
0.80420055491
准确率达到80.4%!字符-ngrams比词-ngrams更好。
3 - 基于词和字符ngrams的词袋模型
字符ngram特征似乎可以比词ngrams提供更好的准确性。 但是,这两者的结合是怎么样的:词 + 字符 ngrams?
我们连接我们生成的两个tfidf矩阵并构建一个新的混合tfidf矩阵。
这个模型将帮助我们了解一个词的特征、它可能的邻居以及它的形态结构。
这些属性结合在一起:
tfidf_matrix_word_char_train = hstack((tfidf_matrix_word_train, tfidf_matrix_char_train))
tfidf_matrix_word_char_test = hstack((tfidf_matrix_word_test, tfidf_matrix_char_test))
lr_word_char = LogisticRegression(solver='sag', verbose=2)
lr_word_char.fit(tfidf_matrix_word_char_train, y_train)
y_pred_word_char = lr_word_char.predict(tfidf_matrix_word_char_test)
joblib.dump(lr_word_char, './models/lr_word_char_ngram.pkl')
pd.DataFrame(y_pred_word_char, columns=['y_pred']).
to_csv('./predictions/lr_word_char_ngram.csv', index=False)
y_pred_word_char = pd.read_csv('./predictions/lr_word_char_ngram.csv')
print(accuracy_score(y_test, y_pred_word_char))
0.81423845895
真棒:81.4%的准确性。
在我们继续讨论之前,我们可以对词袋模型说些什么?
优点:考虑到它们的简单性,它们的功能会非常强大,而且速度很快,而且易于理解。
缺点:尽管ngrams考虑了词与词之间的联系,但词袋模型在建模一个序列中单词之间的长期依赖关系时失败了。
现在我们将深入深度学习模型。 深度学习胜过词袋模型的原因在于它能够捕捉句子中单词之间的顺序依赖性。 这得益于称为递归神经网络的特殊神经网络架构的发明。
我不会介绍RNN的理论基础,但这里有一个我认为值得阅读的链接(这里是一个链接)。 来自Cristopher Olah的博客。 它详述了LSTM:长短期记忆。 一种特殊的RNN。
在开始之前,我们必须建立一个深度学习的专用环境,在Tensorflow之上使用Keras。 我试图在我的个人笔记本电脑上运行程序,但考虑到数据集的大小以及RNN体系结构的复杂性,这并不实际。
一个很好的选择是AWS。 我通常在EC2 p2.xlarge实例上使用这种深度学习AMI。 (这里有两个链接)Amazon AMI是预先配置的VM映像,其中安装了所有软件包(Tensorflow,PyTocrh,Keras等)。 我强烈推荐这款我一直在使用的产品。
from keras.preprocessing.text import Tokenizer
from keras.preprocessing.text import text_to_word_sequence
from keras.preprocessing.sequence import pad_sequences
from keras.models import Model
from keras.models import Sequential
from keras.layers import Input, Dense, Embedding, Conv1D, Conv2D, MaxPooling1D, MaxPool2D
from keras.layers import Reshape, Flatten, Dropout, Concatenate
from keras.layers import SpatialDropout1D, concatenate
from keras.layers import GRU, Bidirectional, GlobalAveragePooling1D, GlobalMaxPooling1D
from keras.callbacks import Callback
from keras.optimizers import Adam
from keras.callbacks import ModelCheckpoint, EarlyStopping
from keras.models import load_model
from keras.utils.vis_utils import plot_model
4 - 没有预先训练embedding的循环神经网络
RNN可能看起来很可怕。 虽然他们很难理解,但他们很有趣。 它们封装了一个非常漂亮的设计,可以克服传统神经网络在处理序列数据时出现的缺陷:文本,时间序列,视频,DNA序列等。
RNN是一系列神经网络模块,它们像链条一样链接到彼此。 每个人都将消息传递给后继者。
同样,如果你想深入内部机制,我强烈推荐Colah的博客,下面的图表就是其中的内容。
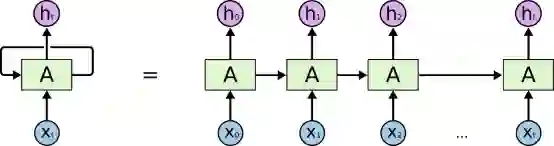
我们将处理文本数据,这是一种序列数据。词的顺序对语义非常重要。 希望RNN能够很好地处理这一点,并且可以捕捉到长期的依赖关系。
要在文本数据上使用Keras,我们必须对其进行预处理。 为此,我们可以使用Keras的Tokenizer类。 该对象采用num_words作为参数,这是根据词频率进行token(标记)后保留的最大词数。
MAX_NB_WORDS = 80000
tokenizer = Tokenizer(num_words=MAX_NB_WORDS)
tokenizer.fit_on_texts(data['cleaned_text'])
对数据使用标记器后,可以将文本字符串转换为数字序列。
这些数字代表字典中每个单词的位置(将其视为映射)。
我们来看一个例子:
x_train[15]
'breakfast time happy time'
标记器如何将它转换为一系列数字:
tokenizer.texts_to_sequences([x_train[15]])
[[530, 50, 119, 50]]
现在让我们在训练和测试上应用这个标记器:
train_sequences = tokenizer.texts_to_sequences(x_train)
test_sequences = tokenizer.texts_to_sequences(x_test)
现在这些推文被映射成数字列表。 但是,由于长度不同,我们仍然无法将它们堆叠在一起。 希望Keras允许用0填充序列到最大长度。 我们将此长度设置为35.(这是推文中标记的最大数量)。
MAX_LENGTH = 35
padded_train_sequences = pad_sequences(train_sequences, maxlen=MAX_LENGTH)
padded_test_sequences = pad_sequences(test_sequences, maxlen=MAX_LENGTH)
padded_train_sequences
array([[ 0, 0, 0, ..., 2383, 284, 9],
[ 0, 0, 0, ..., 13, 30, 76],
[ 0, 0, 0, ..., 19, 37, 45231],
...,
[ 0, 0, 0, ..., 43, 502, 1653],
[ 0, 0, 0, ..., 5, 1045, 890],
[ 0, 0, 0, ..., 13748, 38750, 154]])
padded_train_sequences.shape
(1417523, 35)
现在数据已准备好被送入RNN。
以下是我架构中将使用的一些细节:
embedding维度为300.这意味着我们将使用的80000个单词都映射到300维密集向量(浮点数)。 映射将在整个训练过程中进行调整。
在embedding层上应用空间dropout以减少过拟合:它主要查看35×300个矩阵的批次,并在每个矩阵中随机删除(设置为0)词向量(即行)。 这有助于不将注意力集中在特定的词语上,以尝试一般化。
双向门控循环单元(GRU):这是循环网络部分。 它是LSTM架构的一个更快的变体。 可以把它看作两个循环网络的组合,它们从两个方向扫描文本序列:从左到右,从右到左。 这允许网络在阅读给定的单词时,通过使用来自过去和未来信息的上下文来理解它。 GRU将每个网络块的输出h_t的维数设置为100.由于我们使用GRU的双向版本,因此每个RNN块的最终输出将为200维。
双向GRU的输出具有维度(batch_size,timeteps,units)。 这意味着如果我们使用256的典型批量,这个尺寸将是(256,35,200)
在每个批处理之上,我们应用一个全局average pooling(平均池化),它包括对每个时间步骤对应的输出向量进行平均。
我们应用与max pooling(最大池化)相同的操作。
我们连接前两个操作的输出。
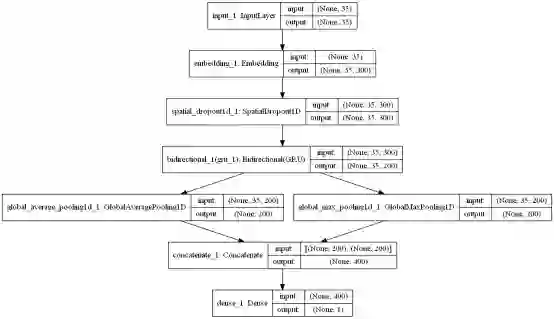
def get_simple_rnn_model():
embedding_dim = 300
embedding_matrix = np.random.random((MAX_NB_WORDS, embedding_dim))
inp = Input(shape=(MAX_LENGTH,))
x = Embedding(input_dim=MAX_NB_WORDS, output_dim=embedding_dim, input_length=MAX_LENGTH,
weights=[embedding_matrix], trainable=True)(inp)
x = SpatialDropout1D(0.3)(x)
x = Bidirectional(GRU(100, return_sequences=True))(x)
avg_pool = GlobalAveragePooling1D()(x)
max_pool = GlobalMaxPooling1D()(x)
conc = concatenate([avg_pool, max_pool])
outp = Dense(1, activation="sigmoid")(conc)
model = Model(inputs=inp, outputs=outp)
model.compile(loss='binary_crossentropy',
optimizer='adam',
metrics=['accuracy'])
return model
rnn_simple_model = get_simple_rnn_model()
我们来看看这个模型的不同层次:
plot_model(rnn_simple_model,
to_file='./images/article_5/rnn_simple_model.png',
show_shapes=True,
show_layer_names=True)
在训练过程中,模型checkpoint被使用。它允许在每一个epoch结束时自动保存最好的模型(在磁盘上)。(w.r.t准确性度量)
filepath = "./models/rnn_no_embeddings/weights-improvement-{epoch:02d}-{val_acc:.4f}.hdf5"
checkpoint = ModelCheckpoint(filepath, monitor='val_acc', verbose=1, save_best_only=True,
mode='max')
batch_size = 256
epochs = 2
history = rnn_simple_model.fit(x=padded_train_sequences,
y=y_train,
validation_data=(padded_test_sequences,
y_test),
batch_size=batch_size,
callbacks=[checkpoint],
epochs=epochs,
verbose=1)
best_rnn_simple_model = load_model
('./models/rnn_no_embeddings/weights-improvement-01-0.8262.hdf5')
y_pred_rnn_simple = best_rnn_simple_model.predict(padded_test_sequences, verbose=1,
batch_size=2048)
y_pred_rnn_simple = pd.DataFrame(y_pred_rnn_simple, columns=['prediction'])
y_pred_rnn_simple['prediction'] = y_pred_rnn_simple['prediction'].map(lambda p: 1
if p >= 0.5 else 0)
y_pred_rnn_simple.to_csv('./predictions/y_pred_rnn_simple.csv', index=False)
y_pred_rnn_simple = pd.read_csv('./predictions/y_pred_rnn_simple.csv')
print(accuracy_score(y_test, y_pred_rnn_simple))
0.826219183127
准确率达到82.6%! 相当不错! 我们现在的表现比之前的词袋模型表现得更好,因为我们正在考虑文本的序列性质。
我们可以做到更好吗?
5 - GloVe预先训练embedding的循环神经网络
在上一个模型中,embedding矩阵被随机初始化。如果我们可以用预先训练好的词嵌入来取代它呢?
让我们举个例子:假设你的语料库中有“pizza”这个词。按照前面的体系结构,将它初始化为随机浮点值的300维向量。这是非常好。您可以这样做,这种embedding将在整个训练过程中进行调整。然而,你可以做的,不是随机选择为pizza选择一个向量,而是利用一个学习了非常大的语料库的模型,进行词embedding。 这是一种特殊的转移学习。
使用来自外部embedding的知识可以提高RNN的精度,因为它集成了有关单词的新信息(词汇和语义),这些信息是在大量数据集上训练和提炼出来的。
预先训练的embedding我们将使用GloVe。
https://nlp.stanford.edu/projects/glove/
官方文档:GloVe是一种无监督学习算法,用于获取单词的矢量表示。 对来自语料库的汇总的全球单词共现统计进行训练,结果展示了词向量空间的有趣线性子结构。
我将使用的Glove embedding是在一个非常大的公共互联网爬行训练得到的,其中包括:
840亿标记
220万词汇
压缩文件有2.03 GB。注意,这个文件不能轻松加载到普通的笔记本电脑上
Glove embedding的维度是300
GloVe embedding来自原始文本数据,每行包含一个词和300个浮点数。 所以首先要做的就是将这个结构转换成一个Python字典。
def get_coefs(word, *arr):
try:
return word, np.asarray(arr, dtype='float32')
except:
return None, None
embeddings_index = dict(get_coefs(*o.strip().split()) for o in tqdm_notebook(
open('./embeddings/glove.840B.300d.txt')))
embed_size = 300
for k in tqdm_notebook(list(embeddings_index.keys())):
v = embeddings_index[k]
try:
if v.shape != (embed_size,):
embeddings_index.pop(k)
except:
pass
embeddings_index.pop(None)
一旦创建了embedding索引,我们可以提取所有的向量,将它们叠加在一起,计算它们的均值和标准差。
values = list(embeddings_index.values())
all_embs = np.stack(values)
emb_mean, emb_std = all_embs.mean(), all_embs.std()
现在我们生成嵌入矩阵。我们将按照mean=emb_mean和std=emb_std的正态分布对其进行初始化。
然后我们看一下我们的语料库的80000个单词。 对于每个单词,如果它包含在GloVe中,我们选择它的embedding。否则,我们pass。
word_index = tokenizer.word_index
nb_words = MAX_NB_WORDS
embedding_matrix = np.random.normal(emb_mean, emb_std, (nb_words, embed_size))
oov = 0
for word, i in tqdm_notebook(word_index.items()):
if i >= MAX_NB_WORDS: continue
embedding_vector = embeddings_index.get(word)
if embedding_vector is not None:
embedding_matrix[i] = embedding_vector
else:
oov += 1
print(oov)
def get_rnn_model_with_glove_embeddings():
embedding_dim = 300
inp = Input(shape=(MAX_LENGTH,))
x = Embedding(MAX_NB_WORDS, embedding_dim, weights=[embedding_matrix],
input_length=MAX_LENGTH, trainable=True)(inp)
x = SpatialDropout1D(0.3)(x)
x = Bidirectional(GRU(100, return_sequences=True))(x)
avg_pool = GlobalAveragePooling1D()(x)
max_pool = GlobalMaxPooling1D()(x)
conc = concatenate([avg_pool, max_pool])
outp = Dense(1, activation="sigmoid")(conc)
model = Model(inputs=inp, outputs=outp)
model.compile(loss='binary_crossentropy',
optimizer='adam',
metrics=['accuracy'])
return model
rnn_model_with_embeddings = get_rnn_model_with_glove_embeddings()
filepath = "./models/rnn_with_embeddings/weights-improvement-{epoch:02d}-{val_acc:.4f}.hdf5"
checkpoint = ModelCheckpoint(filepath, monitor='val_acc', verbose=1,
save_best_only=True, mode='max')
batch_size = 256
epochs = 4
history = rnn_model_with_embeddings.fit(x=padded_train_sequences,
y=y_train,
validation_data=(padded_test_sequences, y_test),
batch_size=batch_size,
callbacks=[checkpoint],
epochs=epochs,
verbose=1)
best_rnn_model_with_glove_embeddings =
load_model('./models/rnn_with_embeddings/weights-improvement-03-0.8372.hdf5')
y_pred_rnn_with_glove_embeddings = best_rnn_model_with_glove_embeddings.predict(
padded_test_sequences, verbose=1, batch_size=2048)
y_pred_rnn_with_glove_embeddings = pd.DataFrame(y_pred_rnn_with_glove_embeddings,
columns=['prediction'])
y_pred_rnn_with_glove_embeddings['prediction'] =
y_pred_rnn_with_glove_embeddings['prediction'].map(lambda p:
1 if p >= 0.5 else 0)
y_pred_rnn_with_glove_embeddings.
to_csv('./predictions/y_pred_rnn_with_glove_embeddings.csv', index=False)
y_pred_rnn_with_glove_embeddings =
pd.read_csv('./predictions/y_pred_rnn_with_glove_embeddings.csv')
print(accuracy_score(y_test, y_pred_rnn_with_glove_embeddings))
0.837203100893
准确率达到83.7%!对于本教程的其余部分,我将在embeddinig矩阵中使用GloVe embedding。
6 - 多通道卷积神经网络
在这一部分中,我正在试验我在这里(这里是一个链接)读到的一种卷积神经网络架构。CNNs通常用于计算机视觉。然而,我们最近开始将它们应用到NLP任务中,结果是很有希望的。
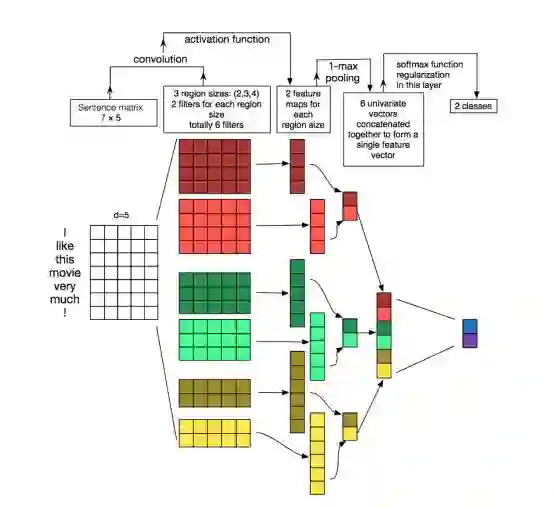
让我们简单地看看在文本数据上使用convnets时发生的情况。为了解释这一点,我借用了wildm.com的这张著名的图表。(一个非常好的博客!)
http://wildm.com/
让我们考虑一下它使用的例子:我非常喜欢这部电影!(7个标记)
每个单词的embedding维数为5。因此,这个句子由一个维度矩阵表示(7,5)。你可以把它想象成一个“图像”(一个数字/浮点数的矩阵)。
6个过滤器,2个大小(2,5)(3,5)和(4,5)在这个矩阵上应用。这些滤波器的特殊性在于它们不是方阵,它们的宽度等于embedding矩阵的宽度。所以每个卷积的结果都是一个列向量。
卷积产生的每个列向量都使用max pooling操作进行子采样。
max pooling操作的结果被连接到最后一个向量中,并传递给softmax函数进行分类。
背后的直觉是什么?
每次卷积的结果将在检测到特殊图案时触发。通过改变内核的大小并连接它们的输出,您可以检测多个大小的模式(2、3或5个相邻的单词)。
模式可以是表达式(词ngrams?),比如“I hate”、“very good”,因此CNNs可以在句子中识别它们,而不管它们的位置。
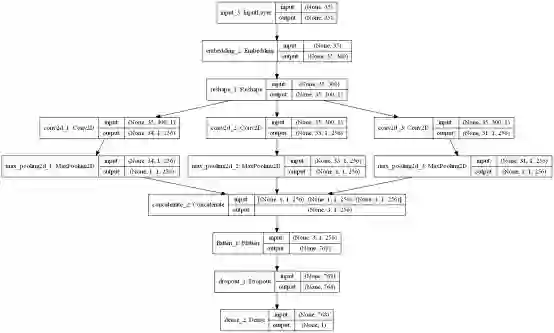
def get_cnn_model():
embedding_dim = 300
filter_sizes = [2, 3, 5]
num_filters = 256
drop = 0.3
inputs = Input(shape=(MAX_LENGTH,), dtype='int32')
embedding = Embedding(input_dim=MAX_NB_WORDS,
output_dim=embedding_dim,
weights=[embedding_matrix],
input_length=MAX_LENGTH,
trainable=True)(inputs)
reshape = Reshape((MAX_LENGTH, embedding_dim, 1))(embedding)
conv_0 = Conv2D(num_filters,
kernel_size=(filter_sizes[0], embedding_dim),
padding='valid', kernel_initializer='normal',
activation='relu')(reshape)
conv_1 = Conv2D(num_filters,
kernel_size=(filter_sizes[1], embedding_dim),
padding='valid', kernel_initializer='normal',
activation='relu')(reshape)
conv_2 = Conv2D(num_filters,
kernel_size=(filter_sizes[2], embedding_dim),
padding='valid', kernel_initializer='normal',
activation='relu')(reshape)
maxpool_0 = MaxPool2D(pool_size=(MAX_LENGTH - filter_sizes[0] + 1, 1),
strides=(1, 1), padding='valid')(conv_0)
maxpool_1 = MaxPool2D(pool_size=(MAX_LENGTH - filter_sizes[1] + 1, 1),
strides=(1, 1), padding='valid')(conv_1)
maxpool_2 = MaxPool2D(pool_size=(MAX_LENGTH - filter_sizes[2] + 1, 1),
strides=(1, 1), padding='valid')(conv_2)
concatenated_tensor = Concatenate(axis=1)(
[maxpool_0, maxpool_1, maxpool_2])
flatten = Flatten()(concatenated_tensor)
dropout = Dropout(drop)(flatten)
output = Dense(units=1, activation='sigmoid')(dropout)
model = Model(inputs=inputs, outputs=output)
adam = Adam(lr=1e-4, beta_1=0.9, beta_2=0.999, epsilon=1e-08, decay=0.0)
model.compile(optimizer=adam, loss='binary_crossentropy', metrics=['accuracy'])
return model
cnn_model_multi_channel = get_cnn_model()
plot_model(cnn_model_multi_channel,
to_file='./images/article_5/cnn_model_multi_channel.png',
show_shapes=True,
show_layer_names=True)
filepath = "./models/cnn_multi_channel/weights-improvement-{epoch:02d}-{val_acc:.4f}.hdf5"
checkpoint = ModelCheckpoint(filepath, monitor='val_acc', verbose=1,
save_best_only=True, mode='max')
batch_size = 256
epochs = 4
history = cnn_model_multi_channel.fit(x=padded_train_sequences,
y=y_train,
validation_data=(padded_test_sequences, y_test),
batch_size=batch_size,
callbacks=[checkpoint],
epochs=epochs,
verbose=1)
best_cnn_model = load_model('./models/cnn_multi_channel/weights-improvement-04-0.8264.hdf5')
y_pred_cnn_multi_channel = best_cnn_model.predict(padded_test_sequences,
verbose=1, batch_size=2048)
y_pred_cnn_multi_channel = pd.DataFrame(y_pred_cnn_multi_channel, columns=['prediction'])
y_pred_cnn_multi_channel['prediction'] = y_pred_cnn_multi_channel['prediction'].
map(lambda p: 1 if p >= 0.5 else 0)
y_pred_cnn_multi_channel.to_csv('./predictions/y_pred_cnn_multi_channel.csv', index=False)
y_pred_cnn_multi_channel = pd.read_csv('./predictions/y_pred_cnn_multi_channel.csv')
print(accuracy_score(y_test, y_pred_cnn_multi_channel))
0.826409655689
82.6%的准确率,没有RNNs那么精确,但仍然比BOW模型好。也许对超参数的研究(过滤器的数量和大小)会带来优势?
7 循环+卷积神经网络
RNN功能强大。 但是,有些人发现他们可以通过在循环层之上添加一个卷积层来使它们更加健壮。
RNN允许你(embed)嵌入关于序列和先前单词的信息,并且CNN采用这种嵌入(embedding)并从中提取局部特征。 这两层共同工作是一个成功的组合。
更多请点击这里
http://konukoii.com/blog/2018/02/19/twitter-sentiment-analysis-using-combined-lstm-cnn-models/
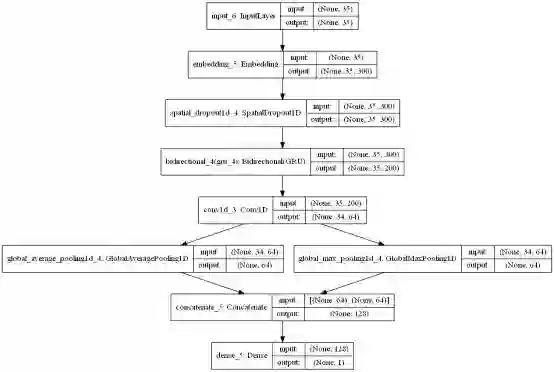
def get_rnn_cnn_model():
embedding_dim = 300
inp = Input(shape=(MAX_LENGTH,))
x = Embedding(MAX_NB_WORDS, embedding_dim, weights=[embedding_matrix],
input_length=MAX_LENGTH, trainable=True)(inp)
x = SpatialDropout1D(0.3)(x)
x = Bidirectional(GRU(100, return_sequences=True))(x)
x = Conv1D(64, kernel_size=2, padding="valid", kernel_initializer="he_uniform")(x)
avg_pool = GlobalAveragePooling1D()(x)
max_pool = GlobalMaxPooling1D()(x)
conc = concatenate([avg_pool, max_pool])
outp = Dense(1, activation="sigmoid")(conc)
model = Model(inputs=inp, outputs=outp)
model.compile(loss='binary_crossentropy',
optimizer='adam',
metrics=['accuracy'])
return model
rnn_cnn_model = get_rnn_cnn_model()
plot_model(rnn_cnn_model, to_file='./images/article_5/rnn_cnn_model.png',
show_shapes=True, show_layer_names=True)
filepath = "./models/rnn_cnn/weights-improvement-{epoch:02d}-{val_acc:.4f}.hdf5"
checkpoint = ModelCheckpoint(filepath, monitor='val_acc', verbose=1,
save_best_only=True, mode='max')
batch_size = 256
epochs = 4
history = rnn_cnn_model.fit(x=padded_train_sequences,
y=y_train,
validation_data=(padded_test_sequences, y_test),
batch_size=batch_size,
callbacks=[checkpoint],
epochs=epochs,
verbose=1)
best_rnn_cnn_model = load_model('./models/rnn_cnn/weights-improvement-03-0.8379.hdf5')
y_pred_rnn_cnn = best_rnn_cnn_model.predict(padded_test_sequences, verbose=1,
batch_size=2048)
y_pred_rnn_cnn = pd.DataFrame(y_pred_rnn_cnn, columns=['prediction'])
y_pred_rnn_cnn['prediction'] = y_pred_rnn_cnn['prediction'].map(lambda p: 1 if p >= 0.5 else 0)
y_pred_rnn_cnn.to_csv('./predictions/y_pred_rnn_cnn.csv', index=False)
y_pred_rnn_cnn = pd.read_csv('./predictions/y_pred_rnn_cnn.csv')
print(accuracy_score(y_test, y_pred_rnn_cnn))
0.837882453033
83.8%的准确率。到目前为止最好的模型。
8 - 结论
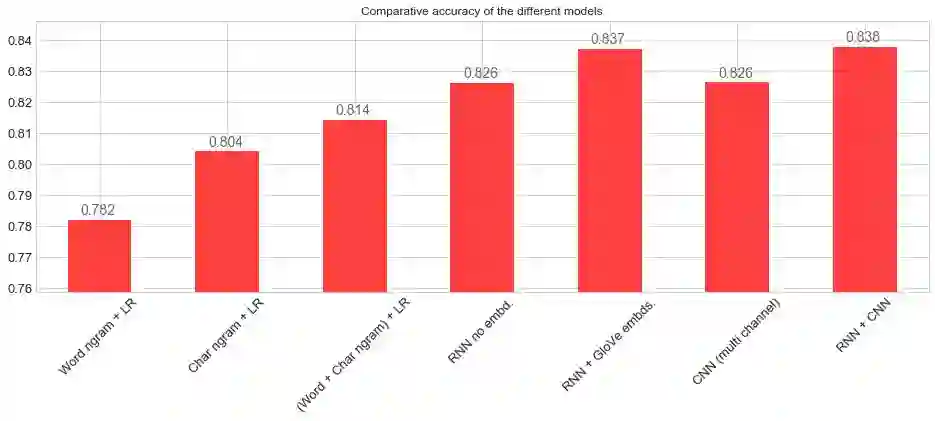
我们运行了7个不同的模型。让我们看看他们是如何比较的:
import seaborn as sns
from sklearn.metrics import roc_auc_score
sns.set_style("whitegrid")
sns.set_palette("pastel")
predictions_files = os.listdir('./predictions/')
predictions_dfs = []
for f in predictions_files:
aux = pd.read_csv('./predictions/{0}'.format(f))
aux.columns = [f.strip('.csv')]
predictions_dfs.append(aux)
predictions = pd.concat(predictions_dfs, axis=1)
scores = {}
for column in tqdm_notebook(predictions.columns, leave=False):
if column != 'y_true':
s = accuracy_score(predictions['y_true'].values, predictions[column].values)
scores[column] = s
scores = pd.DataFrame([scores], index=['accuracy'])
mapping_name = dict(zip(list(scores.columns),
['Char ngram + LR', '(Word + Char ngram) + LR',
'Word ngram + LR', 'CNN (multi channel)',
'RNN + CNN', 'RNN no embd.', 'RNN + GloVe embds.']))
scores = scores.rename(columns=mapping_name)
scores = scores[['Word ngram + LR', 'Char ngram + LR', '(Word + Char ngram) + LR',
'RNN no embd.', 'RNN + GloVe embds.', 'CNN (multi channel)',
'RNN + CNN']]
scores = scores.T
ax = scores['accuracy'].plot(kind='bar',
figsize=(16, 5),
ylim=(scores.accuracy.min() * 0.97, scores.accuracy.max() * 1.01),
color='red',
alpha=0.75,
rot=45,
fontsize=13)
ax.set_title('Comparative accuracy of the different models')
for i in ax.patches:
ax.annotate(str(round(i.get_height(), 3)),
(i.get_x() + 0.1, i.get_height() * 1.002), color='dimgrey', fontsize=14)
让我们快速检查模型预测之间的相关性。
fig = plt.figure(figsize=(10, 5))
sns.heatmap(predictions.drop('y_true', axis=1).corr(method='kendall'), cmap="Blues",
annot=True);
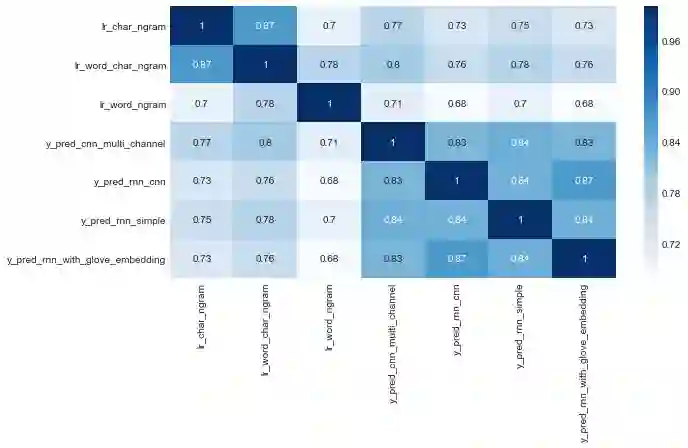
结论
以下是我认为值得分享的发现:
使用字符 ngram的词袋模型可以非常有效。不要低估他们! 它们计算相对简单,而且易于解释。
RNNs是强大的。然而,有时你可以用外部训练过的embeddings,如Glove来抽取它们。您还可以使用其他流行的embedding,如word2vec和FastText。
CNNs可以应用于文本。他们的主要优势是训练非常快。此外,它们从文本中提取本地特征的能力对nlp任务尤其有趣。
RNNs和CNNs可以叠加在一起,利用这两种体系结构的优点。
以下是我写这篇文章时参考的重要链接
http://wildml.com/2015/11/understanding-convolutional-neural-networks-for-nlp/
http://colah.github.io/posts/2015-08-Understanding-LSTMs/
1. https://ahmedbesbes.com/sentiment-analysis-on-twitter-using-word2vec-and-keras.html
原文链接:
https://ahmedbesbes.com/overview-and-benchmark-of-traditional-and-deep-learning-models-in-text-classification.html
-END-
专 · 知
人工智能领域主题知识资料查看与加入专知人工智能服务群:
【专知AI服务计划】专知AI知识技术服务会员群加入与人工智能领域26个主题知识资料全集获取。欢迎微信扫一扫加入专知人工智能知识星球群,获取专业知识教程视频资料和与专家交流咨询!

请PC登录www.zhuanzhi.ai或者点击阅读原文,注册登录专知,获取更多AI知识资料!

请加专知小助手微信(扫一扫如下二维码添加),加入专知主题群(请备注主题类型:AI、NLP、CV、 KG等)交流~
请关注专知公众号,获取人工智能的专业知识!




