【干货】还在自己写训练过程么?你需要一个训练引擎
日常的机器学习实验工作流如下:
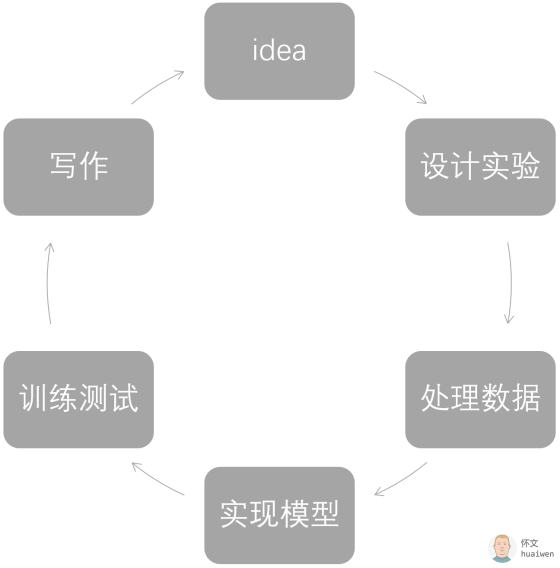
我们从一个 idea 开始,通过设计实验,处理数据,实现模型,训练和测试,最终通过写作沉淀下来。 我们知道,idea和设计实验靠个人的积累和灵感,处理数据是整个流程中相对复杂和细致的工作,而实现模型,是重中之重。当我们终于把模型构建完,我们还要训练和测试。
PyTorch典型的训练和测试的代码如下:
import torch
from torch.optim import SGD
import torch.utils.data as Data
epoch_number = 100
BATCH_SIZE = 5
# 训练,验证,测试的数据加载器
train_data_loader = get_train_data_loader()
valid_data_loader = get_valid_data_loader()
test_data_loader = get_test_data_loader()
# 模型
model = Net()
# 优化方法
optimizer = SGD(model.parameters(), lr=lr, momentum=momentum)
# 损失函数
loss_func = torch.nn.CrossEntropyLoss()
print('开始训练')
for epoch in range(epoch_number): # 训练n轮
running_loss = 0.0
for step, (batch_x, batch_y) in enumerate(train_data_loader):
# 在这里写训练代码...
optimizer.zero_grad()
pred = model(batch_x)
loss = loss_func(pred, batch_y)
loss.backward()
optimizer.step()
# 统计下 loss
running_loss += loss.item()
if i % 2000 == 1999: # 每2000个 batch输出一下
print('[%d, %5d] loss: %.3f' % (epoch + 1, i + 1, running_loss / 2000))
running_loss = 0.0
for step, (batch_x, batch_y) in enumerate(valid_data_loader):
# 在这里写验证代码...
pass
print('训练完了')
# 测试
print('开始测试')
for step, (batch_x, batch_y) in enumerate(valid_data_loader):
# 在这里写测试代码...
pass
print('测试完了')
这中间有很多事情:
• 每一个 batch的开始计算,计算过程,计算完成的输出、日志。比如以 tensorboard 的格式写下日志以待分析
• 每一个 epoch的开始计算,计算过程,计算完成的输出、日志。比如以 tensorboard 的格式写下日志以待分析
• 开始训练,结束训练的各种操作,比如加载数据,存 model 等。
• 训练过程中的各种异常等
也许你已经发现了, 上述的事情,跟模型无关!
我们完全可以把上述需求抽象出来,然后造个轮子。不过,不用自己造了,PyTorch 开源了一个叫 ignite的训练引擎,作为日常训练模型的高级 API。
让我们看一下用 ignite 训练模型是什么画风:
import torch
from torch.optim import SGD
import torch.utils.data as Data
import torch.nn.functional as F
from ignite.engines import Events, create_supervised_trainer, create_supervised_evaluator
from ignite.metrics import CategoricalAccuracy, Loss
epoch_number = 100
BATCH_SIZE = 5
# 训练,验证,测试的数据加载器
train_data_loader = get_train_data_loader()
valid_data_loader = get_valid_data_loader()
test_data_loader = get_test_data_loader()
model = Net()
optimizer = SGD(model.parameters(), lr=lr, momentum=momentum)
loss_func = torch.nn.CrossEntropyLoss()
# 训练
trainer = create_supervised_trainer(model = model,
optimizer = optimizer,
loss_fn = F.cross_entropy)
# 评估
evaluator = create_supervised_evaluator(model = model,
metrics = {
'accuracy': CategoricalAccuracy(),
'cs': Loss(F.cross_entropy)
})
# 注册事件,当一次迭代结束
@trainer.on(Events.ITERATION_COMPLETED)
def log_training_loss(engine):
# 打印训练的 log
pass
# 注册事件,当一个epoch结束
@trainer.on(Events.EPOCH_COMPLETED)
def log_training_results(engine):
# 打印训练结果
pass
# 注册事件,当一个epoch结束, 同一个事件,可以有多个处理函数
@trainer.on(Events.EPOCH_COMPLETED)
def log_validation_results(engine):
# 打印验证结果
pass
trainer.run(train_data_loader, max_epochs=epochs)
你会发现, 在使用 ignite 之后, ignite会去迭代和训练, 它会在你订阅的那些事件发生的时候,执行你写的处理函数 。 我们只需要关心我们想关心的,然后写个函数去处理就行了,比如我们关心,每一次 epoch 迭代完成,我们希望它打印一下准确率。
那么,ignite 支持哪些事件呢?
class Events(Enum):
EPOCH_STARTED = "epoch_started"
# 当一个新的 epoch 开始时会触发此事件
EPOCH_COMPLETED = "epoch_completed"
# 当一个 epoch 结束时, 会触发此事件
STARTED = "started"
# 开始训练模型是, 会触发此事件
COMPLETED = "completed"
# 当训练结束时, 会触发此事件
ITERATION_STARTED = "iteration_started"
# 当一个 iteration 开始时, 会触发此事件
ITERATION_COMPLETED = "iteration_completed"
# 当一个 iteration 结束时, 会触发此事件
EXCEPTION_RAISED = "exception_raised"
# 当有异常发生时, 会触发此事件
满足了日常所有的需求了。
ignite 的状态也记录了日常所需的信息:
class State(object):
def __init__(self, **kwargs):
self.iteration = 0
# 记录 iteration
self.output = None
# 当前 iteration 的 输出. 对于 Supervised Trainer 来说, 是 loss.
self.batch = None
# 本次 iteration 的 mini-batch 样本
for k, v in kwargs.items():
# 其它一些希望 State 记录下来的 状态
setattr(self, k, v)
该项目主页是:
https://github.com/pytorch/ignite ,
你可以在下面链接中看见更多例子。
https://github.com/pytorch/ignite/tree/master/examples
专知成员Huaiwen以前推出一系列PyTorch教程:
【最新PyTorch0.4.0教程01】PyTorch的动态计算图深入浅出
不只是支持Windows, PyTorch 0.4新版本变动详解与升级指南
更多教程资料请访问:人工智能知识资料全集
-END-
专 · 知
人工智能领域主题知识资料查看与加入专知人工智能服务群:
【专知AI服务计划】专知AI知识技术服务会员群加入与人工智能领域26个主题知识资料全集获取

[点击上面图片加入会员]
请PC登录www.zhuanzhi.ai或者点击阅读原文,注册登录专知,获取更多AI知识资料!

请加专知小助手微信(扫一扫如下二维码添加),加入专知主题群(请备注主题类型:AI、NLP、CV、 KG等)交流~

请关注专知公众号,获取人工智能的专业知识!




