从ICLR 2020、AAAI 2020看对话系统近期研究进展

©PaperWeekly 原创 · 作者|王馨月
学校|四川大学本科生
研究方向|自然语言处理

ICLR 2020


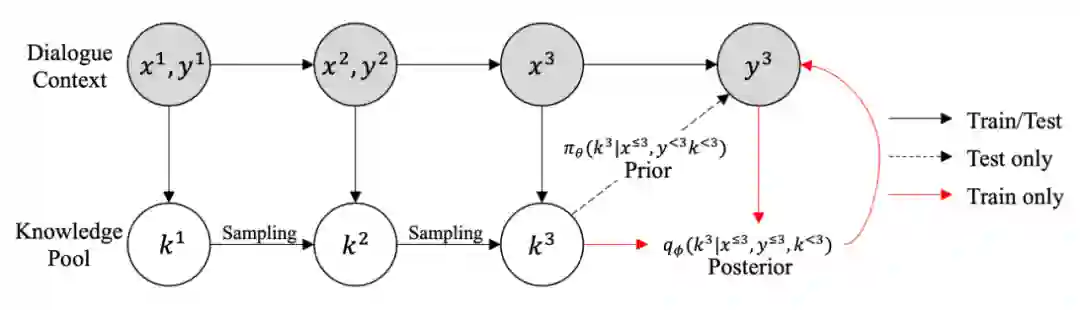
基于知识是一项结合上下文和外部知识生成有效回复的任务,一般通过更好地建模多轮基于知识的对话中的知识来提升。主要分为两步:1)知识选择;2)根据选择出的知识以及上下文生成回应。不同于 TextQA 任务,基于知识的对话系统中上下文与要选择的知识之间是一对多的关系。
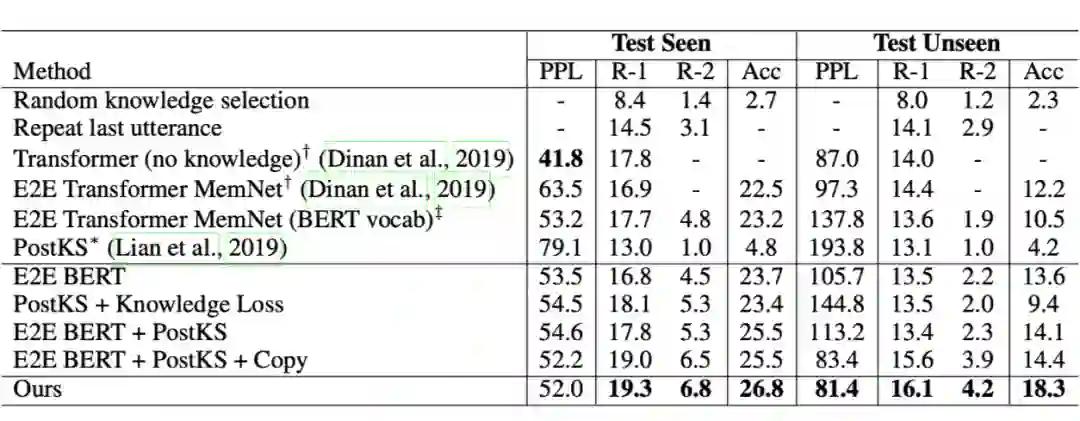
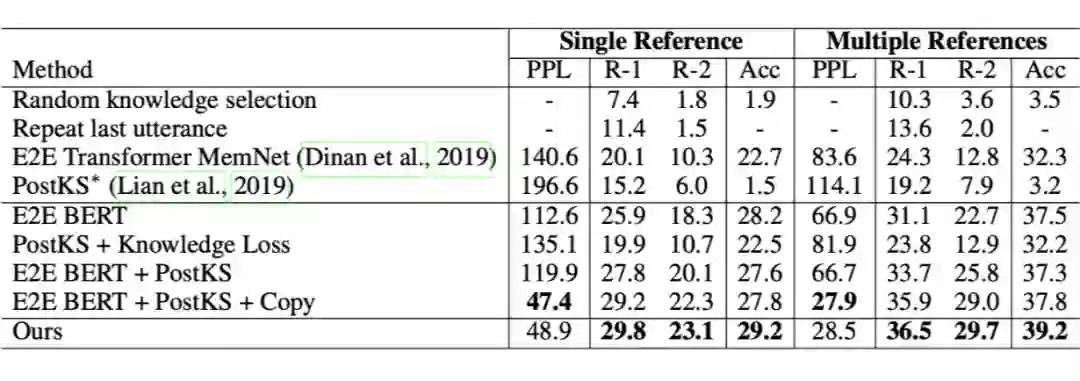
因此,文章将序列潜在变量模型引入知识选择过程,提出了 sequential knowledge transformer (SKT)。将知识选择看作序列决策过程,根据多轮的潜在变量,联合推断出要选择的知识,因此不仅能减少知识提取的多样化造成的歧义,还能够促使回复过程选择合适的知识。在 Wizard of Wikipedia 上达成 SOTA 性能。
模型由三部分构成:句子编码器用 BERT 和 average pooling 实现;序列知识选择用 SKT 实现;解码器用 Transformer 的 Decoder 结合 Copy 机制实现。
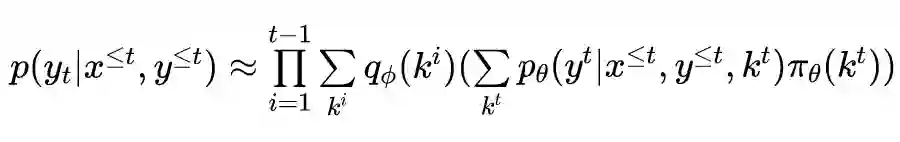


论文标题:Low-Resource Knowledge-Grounded Dialogue Generation
论文来源:ICLR 2020
论文链接:https://arxiv.org/abs/2002.10348

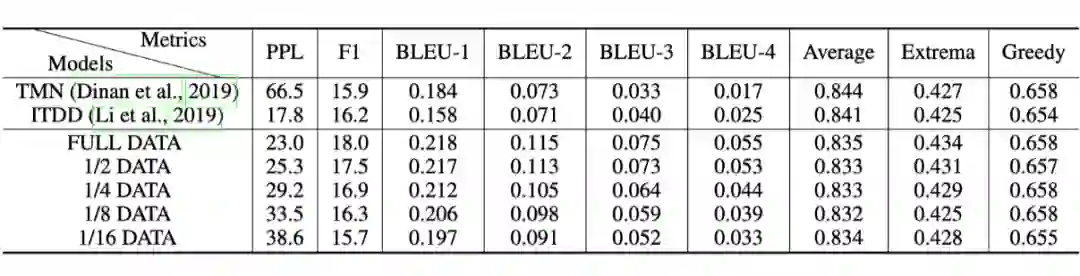
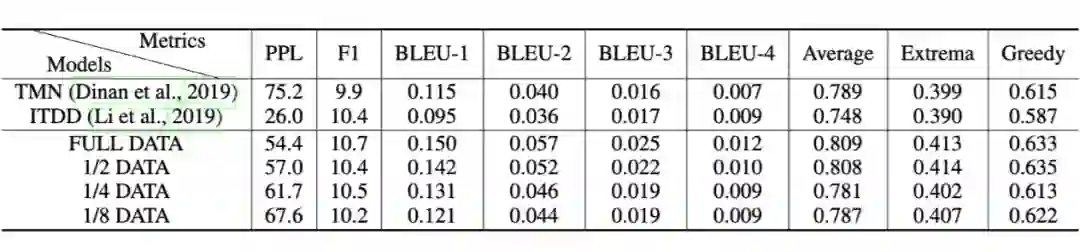
在开放域对话系统中,目前大多数模型只能拟合小规模训练数据,而基于知识对话的知识也很难获取。因此,文章在缺少资源的假定下,设计了 disentangled response decoder,将依赖于基于知识的对话的参数从整个模型中分离分离。
通过这种方法,模型的主要部分可以从大规模的非真实对话以及非结构化文本中训练,而其余的很少一部分参数则可以用有限的训练数据拟合。在两个基准上实验的结果显示只用 1/8 的训练数据,模型就能达到 SOTA 性能并生成很好的跨领域知识。
文章将生成回应的问题分解为 3 个不相关的行为:1) 根据已生成的部分选择合适的词使得句子语法正确(符合语言模型);2) 根据上下文选择合适的词使得对话连贯(符合上下文处理器);3) 根据对话基础上的外部知识选择合适的词(符合知识处理器)。
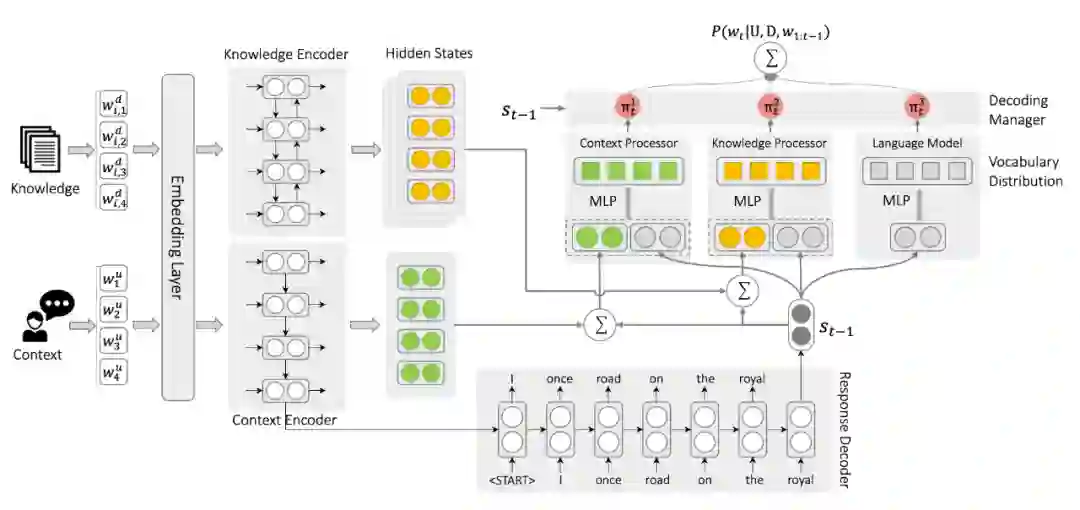
相较传统模型,主要的区别在作者通过将 decoding 过程分解为一个语言模型、一个上下文处理器、一个知识处理器,以模拟上述三个步骤。
-
语言模型:语言模型基于 通过一个 MLP 进行词的预测。 上下文处理器:通过一个 MLP 结合注意力分布权衡预测单词来自词汇表或上下文。
-
知识处理器:知识处理器通过多层注意力机制(此处使用了 sentence-level 和 word-level)通过和上下文处理器类似的方式预测单词。



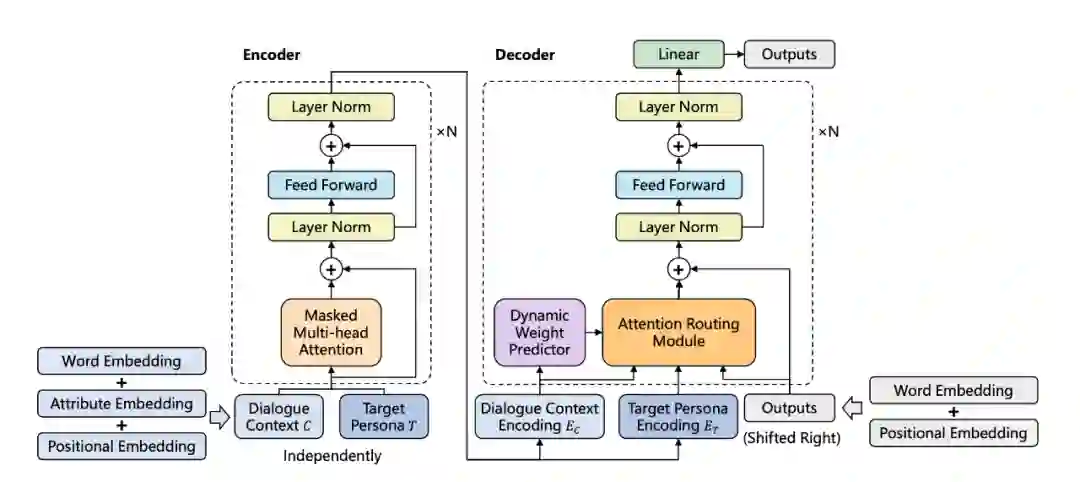
在这篇文章中,作者指出,让模型生成更加 human-like 的回复是对话系统中非常重要的问题,但由于自然语言中难以适当地添加角色信息,且真实生活中大多数对话中是缺少角色信息的(persona-sparse),使得这一问题更加艰难。
而角色信息相关的数据集如 PERSONA-CHAT,则由于构造时对话者被要求在很少轮中显示性格而包含了过多个人信息(persona-dense),这一点不符合真实情况。
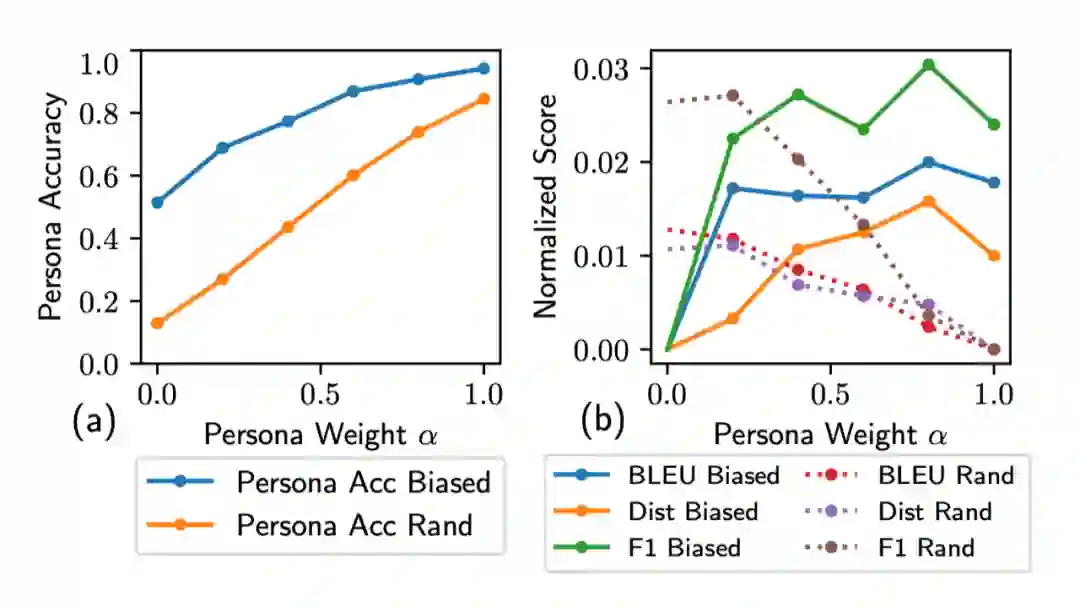
针对这一问题作者提出了可以在 persona-sparse 数据集上训练的预训练模型,并提出了一种注意力路由机制(attention routing mechanism)以在 decoder 中动态预测权重。实验结果显示此模型可以很好地生成连贯且 persona-related 的回应。
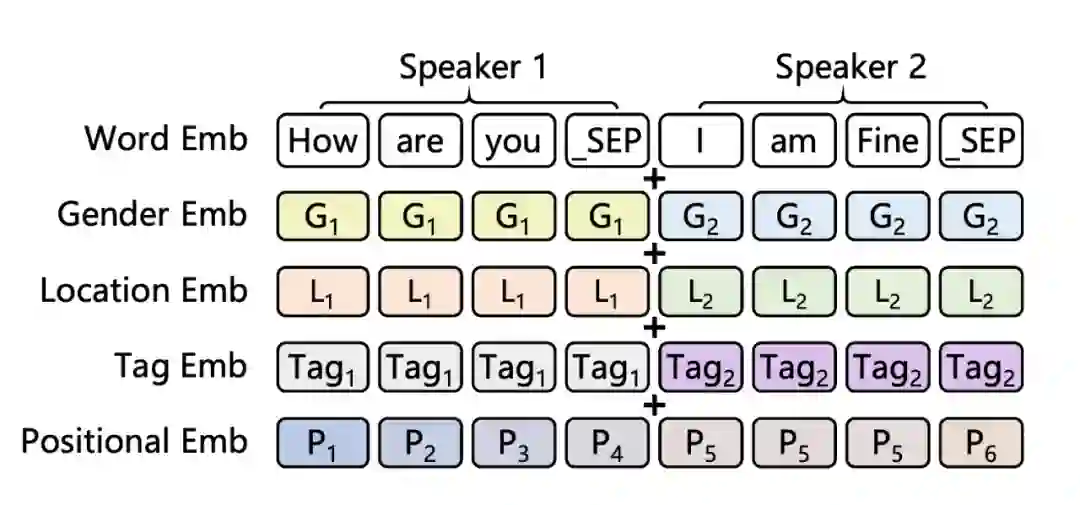
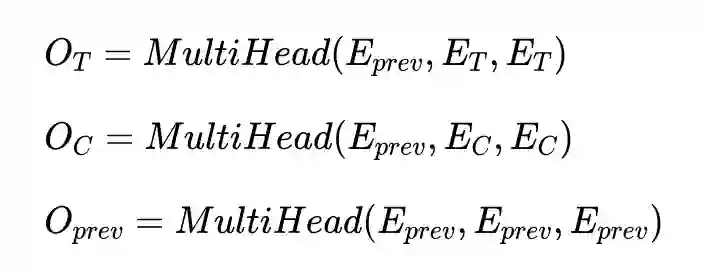
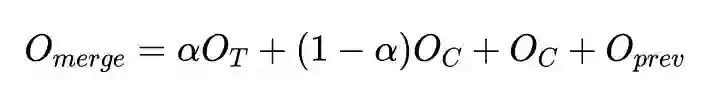




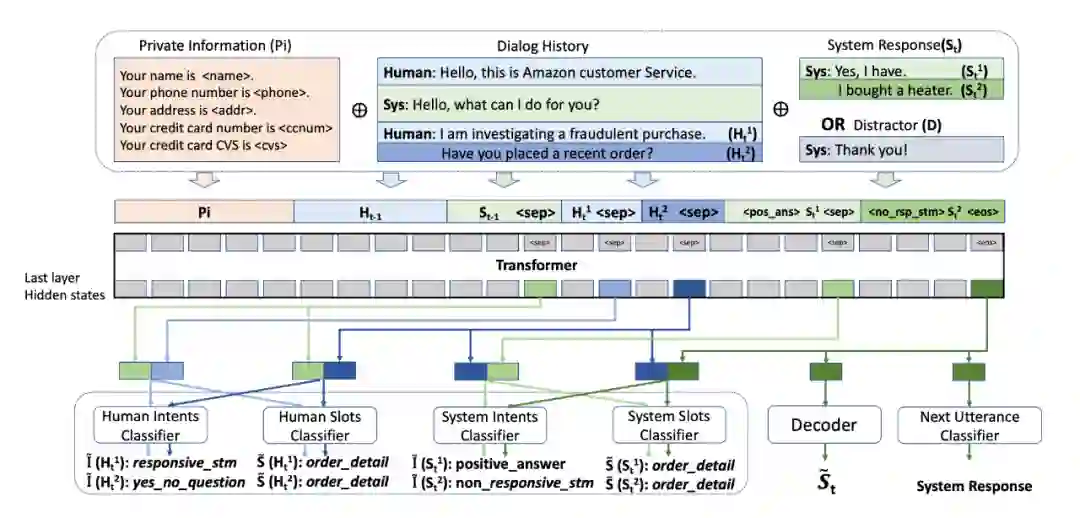
MISSA 在 ANTISCAM 数据集的训练过程如上图所示。作者在 TransferTransfo 的基础上主要做的改变为:
TramsferTransfo: Transformer 模型在对话生成方面的应用,将 Transformer 的 segement embedding 变为 dialogue state embedding 以标注意图和对话状态。
第 t 轮的 Intent classifier 和 semantic slot classifier 根据第 t-1 轮的最后一句的最后一个隐藏状态和第 t 轮第 i 个句子的最后一个隐藏状态加权求 Softmax 得到。
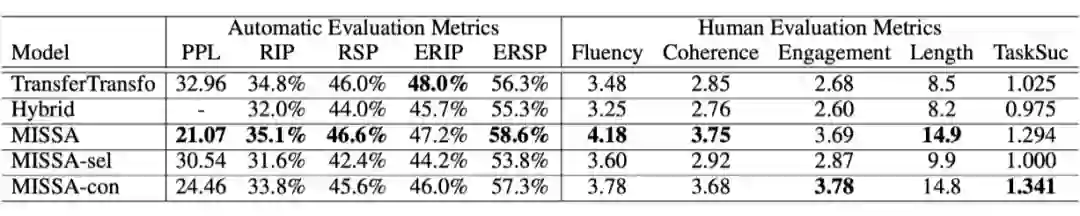

ICLR 2020


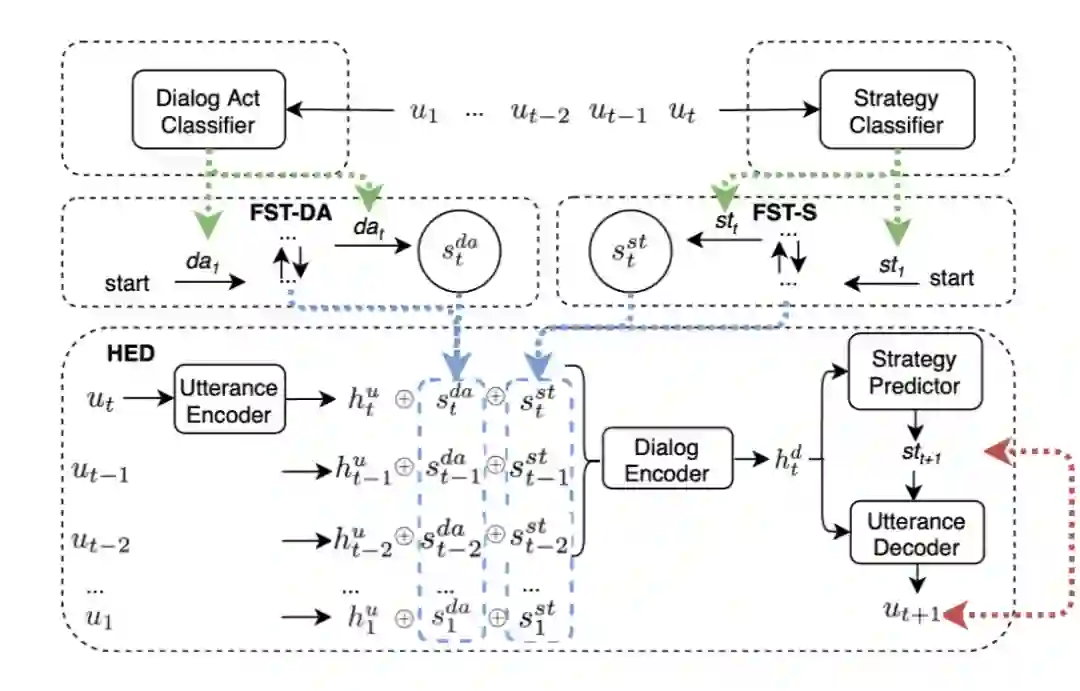
这篇文章同样是针对 Non-collabratibe 的情况,提出了利用有穷状态转换器(finite state transducers, FSTs)构造的模型 FeHED (FST-enhanced hierarchical encoder-decoder model),用于建模对话中的语义和策略 history。
如下图所示,FeHED 模型主要由四个部分组成:一个对话动作分类器、一个策略分类器、两个 FST(FST-DA/S),以及一个层次 encoder-decoder 模型(HED)。
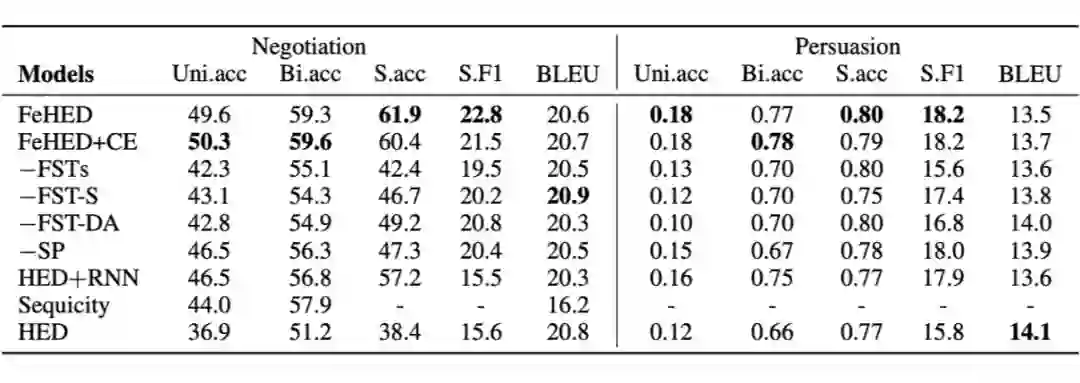

AAAI 2020 上 Google 团队发表了一篇论文 Towards Scalable Multi-Domain Conversational Agents: The Schema-Guided Dialogue Dataset,介绍了数据集 SGD (Schema-Guided Dialogue)。





对话系统的论文数量虽然在各个会议中占比不算很高,但可以看出,还是有一些很有趣的想法。比如在第一篇文章中对 latent variable model 进行改进在解决回复多样性的同时使得知识选择更加准确。
而在第二篇文章中针对低资源的问题将语言模型、上下文与知识分离开,使得仅用 1/8 真实数据情况就能达到很好的性能。
而第三第四篇文章都对于对话系统的个性化作出了不同的尝试,其中第三篇文章很有新意地将人物信息加入 encoding,第四、第五篇文章则考虑到日常生活中更多对话是非协作的情形作出了尝试。
点击以下标题查看更多往期内容:
-
任务导向型对话系统——对话管理模型研究最新进展
-
超详综述 | 基于深度学习的命名实体识别
-
复旦大学邱锡鹏教授:NLP预训练模型综述
-
BERT在小米NLP业务中的实战探索
-
针对复杂问题的知识图谱问答最新进展
-
从三大顶会论文看百变Self-Attention

#投 稿 通 道#
让你的论文被更多人看到
如何才能让更多的优质内容以更短路径到达读者群体,缩短读者寻找优质内容的成本呢?答案就是:你不认识的人。
总有一些你不认识的人,知道你想知道的东西。PaperWeekly 或许可以成为一座桥梁,促使不同背景、不同方向的学者和学术灵感相互碰撞,迸发出更多的可能性。
PaperWeekly 鼓励高校实验室或个人,在我们的平台上分享各类优质内容,可以是最新论文解读,也可以是学习心得或技术干货。我们的目的只有一个,让知识真正流动起来。
📝 来稿标准:
• 稿件确系个人原创作品,来稿需注明作者个人信息(姓名+学校/工作单位+学历/职位+研究方向)
• 如果文章并非首发,请在投稿时提醒并附上所有已发布链接
• PaperWeekly 默认每篇文章都是首发,均会添加“原创”标志
📬 投稿邮箱:
• 投稿邮箱:hr@paperweekly.site
• 所有文章配图,请单独在附件中发送
• 请留下即时联系方式(微信或手机),以便我们在编辑发布时和作者沟通
🔍
现在,在「知乎」也能找到我们了
进入知乎首页搜索「PaperWeekly」
点击「关注」订阅我们的专栏吧
关于PaperWeekly
PaperWeekly 是一个推荐、解读、讨论、报道人工智能前沿论文成果的学术平台。如果你研究或从事 AI 领域,欢迎在公众号后台点击「交流群」,小助手将把你带入 PaperWeekly 的交流群里。






