动态 | 序列转换模型三合一!谷歌提出首个端到端的直接语音翻译模型

AI 科技评论按:不同语言之间的语音到语音转换早已不是什么新鲜事了,任务拆分简单直接,只需要把「源语言的语音识别模型(语音转文本)」、「文本到文本翻译模型」、「目标语言的语音生成模型(文本转语音)」这三个模型串联使用就可以。由于这三类模型的发展都各自比较成熟,现在市面上如谷歌翻译这样的软件产品、如科大讯飞翻译机这样的专用硬件设备都能达到很好的多语互译效果,准确率和延时都让人比较满意。
但技术研究的探索并不会就此止步。谷歌的研究人员们做了一次大胆的试验,尝试把语音转文、文本到文本翻译、文本转语音这三个步骤合并到同一个端到端模型中完成!在论文「Direct speech-to-speech translation with a sequence-to-sequence model」(通过一个序列到序列模型进行语音到语音的直接转换,https://arxiv.org/abs/1904.06037)中,他们用了一个带有注意力机制的序列到序列转换模型构建了新的翻译系统,完全抛弃了需要经过文本表示的中间步骤。他们把这个系统命名为 Translatotron。
Translatotron 介绍
端到端语音模型的萌芽最早是在 2016 年开始的,当时研究人员们发现可以用单个序列到序列转换模型实现语音到文本的转换。在 2017 年,谷歌的研究人员们已经在研究中表明了这样的端到端模型比传统的瀑布式模型有更好的表现(https://arxiv.org/abs/1703.08581)。此后,领域内提出了越来越多的改进方案,不断提升了端到端语音到文本序列转换模型的表现,包括谷歌自己也在近期又提出了利用弱监督数据继续提升表现的方案(https://arxiv.org/abs/1811.02050)。
Translatotron 则是全新的一步,直接把一个语言的语音转换为另一种语言的语音,不需要经过文本形式的中间表示环节。它把源语言语音的频谱图作为输入,然后直接输出说话内容在目标语言的语音频谱图。模型中会使用两个分别独立训练的组件:一个神经网络声码器,它会把输出的频谱图转换成时域的音频波形;另一个组件的使用是可选的,可以借助一个说话人音色编码器在生成的翻译语音中保留源语音的特点。
在训练过程中,这个序列到序列转换模型使用了一个多任务并行训练模型,它需要同时预测源语音转文本的结果、文本翻译的结果以及目标语音的频谱图。前两个任务仅作为辅助任务,在训练完成后就不再需要模型输出文本结果了。
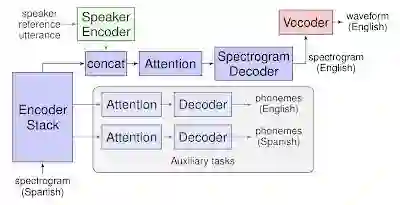
Translatotron 系统框图
模型表现
谷歌的研究人员们用一个额外的语音识别系统识别 Translatotron 的输出,然后通过 BLEU 分数定量地测试了模型的表现。虽然模型的表现不如传统的三步式的语音转换(这并不令人意外),但这已经证明了端到端的直接语音转换的可行性。
谷歌提供了多组 Translatotron 和基线(传统方法)语音转换的对比,两者都可以提供恰当的翻译,发音也很标准。可以在 https://google-research.github.io/lingvo-lab/translatotron/ 试听。
保留说话人特征
借助一个额外的说话人音色编码器,Translatotron 可以在转换后的语音中保留原本的说话人的声音特征,这让转换出的语音听起来更自然、避免生硬。这个功能利用了谷歌此前在说话人鉴别(https://arxiv.org/abs/1710.10467)以及文本转语音的说话人适应(https://arxiv.org/abs/1806.04558)方面的研究成果。
说话人音色编码器首先在说话人鉴别任务上进行了预训练,学习到了如何从一段短的语音中编码说话人声音的特点。让频谱编码器在音色编码器的作用下生成语音,得到的结果就可以含有非常相似的说话音色,即便说的内容是另一个语言。
试听例子 https://google-research.github.io/lingvo-lab/translatotron/#conversational。
除了保留说话人声音特征之外之外,根据谷歌研究人员们的测试,这个系统相比传统的三个步骤的系统还有多项优势:更快的推理(翻译)速度;天然地更善于避开识别和翻译阶段累积的错误;而且对于不需要翻译的词汇也处理得更好(比如名字和专有名词)。
结论
据谷歌的研究人员们目前所知,这是世界上首个可以直接把一种语言的语音翻译到另一种语言语音的端到端模型;除此之外它还可以保留源说话人的声音特点。这项研究可能是未来更多端到端语音翻译系统研究的开端。
详细内容可以阅读论文原文 https://arxiv.org/abs/1904.06037
via:
https://ai.googleblog.com/2019/05/introducing-translatotron-end-to-end.html
2019 全球人工智能与机器人峰会
由中国计算机学会主办、雷锋网和香港中文大学(深圳)联合承办的 2019 全球人工智能与机器人峰会( CCF-GAIR 2019),将于 2019 年 7 月 12 日至 14 日在深圳举行。
届时,诺贝尔奖得主JamesJ. Heckman、中外院士、世界顶会主席、知名Fellow,多位重磅嘉宾将亲自坐阵,一起探讨人工智能和机器人领域学、产、投等复杂的生存态势。

点击阅读原文,加入 NLP 顶会交流小组与同行切磋、交流


