ECCV 2020 | 港中文等提出DDBNet:目标检测中的Box优化
点击上方“CVer”,选择加"星标"置顶
重磅干货,第一时间送达

本文转载自:AI算法修炼营 | 文末附论文下载和 学术交流群

这篇文章收录于ECCV2020,作者团队是香港中文大学、腾讯优图、思谋科技等。整体文章思路通过深入了解box来优化anchor-free目标检测的性能,整体分为box分解和重组(D&R)模块和语义一致性模块,首先进行边界框的重组选择更准确的边界框,之后选择一致性强的像素来更精确地拟合目标范围,从而提高目标检测性能。思路还是不错,只是效果一般般。
论文地址:https://arxiv.org/abs/2007.14350
Anchor-free目标检测方法中精确的边界框估计是这些方法成功的关键。但是,即使边界框具有最高的置信度得分,在定位环节仍然有一些瑕疵。为此,本文提出了一种box reorganization方法(DDBNet),该方法可以深入到box中以进行更准确的定位。具体来说,第一步将漂移的框(drifted box)过滤掉,因为这些框中的内容与目标语义不一致。接下来,将选定的框划分为边界(boundaries),并搜索排列整齐的边界,将其分组为更精确的框,从而更精确地拟合目标实例范围。实验结果表明,本文的方法是有效的,可实现最新的物体检测性能。
简介
在目标检测领域,尽管anchor-free方法取得了成功,但应注意的是,这些方法在准确性方面仍存在局限性,其局限性在于其以atomic fashion方式学习边界框的方式。因此,anchor-free方法的存在两个问题:首先,中心关键点的定义与其语义不一致。众所周知,中心关键点对于anchor-free目标检测器是必不可少的,通常,在其训练阶段将目标包围盒内的正中心关键点嵌入到均匀或高斯分布中,典型的算法有:FCOS 和CornerNet。但是,如图1所示,不可避免地会错误地将背景中的噪点像素视为正样本值。即采用 trivial 的策略来定义正目标会导致明显的语义不一致,从而降低检测器的回归精度。

图1:边界框内的中心关键点的语义与其标注之间不一致。红色中心区域的背景像素被视为正中心关键点,这是不正确的。
第二,局部回归( local wise regression)是受限的。具体而言,中心关键点通常以区域/局部方式提供框预测,这可能会影响检测精度。局部预测是由于卷积核的感受野的限制,以及将每个中心关键点的每个box预测视为原子操作而设计的。如图2所示,虚线的预测框和相应的中心关键点以相同的颜色显示。尽管每个预测的box都围绕着对象,但这是不完美的,因为四个边界不能同时正确地与ground truth对齐。因此,在推断阶段选择高分的box作为最终检测结果有时是较差的。

图2:普通anchor-free目标检测器的box预测中边界漂移现象的示意图。受区域感受野的限制以及将每个box预测视为原子操作的设计,每个带虚线的预测框box都不完美,其中四个边界不能同时适应ground truth。经过box的分解和组合后,重组后的红色box的定位效果更好。
为了解决检测不准确的问题,本文提出了一种新型的边界框重组方法,该方法深入到中心键点的box框回归过程中,并考虑了中心关键点的语义一致性。该重组方法包含两个模块,分别表示为box分解与重组(D&R)模块和语义一致性模块。 具体来说,一个实例内部的中心关键点的边界框box预测形成了一个实例定位的初始粗分布,这种分布与理想的实例定位并不一致,通常会出现边界漂移的问题。D&R模块首先将这些box预测分解为四组边界,在较低的精度水平上建立实例定位模型,每个边界的置信度根据与ground truth的偏差进行评估。接下来,对这些边界进行排序和重新组合,形成一种对每个实例更精确的边界box预测,如图2所述。然后,这些优化后的边界框预测有助于最终的边界框回归。
同时,提出了语义一致性模块来排除背景中的噪声中心关键点,这使本文的方法可以将重点放在与目标实例语义上密切相关的关键点上,并形成与目标实例定位相关的更紧密和可靠的分布,从而进一步提高了D&R模块的性能。语义一致性模块是一种针对预定义空间约束的无额外超参数的自适应策略。
本文方法:DDBNet
在本文中,基于FCOS构建了DDBNet,这是一种先进的anchor-free方法。如图3所示,本文的创新在于box分解和重组(D&R)模块和语义一致性模块。
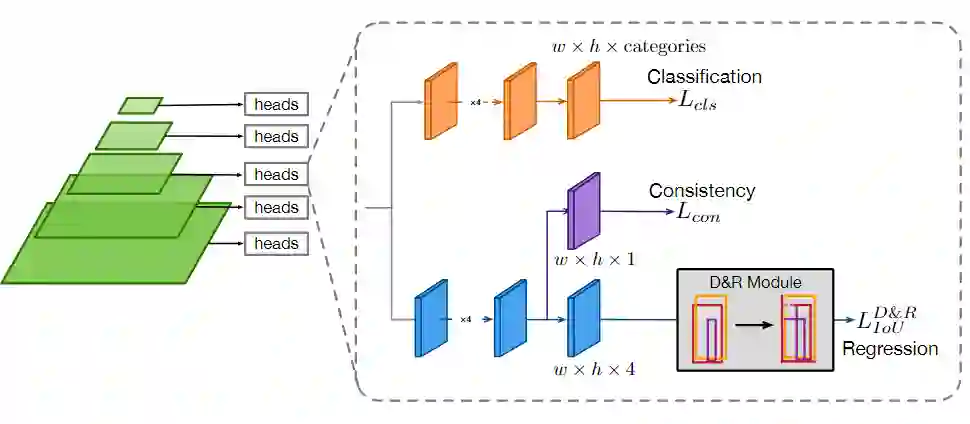
图3:网络架构示意图。D&R模块和一致性模块被合并到通用检测网络中。D&R模块在训练阶段根据IoU损失进行框分解和重组,并预测由边界偏差监督的边界置信度。一致性模块选择语义与目标实例一致的有意义像素,以提高训练阶段的网络收敛性。
具体来说,D&R模块通过将预测的框划分为边界进行训练来重组预测框,该边界在回归分支后面进行连接。在训练阶段,一旦边界框预测在每个像素处回归,D&R模块会将每个边界框分解为四个方向边界。然后,根据它们与ground truth的实际边界偏差对同类边界进行排序。因此,通过重新组合排位边界,可以期望得到更准确的box框预测,然后通过IoU loss对其进行优化。
至于语义一致性模块,将一个新的分支估计语义一致性而不是中心性纳入了框架,并在语义一致性模块的监督下对其进行了优化。该模块基于分类和回归分支的输出,提出了一种自适应过滤策略。
1 Box Decomposition and Recombination
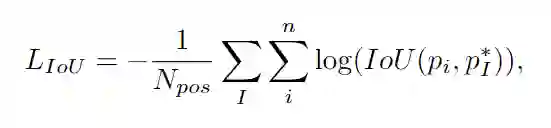
IoU就是所说的交并比,是目标检测中最常用的指标,在anchor-based的方法中,他的作用不仅用来确定正样本和负样本,还可以用来评价输出框(predict box)和ground-truth的距离。

IoU可以反映预测检测框与真实检测框的检测效果。还有一个很好的特性就是尺度不变性,也就是对尺度不敏感(scale invariant), 在regression任务中,判断predict box和gt的距离最直接的指标就是IoU。(满足非负性;同一性;对称性;三角不等性)
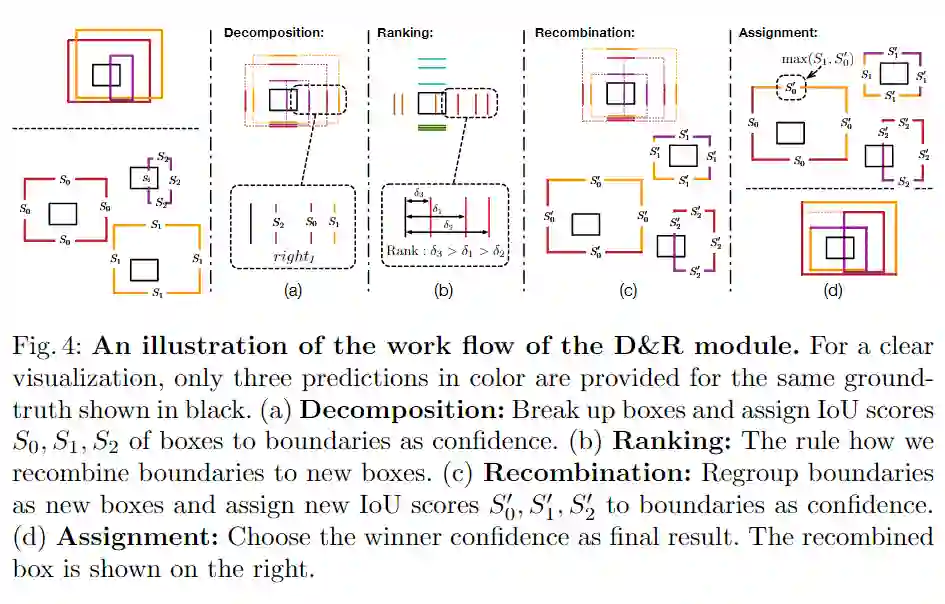
如图4所示,D&R模块由四个步骤组成,然后根据IoU回归对最终的box预测进行正则化。
Step 1: Decomposition
如图4(a)所示,将一个预测的box划分为四个边界的置信度。然后将四种边界分为四组,分别是:left = {l0,l1,...,ln},right = {r0,r1,...,rn},bottom = {b0,b1,..., bn},top = {t0,t1,...,tn}。
Step 2: Ranking
考虑到IoU损失的约束,有利于具有较小并集和较大交集区域的预测框,最佳框预测的IoU损失预计最低。因此,在第二步中可以直接遍历所有边界后进行重新排列以获得最优的框,然而,以这种方式,计算复杂度非常高。为了避免这种暴力方法带来的繁重计算,本文采用了一种简单有效的排序策略。对于目标实例的每个边界集,计算到目标边界集合的偏差。然后,将每个集合中的边界按相应的偏差排序,如图4(b)所示。因此,靠近ground truth的边界比远处的边界具有更高的等级。作者发现这种排序策略效果很好,并且排序噪声不会影响网络训练的稳定性。
Step 3: Recombination
如图4(c)所示,将具有相同等级的四个集合的边界重新组合为新框。然后,将分解后的边界集合和目标边界集合之间的IoU看作为四个边界的重组置信度。重组边界的置信度表示为形状为N×4的矩阵。
Step 4: Assignment
现在得到了原始边界和重组后的边界两组边界得分。如图4(d)所示,每个边界的最终置信度是使用两组边界得分中的较高得分来分配的,而不是完全使用其中一组。如果重新组合后的低位框包含的边界离ground truth很远,这会导致重组后四个边界的置信度远低于其原始边界,这些严重漂移的置信度分数会导致训练阶段的梯度反向传播不稳定,因此选择得分较高的一组。
因此,为了进行可靠的网络训练,在基于ground truth和最优box以及相应的更好边界得分估算的IoU损失的监督下来优化每个边界。最终的回归损失包括两个部分:
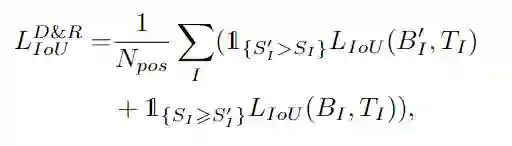
主要思想是根据原始框和重组框之间较高的IoU分数,选择每个边界的梯度以更新网络。
2、Semantic Consistency Module
由于D&R模块的性能在一定程度上取决于目标实例中密集的box预测,因此需要一种自适应滤波方法来帮助网络学习将注意力集中在正样本的像素上,而排除负样本。也就是说,期望目标实例内像素的标签空间与其语义相一致。本文的网络在训练阶段无需额外的空间假设就可以学习准确的标记空间。
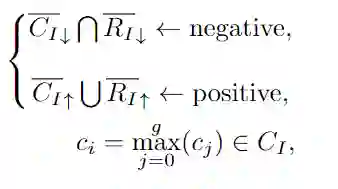
其中RI是背景真实度与目标实例I内像素的预测框之间的IoU得分,RI↓表示IoU置信度低于平均IoURI的像素。相反,RI↑表示具有比RI更高的IoU置信度的像素。元素ci∈CI是第i个像素的所有类别中的最大分类得分,表示类别数。类似地,CI↓表示具有比CI的平均得分低的分类得分的像素。在这种方法中,类别标签是不可知的,因此在训练期间不会抵制不正确类别的预测。最后,如图5所示,RI↓和CI↓中的交点像素被指定为负,而RI↑和CI↑中的并集像素被指定为正。同时,如果像素被多个实例覆盖,则它们优先选择表示最小的实例。
更重要的是,由上面等式确定的滤波方法能够在训练阶段自适应地控制具有不同大小的实例的正负像素的比率,这对网络的检测能力有显著影响。在实验中,研究了不同固定比率的性能,然后发现平均阈值的自适应选择效果最佳。
在根据语义一致性自主确定像素的标签后,网络在学习过程中考虑了每个正向像素的内在重要性,类似于FCOS中的中心度得分。因此,DDBNet网络能够强调一个实例中更重要的部分,学习起来更加有效。具体地,将每个像素的内在重要性定义为预测框与ground truth之间的IoU。然后,在内在重要性的监督下,将估计每个像素语义一致性的额外分支添加到网络中。语义一致性的损失表示为:
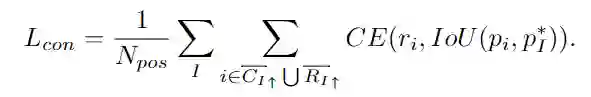
网络整体训练过程中的损失函数为:
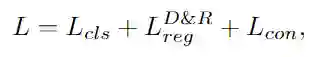
其中,分类损失为Focal loss。
数据集:COCO detection benchmark
评价指标:average precision (AP)、 ten IoU thresholds (i.e., 0.5 : 0.05 : 0.95)
1、对比实验
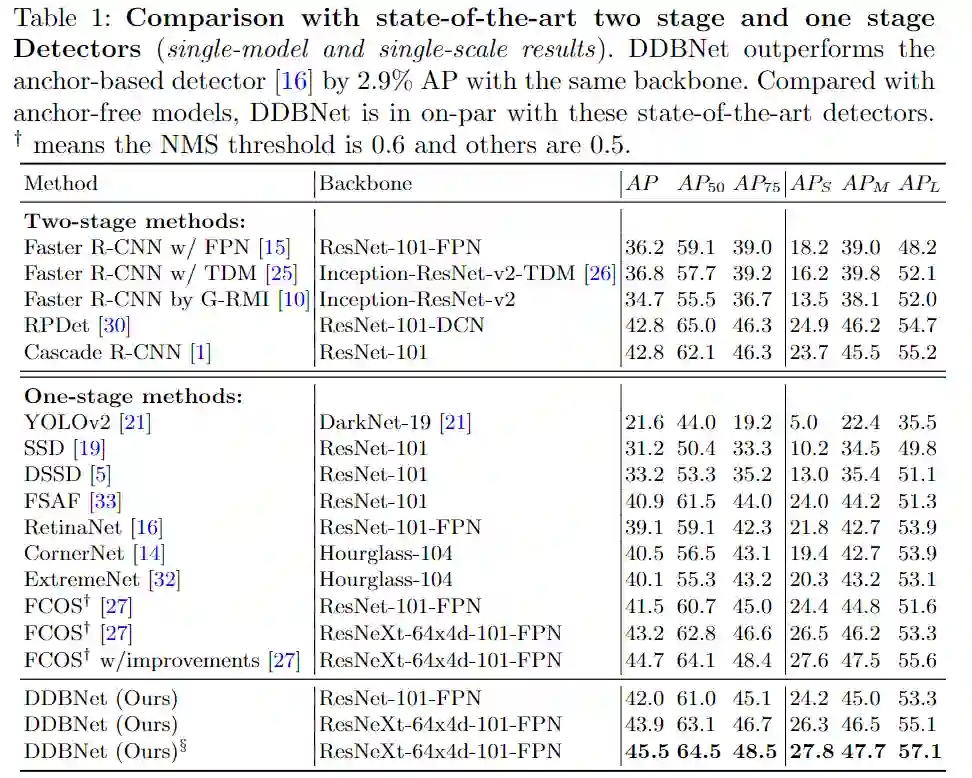
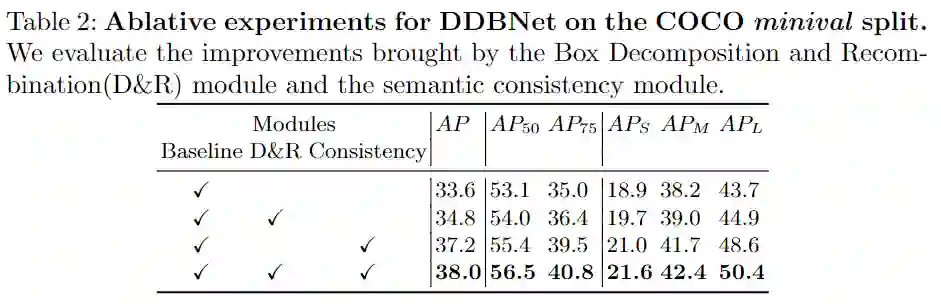
2、消融实验
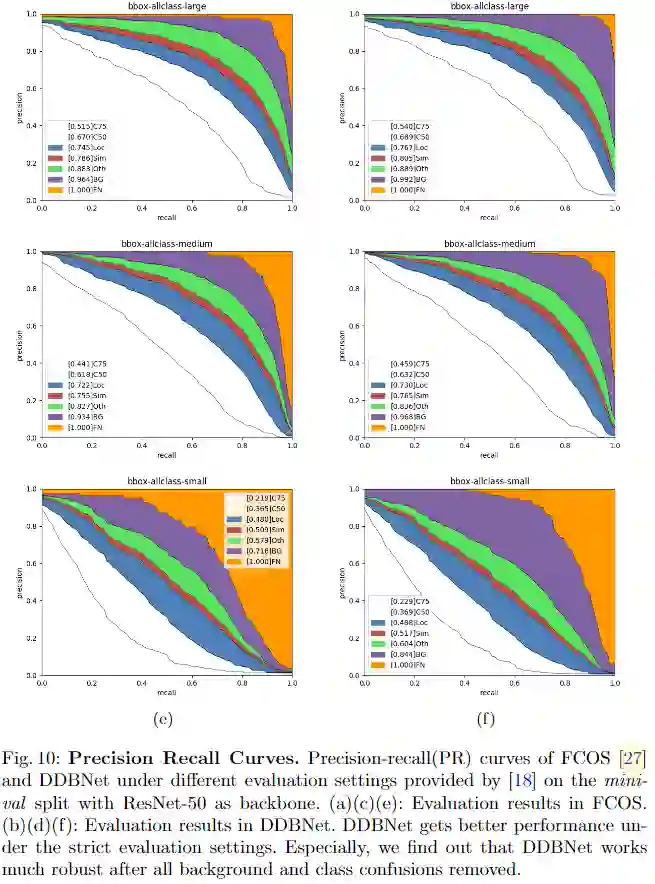
4、可视化与PR曲线

更多细节可参考论文原文。
下载
在CVer公众号后回复:DDBNet,即可下载论文
下载1
在CVer公众号后台回复:OpenCV书籍,即可下载《Learning OpenCV 3》书籍和源代码。注:这本书是由OpenCV发起者所写,是官方认可的书籍。其中涵盖大量图像处理的基础知识介绍,虽然API还是基于OpenCV 3.x,但结合此书和最新API,可以很好的学习OpenCV。

下载2
在CVer公众号后台回复:CVPR2020,即可下载CVPR2020 2020代码开源的论文合集
在CVer公众号后台回复:ECCV2020,即可下载ECCV 2020代码开源的论文合集
重磅!CVer-目标检测 微信交流群已成立
扫码添加CVer助手,可申请加入CVer-目标检测 微信交流群,目前已汇集4200人!涵盖2D/3D目标检测、小目标检测、遥感目标检测等。互相交流,一起进步!
同时也可申请加入CVer大群和细分方向技术群,细分方向已涵盖:目标检测、图像分割、目标跟踪、人脸检测&识别、OCR、姿态估计、超分辨率、SLAM、医疗影像、Re-ID、GAN、NAS、深度估计、自动驾驶、强化学习、车道线检测、模型剪枝&压缩、去噪、去雾、去雨、风格迁移、遥感图像、行为识别、视频理解、图像融合、图像检索、论文投稿&交流、PyTorch和TensorFlow等群。
一定要备注:研究方向+地点+学校/公司+昵称(如目标检测+上海+上交+卡卡),根据格式备注,可更快被通过且邀请进群

▲长按加群

▲长按关注我们
整理不易,请给CVer点赞和在看!

