【AI VS 人类新高峰】冷扑大师发明人:用于策略推理的超人AI

中国人工智能资讯智库社交主平台新智元主办的 AI WORLD 2017 世界人工智能大会11月8日在北京国家会议中心举行,大会以“AI 新万象,中国智能+”为主题,上百位AI领袖作了覆盖技术、学术和产业最前沿的报告和讨论,2000多名业内人士参会。新智元创始人兼CEO杨静在会上发布全球首个AI专家互动资讯平台“新智元V享圈”。
全程回顾新智元AI World 2017世界人工智能大会盛况:
新华网图文回顾:http://www.xinhuanet.com/money/jrzb20171108/index.htm
爱奇艺(上):http://www.iqiyi.com/v_19rrdp002w.html
爱奇艺(下):http://www.iqiyi.com/v_19rrdozo4c.html
阿里云云栖社区: https://yq.aliyun.com/webinar/play/316?spm=5176.8067841.wnnow.14.ZrBcrm
新智元 · AI WORLD 2017
演讲嘉宾: Tuomas Sandholm
【新智元导读】 “冷扑大师”libratus发明人之一的Tuomas Sandholm在新智元AI WORLD207世界人工智能大会上进行分享。他介绍了libratus是如何工作的,包括三大部分:抽象算法(纳什均衡的近似值),次游戏的解决者,自我改进的算法。
新智元 AI World2017世界人工智能大会开场视频

Tuomas Sandholm:大家好,非常感谢新智元给我机会。今天我想跟大家分享不完全信息博弈,这跟西洋跳棋、围棋、象棋等其他完全信息博弈是不一样的。不完全信息博弈更像是谈判、扑克,适用于解决现实问题,因为现实生活中很多都是不完全信息。

接下来,我想给大家介绍一下 AI 如何进入到扑克游戏当中去,以及我们怎么样才能够应对在这些游戏中的超级复杂性。



让我来举例说明。
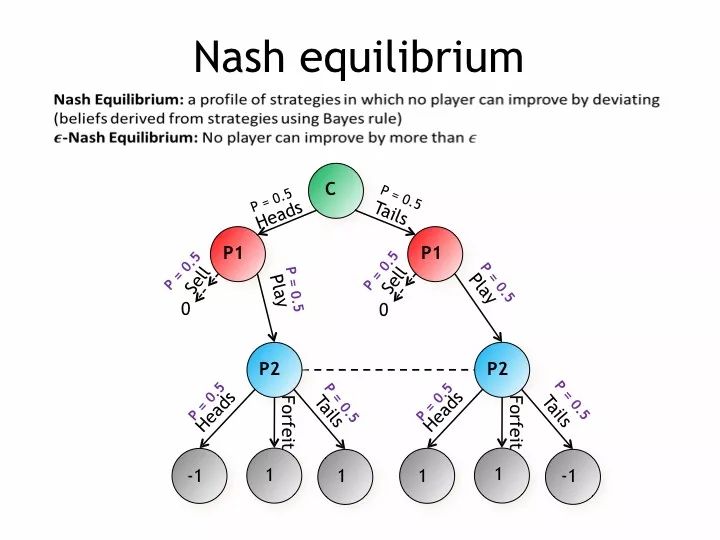
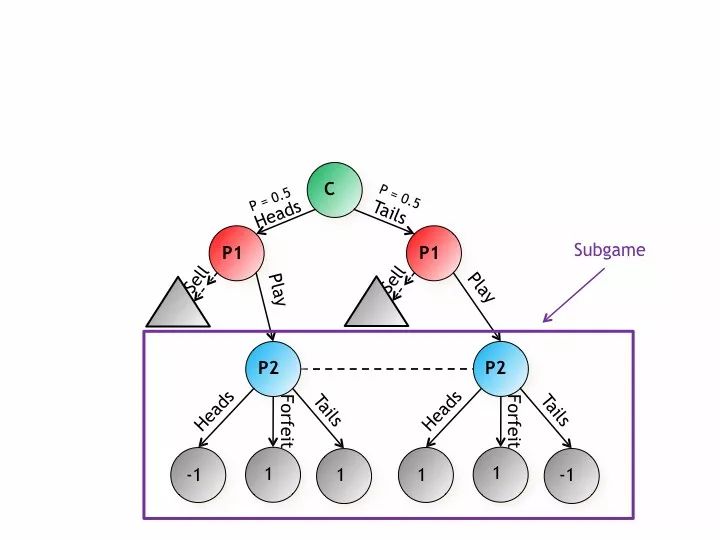
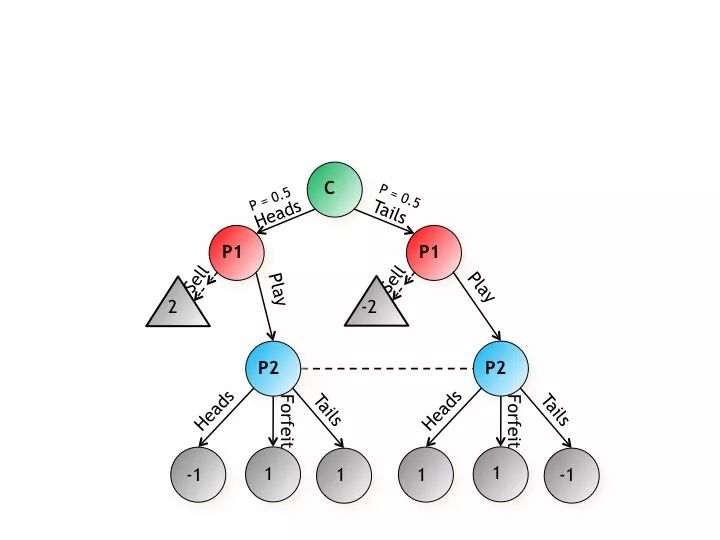
例1:我们不仅仅只为扑克游戏开发技术,也针对一般的游戏。我们来看一下这是扔硬币的游戏,扔硬币有一半的概率是正面,有一半的概率是反面,我们有两个玩家,一个是1号玩家,一个是2号玩家,如果P2猜对的话,P2就会得一分,P1就会减少一分,如果P2猜错的话P1就能得一分,我想说大多数的时候,大家都在不完全游戏博弈中见到过这样的一些游戏树形结构分析。
我们看一下这是信息集的相关信息,也就是说我们玩家到底应该怎么玩,各种不同的玩法。红色的玩家有两个信息集,基于这点他可以决定到底该怎么玩。第二个玩家不知道硬币是正面还是反面,二号玩家只有一个信息集,他每次玩的方法都是一样的,它的可能性也是一样的。
这里,主要的挑战首先是不确定别人会做什么以及相应的机会,也就是未知状态。而且,由于未知状态,我们不得不考虑我们的行为如何向对手传达我们的私人信息。相反,对手的行为如何向我们反映他们的私人信息。
而这正是博弈论中纳什均衡概念出现的地方。约翰·纳什在1950年发明了这个概念,它改变了经济学和许多其他科学。 1994年,他获得了诺贝尔奖。但是,当然,这只是有多个玩家时,并且均为理性玩家前提下的定义。它实际上没有做任何事情。所以为了实现这一点,你必须结合算法来根据纳什均衡实际来计算策略。


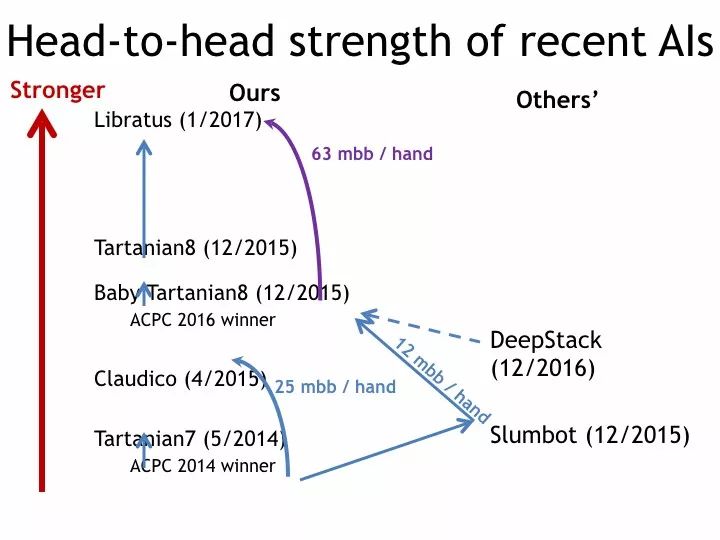
现在,这些独立于的技术成为扑克AI的基准。如果你回到约翰·纳什1950年的博士论文,你会发现,纳什均衡唯一的应用理论就是扑克。从那以后,扑克 AI 有了很多进展。大约 13 年前,这个领域真的有了很大发展。于2006年开始,每年举办年度计算机扑克挑战赛,世界各地不同的研究小组可以比较他们的结果,并逐年增加难度。这导致了核心技术推理方面的多个数量级的稳定改进。并且,有限下注的德州扑克问题在2015年已经得到解决。


因此,无限注德州扑克已成为人工智能不完全信息博弈的主要标杆和挑战问题。这是一个非常大的游戏。它有10的161次方个不同的情况,让我们停下来考虑一下这个数字。它不仅仅是宇宙中所有原子数量。而且,如果宇宙中的每个原子都有一个完整的另一个宇宙,并且计算这些子原子的数量,那么它也不止于此。你需要AI技术来解决它们。而之前没有人工智能能够击败顶级人类玩家。所以如果想想 AI 中的游戏,那么有很多很棒的子集,比如奥赛罗,跳棋,国际象棋和棋子。但是,无限德州扑克仍然是看不到,这是一场艰苦的比赛。因为它非常大,而且是一个不完全信息博弈。

所以,今年1月,我组织了AI复赛的春季版本。我之所以称之为复赛,是因为我在2015年的4月和5月组织了一场类似的比赛。当时我们无法在这场比赛中击败最好的玩家。我邀请了前十名中的4名无限德州扑克专家的专业人士到匹兹堡参加比赛。我们在20天内玩了12万手牌。

它和人类的游戏玩法非常不同,因为它不是从学习人类数据开始的。从刚刚输掉比赛开始,它就使用优化和AI来形成自己的策略。它和人类玩的很不一样。最终的结果是,我们的AI libratus在这场比赛中大大地击败了顶级人类大师。赢率达到99.98%的这是有统计学意义的。而且每个人都输给了冷扑大师。

之后,我们在中国的海口做了一个类似的比赛,我们打了3万6000手牌,对手是一个由六名中国扑克职业选手组成的队伍。奖金是200万人民币。对手做好了准备。所以他们不仅是扑克玩家,还是计算机科学家,机器学习专家。 他们中的一个是唯一的中国世界扑克锦标赛系列赛冠军。为了突破AI,他们事先研究了libratus的手牌历史。我们9场比赛中打了四天半。他们的策略是行不通的。冷扑大师,意思是“冷酷的扑克大师”,是libratus的中国版。它赢得了9场比赛的每一场胜利,同时也击败了每一个人。



他们有三个主要模块。这些是主要的部分:一个是事件发生之前,我们将游戏的规则提供给抽象算法。它运行游戏的抽象,所以它是纳什均衡的近似值。然后有一个次游戏的解决者实时完善这些策略,然后在后台运行一个自我改进的算法。

在比赛之前,我们运行了一台超级计算机。在使用libratus那一次,我们在匹兹堡超级计算中心的超级计算机上运行了大约1500万个小时。那么显然这个游戏太大了,不能直接解决,所以我们运行了一个抽象算法来创建一个更小的抽象游戏。然后,我们使用经典均衡寻找算法来寻找博弈的近似均衡。

Libratus有一个计算近似纳什均衡策略的算法(这也是一个近似的最小最大策略)到抽象的游戏。它为AI的战略提供了一个高层次的蓝图。新算法是Monte Carlo对策略最小化算法的改进版本。主要的新方面包括以降低概率的方式抽取智能体的行为。这大大提高了算法的速度,从而使得更细粒度的抽象得到解决。

最先进的游戏抽象是不完美的 。正因为如此,游戏模型有多条路径到相同的抽象状态。这会导致不同的途径在这个智能体应该做的事情上“斗争”,这就提高了解决方案的质量。新的均衡发现算法也可以通过折扣一些路径来减少抽象状态的入度,从而减轻这个问题。
2.解决子游戏


Libratus有一个新的子游戏解决算法,重复计算一个更详细的策略,以上述蓝图策略为指导。这个算法的新方面包括以下内容。
到目前为止,考虑到对手的错误,安全的子游戏解决。子博弈求解器可以通过错误给予对手我们迄今在游戏中给予我们的数量,同时仍然是完全安全的(即不逊于预先计算的纳什均衡近似蓝图)。

我们使用这个观察来扩展子博弈求解器可以安全地优化的策略空间,从而使其能够比以前的子博弈求解器更好地发挥与对手可能持有的其他(非错误)双手相比更好的灵活性。
通常情况下,子博弈解决不完美信息游戏只进行一次子博弈时。相比之下,Libratus在每个对手在子游戏中移动之后解决每个剩下的子游戏。这样可以实现更细粒度的抽象,也可以避免反向映射对手的抽象外动作和抽象抽象动作的缺点,因为对手的确切动作被添加到剩下的子游戏中。
子游戏的解决在游戏的早期阶段开始(在任何足够大的下注周期,但不迟于第三轮下注开始时)。在子游戏解决中没有抽象卡。
在子游戏解决之前,噪音被添加到动作抽象中。这使得Libratus难以发挥,因为它在每一手牌后都改变了赌注大小。
3.自我改进
Libratus有一个自我完善的模块,它随着时间的推移增加了预先计算的蓝图,以便基于对手已经能够识别哪些漏洞(抽象操作,即扑克中的下注大小),甚至更接近纳什均衡。这与以前在游戏中学习的方法形成了鲜明的对比,在游戏中,目标通常是建模和开发。相比之下,Libratus的自我改进是普遍的。

对于冷扑大师的比赛观察。我们决定对于这些顶级的玩家,我们不想让自己有太多的漏洞给对方,所以我们这里没有对手的漏洞分析,这是我们的弱点。

现在我给大家介绍一下我们将会在其他方面要开展的研究。第一方面是有损耗的边界提取,所以我们要对于现实进行一定的抽象提取,否则的话就会有问题,我们需要有更多的关于损耗提取的一些计算,否则这种游戏就不能够很好地继承下去。同样这也被用在不同的模型方面,我们发现现在有很多的模型对于现实来讲并不是非常的优化,所以我们也是希望能够找到更加优化的模型。另外我们要找到新的基于梯度的平衡的计算,在今年夏天我们已经出台了一个相关的方法,现在速度已经非常的快了。
另外一点,对于均衡计算我们要进行进一步的优化,在深度学习来讲有第三个维度,也就是说对于探索来讲开放程度会有多大,我自己也要进行充分的开放,进行进一步的探索。但是我们在进行探索之前是需要进行充分的准备,现在我们对于这种技术已经进行很多不同的应用了,我们现在也要运用这些新的技术,要有这种方面的应用能力,在这种信息不全的游戏之下,我们需要有更多的人机互动,我们在玩的时候,不仅仅只是需要一个玩家,所以在我们来应用新技术的时候,我们有几点是需要进一步的改良,我们要进行更好的人机互动,在这里我们需要提前考虑到游戏的一些玩法。


另外还有像融资、战略性的一些定价,以及战略性的产品组合的优化等等,还有像金融方面,比如说战略性的一些资产组合的构建,另外还有自动化的磋商,以及磋商的支持等,另外还有一些企业的战略,我们在企业的战略当中应该有我们的一些玩法。
另外在进行拍卖的时候,也可以采用相关的技术,这一点也是非常的有益。像电影相关的内容,在虚拟性安全等等,以及在政治方面进行竞选,在自动化驾驶的汽车或者是舰队,或者半自动化的舰队等等,我们可以跟人机之间建立起一些互动,但是我们应该建立一些相关的规则,就是在人机互动的时候,另外在军事方面的安全等等,在生物应用等等,比如在医疗、治疗、规划的时候,我们在预防一些疾病或者是感染以及像癌症等等,所有的这些领域我们都可以采用新的技术,另外在培训以及在娱乐行业也可以有更多的相关技术的应用。
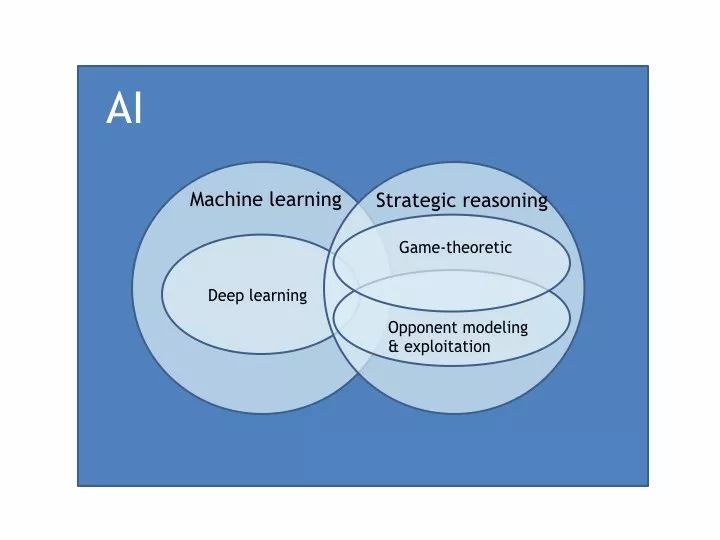
我想说机器学习只是人工智能的一部分,人工智能可以在其他领域可以进一步应用,比如在战略推理也可以有更多的人工智能相关的应用。我们认为对于战略性的推理来讲,实际上我们更多的不仅仅是关注于过去,而是更多地关注于未来。从过去进行学习,这是我们进行战略性推理的一部分,比如说在我们进行人机交互的时候,应该对我们的对手进行更多的分析,来进行进一步的推理等等。谢谢大家。



