为什么我们依然觉得AI换脸很“假”?

大数据文摘转载自数据实战派
作者:Martin Anderson
译者:张雨佳
《星球大战》的衍生剧《波巴·费特之书》(The Book of Boba Fett)中,曾有一集引起粉丝们的激励讨论。这是因为,年轻版 Mark Hamill 由工业光魔公司(Industrial Light and Magic)雇佣 deepfakes 从业者 Shamook 制作而成。
尽管 AI 换脸方法在 2020 年 CGI 技术的基础上有很大进步,而且总体上符合当前 AI 换脸的最佳视觉标准,但有一部分粉丝认为,《星球大战》中“Young Luke Skywalker”的新造型与前一部相比有一定缺陷。
比如最明显的问题是,在以 Skywalker 为主角的长镜头中人物缺乏表现力和细腻真切的情感,这是使用 AI 换脸的典型结果,比 CGI 特效更明显。The Verge 网站认为,Boba Fett 的 AI 换脸结果像“1983 年 Mark Hamill 那张神秘且毫无表情的冰块脸”。
但不管工业光魔公司背后到底使用的是什么技术,AI 换脸目前存在着难以传达细腻情感的根本性问题。
无论是通过改变架构还是改进原始训练素材,都很难解决这个问题。
不过 viral deepfakers 方法在选择目标视频时通常会更加谨慎,从而可以规避这一问题。
面部对齐的局限性
最常用的两个 AI 换脸开源代码库是 DeepFaceLab(DFL)和 FaceSwap,它们都脱胎于 2017 年。DFL 尽管功能有限,但在视觉特效(VFX)行业拥有巨大的领先优势。
这些代码的最初任务是从原始素材(即视频帧或静态图像)中提取人脸特征点。

DFL 和 FaceSwap 都使用了面部定位网络(FAN),FAN 可以为提取出来的人脸创建 2D 和 3D 特征点(如上图所示)。3D 特征点可以广泛感知人脸的方向,包括侧面的轮廓和比较尖锐的角度。
下面是一种非常基本的评估像素准则:

来自 FaceSwap 的面部轮廓的粗略标准,来源:
https://forum.faceswap.dev/viewtopic.php?f=25&t=27
该标准需要考虑面部最基本的线条:比如眼睛和下巴可以扩大和缩小,嘴巴的基本形状(如微笑、皱眉等)也可以被追踪和调整。从相机的角度来看,面部可以向任意方向旋转 200 度左右。
而这些粗糙的像素边界位置,是整个 AI 换脸过程中唯一精确的面部准则。训练时也只是与对应像素或周围像素进行比较,然后选择对应的处理方法。

DeepFaceLab 中的训练示例
(来源:https://medium.com/geekculture/realistic-deepfakes-with-deepfacelab-530e90bd29f2)
由于没有面部子区域的拓扑结构(包括脸颊的凹凸度、年龄细节、酒窝信息等),所以想尝试在匹配原始人物(你想改变的脸)和目标人物(你想复制的脸)中保持“细腻”的特征是不太可能的。
利用有限的数据
训练 AI 换脸模型需要获取两个人物之间的匹配数据,但这并不容易。需要匹配的角度越特殊,你就越有可能在人物 A 和人物 B 之间的(特殊角度)匹配上做出妥协:保持相同的表情。

人脸数据并不完全匹配。
如上图所示,这两个人物的面部结构非常相似,但仍不能达到完全匹配,而这已经是数据集中匹配度最高的结果了。
不过上图中依然存在明显的差异:角度、镜头和灯光没有完全匹配;人物 A(左图)没有像人物 B(右图)一样完全闭上眼睛;人物A的图像质量和压缩率更差;人物 B 看起来比 A 更快乐。
虽然有以上种种差异,但我们只能依靠这些已有素材对 AI 换脸模型进行训练。
因为出现 A 与 B 完全匹配的情况很少,同样训练集中也很少有类似的匹配。因此训练常常会发生欠拟合和过拟合现象。
欠拟合:如果某些特殊角度的匹配数据较少(即数据集中数据量比较大,但该角度的匹配图像对较少),那它与更“简单普遍”的匹配数据相比将不会得到有效训练。因此,AI 换脸模型就不能对这个特殊的角度或表情进行很好地表达。
过拟合:由于缺乏足够的匹配数据,AI 换脸模型有时会复制多次数据集中的匹配数据,以便在最终模型中获得更好的结果。但这可能会导致过拟合,用这种模型制作的 AI 换脸视频很可能会对两张照片的不匹配之处进行复制,比如眼睛的闭合程度。
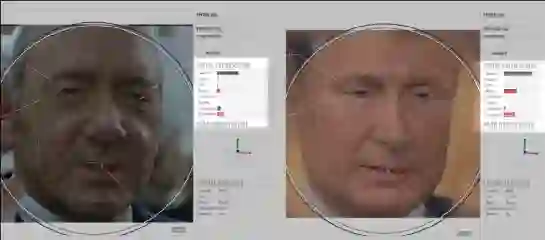
如下图所示,是用 DeepFaceLab 开源方法将弗拉基米尔普京(Vladimir Putin)训练为凯文史派西(Kevin Spacey)的样子,进行了 16 万次迭代训练。

(来源:https://i.imgur.com/OdXHLhU.jpg)
大部分人看到上面的图片后,可能认为 Putin 在这些换脸测试中的结果比 Spacey 更具空间感。下面我们介绍一下在线表情识别程序是如何处理表情不匹配问题的:
(来源:https://www.noldus.com/facereader/measure-your-emotions)
根据这个比 DFL 和 Faceswap 更详细的面部特征分析,我们发现 Spacey 的换脸结果中很少有 Putin 那样的愤怒、厌恶和轻蔑的表情。
这些不同的表情分类是 entangled 包中的一部分,因为常用的 AI 换脸应用程序没有匹配表情或情绪的能力。
对我们来说,这些表情间差异很大。我们很小的时候就将阅读面部表情作为一种基本的生存技巧,并在成年后继续依赖这种技巧来与社会融合、实现进步以及交配,并将其作为一种持续的威胁评估方法。所以我们对微表情非常敏感,所以 AI 换脸技术终需对微表情表达进行处理。
事与愿违
虽然 AI 换脸技术革命带来了在现代电影和电视中插入“经典”电影明星的可能性,但人工智能无法以更兼容的定义和质量来拍摄之前的经典作品,而这对用户来说也很重要。
假设重现 Boba Fett 中的 Hamill 形象就需要一个训练好的 AI 换脸模型,那么就需要利用 Hamill 在制作《绝地归来》(Return of the Jedi)时,30 岁出头样子附近的片段作为训练数据。
这部影片采用伊士曼彩色负片 250T 5293/7293 胶片拍摄,当时被认为较好的中等偏细颗粒度的 250ASA 乳剂,在 80 年代末就已经从清晰度、颜色范围和保真度等方面被超过。在当时的经典之作《绝地归来》中,甚至连主角的特写镜头都没有,这使得图片颗粒度问题更加重要。

Hamill 在《绝地归来》(1983)中的一些镜头。
此外,我们通常会对以 Hamill 为主角的视觉特效镜头通过光学打印机处理,来增加胶片的颗粒度。卢卡斯影业也已经通过在档案馆中处理保存原始底片和几个小时未使用的原始镜头,解决了颗粒度问题。
同时为了丰富和多样化 AI 换脸数据集,我们通常会搜寻演员一个时间段内的所有作品。而 Hamill 在 1977 年经历车祸后外貌有所变化,并且在参演完《绝地归来》后几乎立即开始了他作为著名配音演员的第二职业,这就导致其数据素材过少,无法得到性能较好的 AI 换脸模型。
表情范围是否有限制
如果你想要 AI 换脸模型完成演员的夸张表情,那你需要广泛收集这些不常见面部表情的原始镜头。但很有可能在与年龄相匹配的镜头中不包含这种夸张表情。
例如,当《绝地归来》开始主线剧情时,Hamill 已经可以基本掌握自己的情绪了。如果这时你想用《绝地归来》的数据训练一个 Hamill 的 AI 换脸模型,你就需要一些限定范围内的情绪数据和不常见的面部表情,而不是他出演的那些早期作品。
你可能认为在《绝地归来》中 Skywalker 遇到巨大压力时,会提供比较夸张、有效的表情素材。但实际上这些场景中的脸部表情素材转瞬即逝,并且还受动作场面的运动模糊和快速剪辑的影响,导致素材无法得到有效使用。
概括:表情的融合
如果真的用 AI 换脸模型完成 Boba Fett 中 Skywalker 角色,那么他只能表现有限的表情范围,这不只是因为原始素材的缺少。AI 换脸模型在编码器-解码器训练过程中寻求一种通用模型,该模型能够从成千上万幅图像中成功提取重要特征,并尝试获得 AI 换脸数据集中没有或少见的面部角度。
如果 AI 换脸模型不具备这种灵活性,那它只能在每帧画面的基础上进行复制和粘贴,无法考虑时间上的连续性或背景信息。
而且该技术的发展可能会牺牲表情的真实性,任何“细腻”的表情都有可能不是真实的。我们的脸像 100 个设备精良的管弦乐队一样配合演奏,而 AI 换脸软件至少缺少了里面的弦乐部分。
情绪的表达差异
并不是所有的面部动作及其对我们的影响都是统一的,比如在罗杰·摩尔(Roger Moore)身上看起来漫不经心的挑眉动作,在赛斯·罗根(Seth Rogan)身上就显得不太老练。如果将玛丽莲·梦露的迷人魅力,利用 AI 换脸模型强加到一个充满“愤怒”和“不满”情绪的角色(比如 Aubrey Plaza 在 Parks and Recreation 第七季中扮演的角色)上时,就会传达出消极情绪。
因此,在 A、B 人脸数据之间的相同像素并不一定对模型表达相同的情绪起作用,但这是训练先进的 AI 换脸开源模型的前提。
我们期望的 AI 换脸模型,不仅能够识别表情并推断情绪,而且能够表现诸如愤怒、迷人、无聊、疲惫等高层次概念,并将这些情绪及相关表情在两个身份中进行不同表达,而不是单纯在嘴巴或眼睛的位置上进行复制。