手把手教你用Python进行回归(附代码、学习资料)

作者: GURCHETAN SINGH
翻译:张逸
校对:丁楠雅
本文共5800字,建议阅读8分钟。
本文从线性回归、多项式回归出发,带你用Python实现样条回归。
我刚开始学习数据科学时,第一个接触到的算法就是线性回归。在把这个方法算法应用在到各种各样的数据集的过程中,我总结出了一些它的优点和不足。
首先,线性回归假设自变量和因变量之间存在线性关系,但实际情况却很少是这样。为了改进这个问题模型,我尝试了多项式回归,效果确实好一些(大多数情况下都是如此会改善)。但又有一个新问题:当数据集的变量太多的时候,用多项式回归很容易产生过拟合。
由于而且我建立的模型总是过于灵活,它可能在测试集上结果很好,但在那些“看不见的”数据上表现的就差强人意了。后来我看到另外一种称为样条回归的非线性方法---它将线性/多项式函数进行组合,用最终的结果来拟合数据。
在这篇文章中,我将会介绍线性回归、多项式回归的基本概念,然后详细说明关于样条回归的更多细节以及它的Python实现。
注:为了更好的理解本文中所提到的各种概念,你需要有线性回归和多项式回归的基础知识储备。这里有一些相关资料可以参考:
https://www.analyticsvidhya.com/blog/2015/08/comprehensive-guide-regression/
本文结构
了解数据
简单回顾线性回归
多项式回归:对线性会回归的改进
理解样条回归及其实现
分段阶梯函数
基函数
分段多项式
约束和样条
三次样条和自然三次样条
确定节点的数量和位置
比较样条回归和多项式回归
了解数据
为了更好的理解这些概念,我们选择了工资预测数据集来做辅助说明。你可以在这儿下载:
https://drive.google.com/file/d/1QIHCTvHQIBpilzbNxGmbdEBEbmEkMd_K/view
这个数据集是从一本最近热门的书《Introduction to Statistical learning》(http://www-bcf.usc.edu/~gareth/ISL/ ISLR%20Seventh%20Printing.pdf)上摘取下来的。
我们的数据集包括了诸如ID、出生年份、性别、婚姻状况、种族、教育程度、职业、健康状况、健康保险和工资记录这些信息。为了详细解释样条回归,我们将只用年龄作为自变量来预测工资(因变量)。
让我们开始吧:
#导入需要的包
import pandas as pd
import numpy as np
import statsmodels.api as sm
import matplotlib.pyplot as plt
%matplotlib inline
#读入数据
data = pd.read_csv("Wage.csv")
data.head()
我们会得到这样的结果:

继续:
data_x = data['age']
data_y = data['wage']
#将数据划分为训练集和验证集
from sklearn.model_selection import train_test_split
train_x, valid_x, train_y, valid_y = train_test_split(data_x, data_y, test_size=0.33, random_state = 1)
#对年龄和工资的关系进行可视化
import matplotlib.pyplot as plt
plt.scatter(train_x, train_y, facecolor='None', edgecolor='k', alpha=0.3)plt.show()
我们会得到这样的图:
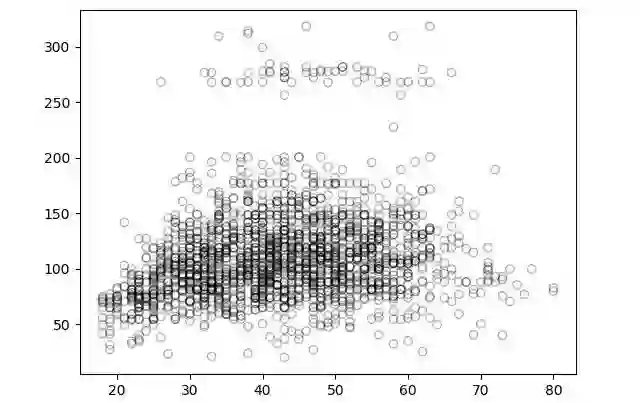
看到上边这个散点图,你会想到什么?这到底是代表正相关还是负相关?或者说根本没有联系?大家可以在下方的评论区说说自己的观点。
介绍线性回归
线性回归是预测模型中最简单同时应用最广泛的统计方法。它是用来解决基于回归任务的一种监督学习方法。
这种方法建立了自变量和因变量之间线性的关系,所以被称为线性回归。主要是一个线性方程,就像下边这个式子。可以这么理解:我们的特征就是一组带系数的自变量。
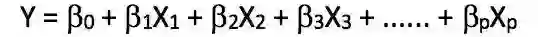
这个式子中,我们认为Y是因变量,X为自变量,所有的β都是系数。这些系数即为对应特征的权重,表示了每个特征的重要性。比如说:某个预测的结果高度依赖于诸多特征中的一个(X1),则意味着与其他所有特征相比,X1的系数(即权重)值会更高。
下面我们来试着理解一下只有一个特征的线性回归。即:只有一个自变量。它被称为简单线性回归。对应的式子是这样的:
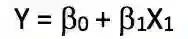
前面提到,我们只用年龄这一个特征来预测工资,所以很显然,可以在训练集上应用简单线性回归,并且在验证集上计算该模型的误差(RMSE)
from sklearn.linear_model import LinearRegression
#拟合线性回归模型
x = train_x.reshape(-1,1)
model = LinearRegression()
model.fit(x,train_y)
print(model.coef_)
print(model.intercept_)
-> array([0.72190831])
-> 80.65287740759283
#在验证集上进行预测
valid_x = valid_x.reshape(-1,1)
pred = model.predict(valid_x)
#可视化
#我们将使用valid_x的最小值和最大值之间的70个点进行绘制
xp = np.linspace(valid_x.min(),valid_x.max(),70)
xp = xp.reshape(-1,1)
pred_plot = model.predict(xp)
plt.scatter(valid_x, valid_y, facecolor='None', edgecolor='k', alpha=0.3)
plt.plot(xp, pred_plot)
plt.show()
得出图像如下:
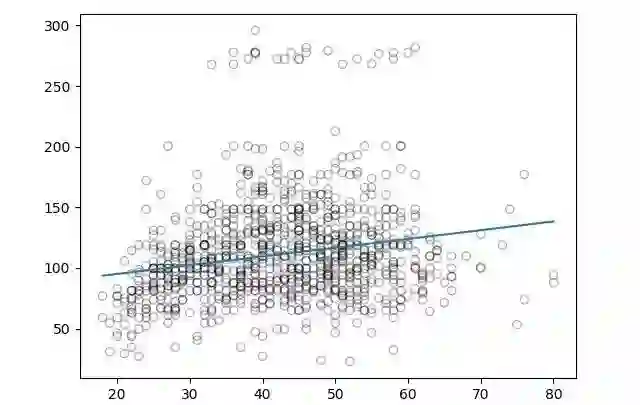
现在对预测出的结果算一下RMSE:
from sklearn.metrics import mean_squared_error
from math import sqrt
rms = sqrt(mean_squared_error(valid_y, pred))
print(rms)
-> 40.436
从上边的图中我们可以看出,线性回归模型并没有抓住数据的全部特点,对于工资预测问题来说,这个方法表现的并不理想。
所以结论是,尽管线性模型在描述和实现上比较简单,并且非常容易理解并应用。但它在预测能力方面还是比较有限。这是因为线性模型假定自变量和因变量之间总是存在线性关系。这个假设是很弱的,它仅仅是近似,而且在有些情况下,近似效果非常差。
在下面要提到的其他方法中,得把这种线性的假设暂且搁到一边,但也不能完全抛之脑后。我们会在这个最简单的线性模型基础上进行拓展,得到多项式回归、阶梯函数,或者更复杂一点的,比如样条回归,也会在下面进行介绍。
线性回归的改进:多项式回归
来看看这样一组可视化的图:
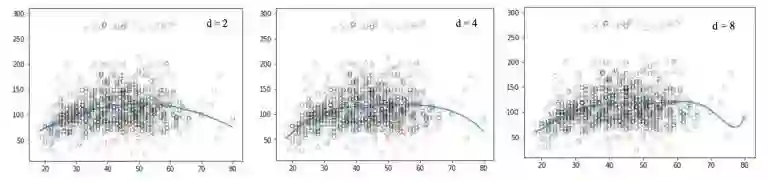
这些图看起来挖掘出了年龄和工资之间的更多联系。它们是非线性的,因为在建立年龄和工资模型的时候使用的是非线性等式。这种使用非线性函数的回归方法,叫做多项式回归。
多项式回归通过增加额外的预测项对简单线性模型进行了拓展。具体来讲,是将每个原始预测项提升了幂次。例如,一个三次回归使用了这样三个变量: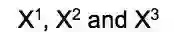
那这种方法是如何做到用非线性模型来代替线性模型,在自变量和因变量之间建立关系的呢?这种改进的根本,是使用了一个多项式方程取代了原来的线性关系。
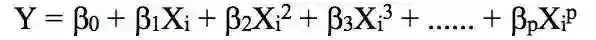
但当我们增加幂次的值时,曲线开始高频震荡。这导致曲线的形状过于复杂,最终引起过拟合现象。
#为回归函数生成权重,设degree=2
weights = np.polyfit(train_x, train_y, 2)
print(weights)
-> array([ -0.05194765, 5.22868974, -10.03406116])
#根据给定的权重生成模型
model = np.poly1d(weights)
#在验证集上进行预测
pred = model(valid_x)
#我们只画出其中的70个点
xp = np.linspace(valid_x.min(),valid_x.max(),70)
pred_plot = model(xp)
plt.scatter(valid_x, valid_y, facecolor='None', edgecolor='k', alpha=0.3)
plt.plot(xp, pred_plot)
plt.show()
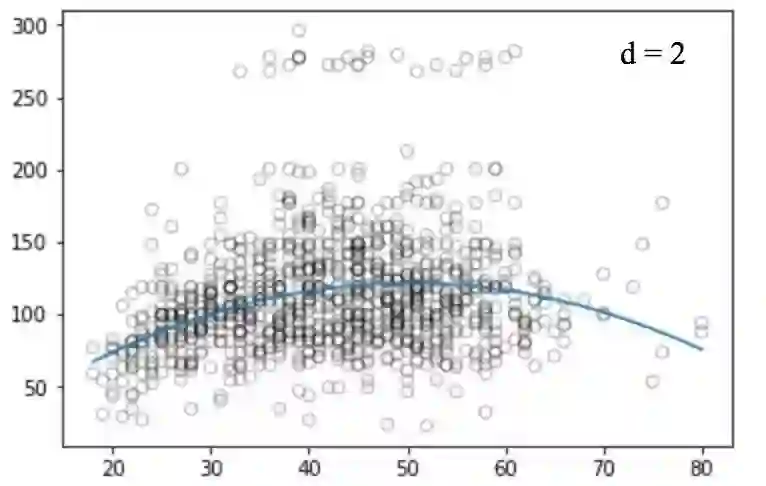
类似的,我们画出不同degree值对应的图:
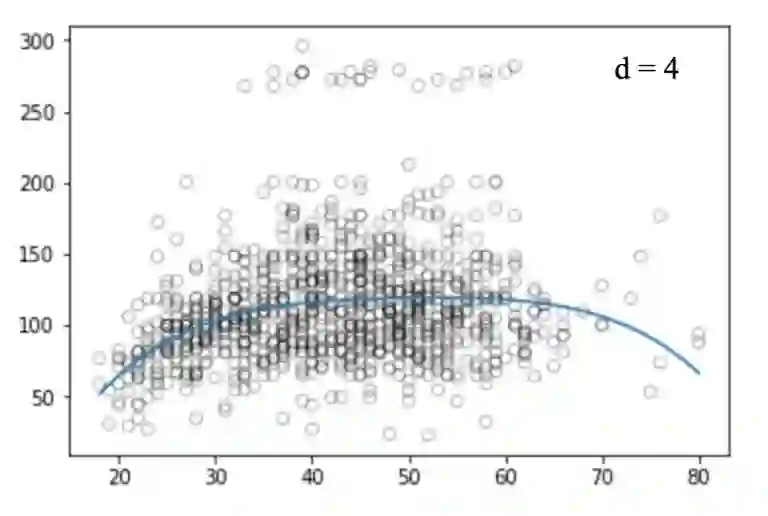
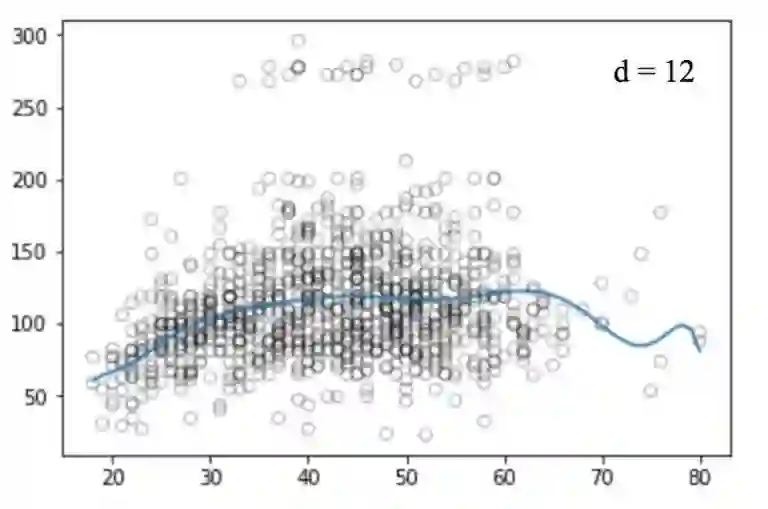
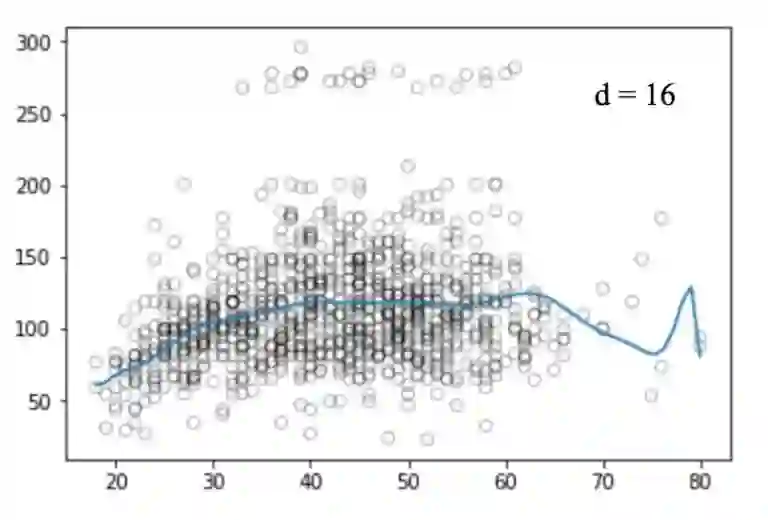
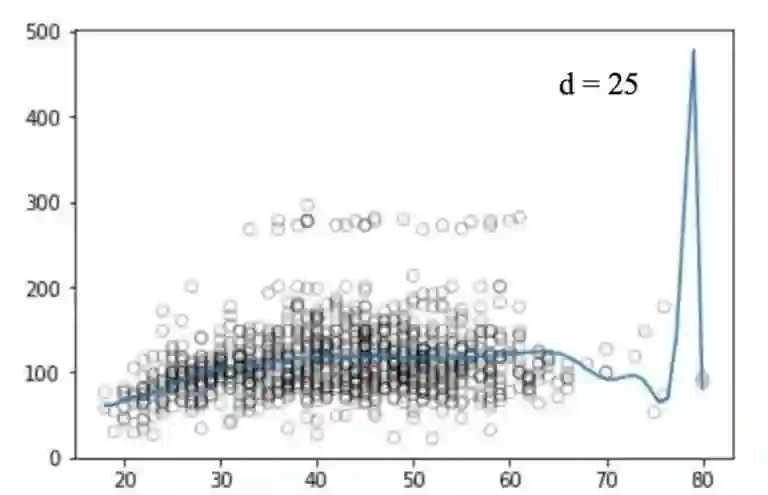
不幸的是,多项式回归也有很多问题,随着等式的复杂性的增加,特征的数量也会增长到很难控制的地步。而且,即便是在上述这个简单的一维数据集上,多项式回归也可能会导致过拟合。
除此之外,还有其他问题。比如:多项式回归本质是非局部性的。也就是说,在训练集中改变其中一个点的y值,会影响到离这个点很远的其他数据的拟合效果。因此,为了避免在整个数据集上使用过高阶的多项式,我们可以用很多不同的低阶多项式函数来作为替代。
样条回归法及其实现
为了克服多项式回归的缺点,我们可以用另外一种改进的回归方法。这种方法没有将模型应用到整个数据集中,而是将数据集划分到多个区间,为每个区间中的数据单独拟合一个模型。这种方法被称为样条回归。
样条回归是最重要的非线性回归方法之一。在多项式回归中,我们通过在已有的特征上应用不同的多项式函数来产生新的特征,这种特征对数据集的影响是全局的。为了解决这个问题,我们可以根据数据的分布特点将其分成不同的部分,并在每一部分上拟合线性或低阶多项式函数。
进行分区的点被称为节点。我们可以用分段函数来对每个区间中的数据进行建模。有很多不同的分段函数可以用来拟合这些数据。
在下一小节中,我们会详细介绍这些函数。
分段阶梯函数
阶梯函数是一种最常见的分段函数。它的函数值在一段时间个区间内会保持一个常数不变。我们可以对不同的数据区间应用不同的阶梯函数,以免对整个数据集的结构产生影响。
在这里我们将X的值进行分段处理,并且对每一部分拟合一个不同的常数。
更具体来讲,我们设置分割点C1,C2,...Ck。在X的范围内构造K+1个新变量。
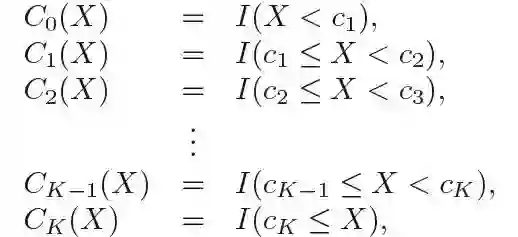
上图中的I()是一个指示函数,如果条件满足,则返回1,反之则返回0.比如当Ck≤X时,函数值I(Ck≤X)为1,反之它就等于0.。对于任意给定的值X,C1,C2,...Ck只能有一个值为非零。因为X只能被分到一个区间中。
#将数据划到四个区间中
df_cut, bins = pd.cut(train_x, 4, retbins=True, right=True)
df_cut.value_counts(sort=False)
->(17.938, 33.5] 504
(33.5, 49.0] 941
(49.0, 64.5] 511
(64.5, 80.0] 54
Name: age, dtype: int64
df_steps = pd.concat([train_x, df_cut, train_y],
keys=['age','age_cuts','wage'], axis=1)
#将讲年龄编码为哑变量
df_steps_dummies = pd.get_dummies(df_cut)
df_steps_dummies.head()
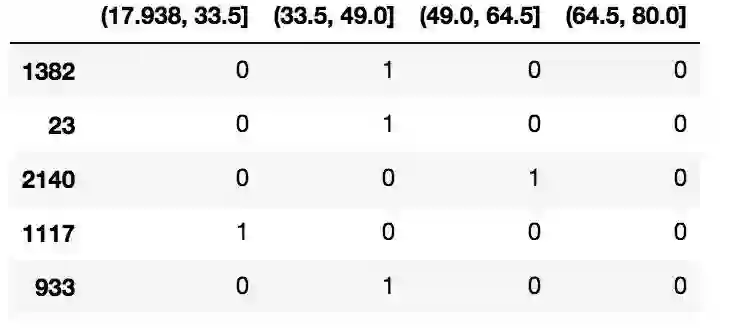
df_steps_dummies.columns = ['17.938-33.5','33.5-49','49-64.5','64.5-80']
#拟合广义线性模型
fit3 = sm.GLM(df_steps.wage, df_steps_dummies).fit()
#同样将验证集划分到四个桶中
bin_mapping = np.digitize(valid_x, bins)
X_valid = pd.get_dummies(bin_mapping)
#去掉离群点
X_valid = pd.get_dummies(bin_mapping).drop([5], axis=1)
#进行预测
pred2 = fit3.predict(X_valid)
#计算RMSE
from sklearn.metrics import mean_squared_error
from math import sqrt
rms = sqrt(mean_squared_error(valid_y, pred2))
print(rms)
->39.9
#在这我们只画出70个观察点的图
xp = np.linspace(valid_x.min(),valid_x.max()-1,70)
bin_mapping = np.digitize(xp, bins)
X_valid_2 = pd.get_dummies(bin_mapping)
pred2 = fit3.predict(X_valid_2)
#进行可视化
fig, (ax1) = plt.subplots(1,1, figsize=(12,5))
fig.suptitle('Piecewise Constant', fontsize=14)
#画出样条回归的散点图
ax1.scatter(train_x, train_y, facecolor='None', edgecolor='k', alpha=0.3)
ax1.plot(xp, pred2, c='b')
ax1.set_xlabel('age')
ax1.set_ylabel('wage')
plt.show()
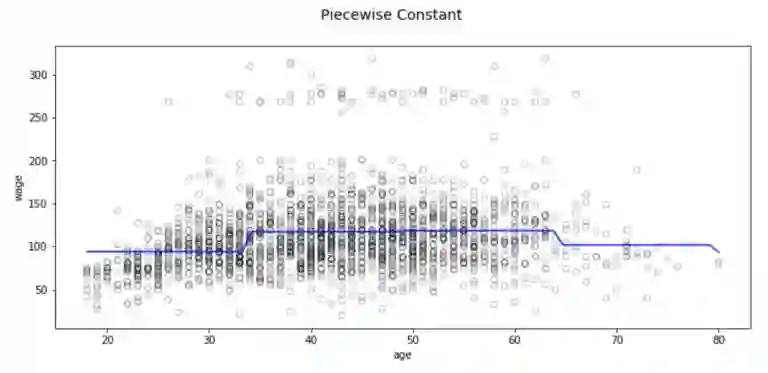
但是这种分段的方法有明显的概念性问题。最明显的问题是,我们研究的大多数问题会随着输入的改变有一个连续变化的趋势。但这种方法不能构建预测变量的连续函数,因此大多数情况下,应用这种方法,首先得假定输入和输出之间没有什么关系。
例如在上面的图表中,我们可以看到,拟合第一个区间的函数显然没有捕捉到工资随年龄的增长而增长的趋势。
基函数
为了捕捉回归模型中的非线性,我们得变换部分或者全部的预测项。而为了避免将每个自变量视为线性的,我们希望有一个更普遍的“变换族”来应用到预测项中。它应该有足够的灵活性,以拟合各种各样形状的曲线(当模型合适时),同时注意但不能过拟合。
这种可以组合在一起捕捉一般数据分布的变换被称为基函数。在这个例子中,基函数是b1(x),b2(x),...,bk(x)
此时,我们拟合的不再是一个线性模型,而是如下所示:
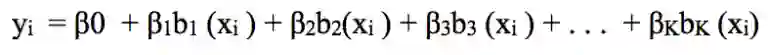
下面我们来看一个普遍使用的基函数:分段多项式。
分段多项式
首先,分段多项式在X的不同范围内拟合的是不同的低阶多项式,而不是像分段阶梯函数那样拟合常数。由于我们使用的多项式次数较低,因此不会观察到曲线有什么大的震荡。
比如:分段二次多项式通过拟合二次回归方程来起作用:
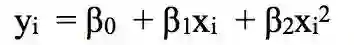
上式中的系数β0、β1还有β2在X的不同区间内是取值不一样的。
一个分段三次多项式,在点C处存在节点,那么它会具有以下形式:
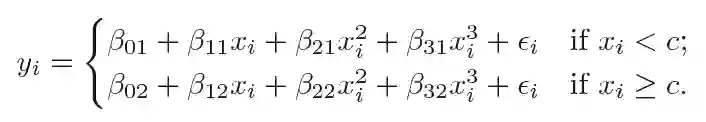
换句话说,我们在数据上拟合了两个不同的三次多项式:一个应用于满足Xi<C的数据,另一个应用于Xi>C的那部分。
第一个多项式函数的系数为: β01, β11, β21, β31,第二个系数则是 β02, β12, β22, β32。这两个多项式函数中的每一个都可以用最小均方误差来拟合。
注意:这个多项式函数有8个自由度,每个多项式有4个(因为是4个变量)。
使用的节点越多,得到的分段多项式就更加灵活,因为我们对X的每一个区间都使用不同的函数,并且这些函数仅仅与该区间中数据的分布情况相关。一般来说,如果我们在X的范围内设置K个不同的节点,最终会拟合K+1个不同的三次多项式。 而且我们其实可以使用任何低阶的多项式来拟合某一段的数据。比如:可以改用分段线性函数,实际上,上面使用的阶梯函数是0阶的分段多项式。
下面我们来看看构建分段多项式时应遵循的一些必要条件和约束。
约束和样条
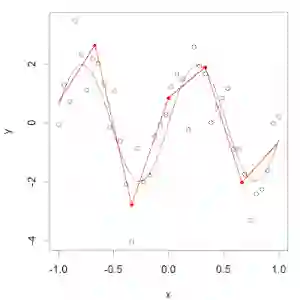
在使用分段多项式时,我们得非常小心,因为它有很多的限制条件。看看下边这幅图:
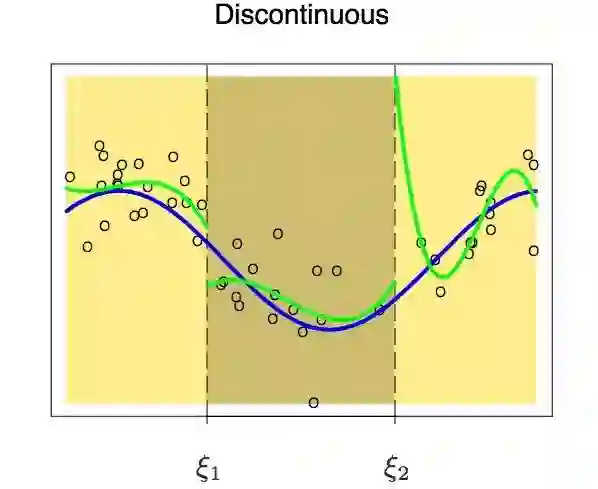
我们可能会遇到这种情况----节点两端的多项式在节点上不连续。这是要避免的,因为多项式应该为每一个输入生成一个唯一的输出。
上面那幅图很显然:在第一个节点处有两个不同的值。所以,为了避免这种情况,要有一个限制条件:节点两端的多项式在节点上也必须是连续的。
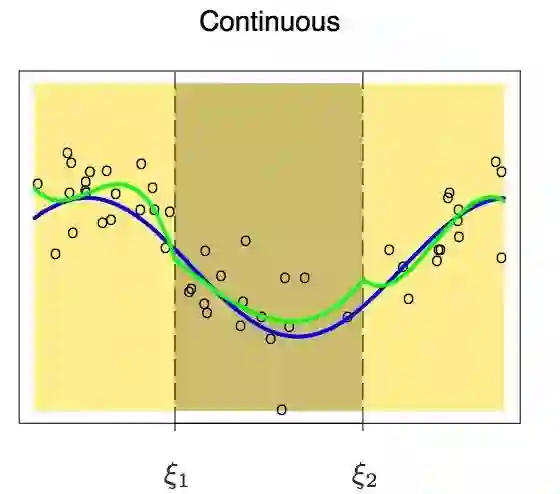
增加这个限制条件之后,我们得到了一组连续的多项式。但这样就够了吗?答案显然是否定的。在继续阅读下文之前,读者可以先考虑一下这个问题,看看我们是不是漏掉了什么。
观察上面的图可以发现,在节点处,曲线还是不平滑。为了得到在节点处依然光滑的曲线,我们又加了一个限制条件:两个多项式的一阶导数必须相同。要注意的一点是:我们每在分段三次多项式上增加一个约束,都相当于降了一个自由度。因为我们降低了分段多项式拟合的复杂性。因此,在上述问题中,我们只使用了10个自由度而不是12个。
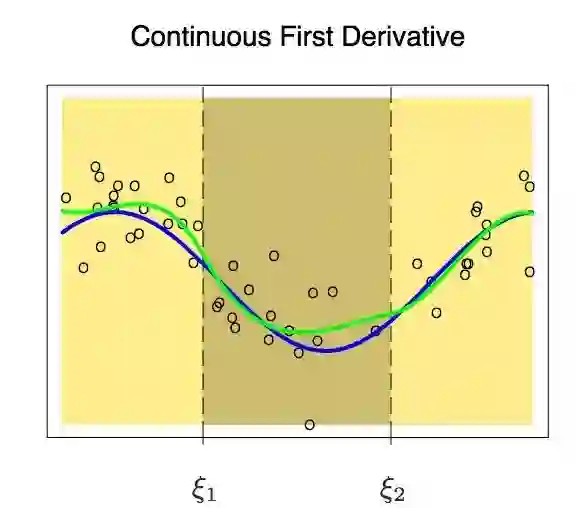
在加上关于一阶导数的约束以后,我们得到了如上所示的图形。因为刚才新增加约束的缘故,它的自由度从12个减少到了8个。但即便目前曲线看起来好多了,但还有一些可以改进的空间。现在,我们又要新增加一个约束条件:两个多项式在节点处的二次导数必须相等。
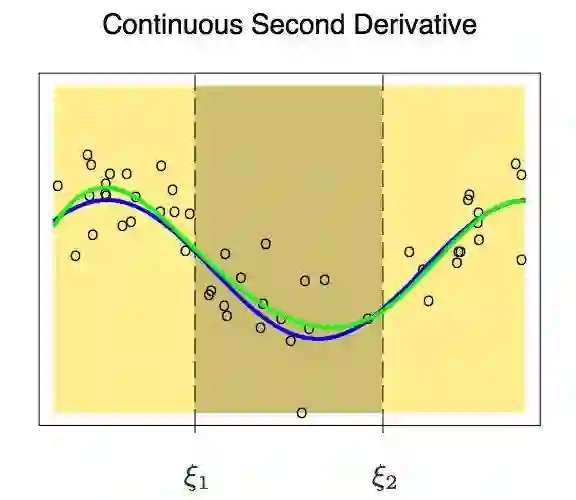
这次的结果看起来真的是好多了。它进一步将自由度下降为6个。像这样具有m-1阶连续导数的m阶多项式被称为样条。所以,在上边的图中,我们实际上是建立了一个三次样条。
三次样条和自然三次样条
三次样条是具有一组额外约束(连续性、一阶导数连续性、二阶导数连续性)的分段多项式。通常,一个有K个节点的三次样条其自由度是4+K。很少会用到比三次还要高阶的样条(除非是对光滑性非常感兴趣)
from patsy import dmatrix
import statsmodels.api as sm
import statsmodels.formula.api as smf
#生成一个三节点的三次样条(25,40,60)
transformed_x = dmatrix("bs(train, knots=(25,40,60), degree=3, include_intercept=False)", {"train": train_x},return_type='dataframe')
#在数据集及上拟合广义线性模型
fit1 = sm.GLM(train_y, transformed_x).fit()
#生成一个4节点的三次样条曲线
transformed_x2 = dmatrix("bs(train, knots=(25,40,50,65),degree =3, include_intercept=False)", {"train": train_x}, return_type='dataframe')
#在数据集上拟合广义线性模型
fit2 = sm.GLM(train_y, transformed_x2).fit()
#在两个样条上均进行预测
pred1 = fit1.predict(dmatrix("bs(valid, knots=(25,40,60), include_intercept=False)", {"valid": valid_x}, return_type='dataframe'))
pred2 = fit2.predict(dmatrix("bs(valid, knots=(25,40,50,65),degree =3, include_intercept=False)", {"valid": valid_x}, return_type='dataframe'))
#计算RMSE值
valuesrms1 = sqrt(mean_squared_error(valid_y, pred1))
print(rms1)
-> 39.4
rms2 = sqrt(mean_squared_error(valid_y, pred2))
print(rms2)
-> 39.3
#我们将使用70个点进行图形的绘制
xp = np.linspace(valid_x.min(),valid_x.max(),70)
#进行一些预测
pred1 = fit1.predict(dmatrix("bs(xp, knots=(25,40,60), include_intercept=False)", {"xp": xp}, return_type='dataframe'))
pred2 = fit2.predict(dmatrix("bs(xp, knots=(25,40,50,65),degree =3, include_intercept=False)", {"xp": xp}, return_type='dataframe'))
#画出样条曲线和误差图
plt.scatter(data.age, data.wage, facecolor='None', edgecolor='k', alpha=0.1)
plt.plot(xp, pred1, label='Specifying degree =3 with 3 knots')
plt.plot(xp, pred2, color='r', label='Specifying degree =3 with 4 knots')
plt.legend()
plt.xlim(15,85)
plt.ylim(0,350)
plt.xlabel('age')
plt.ylabel('wage')
plt.show()
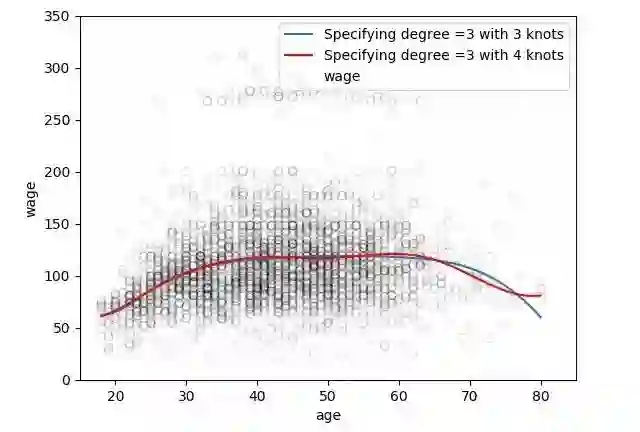
众所周知,多项式拟合数据在边界附近往往表现的很不稳定。这是很危险的。样条也有类似的问题。那些拟合超出边界节点数据的多项式比该区域区间中相应的全局多项式得出的结果更加让人意外。为了将这种曲线的平滑性延伸到边界之外的节点上,我们将使用被称为自然样条的特殊类型样条。
自然三次样条又多一个约束条件,即:要求函数在边界之外是线性的。这个条件将三次和二次部分变为0,每次自由度减少2个,两个端点共减少4个自由度,最后k+4减少为k。
#生成自然三次样条
transformed_x3 = dmatrix("cr(train,df = 3)", {"train": train_x}, return_type='dataframe')
fit3 = sm.GLM(train_y, transformed_x3).fit()
#在验证集上进行预测
pred3 = fit3.predict(dmatrix("cr(valid, df=3)", {"valid": valid_x}, return_type='dataframe'))
#计算RMSE的值
rms = sqrt(mean_squared_error(valid_y, pred3))
print(rms)
-> 39.44
#选取其中70个点进行作图
xp = np.linspace(valid_x.min(),valid_x.max(),70)
pred3 = fit3.predict(dmatrix("cr(xp, df=3)", {"xp": xp}, return_type='dataframe'))
#画出样条曲线
plt.scatter(data.age, data.wage, facecolor='None', edgecolor='k', alpha=0.1)
plt.plot(xp, pred3,color='g', label='Natural spline')
plt.legend()
plt.xlim(15,85)
plt.ylim(0,350)
plt.xlabel('age')
plt.ylabel('wage')
plt.show()
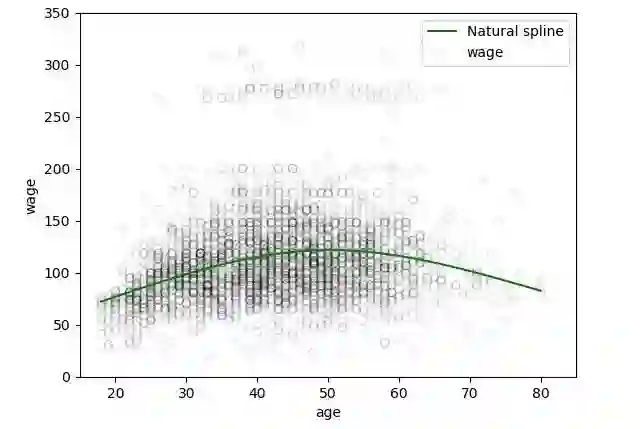
如何选取确定节点的数量和位置
当我们拟合一个样条曲线时,该如何选取节点呢?一个可行的方法是选择那些剧烈变化的区域,因为在这种地方,多项式的系数会迅速改变。所以,可以将在那些我们认为函数值变化剧烈的地方设置更多的节点,在比较稳定的地方少放一些。
不过虽然这种方法虽然效果还可以,但是实际上经常是以一种统一的方式来选取节点。一种方法是指定所需的自由度,然后由软件自动的将相应数量的节点放在数据的统一分位数处。
或者另一种选择是改变节点的数量,不断实践来测试到底哪一种方案会得到更好的曲线。
当然还有一种更加客观的做法-----交叉验证,要是用这种方法,我们要做到以下几点:
取走一部分数据
选择一定数量的节点使样条能拟合剩下的这些数据
再用样条去预测之前取走的那部分数据
不断重复这个过程,直到所有的数据都被取走一次。再计算整个交叉验证的RMSE。这个过程可以针对不同数量的节点进行重复,最后我们选择使得RMSE值最小的那个K值。
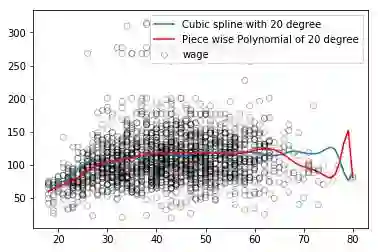
比较对样条回归和多项式回归进行比较
通常情况下,样条回归总是表现得的总是比多项式回归要好一些。这是因为多项式回归必须要用很高阶的项才能对数据拟合出比较灵活的模型。但是样条回归则是通过增加节点的数量做到这一点,同时还保持了阶数不变。
而且样条回归方法会得到更加稳定的模型。它允许我们在函数变化比较剧烈的地方增加更多节点,反之,函数变化平缓的地方节点就会少一些。多项式模型如果要求更灵活,它就会牺牲边界上的稳定性,但三次自然样条却很好的兼顾了灵活性和稳定性。
结语
在这篇文章中,我们学习了样条回归以及其在与线性回归及多项式回归相比时的一些优势。还有另外一种生成样条的方法叫做平滑样条。它与Ridge/Lasso正则化类似,乘惩罚结合了损失函数和平滑函数。大家可以在《统计学习入门》一书中阅读更多的内容。或者你感兴趣的话,也可以在一个具有很多变量的数据集上试试看这些方法,亲身体会一下个中差异。
译者补充
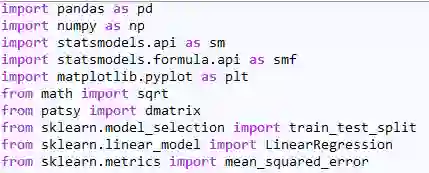
本文所有实验需要的包汇总:
原文标题:Introduction to Regression Splines (with Python codes)
原文链接:https://www.analyticsvidhya.com /blog/2018/03/introduction-regression-splines-python-codes/
译者简介

张逸,中国传媒大学大三在读,主修数字媒体技术。对数据科学充满好奇,感慨于它创造出来的新世界。目前正在摸索和学习中,希望自己勇敢又热烈,学最有意思的知识,交最志同道合的朋友。
翻译组招募信息
工作内容:需要一颗细致的心,将选取好的外文文章翻译成流畅的中文。如果你是数据科学/统计学/计算机类的留学生,或在海外从事相关工作,或对自己外语水平有信心的朋友欢迎加入翻译小组。
你能得到:定期的翻译培训提高志愿者的翻译水平,提高对于数据科学前沿的认知,海外的朋友可以和国内技术应用发展保持联系,THU数据派产学研的背景为志愿者带来好的发展机遇。
其他福利:来自于名企的数据科学工作者,北大清华以及海外等名校学生他们都将成为你在翻译小组的伙伴。
点击文末“阅读原文”加入数据派团队~
转载须知
如需转载,请在开篇显著位置注明作者和出处(转自:数据派ID:datapi),并在文章结尾放置数据派醒目二维码。有原创标识文章,请发送【文章名称-待授权公众号名称及ID】至联系邮箱,申请白名单授权并按要求编辑。
发布后请将链接反馈至联系邮箱(见下方)。未经许可的转载以及改编者,我们将依法追究其法律责任。

点击“阅读原文”拥抱组织




