【GitHub】BERT模型从训练到部署全流程
【导读】BERT等一系列的语言模型给自然语言社区带来了长足的进步。但是,目前网上的各种资料,主要集中在模型的训练方法方面,后续的模型生产环境部署、服务调用很少有文章涉及。GitHub的xmxoxo同学有感于此,特将BERT模型从数据准备到生产部署的全流程都整理了出来,方便大家参考。对BERT感兴趣的同学,不要错过哦。
Github库:https://github.com/xmxoxo/BERT-train2deploy
作者:xmxoxo
作者个人主页:http://www.hexi5.com/
编辑报道:专知
xmxoxo同学以“情感分类”(购买手机者对该手机的评论)为例子,简要说明从训练到部署的全部流程。最终完成后可以使用一个网页进行交互,实时地对输入的评论语句进行分类判断。
【整体架构】
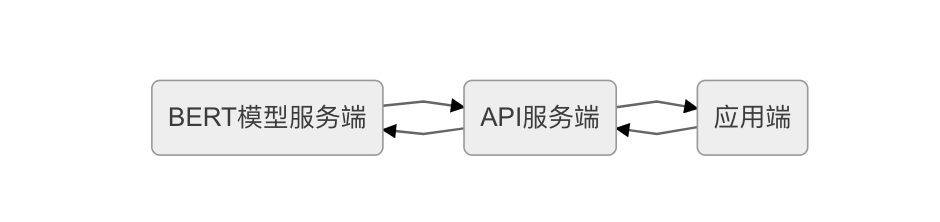
BERT模型服务端
加载模型,进行实时预测的服务;
使用的是 BERT-BiLSTM-CRF-NER
API服务端
调用实时预测服务,为应用提供API接口的服务,用flask编写;
应用端
最终的应用端:Web网页
本例中训练完成的模型文件.ckpt格式及.pb格式文件,由于比较大,已放到网盘提供下载:
链接:https://pan.baidu.com/s/1DgVjRK7zicbTlAAkFp7nWw
提取码:8iaw【关键节点】
主要包括以下关键节点:
数据准备
模型训练
模型格式转化
服务端部署与启动
API服务编写与部署
客户端(网页端的编写与部署)
数据准备
这里用的数据是手机的评论,数据比较简单,三个分类: -1,0,1 表示负面,中性与正面情感 数据格式如下:

数据总共8097条,按6:2:2的比例拆分成train.tsv,test.tsv ,dev.tsv三个数据文件
模型训练
训练模型就直接使用BERT的分类方法,把原来的run_classifier.py 复制出来并修改为 run_mobile.py。关于训练的代码网上很多,就不展开说明了,主要有以下方法:

然后添加一个方法:
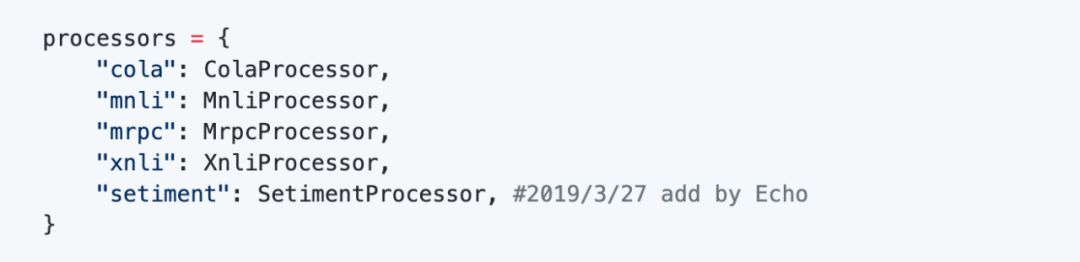
特别说明,这里有一点要注意,在后期部署的时候,需要一个label2id的字典,所以要在训练的时候就保存起来,在convert_single_example这个方法里增加一段:
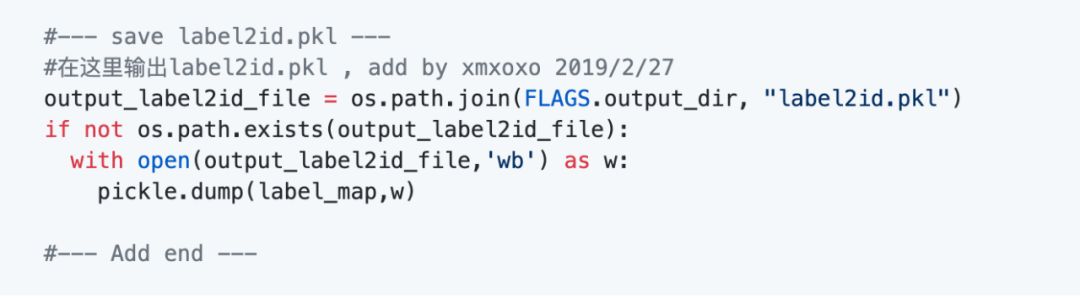
这样训练后就会生成这个文件了。
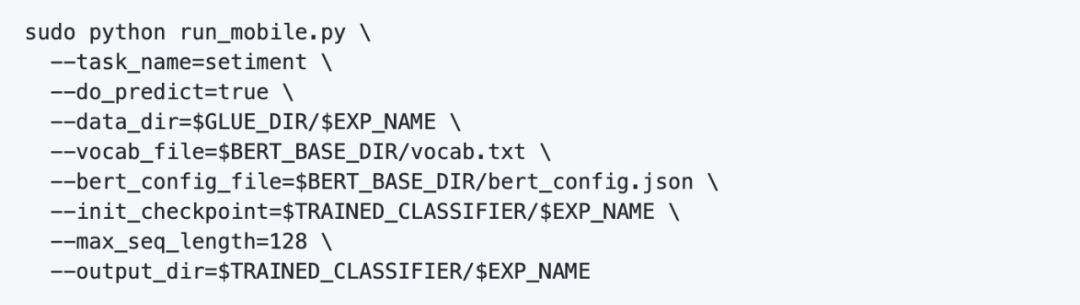
使用以下命令训练模型,目录参数请根据各自的情况修改:
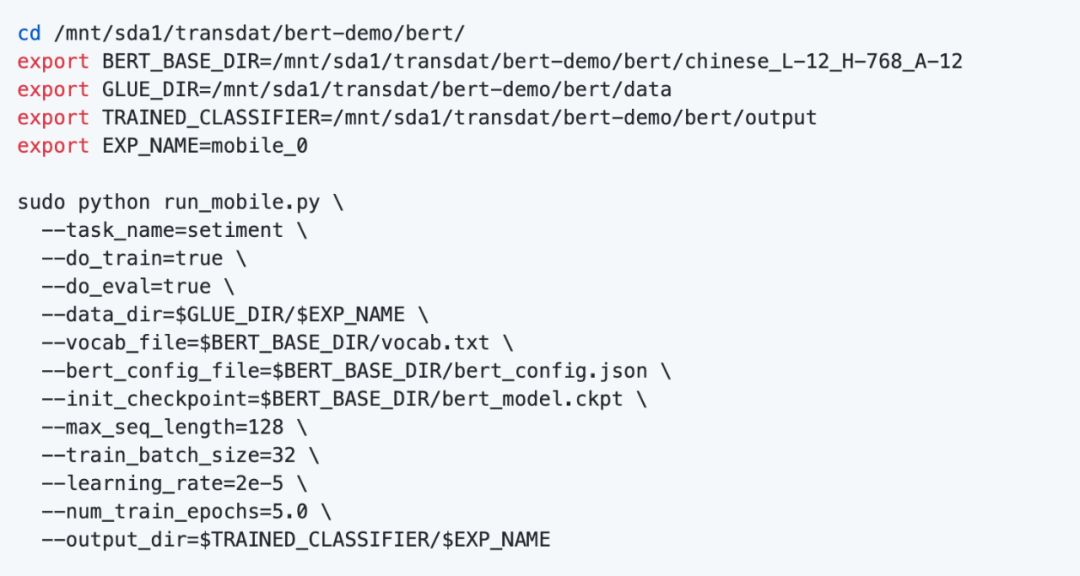
由于数据比较小,训练是比较快的,训练完成后,可以在输出目录得到模型文件,这里的模型文件格式是.ckpt的。训练结果:

可以使用以下语句来进行预测:
模型格式转化
到这里我们已经训练得到了模型,但这个模型是.ckpt的文件格式,文件比较大,并且有三个文件:

可以看到,模板文件非常大,大约有1.17G。后面使用的模型服务端,使用的是.pb格式的模型文件,所以需要把生成的ckpt格式模型文件转换成.pb格式的模型文件。我这里提供了一个转换工具:freeze_graph.py,使用如下:

这里要注意的参数是:
model_dir就是训练好的.ckpt文件所在的目录max_seq_len要与原来一致;num_labels是分类标签的个数,本例中是3个

执行成功后可以看到在model_dir目录会生成一个classification_model.pb 文件。转为.pb格式的模型文件,同时也可以缩小模型文件的大小,可以看到转化后的模型文件大约是390M。

服务端部署与启动
现在可以安装服务端了,使用的是 bert-base, 来自于项目BERT-BiLSTM-CRF-NER, 服务端只是该项目中的一个部分。项目地址:https://github.com/macanv/BERT-BiLSTM-CRF-NER ,感谢Macanv同学提供这么好的项目。
这里要说明一下,我们经常会看到bert-as-service 这个项目的介绍,它只能加载BERT的预训练模型,输出文本向量化的结果。而如果要加载fine-turing后的模型,就要用到 bert-base 了,详请请见: 基于BERT预训练的中文命名实体识别TensorFlow实现
下载代码并安装 :

或者

使用 bert-base 有三种运行模式,分别支持三种模型,使用参数-mode 来指定:
NER 序列标注类型,比如命名实体识别;
CLASS 分类模型,就是本文中使用的模型
BERT 这个就是跟bert-as-service 一样的模式了
之所以要分成不同的运行模式,是因为不同模型对输入内容的预处理是不同的,命名实体识别NER是要进行序列标注;而分类模型只要返回label就可以了。
安装完后运行服务,同时指定监听 HTTP 8091端口,并使用GPU 1来跑;
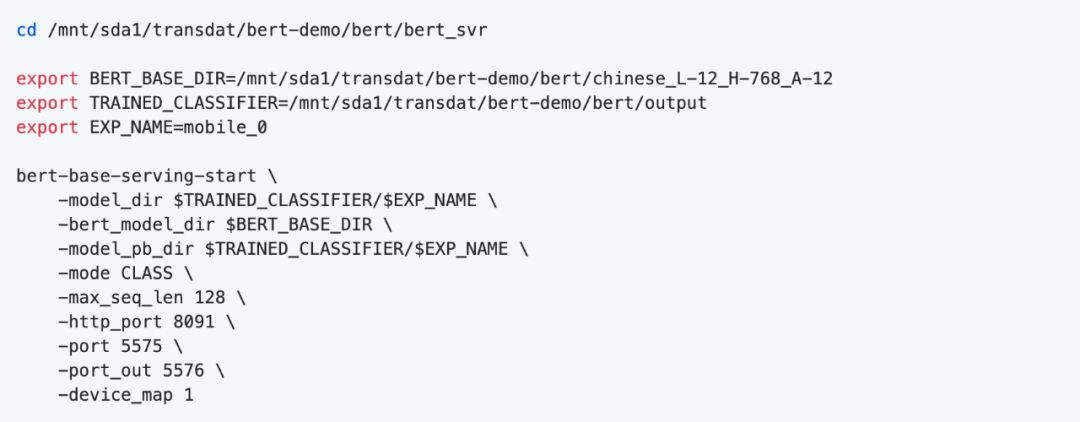
注意:port 和 port_out 这两个参数是API调用的端口号, 默认是5555和5556,如果你准备部署多个模型服务实例,那一定要指定自己的端口号,避免冲突。我这里是改为:5575 和 5576
如果报错没运行起来,可能是有些模块没装上,都是 bert_base/server/http.py里引用的,装上就好了:

我这里的配置是2个GTX 1080 Ti,这个时候双卡的优势终于发挥出来了,GPU 1用于预测,GPU 0还可以继续训练模型。
运行服务后会自动生成很多临时的目录和文件,为了方便管理与启动,可建立一个工作目录,并把启动命令写成一个shell脚本。这里创建的是mobile_svr\bertsvr.sh ,这样可以比较方便地设置服务器启动时自动启动服务,另外增加了每次启动时自动清除临时文件
代码如下:
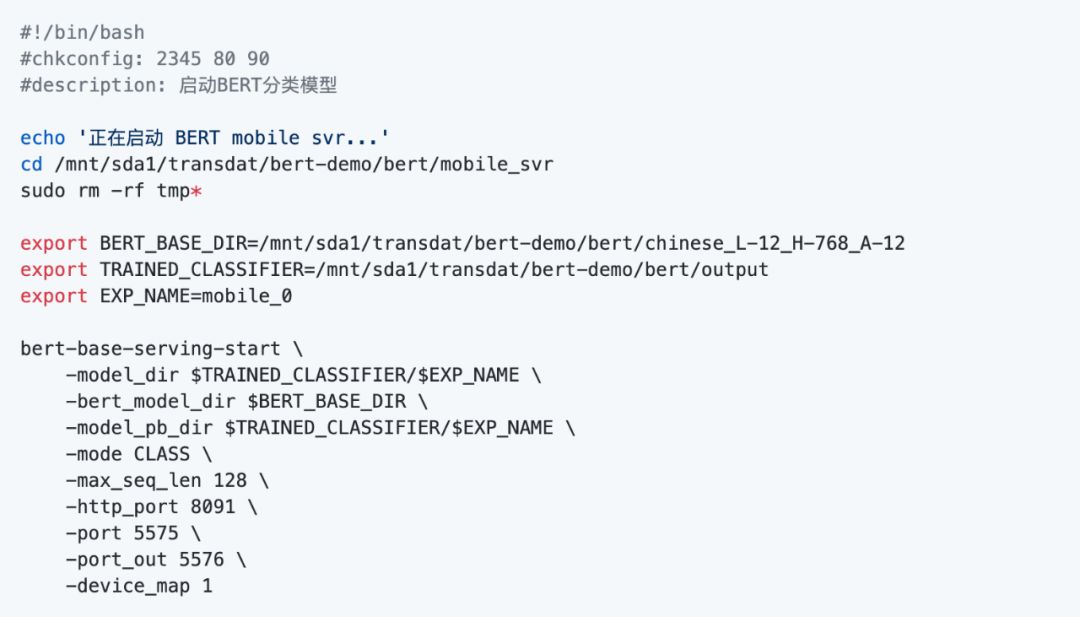
补充说明一下内存的使用情况:BERT在训练时需要加载完整的模型数据,要用的内存是比较多的,差不多要10G,我这里用的是GTX 1080 Ti 11G。但在训练完后,按上面的方式部署加载pb模型文件时,就不需要那么大了,上面也可以看到pb模型文件就是390M。其实只要你使用的是BERT base 预训练模型,最终的得到的pb文件大小都是差不多的。
还有同学问到能不能用CPU来部署,我这里没尝试过,但我想肯定是可以的,只是在计算速度上跟GPU会有差别。
我这里使用GPU 1来实时预测,同时加载了2个BERT模型,截图如下:
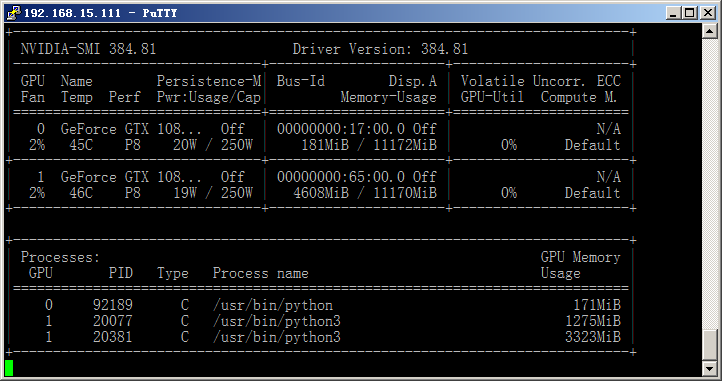
端口测试
模型服务端部署完成了,可以使用curl命令来测试一下它的运行情况。

执行结果:

可以看到对应的两个评论,预测结果一个是1,另一个是-1,计算的速度还是非常很快的。通过这种方式来调用还是不太方便,知道了这个通讯方式,我们可以用flask编写一个API服务, 为所有的应用统一提供服务。
API服务编写与部署
为了方便客户端的调用,同时也为了可以对多个语句进行预测,我们用flask编写一个API服务端,使用更简洁的方式来与客户端(应用)来通讯。整个API服务端放在独立目录/mobile_apisvr/目录下。
用flask创建服务端并调用主方法,命令行参数如下:

主方法里创建APP对象:

这里的接口简单规划为/api/v0.1/query, 使用POST方法,参数名为'text',使用JSON返回结果;路由配置:

API服务端的核心方法,是与BERT-Serving进行通讯,需要创建一个客户端BertClient:
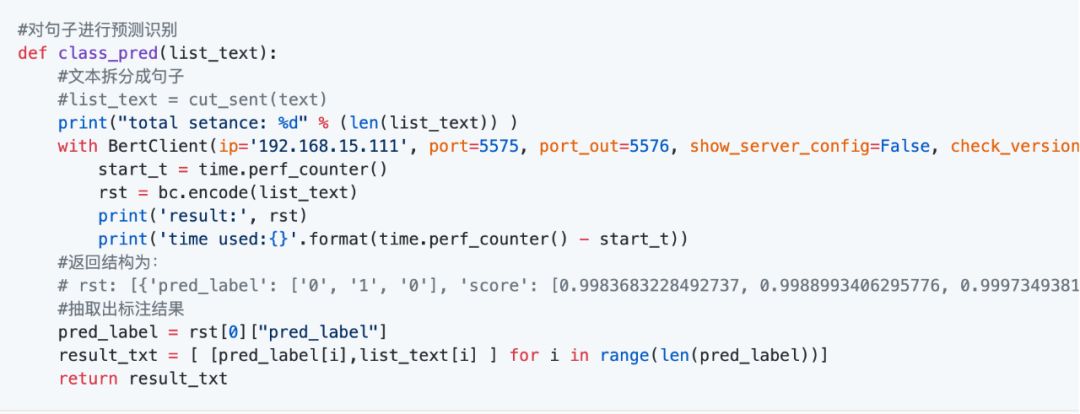
注意:这里的IP,端口要与服务端的对应。
运行API 服务端:

在代码中的debug设置为True,这样只要更新文件,服务就会自动重新启动,比较方便调试。运行截图如下:
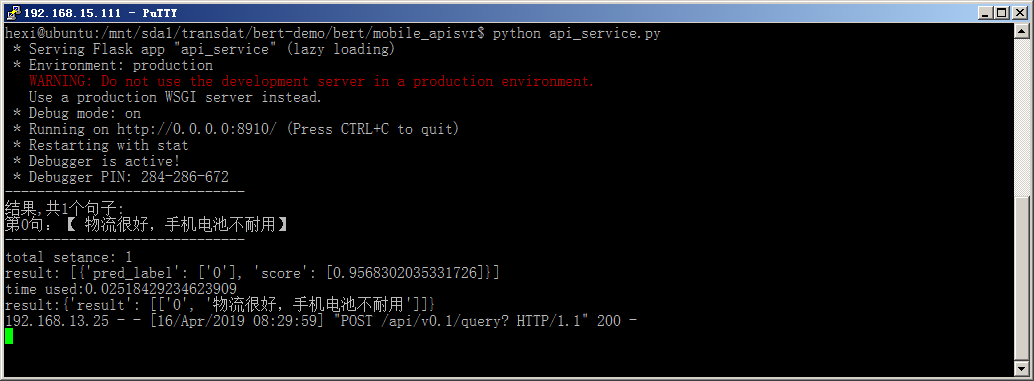
到这一步也可以使用curl或者其它工具进行测试,也可以等完成网页客户端后一并调试。我这里使用chrome插件 API-debug来进行测试,如下图:
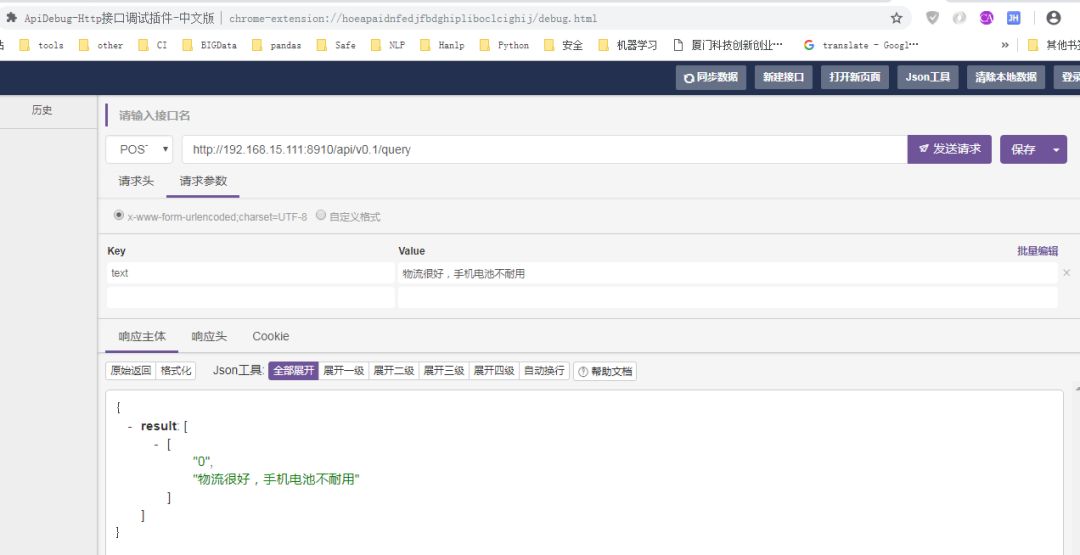
客户端(网页端)
这里使用一个HTML页面来模拟客户端,在实际项目中可能是具体的应用。为了方便演示就把网页模板与API服务端合并在一起了,在网页端使用AJAX来与API服务端通讯。
创建模板目录templates,使用模板来加载一个HTML,模板文件名为index.html。在HTML页面里使用AJAX来调用接口,由于是在同一个服务器,同一个端口,地址直接用/api/v0.1/query就可以了, 在实际项目中,客户应用端与API是分开的,则需要指定接口URL地址,同时还要注意数据安全性。代码如下:

启动API服务端后,可以使用IP+端口来访问了,这里的地址是http://192.168.15.111:8910/
运行界面截图如下:
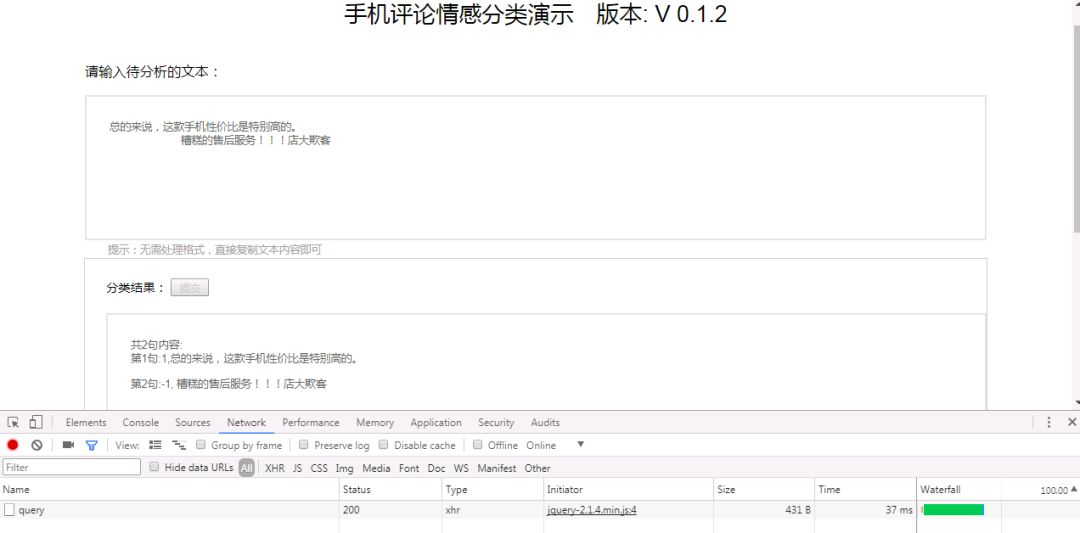
可以看到请求的用时时间为37ms,速度还是很快的,当然这个速度跟硬件配置有关。
-END-
专 · 知
专知,专业可信的人工智能知识分发,让认知协作更快更好!欢迎登录www.zhuanzhi.ai,注册登录专知,获取更多AI知识资料!

欢迎微信扫一扫加入专知人工智能知识星球群,获取最新AI专业干货知识教程视频资料和与专家交流咨询!

请加专知小助手微信(扫一扫如下二维码添加),加入专知人工智能主题群,咨询技术商务合作~

专知《深度学习:算法到实战》课程全部完成!550+位同学在学习,现在报名,限时优惠!网易云课堂人工智能畅销榜首位!

点击“阅读原文”,了解报名专知《深度学习:算法到实战》课程





