【ACL】文本摘要研究工作总结
转自 专知
【导读】ACL2019于7月27日到8月2日于意大利佛罗伦萨举行,本文整理了会议收录的若干篇关于文本摘要的文章,其中包括新数据、多模态文本摘要、抽取式摘要、概括式摘要等。
新的数据集
BIGPATENT: A Large-Scale Dataset for Abstractive and Coherent Summarization
http://arxiv.org/abs/1906.03741
作者介绍了一个新的数据集,包括130万份美国专利文献记录以及人类书面抽象摘要。
特点:
摘要包含更丰富的话语结构和更多的常用实体;
更长的输入序列(CNN / DM的平均3,572.8 VS 789.9个字);
关键内容在输入中均匀分布,而在流行的基于新闻的数据集中,它通常集中在前几句中;
摘要中存在更少和更短的提取片段。
作者报告了CNN / DM,NYT和BIGPATENT的各种提取和抽象模型的结果。结果的分歧很有趣:PointGen与基于新闻的数据集上的提取无监督模型Text-Rank相比有利,同时在和BIGPATENT上获得更差的结果。这再次表明了在几个不同的数据集上测试模型的重要性。
Multi-News: a Large-Scale Multi-Document Summarization Dataset and Abstractive Hierarchical Model
http://arxiv.org/abs/1906.01749
作者提出了第一个新闻多文档摘要数据集。它包含来自1500多个不同网站的输入文章以及从网站newser.com获得的56,216篇这些文章的专业摘要。此外,作者提出了一种端到端模型,该模型在各种多文档数据集(包括Multi-News)的自动和人工评估下实现了较好的结果。
多模态摘要
Talk-Summ: A Dataset and Scalable Annotation Method for Scientific Paper Summarization Based on Conference Talks
http://arxiv.org/abs/1906.01351
本文收集了1716对论文/视频,并将口头报告的视频视为相关论文的摘要。它的训练数据的生成方法是完全自动的。它的训练数据可以随着文章的发表源源不断的增加。
Multimodal Abstractive Summarization for How2 Videos
http://arxiv.org/abs/1906.07901
作者探讨了How2数据集上几个视频摘要模型的行为。他们提出了一种多模式方法,使用自动转换,音频和视频潜在表示,并使用层次Attention进行组合。对于评估,除了ROUGE之外,作者提出了一个不考虑停用词的变体。有趣的是,所提出的模型包括仅视频摘要模型,该模型与纯文本模型竞争性地执行。
抽取模型
Improving the Similarity Measure of Determinantal Point Processes for Extractive Multi-Document Summarization
http://arxiv.org/abs/1906.00072
作者建议使用行列式点过程(DPP),可学习的抽取方法和胶囊网络组件来处理多文档摘要。动机:TF-IDF向量在建模语义相似性方面不尽如人意,这一事实对于多文档摘要尤其成问题。解决方案:对句子对的相似性度量,使得语义上相似的句子可以获得高分,尽管具有非常少的单词。在来自CNN / DM的数据集上,在二进制分类设置下训练胶囊网络:作者将抽象句子映射到最相似的文章句子和负采样。
Self-Supervised Learning for Contextualized Extractive Summarization
http://arxiv.org/abs/1906.04466
一种以自监督的方式训练抽取模型的方法。它允许更快地训练并获得CNN / DM的轻微改进。所提出的方法还可以以自监督的方式导致更长的文本表示。
Answering while Summarizing: Multi-task Learning for Multi-hop QA with Evidence Extraction
http://arxiv.org/abs/1905.08511
该研究主要关注HotpotQA,这是一个多跳QA可解释的任务:系统通过推理和收集参考文本收集的不相交的部分来回答证据句子。查询聚焦提取器(QFE)的灵感来自Chen等人提出的提取摘要模型。该方法不是用提取摘要覆盖源文档中的重要信息,而是用提取的证据来解决问题。该模型与HotpotQA干扰器设置中基于SOTA BERT的模型相比有利,可以在不受益于任何预训练的情况下检索证据。此外,它还在FEVER数据集上实现了SOTA性能。
Sentence Centrality Revisited for Unsupervised Summarization
http://arxiv.org/abs/1906.03508
作者使用基于图的排序方法重新审视了经典的提取无监督摘要,其中节点是文档的句子。他们利用BERT对每个句子进行编码。其中一个动机是受欢迎的监督方法受到大规模数据集需求的限制,因此不能很好地概括为其他领域和语言。该模型与流行的CNN / DM和NYT数据集上的SOTA方法以及TTNews(一种中国新闻摘要语料库,表现出适应不同领域的能力)的表现相当。根据对黄金摘要提出的一组问题进行人工评估,评估生成的评估摘要中存在多少相关信息。在多文档摘要中对句子选择的应用被建议作为未来的工作。
HIBERT: Document Level Pre-training of Hierarchical Bidirectional Transformers for Document Summarization
http://arxiv.org/abs/1905.06566
HIBERT代表Hierarchical BERT。作者的想法是使用两个预训练Transformer:第一个是用于表示句子的标记级别的标准BERT; 第二,在句子层面,并利用前者的表示来编码整个文件的句子。在BERT预训练方法之后,作者训练了句子级TTransformer文档的一些句子,并且最终模型在CNN / DM和NY时间数据集上实现SOTA以进行汇总。作者还报告了信息消融,使用域外,域内数据及其组合进行预训练。在蛋糕上,它们将BERT调整为提取监督摘要(即在分类设置中微调BERT以选择要提取的句子)并将结果报告为基线。
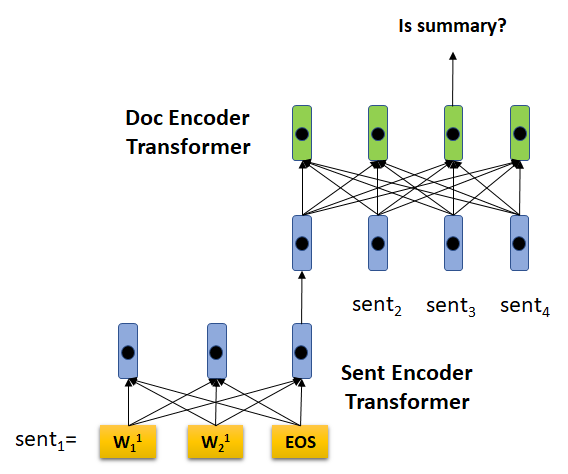
STRASS: A Light and Effective Method for Extractive Summarization Based on Sentence Embeddings
https://aclweb.org/anthology/papers/P/P19/P19-2034/
作者利用句子嵌入空间中的语义信息以计算有效的方式提取摘要。他们还引入了一个新的数据集CASS,它是根据法国最高上诉法院的判决和相应的摘要建立的。
概括式摘要
Scoring Sentence Singletons and Pairs for Abstractive Summarization
http://arxiv.org/abs/1906.00077
抽象概括者倾向于通过学习以端到端方式生成文本来隐式地进行内容选择和融合。 动机是将摘要过程分成两个步骤,可以为每个组件提供更大的灵活性和可解释性。提取阶段使用BERT表示完成,然后将提取的单个单例输入到序列模型中以生成摘要。
Hierarchical Transformers for Multi-Document Summarization
http://arxiv.org/abs/1905.13164
在最初的WikiSum论文中,作者提出了两个阶段的过程,首先从所有文档中提取最重要的句子以获得更短的输入,然后学习使用Transformer器模型生成输出。最重要的是,作者建议使用注意力来改进提取步骤,使用层次表示文档而不是仅仅连接提取的句子。
BiSET: Bi-directional Selective Encoding with Template for Abstractive Summarization
http://arxiv.org/abs/1906.05012
使用模板的双向选择性编码(Biset)是在Gigawords数据集上测试的抽象摘要的新架构。基于模板的摘要依赖于手动创建模板。这种方法的优点在于它可以在不需要训练数据的情况下产生简洁和连贯的摘要。但是,它需要专家来构建这些模板。本文提出了一种从训练语料库中检索高质量模板的自动方法。给定输入文章,模型首先使用基于TF-IDF的方法检索最相似的文章。此外,通过神经网络计算相似性度量,以便对检索到的文章进行重新排序。然后选择对应于与输入最相似的文章的摘要作为模板。最后,训练序列网络的序列以生成摘要:作者提出了一种架构来学习源摘要和所选模板之间的交互。
Generating Summaries with Topic Templates and Structured Convolutional Decoders
http://arxiv.org/abs/1906.04687
大多数先前关于神经文本生成的工作将目标摘要表示为单个长序列。假设文档被组织成局部连贯的文本段,作者提出了一种层次模型,它对由目标摘要的主题结构引导的文档和句子进行编码。摘要中的主题模板通过经过训练的Latent Dirichlet分配模型获得。WikiCat-Sum,用于评估的数据集源自WikiSum,主要关注三个领域:公司,电影和动物。
Global Optimization under Length Constraint for Neural Text Summarization
https://www.aclweb.org/anthology/P19-1099
大多数抽象摘要模型不控制生成的摘要的长度,并从训练期间看到的示例的分布中学习它。作者提出了一种长度约束下的优化方法。他们报告了使用具有不同长度约束和优化方法的几种模型对CNN / DM进行的大量实验。除了ROUGE和长度控制之外,作者还报告了平均生成时间以及人工评估。
评估指标
HighRES: Highlight-based Reference-less Evaluation of Summarization
http://arxiv.org/abs/1906.01361
自动摘要评估是一个开放的研究问题,目前的方法存在一些缺陷。出于这个原因,大多数论文进行人工评估,这是一项具有挑战性和耗时的任务。作者提出了一种新的人类评估方法:首先,一组注释器突出了输入文章中的重要内容。然后,要求其他注释者对精确度进行评分(即,只有重要信息存在于摘要中),回忆(所有重要信息都存在于摘要中)和语言指标(清晰度和流畅性)。这种方法的主要优点:
重点不依赖于被评估的摘要,而只取决于源文档,从而避免了参考偏差;
它提供绝对而不是排名评估,以便更好地解释;
高亮注释只需要在每个文档中发生一次,并且可以重复使用它来评估许多系统摘要。
最后,作者提出了一个利用高亮注释的ROUGE版本。用户界面(见下图)是开源的。
https://github.com/sheffieldnlp/highres

A Simple Theoretical Model of Importance for Summarization
https://www.aclweb.org/anthology/P19-1101
在这项工作中,作者在统一的重要性概念下,形式化了几个简单而严谨的与摘要相关的指标,如冗余,相关性和信息性。该文件包括几项支持该提案的分析,并被认为是一项杰出贡献。我们期待看到拟议框架将如何通过!
Github链接:
https://github.com/recitalAI/summarizing_summarization/blob/master/README.md
-END-
专 · 知
专知,专业可信的人工智能知识分发,让认知协作更快更好!欢迎登录www.zhuanzhi.ai,注册登录专知,获取更多AI知识资料!

欢迎微信扫一扫加入专知人工智能知识星球群,获取最新AI专业干货知识教程视频资料和与专家交流咨询!

请加专知小助手微信(扫一扫如下二维码添加),加入专知人工智能主题群,咨询技术商务合作~

专知《深度学习:算法到实战》课程全部完成!560+位同学在学习,现在报名,限时优惠!网易云课堂人工智能畅销榜首位!

点击“阅读原文”,了解报名专知《深度学习:算法到实战》课程


