康奈尔大学王飞: 医学人工智能真正落地面临的三大挑战

中国人工智能资讯智库社交主平台新智元主办的 AI WORLD 2017 世界人工智能大会11月8日在北京国家会议中心举行,大会以“AI 新万象,中国智能+”为主题,上百位AI领袖作了覆盖技术、学术和产业最前沿的报告和讨论,2000多名业内人士参会。新智元创始人兼CEO杨静在会上发布全球首个AI专家互动资讯平台“新智元V享圈”。
全程回顾新智元AI World 2017世界人工智能大会盛况:
新华网图文回顾
http://www.xinhuanet.com/money/jrzb20171108/index.htm
爱奇艺
上午:http://www.iqiyi.com/v_19rrdp002w.html
下午:http://www.iqiyi.com/v_19rrdozo4c.html
阿里云云栖社区
https://yq.aliyun.com/webinar/play/316?spm=5176.8067841.wnnow.14.ZrBcrm
新智元 · AI WORLD 2017
演讲嘉宾:王飞 康奈尔大学威尔医学院助理教授
【新智元导读】新智元AI WORLD2017 世界人工智能大会上,康奈尔大学威尔医学院助理教授王飞带来 《人工智能与智慧医疗》的演讲。他以一些研究上的实例,探讨了临床数据分析领域遇到的问题和成果,以及医学数据的质量、数据量和数据标准,模型推广性、可解释性、适用性,数据和模型的隐私性等方面的挑战。


王飞:谢谢大家!很高兴新智元的邀请让我有机会跟大家分享。我们这个会主要强调人工智能,所以技术方面的内容大家听得比较多。我想讲一讲我从2010年开始在临床数据分析领域我们在技术之外遇到的一些问题,以及还有哪些挑战。

我们现在强调人工智能在治疗当中的应用,有各种各样的创业话题,包括AI技术怎样帮助医生进行决策支持,怎样帮助病人去更好地了解自己的病情,我们也有专门人员在研究怎样通过AI技术促进患者参与到治疗过程当中。前段时间有一篇论文发表在新英格兰医学杂志上,讲到Patient Reported Outcome。过去医生给病人医嘱,但不去确认病人是否按照这些建议执行。现在通过AI系统跟踪病人,然后就病人是否遵照医嘱做临床比较试验,结果发现病人如果严格遵照医嘱治疗效果会明显提升。AI技术对于药厂等企业也有很大帮助。
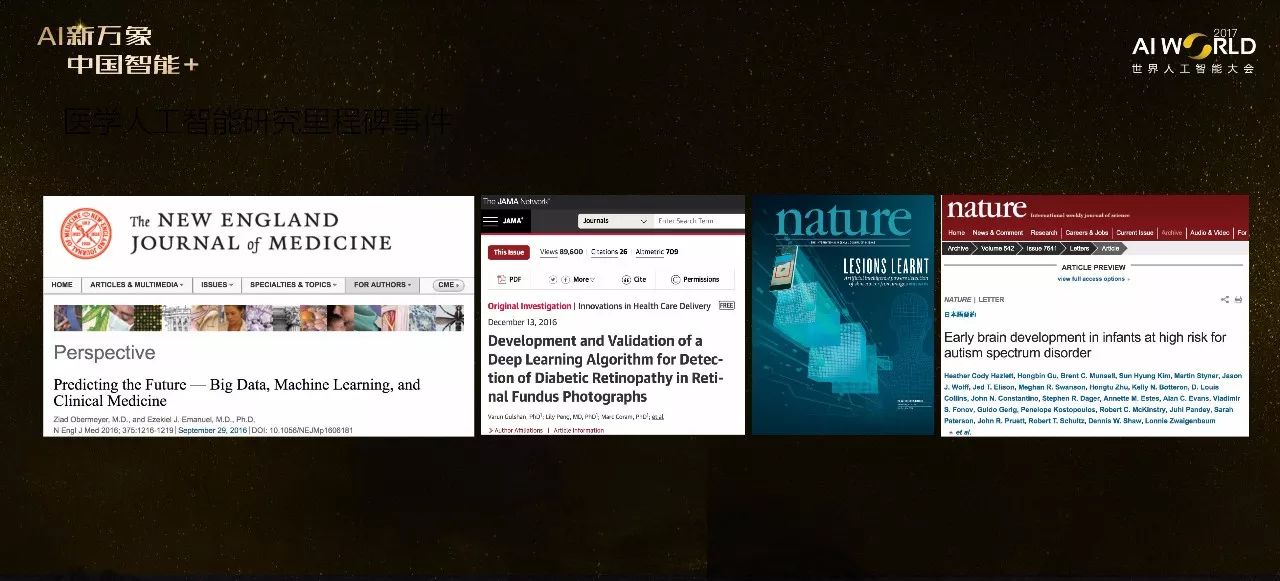
今年发生的多个重要事件让AI在医学领域的应用变得非常火爆。首先是我的一个医生朋友去年在新英格兰医学杂志上发表的一篇论文,讨论了大数据和机器学习对临床医学的一些影响,里面有一个观点:以前大家用的AI是专家系统,专家系统就好比是医学院的学生,毕业后做医生看病时实际是把病人当前状况和书本里面学到的知识作比较,书本里叫我怎样做我就应该怎样做。而现在的机器学习和AI更像是已经在看病人的医生,从已有的案列中寻找相似性,绝非仅限于书本知识 。
另一个事件是斯坦福今年2月在Nature上发表的一篇封面文章,研究团队用GoogleNet对13万张皮肤病人图像做了分析建立预测模型,从皮肤图像来预测改病人是否有恶性病变。经过系统评测该模型可达到与皮肤科医生类似的判断水准。还有几篇类似论文,比如用深度学习方法研究自闭症婴儿的脑图像,也得到了好的预测结果。

实际上AI促进医学发展不只体现在学术界,同样也体现在工业界。现在美国有上百家的创业公司从事医药各方面的数据工作,涵盖影像、语音交互等各个方面。中国数字医疗网曾对AI在医药方面的应用市场情况做过预测,预测结果表明市场前景一片大好。而随着AI应用的不断发展,也涌现出来一些问题。
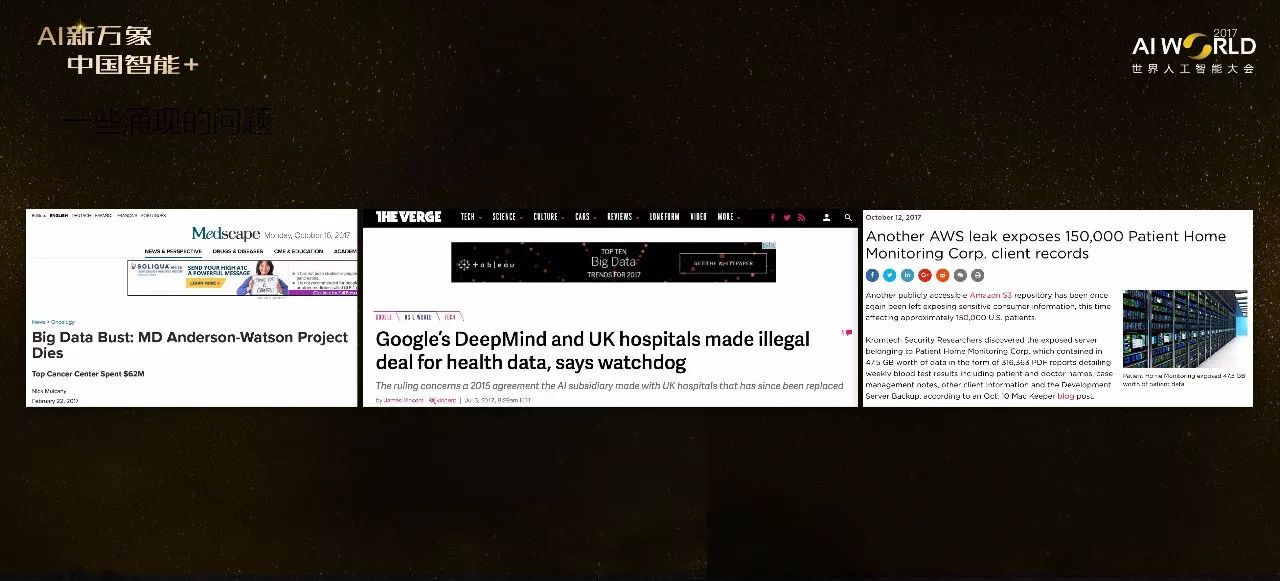
首先看一个很著名的案例,MD Anderson宣布解除与IBM开发的Watson的合作。尽管MD Anderson也有自己的问题,但是沃森这个项目在对应时间内的确没有做出之前预期的效果,这也是导致合作失败的一个原因。因为医学数据的特殊性比其他类别的数据要强很多,比如隐私性,伦理道德约束,法律约束等。这意味着与图像、语音应用相比,分析医学数据的壁垒会更高。这个壁垒不仅指技术壁垒,更指其还受其他因素的制约。
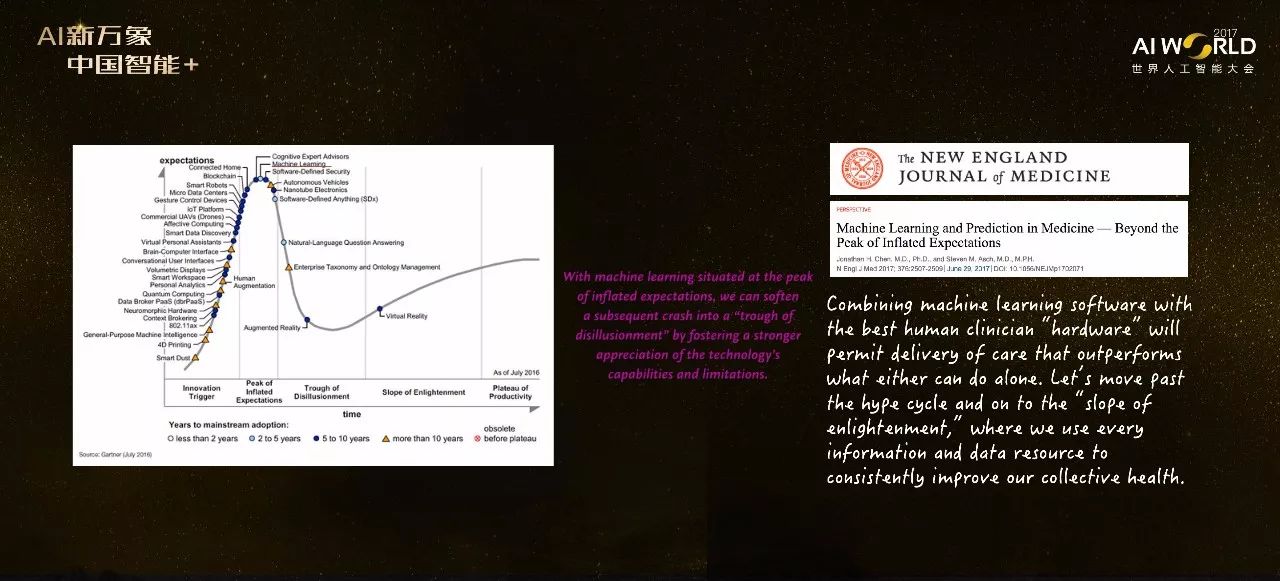
最近Gartners的技术曲线非常火热,它认为任何一个技术兴起都要经过几个阶段:技术从兴起到过热,再到peak of inflated expectation,在这一点上表示人们对该技术的期望过高,这样后期期望就会下降,在曲线上形成槽型部分;经过这个下降阶段后人们变得理智,这项技术会再慢慢发展起来,最后趋向成熟。
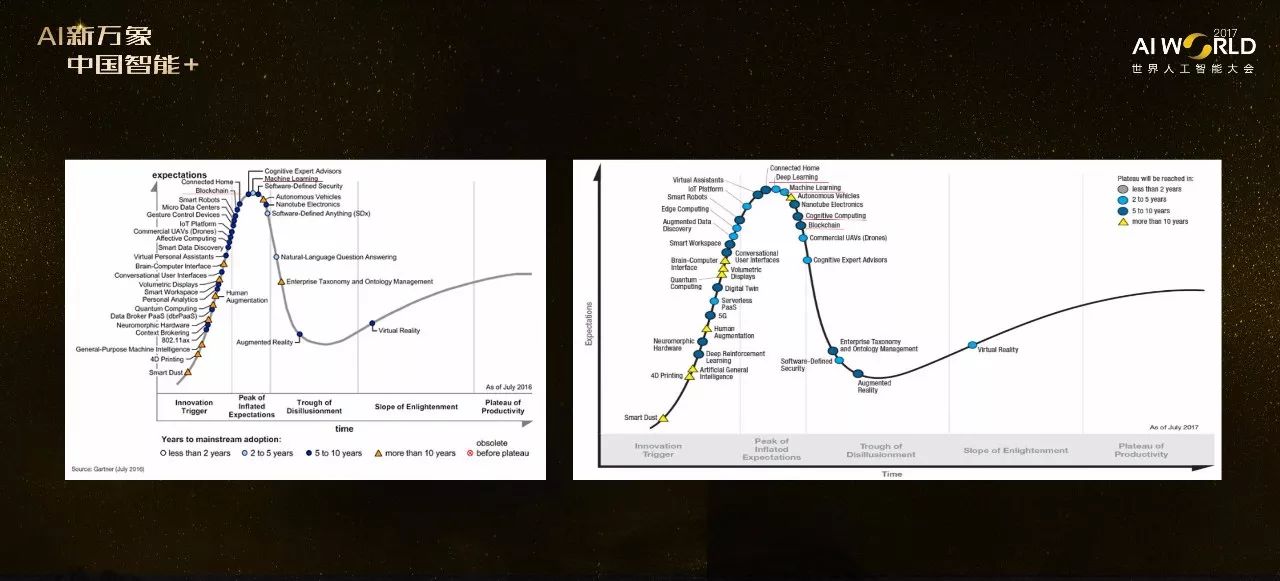
从2016年的曲线图上我们能看到,机器学习是在peak inflated expectation上的,那么接下来它就会下行。今年早些时候新英格兰医学杂志上的一篇评论指出,为了让机器学习的方法在医学中的应用平稳的度过这个下行期,一个重要的途径是正确认识机器学习方法的局限性,与医生的知识相结合。
最近AlphaGO又出了zero,号称可以不借助任何的外在知识一样可以下赢围棋,但一个前提条件是围棋有明确的规则和胜负规则,但医学并没有如此清晰的规则。但这一点是许多研究者,尤其是计算机科学或者AI研究人员忽视的方面。很多时候技术人员强调数据,强调自动,但是忽略了医药是一个专业性很强的领域,如果没有医生参与,我们很难得到正确的对临床确实有益的结论。由于我本身在医学院工作,这方面体会尤其明显。
我想举几个例子来说明AI在分析医学数据时遇到的问题。
第一个例子,我们说说再住院预测(Hospital Readmission Prediction),这是很火的一个话题,2012、2013年有机构曾专门投入300万美元来做这项研究。再住院是指你住了院以后,出院很短时间内又住回来,这种情况很有可能是因为医院措施不当。一般来讲再定义的时间一般是30天 。像CMS会惩罚重复住院率很高的医院。这是一些重复住院率非常高的疾病,比如说像心衰,心脏病,还有肺炎。这是一个美国地图,我们可以看到超时曲线的下降,就是因为CMS出台的高再住院率处罚政策,证明这个政策还是有效的。
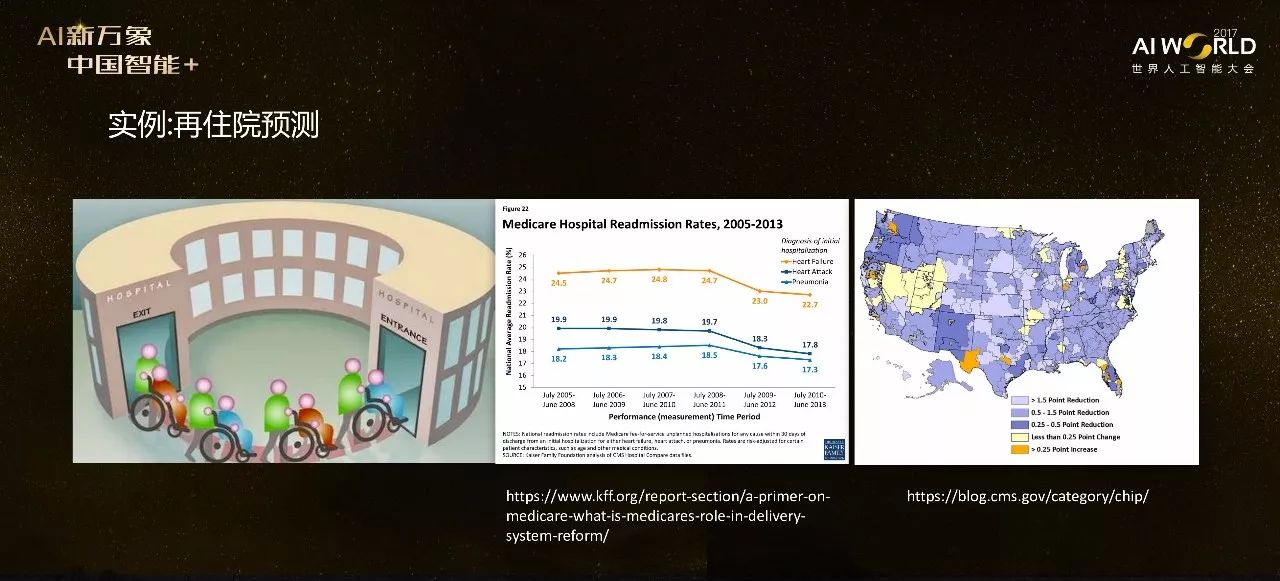
这个是UPMC做的研究,他们是想预测肺炎病人能不能在不住院的情况下治好,是不是能避免再住院。他们使用大数据或机器学习的方法,得到一条规律是,同时患肺炎和哮喘的病人的死亡风险比只患肺炎的人低很多。这条规律令所有人惊讶,后来大家发现是因为同时得了肺炎和哮喘的病人会直接被送到ICU,在ICU里他会得到密切的照顾,这样使得他的治疗结果会变得更好。而这一点并没有在数据中体现。
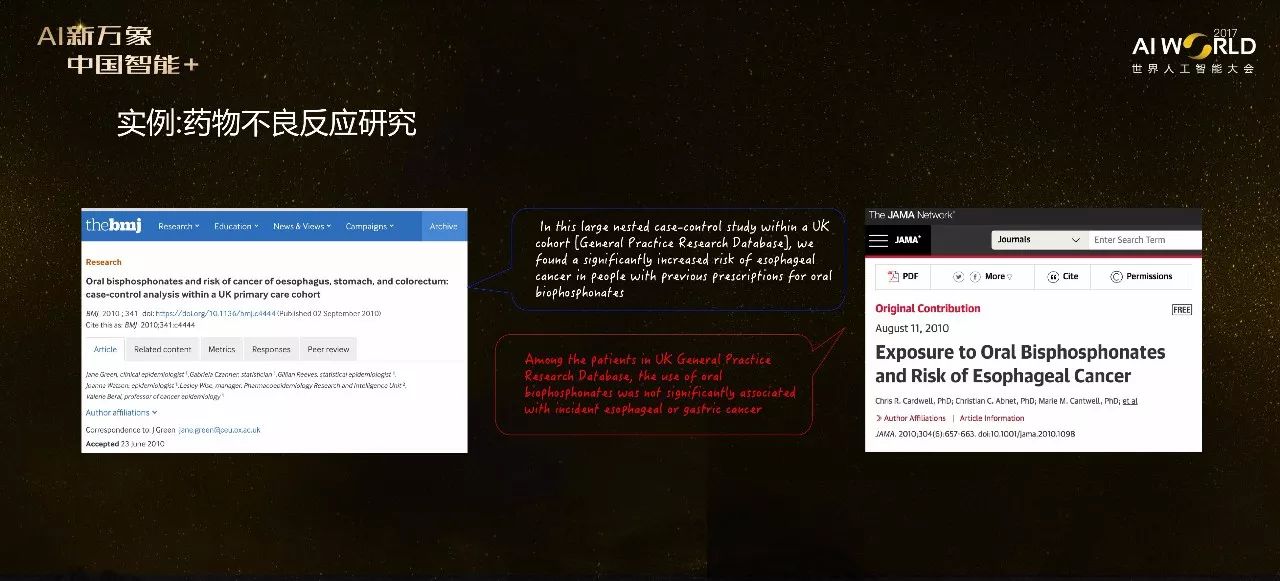
另一个例子是药物不良反应研究。BMJ上2010年9月份曾发表过一篇论文,发现吃双磷酸盐这种药,会极大提升食管癌发病率。而同年8月,JAMA在同样的问题上做了研究,发现吃这种药和食管癌发病率提升没有明显关系。课件这两篇在同一时期发表在两本不同顶级临床医学杂志上的文章的除了截然不同的结论,并且他们还都是在同一个病人队列中进行的研究。这个情况在医药学中经常出现,我们经常强调数据质量,其实这远不止数据质量的问题,我们需要考虑很多因素来保证从数据中发现的不是噪音,而是真实的结果。

总结一下,我们分析医学数据和医学人工智能,要真正做能落地的研究面临的挑战有哪些呢?大概有这几个方面。
第一数据质量是关键,如果数据质量很差,有很多噪音或异常值就发现不了很多东西。所以我们需要发展统一的质量评估框架,现在很多人在做这方面的研究。
第二点是数据量,跟很多应用深度学习的领域不同,医学数据不是想要多少病人就有多少病人的,还需要将病人数分散到不同的病种上,尤其是一些少见疾病的病人的数量非常少。样本量不足时怎样进行分析呢?我们通过各种各样的技术,比如临床、可穿戴设备等多种手段尽量得到病人的所有信息,就是为了弥补有限的病人样本的问题。
第三点是数据标准,美国的数据标准化程度比较好,我们现在在推广Observational Health Data Science and Informatics,OHDSI,这是一个组织,希望能推行病人电子病历数据的一套标准,现在已经有很多美国医院在将他们的数据向这个标准上靠拢。全世界已经有20个国家有OHDSI成员,数据库中已经有6亿个病人数据。我们也成立了OHDSI China Working Group,并成立了几个分组,我是数据分析分组的组长之一,我们也在试图和中国多家医院进行合作推广。数据如果不标准,很多疾病称呼混淆就无法进行讨论,所以需要规范化的标准。

这里数据维度和异质性就不讲了。还有数据偏倚,比如沃森只能在美国病人群体上用,在菲律宾怎么用?还有模型的可解释性,我们用深层学习模型去预测皮肤癌,但结果皮肤科医生不敢用,因为医生需要知道是由于出现哪些特点,才导致了这样一个预测结果,模型的解释性要强。还有模型的适用性,前面说了,AlphaGO Zero的优势在于不需要数据,它的规则非常清晰,但医疗领域没有那么清晰的规则。还有隐私性,有学者在专门研究怎样在不泄漏任何隐私的条件下做医疗分析。
这是当前发展机器学习或者AI算法用于分析医疗数据的挑战,我们在开发任何方法的时候都要意识到这些挑战,才能让我们做出来的应用真正适用于医学场景,让它变得更实用。
谢谢大家!
(整理:Marvin,Ferguson)
NIPS 2017,新智元智库专家、CMU计算机学院副教授马坚老师和斯坦福大学AI博士生Jim Fan将在美国长滩带来现场直播,关注新智元小程序或扫描下方二维码加入直播群,参与直播互动,第一时间了解NIPS前沿资讯。





