我是粉红猪佩奇,我要把粉色吹风机写进 IJCAI 论文!

文 | 智商掉了一地
当小猪佩奇的忠实观众进行AI研究,论文配图居然是这样的风格……
在介绍接下来的内容前,我们先来看一则笑话:
小猪佩奇哭着对妈妈说:“小伙伴们都说我长得像粉色吹风机。” 猪妈妈安慰道:“尽瞎说,不过宝贝,下次说话时离妈妈远一点吧,别把妈妈新烫的头发给吹乱了。”
不知道大家有没有注意过这个现象:随着年轻一代开始步入科研的道路,学术论文的画风也越来越有趣。在自然语言处理领域可以看到,从科幻电影中的Transformer,再到儿童教育节目《芝麻街》中的BERT、ELMo、ERNIE和Big Bird,越来越多的论文作者冲破论文命名需要严肃的桎梏,给自己的模型起一些富有趣味且朗朗上口的简称,让读者可以迅速记住自己的模型,同时这些模型也不负众望地在其研究领域占据了主流地位。

今天这篇文章的作者就在论文配图上别出心裁,给我们诠释了一位小猪佩奇爱好者在CV领域进行研究时,配图画风究竟会有多可爱。作者首次提出域信息和类别信息的解耦表达,利用双对抗网络结构学习较有影响力的类别信息。
论文题目:
Learning Disentangled Semantic Representation for Domain Adaptation
论文链接:
https://www.ijcai.org/proceedings/2019/285
点开这篇论文时,最吸引目光的无疑是这张问题图,作者借助小猪佩奇和吹风机这两类毫不相干却又有一定联系的样本,引出了本文要研究的问题。
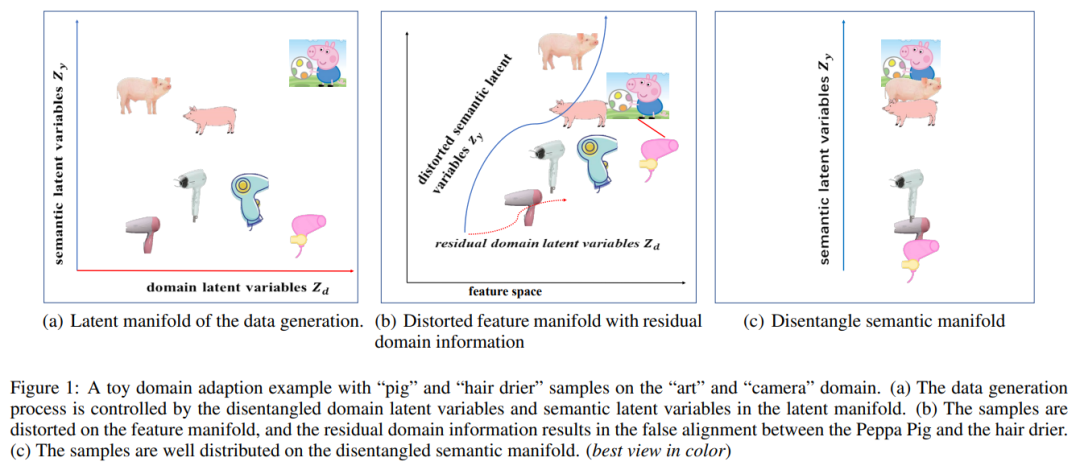
作者指出,现有的域自适应方法无法从特征空间提取具有域耦合信息和语义信息的域不变表示,因此作者提出了用潜在可解耦语义表示(latent disentangled semantic representation)来扩展语义信息。
本文引出了以下两个问题:
-
跨域问题中,域的不变性表示是什么? -
如何设计一个模型来提炼域的不变性表示?
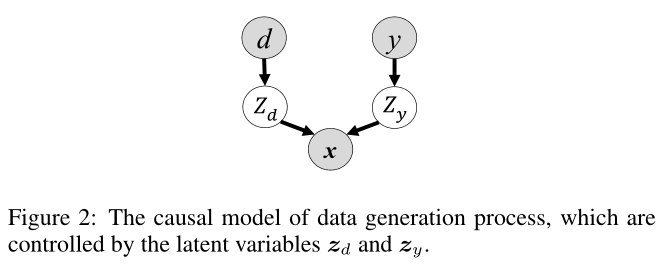
针对第一个问题,作者从数据生成过程背后的因果机制入手,如下图所示,给定由两个独立的潜在变量生成的 x,其中域潜在变量 对域信息编码,语义潜在变量 对语义信息编码,并且假设两者相互独立。作者还考虑到域信息在不同域之间可能存在很大差异,因此推断语义潜在变量在提取域不变表示中起着重要作用。
对于第二个问题,利用上述数据生成机制,作者提出了一种可解耦语义表示 (Disentangled Semantic Representation, DSR) 的域适应框架,如下图所示,其中 和 分别是语义和域信息的编码器。
首先通过变分自编码器重构两个独立的潜在变量,然后通过双对抗训练网络来解耦合。
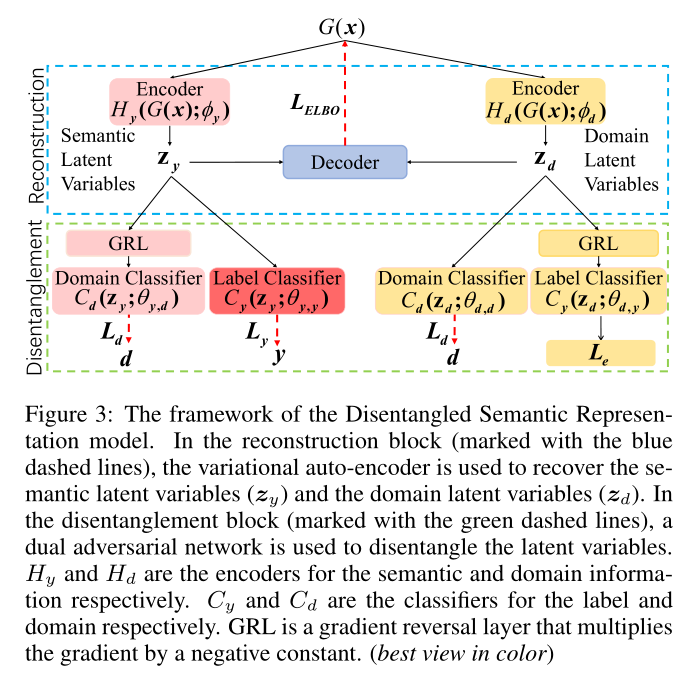
在重建块中,变分自编码器用于恢复语义潜在变量 和域潜在变量 。
在解耦合块中,使用双对抗网络对潜在变量解耦合。图的左侧是利用了语义潜在变量 的标签对抗学习模块,融合了语义信息,并对域分类器 用梯度反转层 (GRL) 排除了所有的域信息。这是通过使用标签分类器 和域分类器 来完成的。图的右侧是域对抗学习模块,将域信息融合到 中,并从 中排除语义信息。同时将 GRL 用于标签分类器上,以便掌握来自 的所有域信息。但与语义模块不同的是,作者没有用交叉熵作为标签损失,因为目标域中的无监督学习。
![]() 实验效果
实验效果![]()
 实验效果
实验效果实验使用的公开数据集如下:
-
Office-31:是视觉域自适应的Baseline,包含来自三个不同域的 4652 张图像和 31 个类别:Amazon (A),Webcam (W) 和 DSLR (D)。 -
Office-Home:是 Office-31 的升级版本,包含来自 65 类日常对象的约 15500 张图像。该数据集分为四个域:Art (Ar),Clipart (Cl),Product (Pr) 和 Real-world (Rw)。
接下来看看在两个公开数据集上的表现:
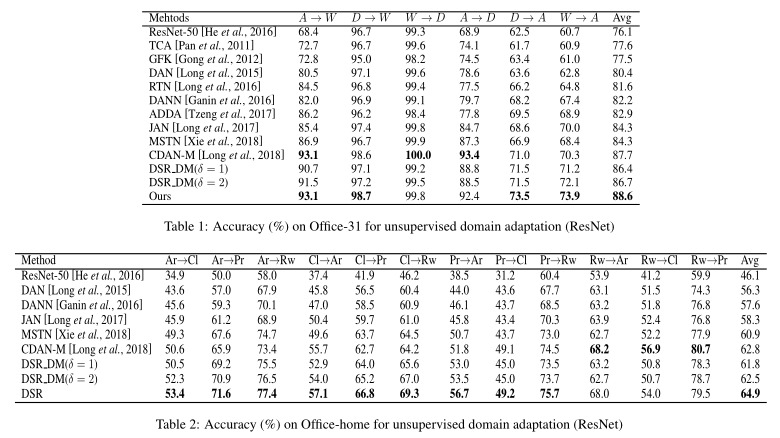
图中加粗表示在公开数据集上训练的最优结果。
从实验结果来看,DSR 在数据集 Office-Home 的大多数迁移任务上优于其他Baseline,尤其显著提升了硬迁移任务的分类精度,但在 W→D 和 A→D 任务上的结果低于一些比较方法,这是因为域中的样本数量过少导致 DSR 模型不足以重建可解耦的语义表示。
数据集 Office-Home 的结果也显示了 DSR 模型更容易提取相对简单的图片和更复杂的场景的语义表示,而真实图片是在现实生活中拍摄的,存在很多模棱两可的样本这样的语义信息是在域中难以被解耦合和提取。
为了验证可解耦语义表示的有效性,在任务 Ar→Cl(源域Art,目标域Clipart)上,作者还将 DSR 与两种使用类似对抗学习策略的方法利用 t-SNE 可视化进行了比较。

可以看到,DSR 的对齐效果更佳,而 DANN 和 MSTN 都有大量样本的对齐存在错误。
![]() 小结
小结![]()
作者提出了一种用于无监督域自适应任务的可解耦语义表示模型 DSR ,该模型遵循数据生成过程的因果模型,在可恢复的潜在空间上提取分离的语义表示,也因此该模型还具有基于变分自编码器的潜在空间恢复和基于双对抗学习的可解耦表示的特点。该方法的成功不仅为域自适应任务提供了有效的解决方案,而且为基于可解耦的学习方法开辟了可能性。
最后,说一句题外话,作者可爱的论文配图画风也是吸引我阅读这篇文章的原因之一,当越来越多的科研人员冲破学术论文严肃的桎梏时,也许研究的内容也会让读者阅读时感觉更亲切吧。

后台回复关键词【入群】
加入卖萌屋NLP、CV与搜推广求职讨论群
后台回复关键词【顶会】
获取ACL、CIKM等各大顶会论文集!
![]()
 后台回复关键词【
后台回复关键词【
