【荐读】VAE和Adam发明人博士论文:变分推理和深度学习(下载)
2017 年 11 月 8 日,在北京国家会议中心举办的 AI WORLD 2017 世界人工智能大会开放售票!早鸟票 5 折 抢票倒计时 6 天开抢。还记得去年一票难求的AI WORLD 2016盛况吗?今年,我们邀请了冷扑大师”之父 Tuomas 亲临现场,且谷歌、微软、亚马逊、BAT、讯飞、京东和华为等企业重量级嘉宾均已确认出席。
AI WORLD 2017 世界人工智能大会“AI 奥斯卡”AI Top 10 年度人物、 AI Top10 巨星企业、AI Top10 新星企业、AI Top 10 创投机构、AI 创新产品五个奖项全部开放投票。谁能问鼎?你来决定。
关于大会,请关注新智元微信公众号或访问活动行页面:http://www.huodongxing.com/event/2405852054900?td=4231978320026了解更多
1新智元编译
作者:Diederik P. Kingma
编译:佩琦,Neko,熊笑
【新智元导读】VAE(变分自编码器) 和 ADAM 优化算法是深度学习使用率极高的方法。二者的发明者之一、OpenAI 的研究科学家 Durk Kingma 日前公布了自己的博士论文《变分推理和深度学习:一种新的综合方法》,新智元第一时间为您介绍。
论文下载:https://pan.baidu.com/s/1eSPDGv4


近年,随着有监督学习的低枝果实被采摘的所剩无几,无监督学习成为了研究热点。VAE(Variational Auto-Encoder,变分自编码器)和 GAN(Generative Adversarial Networks) 等模型,受到越来越多的关注。
大多数生成模型有一个基础的设置,只是在细节上有所不同。GAN 和 VAE 都是生成模型的常用方法:
Generative Adversarial Network(GAN)将训练过程作为两个不同网络的对抗:一个生成器网络和一个判别器网络,判别器网络试图区分样来自于真实分布 p(x) 和模型分布 p^(x) 的样本。每当判别器发现两个分布之间有差异时,生成器网络便微整参数,使判别器不能从中找到差异。
Variational Autoencoders(VAE)让我们可以在概率图模型框架下形式化这个问题,我们会最大化数据的对数似然(log likelihood)的下界。
OpenAI 的研究科学家 Durk Kingma 正是 VAE 的发明者之一,他同时也是业界使用率极高的优化算法 ADAM 的发明者之一。另外,他颜值也很高。
就在上月底,他公开了他的博士论文《变分推理和深度学习:一种新的综合方法》。让我们为您介绍其博士论文的内容。
在论文《变分推理与深度学习:一种新的综合方法》,我们针对变分(贝叶斯)推理、生成建模、表示学习、半监督学习和随机优化等问题,提出了新的解决方法。
我们提出一种高效的变分推理算法 [Kingma and Welling, 2013] (chapter 2),适用于大模型求解高维推理问题。该方法使用模型关于潜在变量和/或参数的一阶梯度;使用反向传播算法可以有效计算这种梯度。这使得该方法特别适合于使用深度神经网络进行推理和学习。
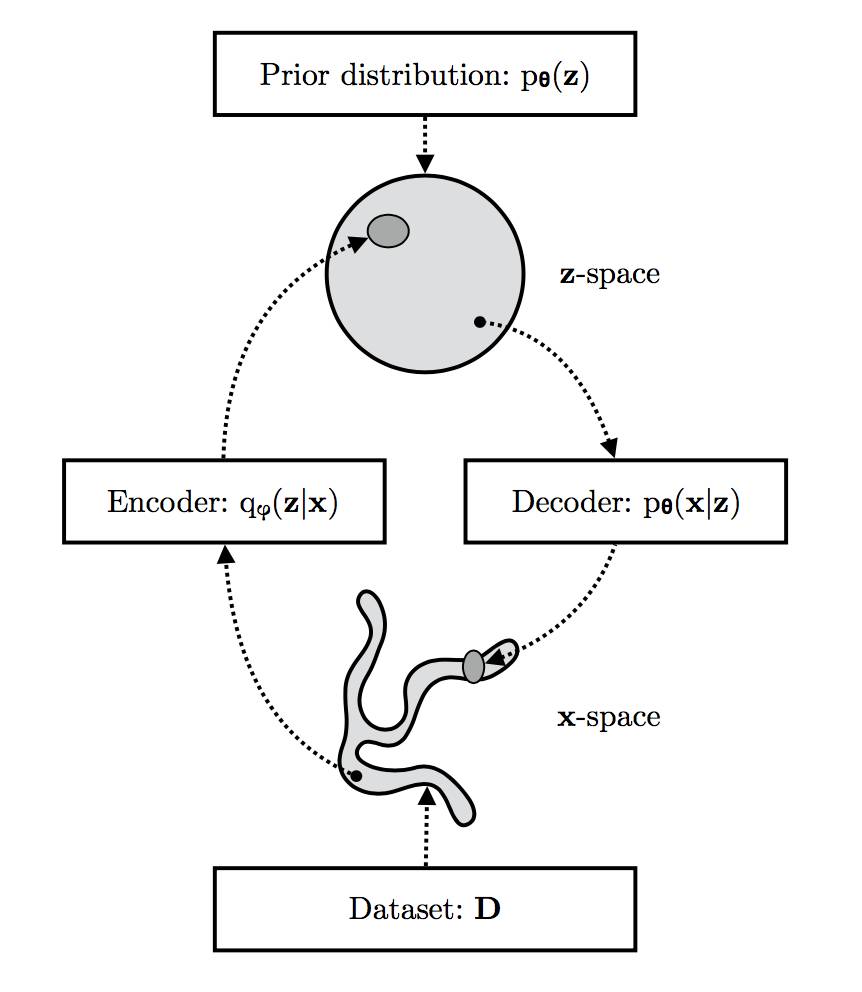
VAE在可观测的x空间(其实证分布qD(x)通常较复杂)和潜在的z空间(其分布相对简单,如图中所示球形)之间学习到的随机映射。
我们提出变分自编码器(VAE)[Kingma and Welling, 2013] (chapter 2)。VAE框架将一个基于神经网络的推理模型和一个基于神经网络的生成模型结合起来,并提供一种简单的方法来联合优化两个网络,以限制给定数据的参数的对数相似度。双重随机梯度下降过程允许多占到非常大的数据集。我们展示了使用变分自编码器进行生成建模(generative modeling)和表示学习(representation learning)。
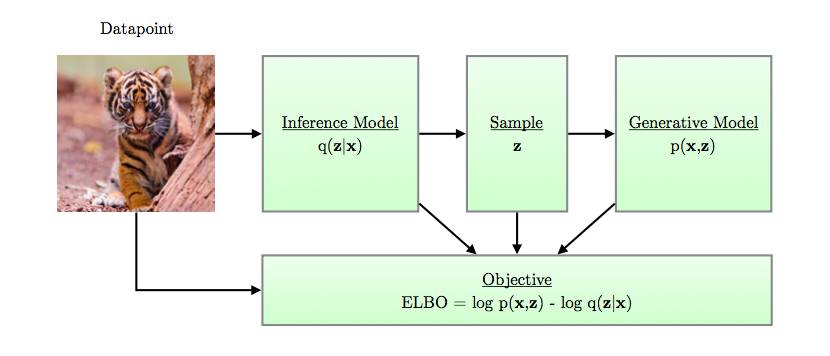
一副关于变分自编码计算流程的简单示意图
我们展示了如何使用VAE框架来解决半监督学习问题[Kingma et al., 2014](chapter 3),截至本论文发表时,我们在标准半监督图像分类基准上得到了state-of-the-art的结果。
我们提出逆自回归流(inverse autoregressive flows)[Kingma et al., 2016] (chapter 5),这是基于normalizing flows的一类灵活的后验分布,允许在高维隐藏空间上推断高度非高斯后验分布。我们演示了如何使用该方法来学习VAE,其对数似然性能与自回归模型相当,同时允许更快速的合成。
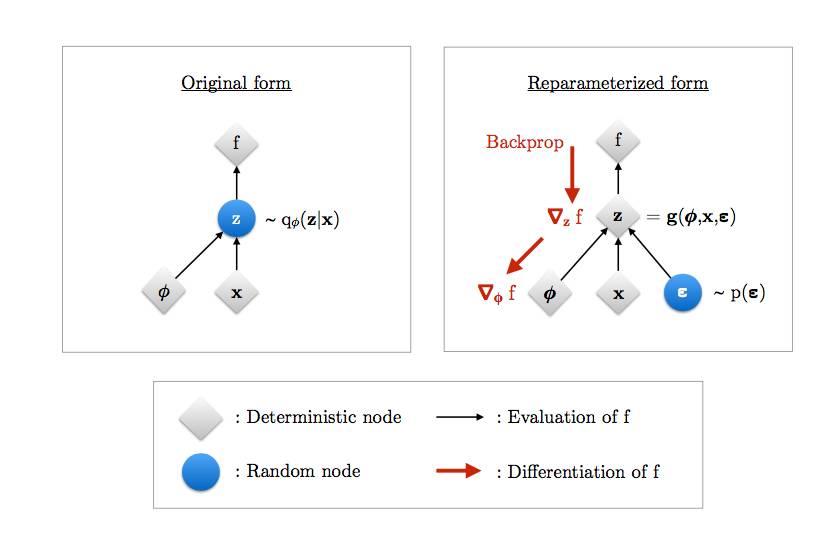
再参数化说明
我们提出局部再参数化(local reparameterization)方法(chapter 6),以进一步提高高斯后验模型参数的变分推理效率[Kingma et al., 2015]。这种方法提供了一种额外的(贝叶斯)dropout 视图,即一种流行的正则化方法; 使用这种联系,我们提出 variational dropout,这使我们能够学习dropout率。
我们提出 Adam [Kingma and Ba, 2015) (chapter 7),这是一种基于自适应时刻的随机梯度优化方法。
Kingma 在论文的开头,提出了一些研究问题,并围绕这些问题组织了全文的结构:
研究问题1:在有大数据集的情况下,我们如何在深度潜在变量模型(deep latent-variable)中执行有效的近似后验和最大似然估计?
在第 2 章和[Kingma and Welling, 2013]中,我们提出了一种基于重构参数的变分推理的有效算法,适用于解决大型模型的高维推理问题。 该方法使用模型w.r.t.的一阶梯度。 潜在变量和/或参数; 这种梯度使用反向传播算法进行计算是有效的。这使得该方法非常适用于深度潜在变量模型中的推理和学习。
变分自动编码器(VAE)框架将基于神经网络的推理模型与基于神经网络的生成模型相结合,提供了一种简单的两种网络联合优化方法,即对参数对数似然度的约束给出数据。 这种双随机梯度下降过程允许扩展到非常大的数据集。 我们展示了使用变分自动编码器进行生成建模和表征学习。
研究问题2:我们能使用VAE模型来改进最先进的半监督分类结果吗?
在第 3 章和[Kingma et al., 2014]中,我们展示了如何使用VAE来解决半监督学习的问题,出版时,获得了标准半监督图像分类基准的最先进成果。
规范化流动框架[Rezende 和 Mohamed,2015]提供了一个有吸引力的方法来参数化VAE框架中的灵活近似分布,但不能很好地扩展到高维潜在空间。 这导致我们遇到以下问题:
研究问题3:是否存在一个实用的规范化流动框架,能够很好地拓展到高维潜在空间?
在第5章和[Kingma etal.,2016]中,我们提出了逆自回归流,一种基于规范化流动的灵活后验分布,从而在高维潜在空间中提供高度非高斯后验分布的推论。我们演示了该方法如何用于学习VAE,其对数似然性能与自动注册模型相当,同时允许高数量级的合成。
如第2章所述,基于参数化的推理方法可用于推断神经网络参数的近似后验分布。然而,其实施是相对低效的。
研究问题4:我们能在不牺牲平行度的情况下,通过构建梯度估计器来改进基于再参数化的梯度估计器(该方差的变化与小尺寸成反比)吗?
在第6章和[Kingma etal., 2015年]中,我们提出了一个局部再参数化技巧来进一步提高高斯后验模型参数的变分推理效率,这导致了一个梯度估计器,其方差收缩与小型化成比例尺寸。这种方法还提供了一种额外的(贝叶斯)dropout 视角,一种流行的规则化方法; 利用这种连接,我们提出了变量 dropout,这使我们能够了解 dropout率。
几乎所有的神经网络实验都需要随机梯度优化; 这些优化器的改进值得研究,因为它们可以转化为所有这些结果的改进。这引出了我们的最终研究问题:
研究问题5:我们可以改进现有的随机梯度优化方法吗?
在第7章和[Kingma and Ba, 2015]中,我们提出了 Adam,一种基于自适应时刻的随机梯度优化的可扩展方法。该方法实现简单,计算开销低。我们展示潜力巨大的理论和实证结果。
在论文中,Kingma 试图对这些问题进行了回答,他再次总结了自己论文的主要贡献:
贝叶斯概率模型(directed probabilistic models)形成了现代人工智能的一个重要方面。通过使用可微分的深度神经网络参数化条件分布,这些模型可以非常灵活。

ELBO 概率优化算法
在fully-observed case 里,这种模型面向最大似然目标的优化很直接。通常,我们对这种模式中更复杂的(近似)贝叶斯后验推理感兴趣。两种常见的情况是(1)在 partially observed case 中,最大似然估计,例如深度潜变量模型(DLVM),和(2)贝叶斯后验推理参数。在变分(variational)推理的情况下,推理被当作新引入的变分参数的优化问题,通常针对ELBO 进行优化——模型证据的下限或数据的边际可能性。这种后验推理的现有方法或者相对低效,或者不适用于使用神经网络作为组件的模型。

从人脸生成模型中随机抽取的彩色样本。我们使用了与先前的Frey Face示例相同的一个相对简单的VAE,这次是在Labeled Faces in the Wild(LFW)数据集的一个低分辨率版本上训练的。图中显示的是模型中的随机样本。更好的模型可以通过更复杂的生成模型和推理模型来实现。
我们的主要贡献是一套有效和可扩展的基于梯度的变分后验推理和近似最大似然学习的有效方法。我们提出的方法中,一个常见组成部分是将潜在变量或参数再参数化,作为独立噪声的可微函数和变分参数。这可以使用自动微分软件直接计算梯度。为了优化关于ELBO 的潜变量模型,我们提出了变分自动编码器(VAE)框架,将推理网络与再参数化的梯度结合,避免局部参数,并通过双随机优化流程实现了对大数据集的可扩展性。研究展示了,该框架允许学习灵活的DLVM,它们原则上能够对大型数据集中的复杂分布进行建模。这对研究问题 2 给出了肯定的答案。VAE 框架现在是概率建模各种应用的常用工具,在大多数主要的深度学习软件库中都能找到。

我们还展示了与发布前的最先进技术相比,该框架如何使得半监督分类性能有了大幅提升。这同样给了研究问题2 一个肯定的答案。这一结果现在已经被基于GAN 的方法超越了(Salimans 等, 2016)。离散潜在变量的新型评估器(Maddison等,2016;Jang 等,2016)使得将和我们的架构类似的架构扩展到更多的类成为可能,并且成为用深度生成模型进一步探索半监督学习的有趣途径。
对于学习灵活的推理模型,我们提出了逆自回归流(inverse autoregressive flows,IAF),一种允许缩放到高维潜在空间的归一化流。这给了研究问题3 以肯定答案。VAE 框架与几乎任意的可微神经网络兼容。我们表明,具有IAF 后验的VAE 和新型神经网络 ResNet 可以学习自然图像模型,在对数似然性方面接近最先进技术,同时允许更快的大数量采样。进一步探索的一个有趣的方向是与低成本计算 inverse 的变换进行比较,例如 NICE (Dinh 等,2014)和 Real NVP (Dinh 等,2016)。在VAE 框架中应用这种转换可能会引出相对简单的VAE ,与强大的后验、先验和解码器。这样的架构可能媲美或超越单纯的自回归结构[van den Oord 等,2016a],同时允许快得多的合成。
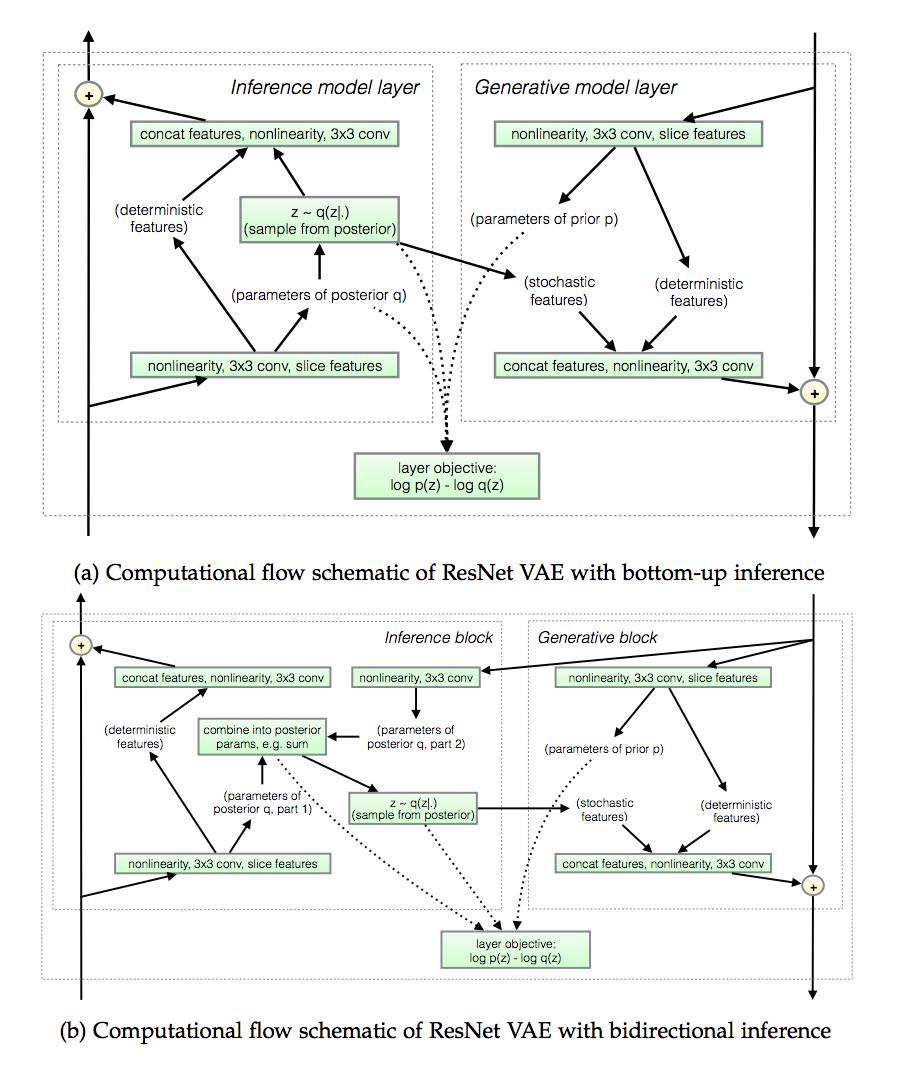
VAE框架仍然是文献中唯一允许离散和连续观测变量的框架,允许有效的平摊潜变量推理分析和快速综合分析,表现出数据对数似然性方面的最先进性能。
我们通过神经网络参数进行了进一步提高基于梯度的变分推理因子分解高斯后验效率的工作。我们开发了一种局部再参数化技术,它将全局权重的不确定性作为局部活动的不确定性进行参数化,导致梯度估计器的精度与最小尺寸线性相关。这对研究问题 4 给出了肯定答案。在准确性或对数似然性方面早期停止或二进制退出方面,我们的实验并没有显示出巨大的进步。随后的工作,如[Molchanov等人,2017]和[Louizos等人,2017]显示了类似的参数化可以用于模型稀疏和模型压缩。我们认为这是未来研究的一种途径。
最后,我们提出了Adam,基于自适应时刻的一阶梯度优化算法。我们表明该方法相对容易调整,并且存在超参数选择,可以在大范围的问题中产生可接受的结果。我们的研究结果对研究问题 5 给出了肯定答案。优化方法已在所有主要的深度学习软件库中实施,并用于数千种出版物。我们猜测,通过加入曲率信息可以进一步改进。
论文下载:https://pan.baidu.com/s/1eSPDGv4
【扫一扫或点击阅读原文抢购五折“早鸟票”】
AI WORLD 2017 世界人工智能大会购票二维码:



