学界 | OpenAI最新发现:易于实现的新方法,轻松加快学习速度
AI 科技评论按:OpenAI最新发现表明,通过在网络的参数空间中加入噪声,可以获得远优于在网络的行为空间中增加噪声的表现。此外,他们发布了一系列基准代码,覆盖多个网络。AI科技评论编译如下:
OpenAI实验室最新发现:频繁地给增强学习算法中的参数增加自适应噪声后,能得到更好的结果。这种方法实现简单,基本上不会导致结果变差,值得在任何问题上尝试。

图1:加入行为空间噪声训练的模型
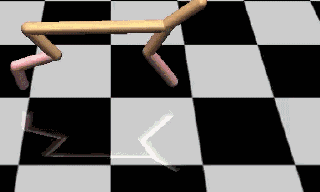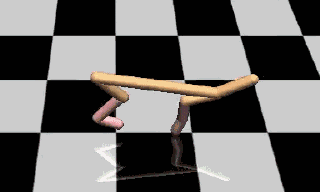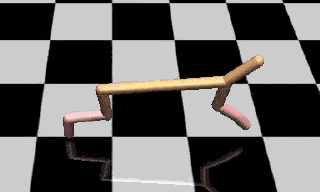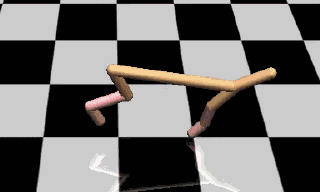
图2:加入参数空间噪声训练的模型
参数噪声可以帮助算法高效地探索出合适的动作范围,在环境中获得优良表现。如图1、图2所示,经过216个episode的训练之后,没有加入参数噪音的DDPG会频繁产生低效的奔跑行为,而加入参数噪声训练之后产生的奔跑行为得分更高。
增加参数噪声后,智能体学习任务的速度变得更快,远优于其他方法带来的速度增长。在半猎豹运动环境(图1、图2)中经过20个episode的训练之后,这项策略的得分在3000分左右,而采用传统动作噪音训练的策略只能得到1500分左右。
在参数空间增加噪声
参数噪声方法是将自适应噪声加在神经网络策略的参数中,而不是加在行为空间。传统的增强学习(RL)利用行为空间噪声来改变智能体每一刻执行的动作的可能性。参数空间噪声使智能体的参数直接增加了随机性,改变了智能体做出的决策的类型,使它们总是能完全依赖于对当前环境的感知。这种技术介于进化策略(可以控制智能体的参数,但是当它在每一步中探索环境时,不会再次影响它的行为)和类似TRPO、DQN、DDPG这样的深度增强学习方法之间 (不能控制参数,但可以在策略的行为空间上增加噪声)。
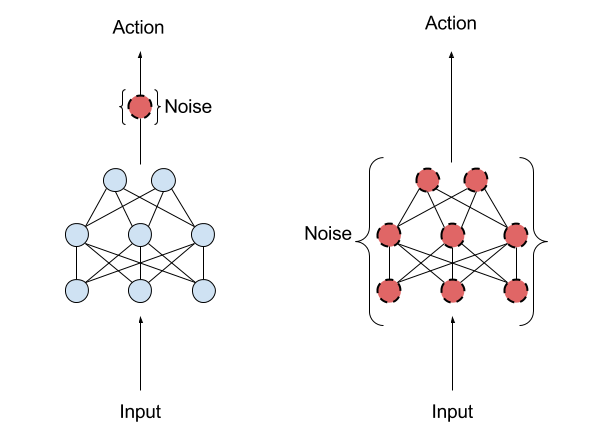
图3:左图是行为空间噪声,右图是参数空间噪声
参数噪声可以让算法更高效的探索环境,得到更高的分数和更优雅的动作。因为有意的在策略参数中增加噪声,能使智能体在不同时刻的探索保持一致,而在行为空间中增加噪声,会让探索过程更加难以预测,这种探索过程也就与智能体的参数没有特定的关联性。
人们之前曾尝试过将参数噪声应用于策略梯度。在OpenAI的探索之下,这种方法现在可以用在更多地方了,比如用在基于深度神经网络的策略中,或是用在基于策略和策略无关的算法中。

图4:加入行为空间噪声训练的模型

图5:加入参数空间噪声训练的模型
如图4、图5所示,增加参数空间噪声后可以在赛车游戏中获得更高的分数。经过2个episode的训练,训练中在参数空间增加噪声的DDQN网络学会了加速和转弯,而训练中在行为空间增加了噪声的网络展现出的动作丰富程度就要弱很多。
在进行这项研究时他们遇到了如下三个问题:
不同层数的网络对扰动的敏感性不同。
在训练过程中,策略权重的敏感性可能会随着时间改变,这导致预测策略的行动变得很难。
选取合适的噪声很困难,因为很难直观地理解训练过程中参数噪音是怎么影响策略的。
第一个问题可以用层级归一化来解决,这可以保证受到了扰动的层的输出(这个输出是下一个层级的输入)与未受扰动时的分布保持相似。
可以引入一种自适应策略来调整参数空间扰动的大小,来处理第二和第三个问题。这一调整是这样实现的:测量扰动对行为空间的影响和行为空间噪声与预定目标之间的差异(更大还是更小)。这一技巧把选择噪声大小的问题引入行为空间,比参数空间具有更好的解释性。
选择基准,进行benchmark
OpenAI发布了一系列基准代码,为DQN、双DQN(Double DQN)、决斗DQN(Dueling DQN)、双决斗DQN(Dueling Double DQN)和DDPG整合了这种技术。
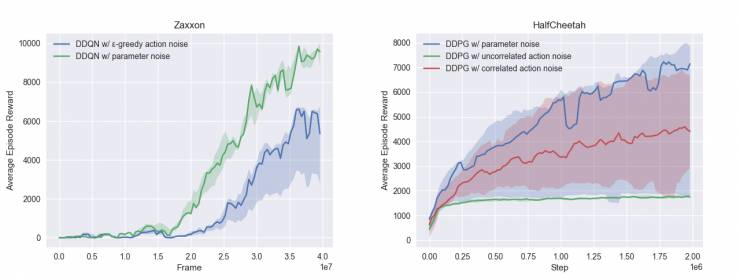
此外,也发布了DDQN在有无参数噪声下玩部分Atari游戏性能的基准。另外还有DDQN三个变体在Mujoco模拟器中一系列连续控制任务下的性能基准。
研究过程
在第一次进行这项研究时,OpenAI发现应用到DQN的Q函数中的扰动有时候太极端了,导致算法重复执行相同的动作。为了解决这个问题,他们添加了一个独立的策略表达流程,能够像在DDPG中一样明显的表示出策略(在普通的DQN网络中,Q函数只能隐含的表示出策略),使设置与其他的实验更相似。
然而,在为这次发布准备代码时,他们做了一次实验,在使用参数空间噪声时没有加独立的策略策略表达流程。
他们发现实验的结果与增加独立策略表达流程之后的结果很相似,但实现起来更简单。进一步的实验证实独立的策略头确实是多余的,因为算法很可能在早期的实验中就得到了改进(他们改变了调节噪声的方式)。这种方法更简单、更具有可行性,降低了训练算法的成本,并且能得到相似的结果。
重要的是要记住,AI算法(特别是在增强学习中)可能会出现一些细微的失败,这种失败会导致人们寻找解决方案的时候很难对症下药。
via:OpenAI blog
论文地址:https://arxiv.org/abs/1706.01905
代码地址:https://github.com/openai/baselines
AI科技评论编译。
———————— 给爱学习的你的福利 ————————
CCF-ADL在线讲习班 第80期:区块链—从技术到应用
顶级学术阵容,50+学术大牛
快速学习区块链内涵,了解区块链技术实现方法
课程链接:http://www.mooc.ai/course/113
或点击文末阅读原文

——————————————————————————



