想轻松复现深度强化学习论文?看这篇经验之谈
选自Amid Fish
作者:Matthew Rahtz
机器之心编译
近期深度强化学习领域日新月异,其中最酷的一件事情莫过于 OpenAI 和 DeepMind 训练智能体接收人类的反馈而不是传统的奖励信号。本文作者认为复现论文是提升机器学习技能的最好方式之一,所以选择了 OpenAI 论文《Deep Reinforcement Learning from Human Preferences》作为 target,虽获得最后成功,却未实现初衷。如果你也打算复现强化学习论文,那么本文经验也许是你想要的。此外,本文虽对强化学习模型的训练提供了宝贵经验,同时也映射出另外一幅残酷画面:强化学习依然难免 hype 之嫌;强化学习的成功不在于其真正有效,而是人们故意为之。

瑞士卢加诺大学信息学硕士 Tim Dettmers 对本文的点评
首先,整体而言,强化学习问题要远比预期的更为棘手。
主要原因是强化学习本身非常敏感,需要纠正大量的细节,如果不这么做,后面诊断问题所在会非常难。
实例 1:基本实现完成之后,训练效果并未跟上。我对问题所在充满各种想法,但经过数月的苦思冥想,发现问题出现在关键阶段中的奖励归一化和像素数据。尽管想通了这点,却仍未搞明白整个问题:像素数据进入的奖励探测器网络的准确度刚刚好,我花了很长时间终于明白仔细检查已预测的奖励足以发现奖励归一化漏洞。一句话,搞明白发生了什么问题几乎是偶然性的,找出最终可以导向正确路径的微小的不一致性。
实例 2:最后的代码清理完成之后,我多少有些错误地实现了 dropout。奖励探测器网络需要一对视频片段作为输入,由权重共享的两个网络同等处理。如果你添加 dropout,并在每个网络中不小心给了它相同的随机种子,每个网络将获得不同的 dropout,因此视频片段将不会被同等处理。正如结果表明完全修正它会破坏训练,尽管网络的预测准确度看起来一模一样。
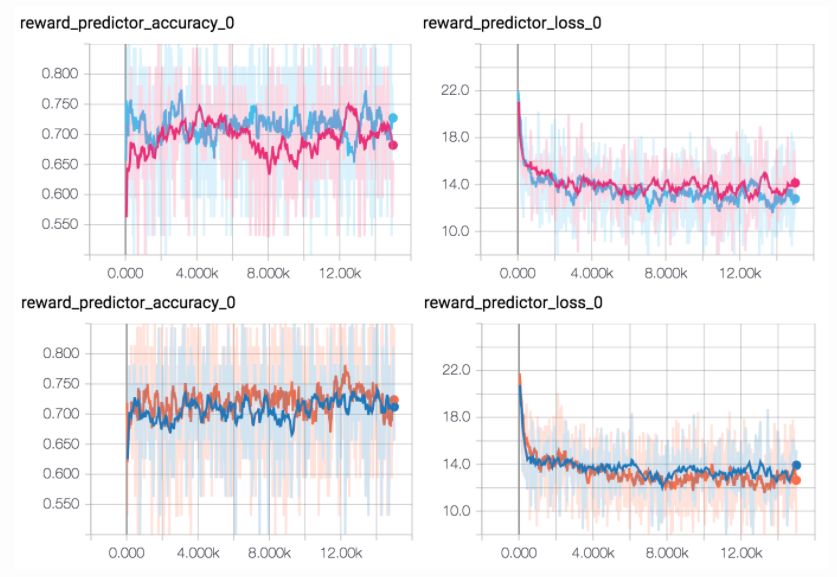
找出被破坏的那一个。没错,我也没找到。
在我印象中这种情况非常普遍(比如《Deep Reinforcement Learning Doesn't Work Yet》)。我的解读是你要像对待数学问题一样对待强化学习项目。它不同于编程问题,你可以在数天内完成它;它更像是你在解决一个谜题,没有规律可循,唯一的方法是不断尝试,直到灵感出现彻底搞明白。
这需要你不断尝试,并对实现过程中的困惑保有最敏锐的嗅觉。
该项目中有很多这样的点,其中唯一的线索就是那些看起来无关紧要的小事情。比如,某些时候采用不同帧之间的差异作为特征会更加奏效。通过一些新特征继续向前会非常诱人,但我很困惑当时在我工作的简单环境中会造成如此大的差异。这只有通过思考这些困惑并意识到采用不同帧之间的差异,才能给正则化问题提供线索。
我不完全确定如何使人在这方面做更多,但我目前最好的猜测是:
学习识别困惑的感觉。「事情不太对的感觉」有很多种,有时是代码很丑,有时是担心浪费时间在错误的事情上。但有时是「你看到了一些意料之外的事情」。能够精确知道令自己不舒服的事情很重要,因此你可以……
培养思考困惑来源的习惯。一些不舒服的原因最好选择忽略(比如原型设计时的代码风格),但困惑并不是。一旦遇到困惑。立即调查其来源对你来说很重要。
无论如何:做好每次卡住数周的准备。(并相信坚持下来就会攻克难关,并留意那些小的细节。)
说到和过去的编程经验的区别,第二个主要学习经验是观念模式的区别,即需要长时间的工作迭代。
调试过程大致涉及 4 个基本步骤:
收集关于问题性质的证据;
基于已有证据对问题作出假设;
选择最可能成立的假设,实现一个解决办法,看看结果如何;
重复以上过程直到问题解决。
在我做过的大部分编程工作都习惯于快速反馈。如果有程序不工作了,你可以在数秒或数分钟内做出改变并查看有没有奏效。收集证据是很简单的工作。实际上,在快速反馈的情况下,收集证据可能比作出假设要简单得多。当你能凭直觉想到解决方案(并收集更多证据)时,为什么还要花费那么多时间考虑所有的可能性呢?换句话说,在快速反馈的情况下,你可以通过尝试而不是仔细考虑并迅速地缩小假设空间。
但当单次运行时间达到 10 小时的时候,尝试和反馈的策略很容易使你浪费很多的时间。
并行运行多个解决方案会有帮助,如果(a)你有计算机集群的云计算资源;(b)由于上述的强化学习中的各种困难,如果你迭代得太快,可能永远无法意识到你真正需要的证据。
从「多实验、少思考」到「少实验、多思考」的转变是提高效率的关键。当调试过程需要耗费很长的迭代时间时,你需要倾注大量的时间到建立假设上,即使需要花费很长的时间,比如 30 分钟甚至 1 小时。在单次实验中尽可能详实地检验你的假设,找到能最好地区分不同可能性的证据。
转向「少实验、多思考」的关键是保持细节丰富的工作日志。当每次实验的运行时间较少的时候,可以不用日志,但在实验时间超过一天的时候,很多东西都容易被忘记。我认为在日志中应该记录的有:
日志 1:你现在所需要的具体输出;
日志 2:把你的假设大胆地写出来;
日志 3:简单记录当前的进程,关于当前运行实验想要回答的问题;
日志 4:实验运行的结果(TensorBoard 图,任何其它重要观测),按运行实验的类型分类(例如按智能体训练的环境)。
我起初记录相对较稀疏的日志,但到了项目的结束阶段,我的态度转变成了「记录我头脑中出现过的所有东西」。这很费时,但也很值得。部分是因为某些调试过程需要交叉参照结果,这些结果可能是数天前或数周前做出的。部分是因为(至少我认为)思考质量的通常提升方式是从大量的更新到有效的心理 RAM。

典型日志
为了从所做的实验中得到最大的效果,我在实验整个过程中做了两件事:
首先,持记录所有可以记录的指标的态度,以最大化每次运行时收集的证据量。有一些明显的指标如训练/验证准确率,但是在项目开始时花费一点时间头脑风暴,研究哪些指标对于诊断潜在问题比较重要是很有益的。
我这么推荐的部分原因是由于事后偏见:我发现哪些指标应该更早记录。很难提前预测哪些指标有用。可能有用的启发式方法如下:
对于系统中的每个重要组件,考虑什么可以被度量。如果是数据库,那么度量它的增长速度。如果是队列,则度量各个项的处理速度。
对于每个复杂步骤,度量其不同部分所花费时间。如果是训练循环,则度量运行每个批次要花费多长时间。如果是复杂的推断步骤,则度量每个子推断任务所花费的时间。这些时间对之后的性能 debug 大有裨益,有时候甚至可以检查出难以发现的 bug。(例如,如果你看到某个部分花费时间很长,那么它可能出现内存泄露。)
类似地,考虑搜集不同组件的内存使用情况。小的内存泄露可能揭示所有问题。
另一个策略是查看别人使用什么度量指标。在深度强化学习中,John Schulman 在其演讲《Nuts and Bolts of Deep RL Experimentation》中给出了一些好主意(视频地址:https://www.youtube.com/watch?v=8EcdaCk9KaQ;slides 地址:http://joschu.net/docs/nuts-and-bolts.pdf;摘要:https://github.com/williamFalcon/DeepRLHacks)。对于策略梯度方法,我发现策略熵是判断训练是否开始的优秀指标,比 per-episode 奖励更加敏锐。
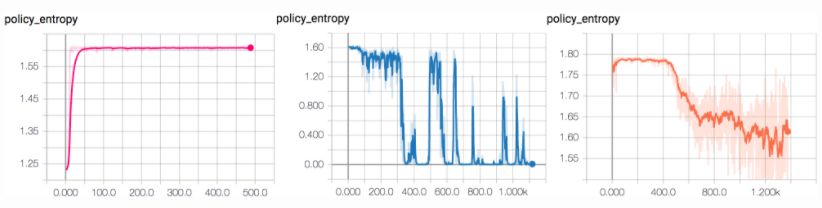
不健康和健康的策略熵图示例。失败模式 1(左):收敛至常数熵(随机选择动作子集)。失败模式 2(中):收敛至零熵(每次选择相同的动作)。右:成功的 Pong 训练运行中的策略熵。
如果你在记录的指标中看到了一些可疑的现象,记得注意混淆,宁可假设它很重要也不要轻视,比如一些数据结构的低效实现。(我因为忽视了每秒帧数的微小而神秘的衰减,导致好几个月没找到一个多线程 bug。)
如果你能一次性看到所有指标,那么 debug 就容易多了。我喜欢在 TensorBoard 上有尽可能多的指标。用 TensorFlow 记录任意指标有点棘手,因此考虑使用 easy-tf-log(https://github.com/mrahtz/easy-tf-log),它提供简单的 tflog(key, value) 接口,无需任何额外设置。
另一件有助于从运行中获得更多信息的事情是,花时间尝试和提前预测失败。
多亏了事后偏见,在回顾实验过程时往往很容易发现失败原因。但是真正令人挫败的是在你观察之前,失败模式就已经很明显了。开始运行后,第二天回来一看失败了,在你开始调查失败原因之前,你就已经发现:「噢,一定是因为我忘记 frobulator 了」。
简单的事情是有时你可以提前触发「半事后观察」。它需要有意识的努力——在开始运行之前先停下来思考五分钟哪里可能出错。我认为最有用的是:
问问自己:「如果这次运行失败了,我会有多惊讶?」
如果答案是「不会很惊讶」,那么想象自己处于未来情境中:运行失败了,问自己:「哪些地方可能出问题:」
修复想到的问题。
重复以上过程直到问题 1 的答案是「非常惊讶」(或至少是「要多惊讶就多惊讶」)。
总是会有很多你无法预测的失败,有时你仍然遗漏了一些明显的事情,但是这个过程至少能够减少一些因为没有提前想到而出现的愚蠢失误。
最后,该项目最令人惊讶的是花费时间,以及所需的计算资源。
前者需要从日历时间的角度来看。我最初的估计是它作为业余项目,应该花费 3 个月时间,但它实际上用了 8 个月。(而我一开始预估的时间就已经很消极了!)部分原因是低估了每个阶段可能花费的时间,但是最大的低估是没有预测到该项目之外出现的其他事情。很难说这个规律有多广泛,但是对于业余项目来说,把预估时间乘以 2 可能是不错的方法。
更有趣的是每个阶段实际花费的时间。我原本的项目计划中主要阶段时间表基本如下:
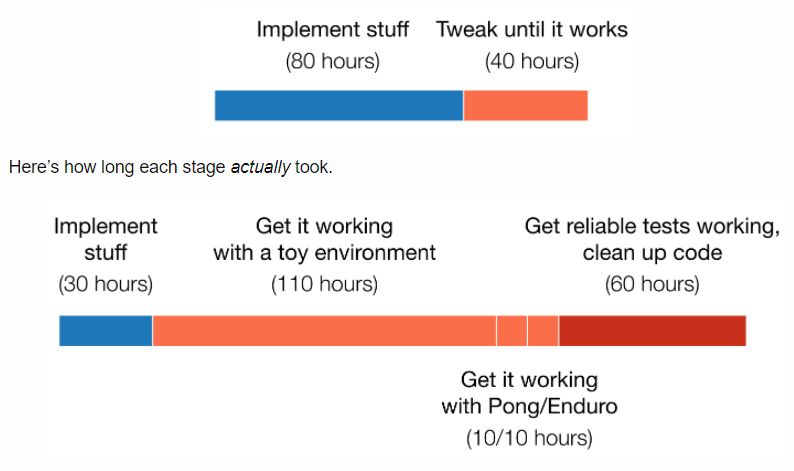
写代码不费时,费时的是调试。事实上,在一个所谓的简单环境上花费的时间 4 倍于最初的实现。(这是我第一个花了数小时的业余项目,但所得经验与过去的机器学习项目相似。)
注:从一开始就仔细设计你认为什么应该是强化学习的「简单」环境。尤其是,仔细思考:(a)你的奖励是否真正传达解决任务的正确信息,是的,这很容易弄砸;(b)奖励是仅依赖之前的观测结果还是也依赖当前的动作。在你进行任意的奖励预测时,后者都可能是相关的。
第二个令人惊讶的事情是项目所需的计算时间。我很幸运可以使用学校的机房,虽然只有 CPU 机,但已经很好了。对于需要 GPU 的工作(如在一些小部分上进行快速迭代)或机房太繁忙的时候,我用两个云服务进行实验:谷歌云计算引擎的虚拟机、FloydHub。
谷歌云计算引擎挺好的,如果你只想用 shell 访问 GPU 机器,不过我更多地是在 FloydHub 上进行实验的。FloydHub 是针对机器学习的云计算服务。运行 floyd run python awesomecode.py,FloydHub 会设置一个容器,加载和运行你的代码。使 FloydHub 如此强大的两个关键因素是:
GPU 驱动预安装的容器和常用库。
每次运行都可以自动存档。每次运行时使用的代码、开始运行的命令、任意命令行输出和任意数据输出都可以自动保存,并通过网页接口设置索引。
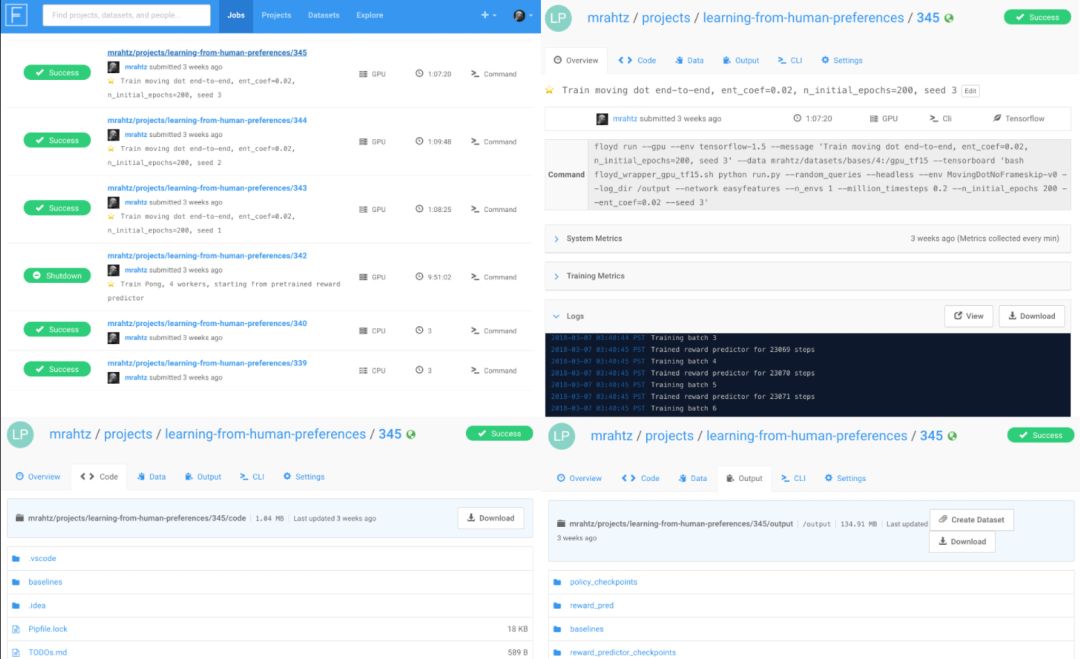
FloydHub 的网页接口。上方:过去运行的索引,和单次运行的概览。下方:每次运行所用代码和运行的任意数据输出都可以自动存档。
第二个功能非常重要。对于任何项目,对尝试过程的详细记录和复现之前实验的能力都是绝对必要的。版本控制软件有所帮助,但是 a)管理大量输出比较困难;b)需要极大的勤勉。(比如,如果你开始一些运行,然后做了一点更改,启动了另一次运行,当你提交第一批运行的结果时,是否能够清楚看到使用了哪些代码?)你可以仔细记录或展开自己的系统,但是使用 FloydHub 压根不需要花费这么多精力。
我喜欢 FloydHub 的其他原因是:
运行结束时容器自动关闭。无需检查容器是否关闭、虚拟机是否关闭。
账单比云虚拟机更加直接。
我认为 FloydHub 的一个痛点在于不能自定义容器。如果你的代码中有大量的依赖包,你需要在所有运行启动前安装它们。这限制了短期运行上的迭代次数。当然,你可以创建一个「dataset」,其中包含了对文件系统的安装依赖包的改变,然后在每次运行起始阶段复制该 dataset 的文件(例如,create_floyd_base.sh)。这很尴尬,但仍比不上处理 GPU 驱动的时候。
FloydHub 相比谷歌云虚拟机更贵一些:1.2 美元/小时用一台 K80 GPU 的机器,对比 0.85 美元/小时用一台配置相似的虚拟机。除非你的预算很有限,我认为 FloydHub 带来的额外便利是值得的。只有在并行运行大量计算的时候,谷歌云虚拟机才是更加划算的,因为你可以在单个大型虚拟机上堆栈。
总的来说,该项目花了:
计算引擎上 150 个小时的 GPU 运行时间和 7700 个小时的(wall time × cores)的 CPU 运行时间。
FloydHub 上 292 个小时的 GPU 运行时间。
大学计算机集群上的 1500 个小时(wall time, 4 to 16 cores)的 CPU 运行时间。
我惊讶地发现在实现项目的 8 个月期间,总共花费了 850 美元(FloydHub 花了 200 美元,谷歌云虚拟机花了 650 美元)。
但是即使花了这么多的精力,我在项目的最后阶段仍然遇到了很大的惊(jing)喜(xia):强化学习可能不太稳定以至于我们需要使用不同的随机种子重复运行多次以确定性能。
例如当我感觉完成了基本工作,我就会直接在环境上执行端到端的测试。但是即使我一直使用最简单的环境,我仍然遇到了非常大的问题。因此我重新回到 FloydHub 进行调整并运行了三个副本,事实证明我认为优秀的超参数只在三次测试中成功了一次。
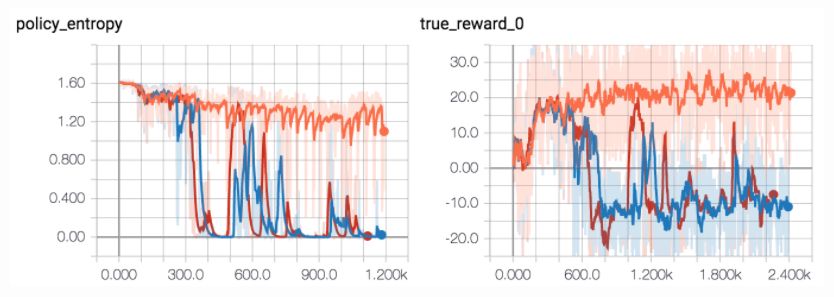
三个随机种子的两个出现失败(红/蓝)是很少见的。
为了让你确切感受到需要做的计算的量级:
使用 A3C 和 16 个工作站,Pong 需要 10 个小时来训练;
这是 160 个 CPU 小时;
训练 3 个随机种子,则是 480 个 CPU 小时。
至于计算开销:
对于 8 核机器,FloydHub 大约每小时花费 0.5 美元;
因此 10 小时需要花费 5 美元;
同时运行 3 个随机种子,则每次运行需要花费 15 美元。
从《Deep Reinforcement Learning Doesn't Work Yet》这篇文章中,我们知道,那些不稳定性是正常的、可接受的。实际上,即使「五个随机种子(常用的报告指标)也可能不足以得到显著的结果,因为通过仔细的选择,你可以得到非重叠的置信区间。」
因此在 OpenAI Scholars programme 中提供 25000 美元的 AWS 信贷实际上并不疯狂,这可能正是确保你的计算可靠的大致成本。
我要表达的意思是,如果你想要完成一个深度强化学习项目,确保你知道你正趟进的是什么浑水,确保你已经准备好付出多少时间成本和多少经济成本。
总之,复现一篇强化学习论文很有趣。但在这之后,回头看看你有哪些技能真正得到了提升。同时,我也很好奇复现一篇论文是不是对过去数月时间的最佳利用。
一方面,我确实感觉到了机器学习工程能力的提升。我在识别常见的强化学习实现错误上更有自信了;我的工作流程在整体上变得更好了;从这篇特定的论文中,我学到了关于分布式 TensorFlow 和非共时设计的很多东西。
另一方面,我并不认为我的机器学习研究能力有很大提高(这才是我当初的真正目的)。和实现不同,研究的更加困难的部分似乎总在有趣但易驾驭、具体的思想,以及你确实花费时间实现并认为得到最高回报的思想之后出现。挖掘有趣的思想似乎取决于(a)丰富的概念词汇;(b)对思想的良好品味。我认为阅读有影响力的论文、写总结,并对它们做严谨分析是兼顾两者的好办法。
因此,无论你想提高工程技能还是研究技能,深度考虑都是值得的。如果你在某方面比较欠缺,最好启动一个项目来针对性提高。
如果你想要提高两者,最好是先阅读论文,直到你找到真正感兴趣的东西,能用简洁的代码进行实现,并尝试对其进行扩展。
如果你希望处理一个强化学习项目,下面是一些更具体的注意内容。
选择需要复现的论文
分为几部分查找论文,并避免需要多个部分协同处理的论文。
强化学习
如果我们的强化学习是作为更大系统中的一个组件,请不要尝试自己实现强化学习算法。这是一个很大的挑战,并且我们也能学习到非常多的东西,但是强化学习目前仍然不够稳定,我们不能确定到底是大型系统存在问题还是作为系统一部分的强化学习存在问题。
在做任何事前,先要查看用基线模型在我们的环境上训练智能体有多么困难。
不要忘了归一化观察值,因为模型很多地方都要使用这些观察值。
一旦我们认为模型已经基本好了就直接完成一个端到端的测试,那么成功的训练要比我们预期的更加脆弱。
如果我们正在使用 OpenAI Gym 环境,注意在-vo 的环境中,当前动作有 25% 的时间会被忽略,并复制前面的动作以替代,这样会减少环境的确定性。如果我们不希望增加这种额外的随机性,那么就要使用-v4 环境。另外,默认环境只会从模拟器中每隔 4 帧抽取一次,以匹配早期的 DeepMind 论文。如果不希望这种采样,可以使用 NoFrameSkip 环境控制。结合上面的确定性与不跳过采样,我们可以使用 PongNoFrameskip-v4。
一般机器学习
由于端到端的测试需要很长时间才能完成,因此如果我们需要做一些重构会浪费大量时间。我们需要在第一次实现就检查错误并试运行,而不是在训练完后重新编写代码与结构。
初始化模型大概需要花 20s,且因为语法检测会浪费大量的时间。如果你不喜欢使用 IDE 或只能在服务器用 shell 访问与编辑,那么可以花点时间为编辑器配置 linter。或者每当我们尝试运行时遇到语法错误,可以花点时间令 linter 可以在在未来捕捉它。
不要仅仅使用 Dropout,我们还需要注意网络实现中的权重共享,批归一化同样也需要注意这一点。
在训练过程中看到内存占用有规律地上升?这可能是验证集过大。
如果使用 Adam 作为优化器发现一些奇怪的现象,那可能是因为 Adam 动量有问题。可以尝试使用 RMSprop 等不带动量的优化器,或设置 Adam 的超参数β1 为零。
TensorFlow
如果你想调试计算图中某个内部节点,可以使用 tf.Print,这个函数会打印该节点在每一次运行计算图时的输入。
如果你仅为推断过程保存检查点,则通过不保存优化器的参数而节省很多空间。
Session.run() 会出现很大的计算开销,如果可以的话将一个批量中的多个调用分组并运行计算图。
如果在相同机器上运行多个 TensorFlow 实例,那么就会得到 GPU 内存不足的报错。这可能是因为其中一个实例尝试保存所有的 GPU 内存,而不是因为模型过大的原因。这是 TF 的默认选项,而如果需要修改为只保存模型需要的内存,可以查看 allow_growth 选项。
如果你希望从一次运行的多个模块中访问计算图,那么应该可以从多个线程中访问相同的计算图,但目前锁定为只允许单线程一次读取。这看起来与 Python 全局解释器锁不同,TensorFlow 会假定在执行繁重任务前释放。
在使用 Python 过程中,我们不需要担心溢出问题,在 TensorFlow 中,我们还需要担心以下问题:
> a = np.array([255, 200]).astype(np.uint8)
> sess.run(tf.reduce_sum(a))
199如果 GPU 不可用,注意使用 allow_soft_placement 返回到 CPU。如果你编码的东西无法在 GPU 运行,那么可以移动到 CPU 中:
with tf.device("/device:GPU:0"):
a = tf.placeholder(tf.uint8, shape=(4))
b = a[..., -1]
sess = tf.Session(config=tf.ConfigProto(allow_soft_placement=True))
sess.run(tf.global_variables_initializer())
# Seems to work fine. But with allow_soft_placement=False
sess = tf.Session(config=tf.ConfigProto(allow_soft_placement=False))
sess.run(tf.global_variables_initializer())
# we get
# Cannot assign a device for operation 'strided_slice_5':
# Could not satisfy explicit device specification '/device:GPU:0'
# because no supported kernel for GPU devices is available.我们并不知道有多少运算不能在 GPU 上并行化运行,但为了安全起见,我们可以手动回退 CPU:
gpu_name = tf.test.gpu_device_name()
device = gpu_name if gpu_name else "/cpu:0"
with tf.device(device):
# graph code心理状态
讲真,不要对 TensorBoard 上瘾。不可预测的奖励是对 TensorBoard 上瘾的完美示例:大部分时间你检测运行的如何,这没什么,但在训练过程,有时检测中忽然就中了大奖。所以有时非常刺激。如果你开始感觉每分钟都想要检查 TensorBoard,那你就需要设定合理的检查时间了。
以下是强化学习的一些入门资源:
Andrej Karpathy 的《Deep Reinforcement Learning: Pong from Pixels》很好的介绍了强化学习的理论动机与直觉:http://karpathy.github.io/2016/05/31/rl/
更多有关强化学习的理论,查看 David Silver 的文献:http://www0.cs.ucl.ac.uk/staff/d.silver/web/Teaching.html。该资源对深度强化学习介绍不多,但却教授了理解论文时需要的词汇。
John Schulman 的《Nuts and Bolts of Deep RL Experimentation》课程中包含了很多实践时的注意点,链接:https://www.youtube.com/watch?v=8EcdaCk9KaQ。
想要了解深度强化学习的现状,可以查看以下文章:
Alex Irpan 写的《Deep Reinforcement Learning Doesn't Work Yet》,机器之心对此文做了中文编译《变革尚未成功:深度强化学习研究的短期悲观与长期乐观》。
Vlad Mnih 的视频《Deep RL Bootcamp Frontiers Lecture I: Recent Advances, Frontiers and Future of Deep RL》,链接:https://www.youtube.com/watch?v=bsuvM1jO-4w
Sergey Levine 的《Deep Robotic Learning》演讲,注重改建机器人泛化与采样的效率,链接:https://www.youtube.com/watch?v=eKaYnXQUb2g。
Pietel Abbeel 在 NIPS 2017 上的 Keynote,讲解了深度强化学习近期的技巧。链接:https://www.youtube.com/watch?v=TyOooJC_bLY。

IJCAI 2018 阿里妈妈国际广告算法大赛于 2018 年 2 月正式启动,获奖队伍将有机会前往斯德哥尔摩参加 IJCAI 2018。点击阅读原文参与报名。





