基于Objects as Points检测算法的小小尝试
点击上方“CVer”,选择加"星标"或“置顶”
重磅干货,第一时间送达

作者: xggiou
https://zhuanlan.zhihu.com/p/68383078
本文已授权,未经允许,不得二次转载
前言
最近anchor-free的目标检测势头很猛,尤其是两个centernet。一个以左上、右下及中心点确定目标,目标尺寸由左上右下两个角点确定;一个以中心点确定目标位置,附加目标尺寸预测。由于前者有corner pooling、center pooling、corner embedding等操作,后者仅仅是heatmap预测,所以感觉后者不拖泥带水,萌发了想试一发的念头。
工作快一年了,刚好前段时间离职在家,掏出了一部分积蓄(本就没攒多少钱,啊心痛)自己组装了一个DL入门环境(什么tesla、titan,根本不知道什么东西,不知道能不能吃,我只知道二手1080ti真香 )。
本次仅仅是简单尝试下算法的效果,并记录在此,供参考和交流学习。有什么不对的或者好的建议欢迎各大佬指出。
传送门:
https://github.com/xggIoU/centernet_tensorflow_wilderface_voc
如果感觉有帮助,请给个小小star(比心)。
正文
实验环境
这里不叨叨算法原理流程,有兴趣但没了解过的可以去看看论文。官方的开源实现是基于pytorch的,我是用tensorflow的,所以只能看懂个大概。以下是本次实验的环境:
1.anaconda3、pycharm-community、python3.6、numpy1.14
2.tensorflow1.12、slim
3.cuda9.0、cudnn7.3
4.opencv-python4.1数据集
本次尝试实验,实验了两种任务:单目标检测、多目标检测。
对于单目标检测,采用了wilderface人脸检测数据集,包含12876张训练集;
对于多目标检测,采用pascal voc2012目标检测数据集,包含17125张训练集,分20个类别。
实验部分参数
为了更快速的看到算法效果,我在训练过程中没有采用any data augmentation and any other tricks,初始学习率0.0001,采用指数衰减学习率,adam优化器。
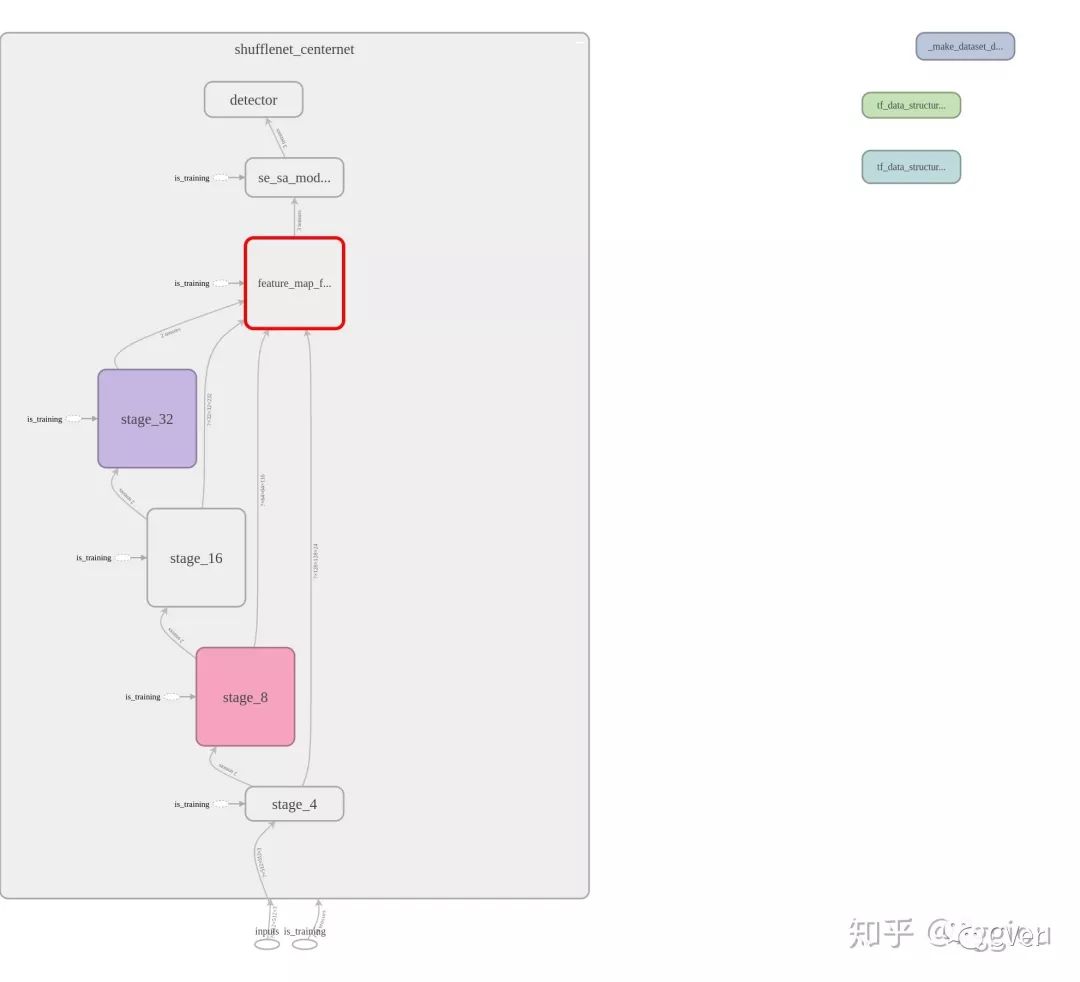
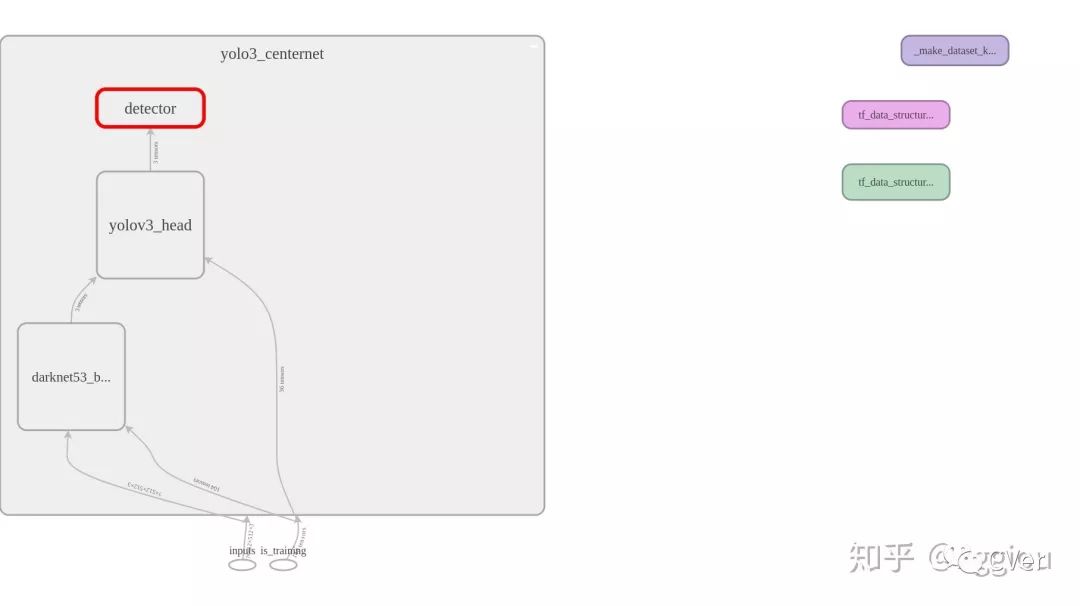
本次我的尝试实验,并没有基于原论文中的DLA、Hourglass等网络,仅仅简单的修改了下shufflenetv2_1.0x和yolov3,保留了他们的feature extraction部分,再接上centernet_detect_head,都没有采用dcn卷积,前者只是想试一下在轻量级网络中的效果。总体架构如下:
1.人脸检测:shufflenetv2_1.0x+centernet_detect_head downsample_ratio=4.0
2.多目标检测:yolov3+centernet_detect_head downsample_ratio=8.0实验结果
1.人脸检测
input_size:512x512
downsample_ratio:4.0
batch_size:14
global_steps:14800
epochs≈16
train_time≈3.7 hours1.1网络部分结构图
1.2可视化效果

2.多目标检测
input_size:512x512
downsample_ratio:4.0
batch_size:8
global_steps:70000
epochs≈32
train_time≈9.7 hours2.1网络部分结构图
2.2可视化效果

3.推理速度
测试了两个模型在100张图片下的推理速度,从读图开始到前向运行推理,再到解码还原到原图坐标结束。结果如下:
运行环境:
软件环境: python3.6
硬件环境: gpu:gtx1080ti*1,cpu:intel i7-8700k
model_name avg_time(ms) input_size model_size(.pb)
shufflenet-face 21.37 512x512 20.5MB
yolo3_centernet_voc 25.23 512x512 230MB4.结果分析
从我做的实验结果来看,效果还是不错的,但是由于没做data augmentation以及其他tricks,性能还是不够看的。对于单目标检测,其收敛速度还是比较快的;对于多目标检测,目标种类越多,收敛越慢,此时对feature extraction部分的网络要求就越高。
其中人脸检测存在的问题是,某些中心点位置预测并不是很准,有些漂移;而且还存在误识别。
多目标检测也存在中心点漂移的问题,而且还存在同一个目标多个中心点的情况,多出现在大目标上,此时需要nms(虽然官方说不需要,估计是我没训练好,毕竟人脸检测的在nms和no-nms下差别不大)。
二者在w、h上的预测都不是很准(中心点准不准也有很大关系),也许将w、h取对数或者采用foveabox算法中的wh预测方式可能更好,毕竟直接回归目标尺寸波动范围还是不小。
另外我尝试过将自己修改的轻量级的shufflenetv2_1.0x用于voc的检测,训练了很久,都没收敛,最后弃了。可能是batch_size太小,要么就是需要更强力的规模更大的网络。所以将yolov3作为backbone,效果明显改善了,虽然在其他测试图像上效果不是很好,但是训练至少收敛了。
综上所述,需要改进或者尝试做的是:
1.voc的测试效果不理想,需要采用data augmentation,或者加入正则化进行实验,增大batch size。
2.人脸的检测,采用data augmentation后我觉得能好不少。
3.采用更合理的网络架构,毕竟其中参杂了自己DIY改的部分。
4.按照官方pytorch的DLA、Hourglass实现来做(需要设备环境)。
5.加入dcn卷积,或许能解决中心点以及wh预测有些不准的情况。
6.采用一些骚操作看能否让中心点定位更准交流学习
最近的anchor-free的目标检测算法,大致有如下几种(另外还有ExtremeNet,FSAF,GA-RPN,没看就不贴了):
CenterNet:Objects as Points
CenterNet:Keypoint Triplets for Object Detection
FCOS:Fully Convolutional One-Stage Object Detection
FoveaBox:Beyond Anchor-based Object Detector
CSP:Center and Scale Prediction:A Box-free Approach for Object Detection
所有的方法其实都直接或者间接在利用中心点作检测,当Objects as Points的检测类别数为1时,其实这时就和CSP的行人检测大同小异了;Keypoint Triplets在cornernet的基础上引入center pooling,直接利用物体内部的信心;FCOS中的centerness预测分支,虽然采用中心点距离四边的距离(l,r,t,b)计算中心性,但是和heatmap差别不大,如果将这个分支融入到cls分支里,此时和Objects as Points也是基本一致的检测路数;foveabox由中心区域向外,按照一定的比列参数划分正负样本区域,间接也是利用中心信息(姑且这么说吧,不太好表达)。
此外,Keypoint Triplets方法的精度是目前而言最高的,主要是有效的利用了中心点的信息,让网络看到了物体内部信息。我觉得官方在Objects as Points的实现中,采用dcn,是否也是让网络学习偏移,使网络注意到物体内部信息,让中心点的定位更准。如果像我此次的实验中没有采用dcn,采用普通卷积,是否有其他方法让目标中心点看到整个目标的信息,好让中心点定位更准(因为很多中心点不在目标内部),比如像center pooling类似的法子。
附:shufflenetv2 yolov3
https://github.com/xggIoU/centernet_tensorflow_wilderface_voc
以上是个人的理解和实验,还望批评指正,感谢浏览。
CVer-目标检测交流群
扫码添加CVer助手,可申请加入CVer-目标检测交流群。一定要备注:研究方向+地点+学校/公司+昵称(如目标检测+上海+上交+卡卡)

▲长按加群
这么硬的实战分享,麻烦给我一个在在看

▲长按关注我们
麻烦给我一个在看!



