GPipe: 小批量流水线带来的大模型训练

模型训练相关文章:
-
大批量SGD: 1小时训练ImageNet -
LARS: 学习率层次自适应,超大批量32K -
Ring All-reduce: 分布式深度学习的巧妙同步 -
混合精度: 4分钟训练ImageNet -
LAMB: 76分钟训练Bert -
GPipe: 小批量流水线带来的大模型训练(本篇)
Overall
现在大模型能带来好效果已是深度学习的定式了,比如最近出的T5、GPT3等模型一个比一个大。而常用的框架对大模型的训练的支持还不是特别好,GPipe则弥补了这一空白,将一个大模型均匀的分布在多个设备上,然后通过流水线的方式进行模型的训练和加速。
模型切分
当一个模型足够大时,现在的TPU或者GPU是无法完全载入到内存的,更别说训练了。因此,需要多模型进行拆分。拆分有两种方式,横向和纵向:
-
横向拆分是指模型的每一层都拆分到多个设备上。这样,相当于这一层在每个设备上占用的内存就变少了,因而,总模型可以很大。 -
纵向拆分是指模型按照层次分到多个设备上,一个设备上可以放一层或者连续的多层。
横向和纵向各有利弊,因为深度学习模型大部分都是层次状的,下一层的计算依赖上一层的输出,因而,如果横向切分,会导致设备间有大量的通信需求,通信有可能会成为瓶颈。而纵向切分则有个硬性要求,那就是单层的内存占用不能超过一个设备的上限。
因为现在来看,单层的内存占用远不足以超过一个GPU或TPU的上限,因而,GPipe采用的是纵向切分。
采用了纵向切分后,模型的前向计算和梯度计算就是跨设备的了。
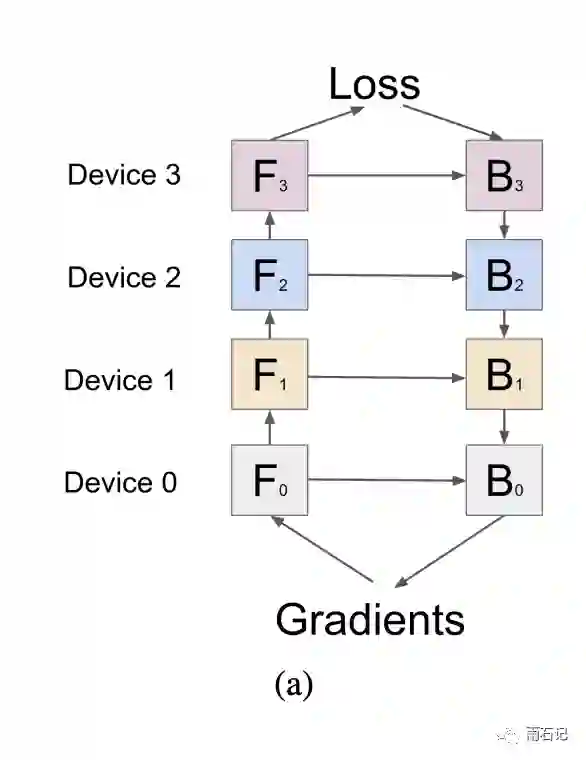
流水线
因为层与层之间是跨设备的,就导致了有些设备在空转,如下图所示,如果有四个设备的话,那么同一时间有三个设备是没有计算任务的。
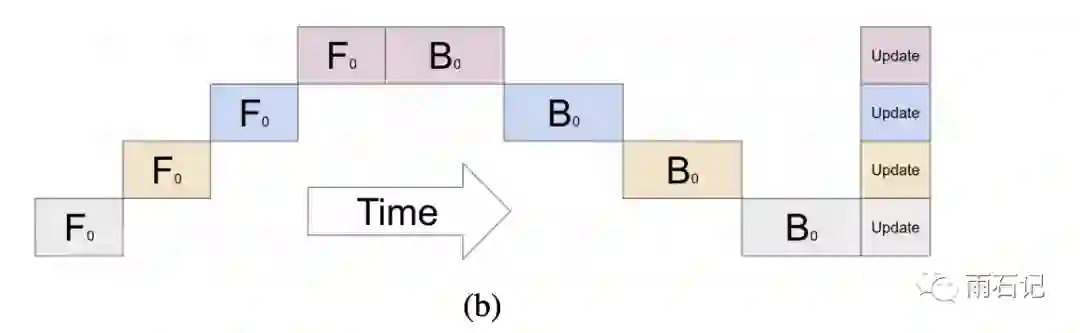
解决的办法则是流水线作业,即计算的时候,将一个大Batch,切成很多小batch,从而实现并行化,梯度则是在所有的小batch都计算完之后进行累加。如下图所示:
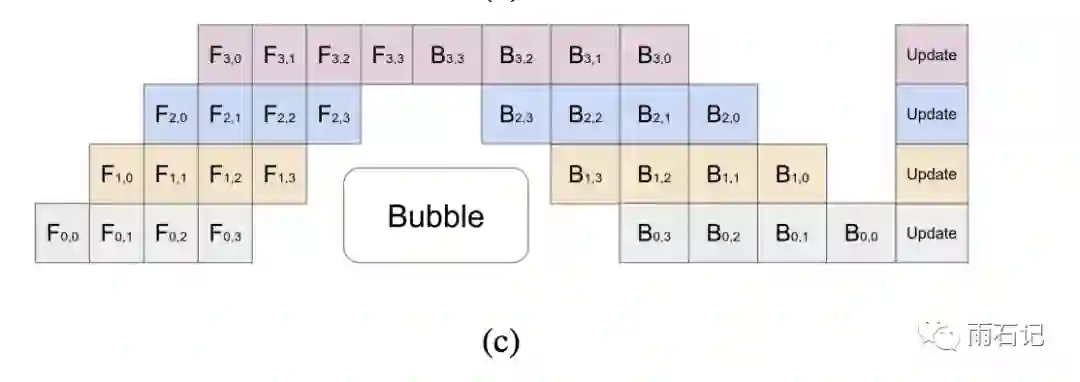
这样做有两个好处:
-
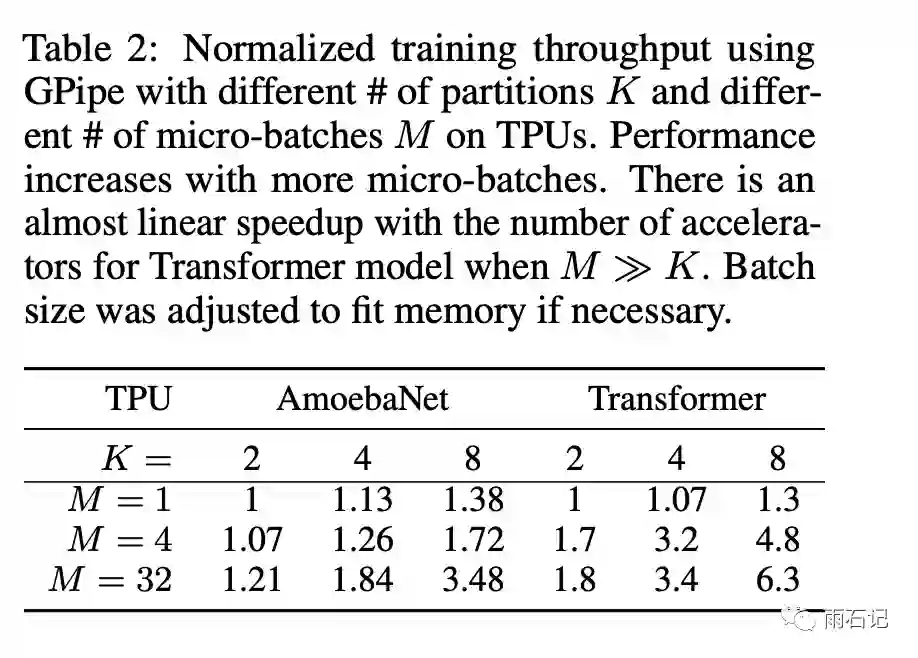
并行化,提高并行程度。假设有K个设备,大batch切成M个小batch,那么每个设备的空转时间是O((K-1)/(M+K-1)),当M>>K的时候,这个时间可以忽略不计。实验表明如果M>=4K,那么这个空转时间就很少了。 -
节省内存,模型占用的内存和batch大小是线性关系,而把大batch切分以后,就导致在一个设备上占用的内存峰值变小了,因而就需要比较少的设备了。反之,如果调大这个batch,那么总体的大batch的值就变大了,而大批量也可以加速训练,参考 大批量SGD: 1小时训练ImageNet
但也有一个坏处,那就是把batch拆小了之后,对于那些需要统计量的层,比如Batch Normalization来说,就会导致计算变得麻烦,需要重新实现。
Re-materialization
在并行化和流水线的同时,GPipe还应用了一项叫做Re-materialization的技术,该技术可以不用保存中间层输出的激活值,在计算梯度的时候会重新计算出来这些值从而可以计算梯度。在GPipe中,应用了这个技术后,如果一个设备上有多层,那么就可以只保存多层中的最后一层的输出值。这样就降低了每个设备上内存占用峰值,同样的模型尺寸需要的设备就少了,或者说同样的设备数,能承载的模型就变大了。
这个技术我们稍后在另外的文章中详细阐述。这里先挖个坑。
实验结果
对两种模型分别进行了实验,那就是AmoebaNet-D和Transformer-L,模型尺寸如下:
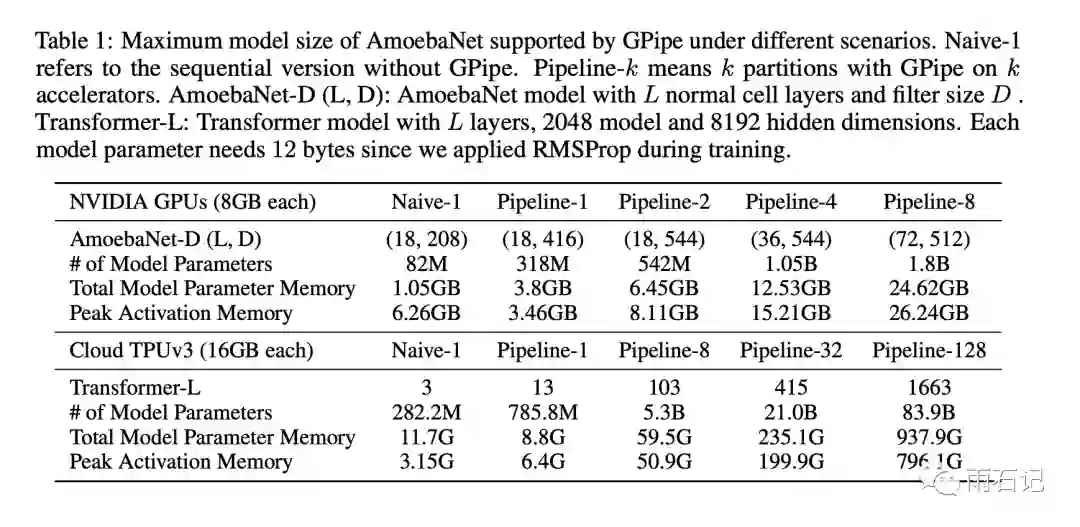
其中,随着设备数的增加,AmoebaNet的尺寸是次线性的,而Transformer的尺寸是线性增长的,这主要是因为AmoebaNet模型并不是均匀分布的,层与层的参数量会不同,而Transformer的每个Block都是同尺寸的。
同理,不同参数的加速比如下:
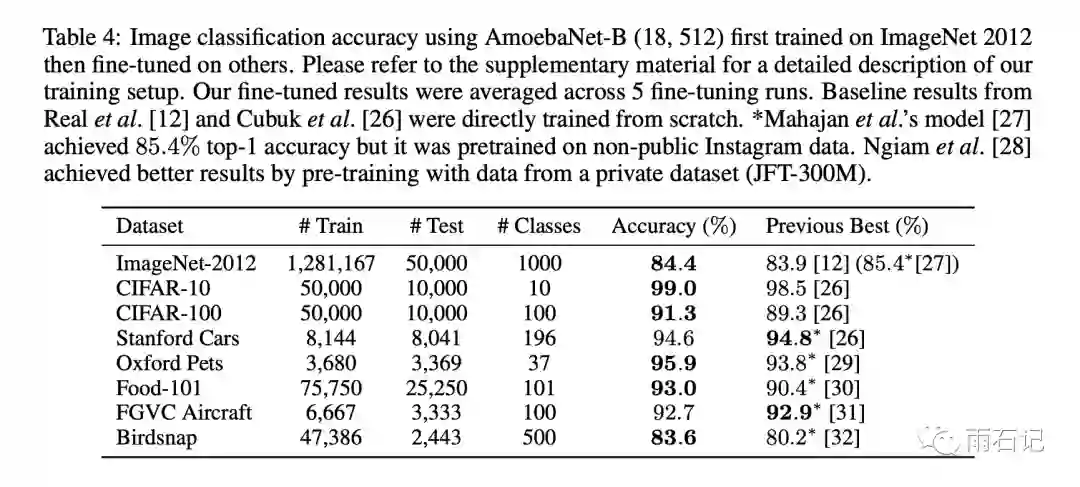
效果上,在图像分类任务上,AmoebaNet可以得到比之前好的效果。
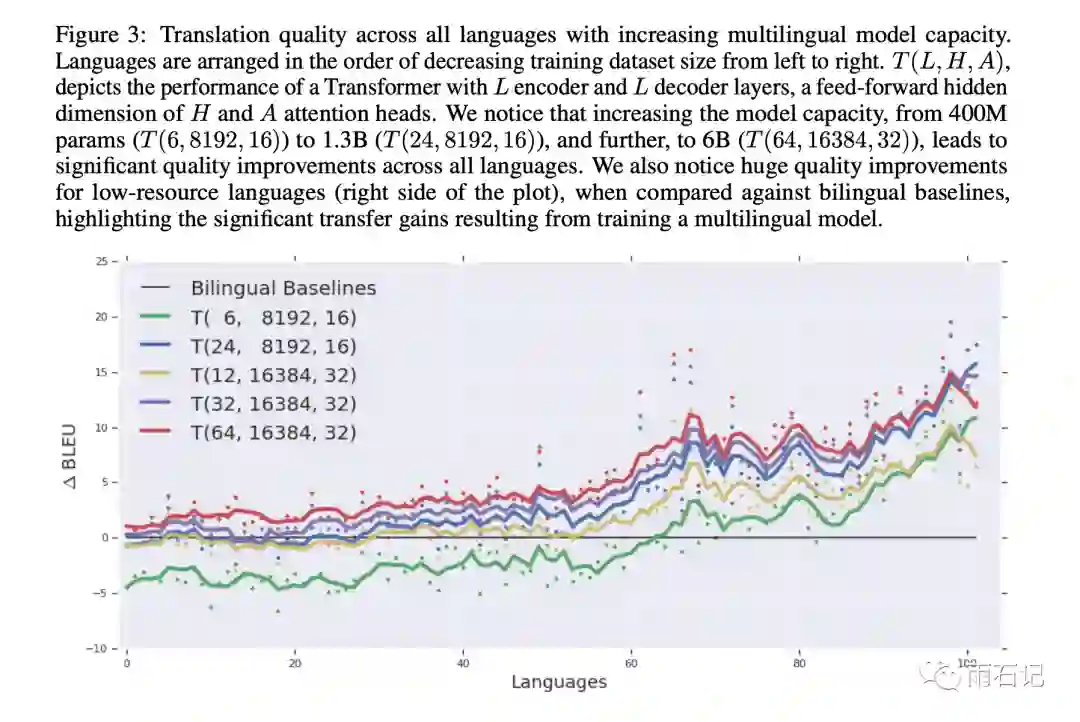
Transformer也可以在大规模多语种机器翻译任务上得到很好的效果。
总结与思考
本文介绍的GPipe通过纵向对模型切分解决了单个设备无法训练大模型的问题,又通过小批量流水线增加了多设备上的并行程度,使用re-materialization降低了单设备上的峰值。在实验中用128个TPU训练了一个83.9B参数的Transformer,非常给力。
参考文献
-
[1]. Huang, Yanping, et al. "Gpipe: Efficient training of giant neural networks using pipeline parallelism." Advances in neural information processing systems. 2019.
由于微信平台算法改版,公号内容将不再以时间排序展示,如果大家想第一时间看到我们的推送,强烈建议星标我们和给我们多点点【在看】。星标具体步骤为:
(1)点击页面最上方"AINLP",进入公众号主页。
(2)点击右上角的小点点,在弹出页面点击“设为星标”,就可以啦。
感谢支持,比心

推荐阅读
征稿启示| 200元稿费+5000DBC(价值20个小时GPU算力)
完结撒花!李宏毅老师深度学习与人类语言处理课程视频及课件(附下载)
模型压缩实践系列之——bert-of-theseus,一个非常亲民的bert压缩方法
文本自动摘要任务的“不完全”心得总结番外篇——submodular函数优化
斯坦福大学NLP组Python深度学习自然语言处理工具Stanza试用
关于AINLP
AINLP 是一个有趣有AI的自然语言处理社区,专注于 AI、NLP、机器学习、深度学习、推荐算法等相关技术的分享,主题包括文本摘要、智能问答、聊天机器人、机器翻译、自动生成、知识图谱、预训练模型、推荐系统、计算广告、招聘信息、求职经验分享等,欢迎关注!加技术交流群请添加AINLPer(id:ainlper),备注工作/研究方向+加群目的。

阅读至此了,分享、点赞、在看三选一吧🙏


