【GNN】Cluster-GCN:一个简单又有效的 Trick

今天学习的是 Google 2019 年的工作《Cluster-GCN: An Efficient Algorithm for Training Deep and Large Graph Convolutional Networks》,发表于 KDD 2019。
目前,GCN 已经成功应用于各个领域,但是大规模的 GCN 训练仍然是一个非常大的挑战。目前基于 SGD 优化的 GCN 算法要么面临着随着层数呈指数增长的计算成本,要么面临着保存整个图和节点 Embedding 的巨大内存需求。
针对这个问题,作者提出了一种适用于基于 SGD 训练新的图聚类结构——Cluster-GCN。其核心思想是先利用图聚类算法来区分子图进行采样,并限制该子图中的邻居搜索。这种策略虽然简单,但是对提高内存和计算效率而言非常有效,同时也能够保证算法的精度。
为了测试算法的可扩展性,作者创建了一个新的 Amazon 数据集,比之前的 Reddit 大五倍,并在该数据集上取得了更快、更少内存。此外,随着层数增加,Cluster-GCN 的预测精度也取得了 SOTA 的成绩。
1.Introduction
由于节点的依赖性,GCN 的训练需要消耗大量内存来计算图上节点的 Embedding。
一些经典模型如 GCN 采用了 full-batch 的 SGD 优化算法,要计算整个梯度则需要存储所有中间的 Embedding,因此,其是不可扩展的。此外,虽然每个 epoch 也只能更新一次参数。
GraphSAGE 中提出 mini-batch 的 SGD 优化方法,由于每次更新只基于一个 mini-batch,所以内存的需求降低,并在每个 epoch 中可以进行多次更新,从而收敛速度更快。然而,随着层数加深,每个节点的感受野越来越大,其计算单个节点的计算开销也会越来越大。针对这个问题,GraphSAGE 通过使用固定大小的邻居采样,同时 FastGCN 的重要性采样可以一定程度上解决计算开销,但是随着 GCN 的深度加深,计算开销问题依然没法解决。
VR-GCN 提出利用方差来控制邻居的采样节点,尽管减少了采样的大小,但是它需要将所有节点的中间 Embedding 存储于内存中,导致其可扩展性较差。
下表展示了不同模型的时间复杂度和空间复杂度:
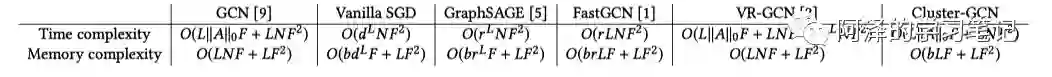
作者在实验中发现 mini-batch 的算法效率与 batch 内节点与 batch 外节点间的连接数量成正比,针对这一现象,作者构造了节点的分区,使同一分区中的节点之间的图连接于不同分区中的节点之间的图连接更多。
在此基础上,作者提出了基于图聚类结构的新算法——Cluster GCN,并设计了一个随机多聚类框架(「stochastic multi-clustering framework」)来提高 Cluster-GCN 的收敛性,从而降低了内存消耗和计算消耗。
2.Cluster-GCN
我们知道,基于 mini-batch 的 SGD 可以在单个 epoch 中更新多次,从而使得其比 full batch 具有更快的收敛速度,但是前者每个 epoch 所花的时间都更长。
出现这种情况主要是 SGD 在训练时引入额外的计算开销,我们简单介绍下。
首先给出 SGD 的计算公式:
在计算节点 i 相关梯度时,需要节点 i 的 Embedding,而其计算需要依赖前一层邻居的 Embedding,而前一层的节点的 Embedding 需要前前一层的邻居节点的 Embedding,并如此嵌套下去,直至第一层。
考虑每个节点平均度数为 d,GCN 网络有 L 层,为了获取节点 i 相关的梯度需要对途中节点聚合 个节点的特征。也就是说需要获取途中节点的 hop-k(k=1,..,L)邻居的信息来执行一次更新。此外,还需要和权重矩阵 相乘,所以每次计算 Embedding 还需要 的时间,所以综合起来平均计算一个节点相关的梯度的时间复杂度为 。
如果一个 batch 包含多个节点,那么时间复杂度就没那么直观了,因为不同节点可能会有重叠的 hop-k 邻居,并且 Embedding 计算的数量可以小于最坏情况 。为了反映 mini-batch SGD 的计算效率,作者定义了 Embedding utilization 的概念来表达计算效率。
如果节点 i 在第 l 层的 Embedding 在计算第 l+1 层计算时被重用了 u 次,那么就说 的 Embedding utilization 为 u。
对基于随机抽样的 mini-batch SGD 而言,由于图通常比较大且稀疏,所以 u 通常非常小,所以 mini-batch SGD 需要计算每个 batch 的 个 Embedding,这将导致每次更新时间复杂度为 ,epoch 的时间复杂度为 。
full batch 梯度下降具有最大的 Embedding utilization——每个 Embedding 将在上层重复使用 d 次。因此,full-batch 的每个 epoch 只需要计算 个 Embedding,这就意味着只需要计算 个 Embedding 就可以计算一个节点的梯度。
针对这样一种现象,作者为了最大化 Embedding utilization,设计了 Cluster-GCN,旨在设计一个 batch 来最大化 batch 内边的数量。
2.1 Vanilla Cluster-GCN
对于一个图 G 而言,将其分为 c 组:
其中, 只包含 中节点之间的边。
对节点进行重组后,邻接矩阵被划分为 个子矩阵:
其中:
其中, 为子图 的内在邻接矩阵; 为图 的邻接矩阵; 为 A 的所有非对角块组成的矩阵; 为 和 之间组成的邻接矩阵。
类似的,也可以对特征矩阵 和训练标签 按照子图进行划分。
损失函数也被分解为:
Cluster-GCN 便是基于上面的公式,在每一步中,先对矩阵 进行采样,然后根据 的梯度进行 SGD 更新,这里只需要当前 batch 上的子图的邻接矩阵 、特征矩阵 、标签向量 和权重矩阵 。这相比于之前的 SGD 训练所使用的邻接采样更容易实现,速度也更快。
作者使用 Metis 和 Craclus 等聚类算法在图中的的顶点上构建分区,使簇内连接大于簇间链接,从而得到更好的聚类和社区结构。
划分簇的意义在于:
-
对于每个 batch 而言,Embedding utilization 相当于簇内的连接。每个节点及其相邻节点通常位于同一簇内,因此经过几次后跳跃后,邻接节点大概率还是在簇内; -
利用 来代替 ,误差与簇间的的连接成正比,所以需要使得簇间的连接数量尽可能少。
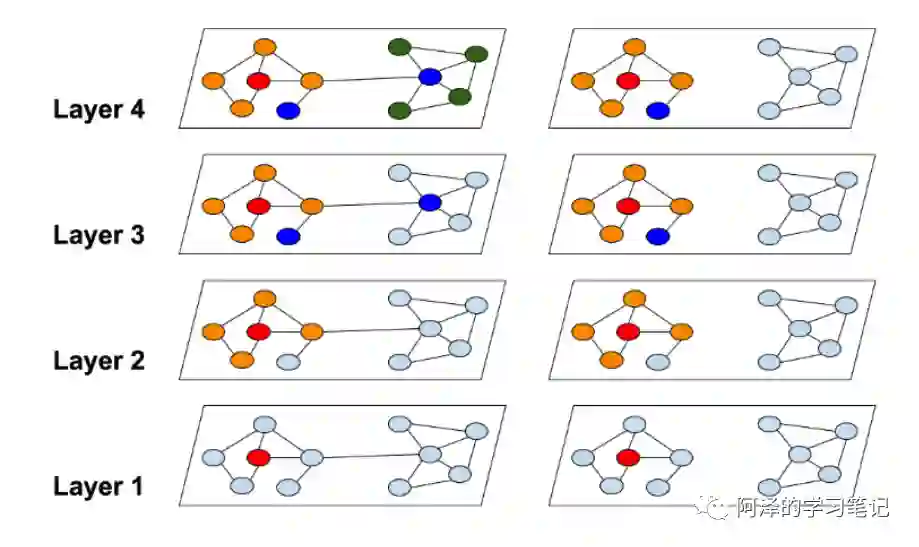
下图为全图 和聚类分区图 :
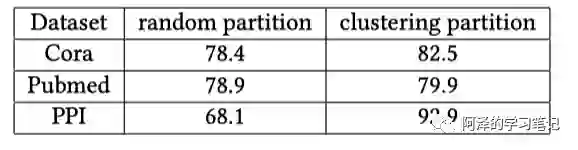
下表为两种不同数据集的分区策略(随机和 metis)及对应的训练精度,可以看到聚类划分还是很有必要的。
2.2 Stochastic Multiple Partitions
尽管 vanilla Cluster-GCN 能够减少计算开销和内存开销,但仍然存在两个问题:
-
图被分割后, 中的一些连接会被删除,影响性能; -
聚类后的分布会与原始数据集有区别,从而导致 SGD 更新时有偏差。
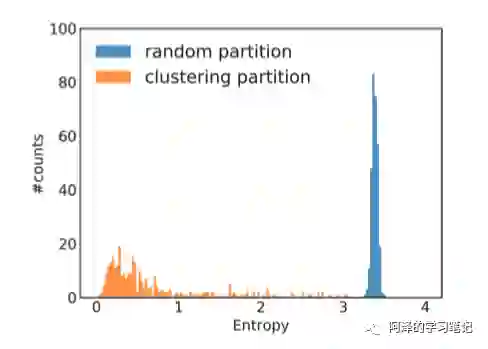
下图为 Reddit 数据集中标签分布不平衡的案例,通过每个簇的标签分布计算其熵值,与随机分割相比,可以清楚的看到聚类分区的簇的熵较小,这表明簇的标签分布偏向于某些特征的标签,所以这会增加不同 batch 的梯度更新的差异,并影响 SGD 的收敛性。
为了解决这个问题,作者提出随机多聚类方法(stochastic multiple clustering)对簇进行合并,从而减少 batch 间的差异。
作者首先将图分为多个小簇,然后随机选择 q 个簇并到 batch 中,这样便可以减少 batch 之间的差异。
下图展示了每个 epoch 随机组合的 batch:
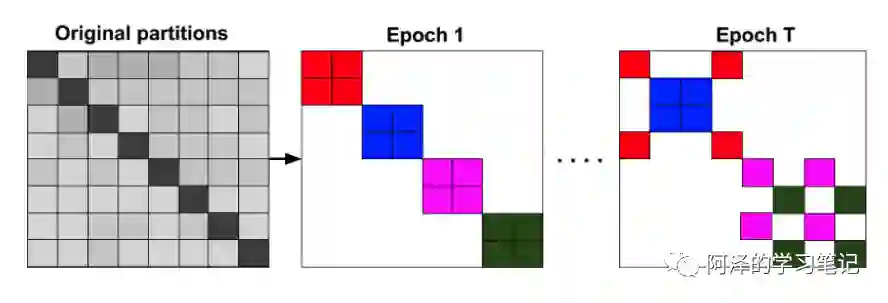
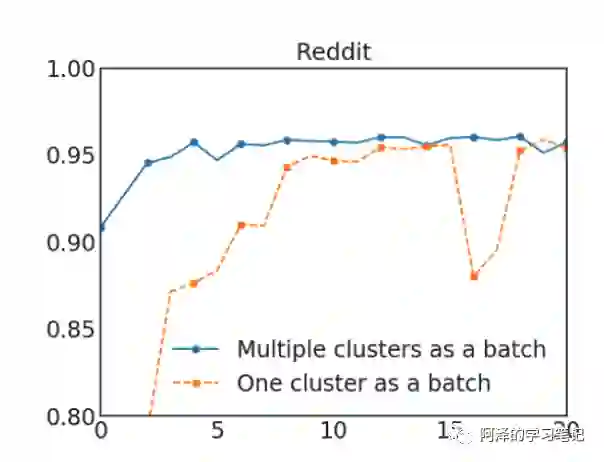
下图两种方式的对比,随机多聚类方法的收敛速度更快:
2.3 Issues of training deeper GCN
作者提出了一个简单的技术来改进深度 GCN 的训练,核心思想在于放大每个 GCN 层中使用的邻接矩阵 A 的对角部分,并通过这种方式在每个 GCN 层的聚合中对上一层的 Embedding 添加更多的权重:
但这种方法有些问题,比如这种方法无视相邻节点的数量,而对所有节点使用相同的权重。此外,当层数增加时,其数值可能会呈现指数型爆炸。
所以作者先对邻接矩阵进行标准化:
然后考虑:
这种新的标准化策略达到了 SOTA 的效果。
3.Experiment
简单看一下实验。
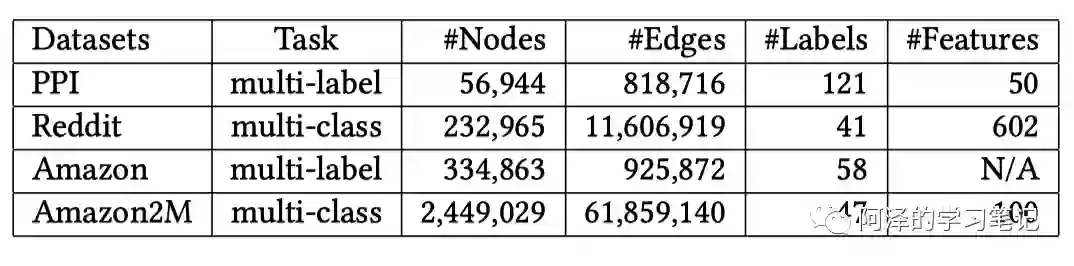
首先是数据集:
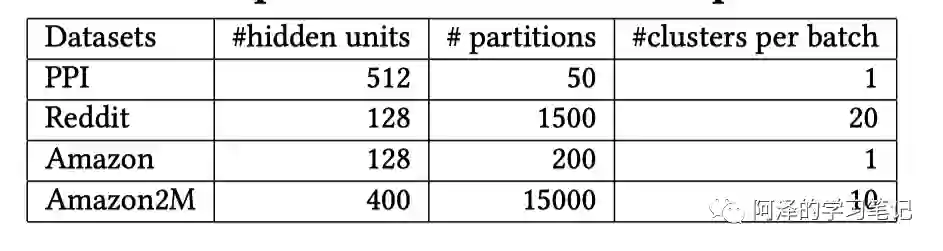
实验所用参数:
不同数量的隐藏层下的模型内存消耗:

训练时间和准确度:
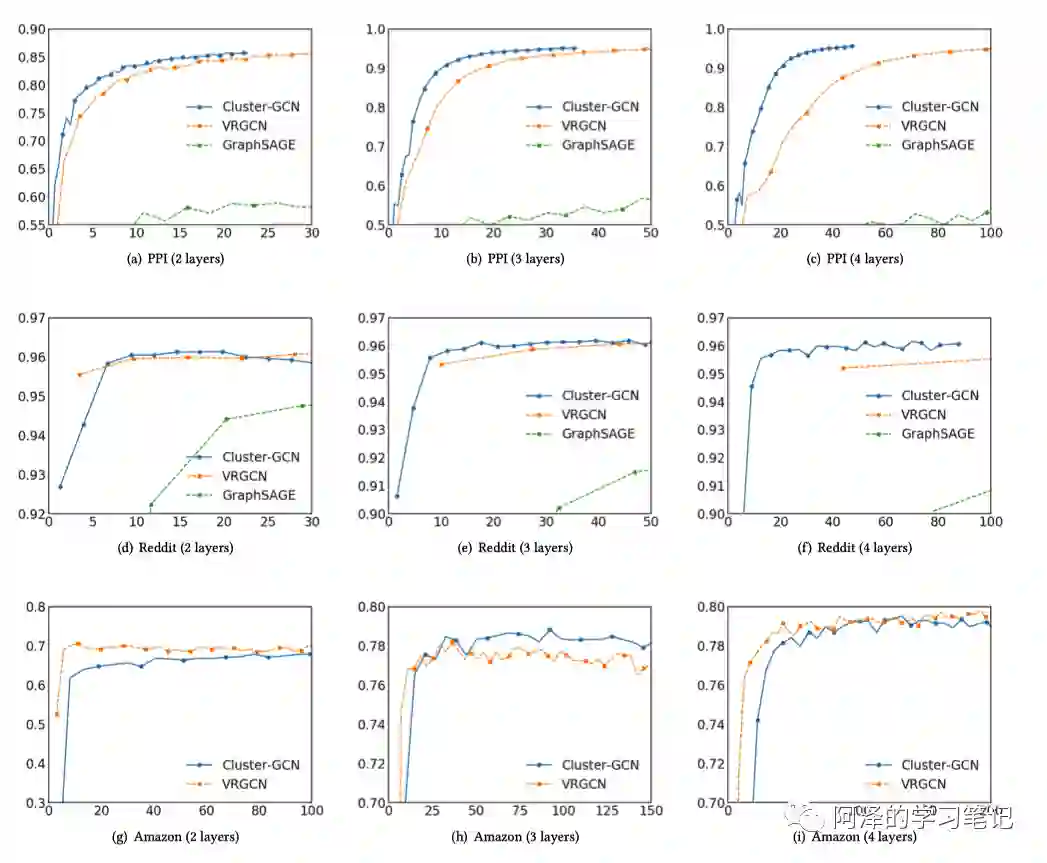
在大数据集下实验:

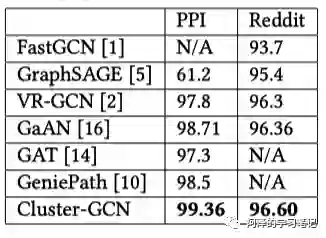
诸多模型的测试精度:
4.Conclusion
本文提出了一种新的训练算法 Cluster-GCN,核心思想在于利用聚类算法将大图划分为多个簇,划分遵循簇间连接少而簇内连接多的原则,这种简单的方法有效的减少了内存和计算资源的消耗,同时也能取得非常好的预测精度。
5.Reference
-
《Cluster-GCN: An Efficient Algorithm for Training Deep and Large Graph Convolutional Networks》 -
benedekrozemberczki/ClusterGCN -
google-research/cluster_gcn
推荐阅读
征稿启示| 200元稿费+5000DBC(价值20个小时GPU算力)
文本自动摘要任务的“不完全”心得总结番外篇——submodular函数优化
斯坦福大学NLP组Python深度学习自然语言处理工具Stanza试用
关于AINLP
AINLP 是一个有趣有AI的自然语言处理社区,专注于 AI、NLP、机器学习、深度学习、推荐算法等相关技术的分享,主题包括文本摘要、智能问答、聊天机器人、机器翻译、自动生成、知识图谱、预训练模型、推荐系统、计算广告、招聘信息、求职经验分享等,欢迎关注!加技术交流群请添加AINLPer(id:ainlper),备注工作/研究方向+加群目的。

阅读至此了,分享、点赞、在看三选一吧🙏


