ACL2020论文:使用强化学习为机器翻译生成对抗样本
来自:南大NLP

01
—
背景介绍
对抗样本(adversarial example)是近年来用于探索深度学习系统鲁棒性的重要工具。对抗样本通过对普通测试输入进行微小扰动(以不改变人期望输出为准),并以劣化系统输出为目标得到。
当前神经机器翻译(neural machine translation, NMT)系统在实用场合常常会出现用户难以预计的错误,这些错误甚至存在消极的社会影响。而基于用户反馈进行的维护通常也是在这些错误产生后才能进行,开发者更希望在上线前就能进行大量的测试进行预防性维护。直接的鲁棒性测试通常需要专家编制大量对应的测试数据并进行标注,但对于机器翻译这类任务而言成本过高。因此我们可以通过利用已有平行句对的输入产生对抗样本的方式,沿用原本的输出,从而快速得到大量可用于鲁棒分析的平行数据。
图1: 对人名的变动影响了翻译的预期结果(此样例当前已被修复)
02
—
文本对抗样本及难点
对抗样本的两个核心为:保持语义限制,同时达成系统性能恶化。不同于图像处理(computer vision, CV)的对抗样本由直接使用梯度优化的方法得到,文本由于其表示的离散性质无法直接套用。当前生产文本对抗样本的模式分为两大类:
对图像对抗样本生成方法的离散化改进。即将文本嵌入(embedding)视为图像的像素输入,使用k-PGD(k round of projected gradient descent)寻找一组对嵌入的扰动δ,之后通过采样的方式映射为具体的文本表示,但此模式的缺陷在于任意的扰动并不能保证存在实词对应,产生的结果通常被视为“虚拟对抗”(virtual adversarial)。
将对抗生成的过程视为搜索优化问题(search optimization),即为每个词修改动作定义一个损失,通过优化整体的损失来找到一组修改,从而得到样本。但此模式需要针对对抗目标设计间接的损失函数(通常是基于梯度的损失),因此,此类方法除了特征工程(feature engineering)在带噪数据上限制语义和实现对抗目标的局限性,还面临搜索优化的计算开销问题。此外,如果对抗编辑改变了输入的切分方案,搜索所依赖的单步分数会失去意义。
03
—
解决思路
根据上文的归纳,我们总结问题的核心在于:
需要直接针对离散文本建模对抗生成;
我们无法预知错误特征,生成对抗样本是无监督学习;
我们无法直接建模对抗样本生成中对带噪数据的语义限制。
本质上,对抗样本的生成还可以被视为一个受限的马尔可夫决策过程(markovian decision process, MDP),我们可以从左到右编辑每个位置,每个编辑决策取决于已有修改对语义的影响程度和对系统输出的劣化期望。对于MDP的无监督学习问题,我们可以使用强化学习(reinforcement learning, RL)建模学习值函数估计,通过对受害系统的不断交互反馈得到对抗样本的生成策略。不同于一般的梯度优化,强化学习并不受限于优化离散建模,因此适合建模本问题的优化。
再者,强化学习是基于「探索&利用」(explore & exploit)原理进行的无监督学习,当前已在许多人工智能挑战中取得很好的成绩。其核心在于建模环境交互,以训练能完成特定目的的智能体(agent)。一个直观的例子就是flappy bird游戏,如下图所示,玩家(或智能体)需要根据图像状态产生动作,与环境(environment,env)交互;环境基于动作发生变动,并将更新后的状态和对动作的反馈(如游戏分数)返回给智能体。期间小鸟飞过柱子会得分,而撞柱子和落地都会终结游戏。智能体需根据正、负反馈选择强化有利于目标的策略(最大化游戏分数),最终达成学习。

图2: 强化学习进行flappy bird游戏
类似的,我们生产一句话的对抗样本,同样可以从左到右逐个token进行编辑动作,而编辑动作需要满足对抗样本定义的语义限制,类似于游戏中的障碍物会判定game over。如此我们需要找到一组编辑,最大化完成编辑后翻译系统的指标损失。
根据以上逻辑,我们就可以将受害的NMT系统作为环境的反馈之一,将其最终的测试性能损失作为阶段性反馈。而对于带噪语义的限制,我们借鉴了生成对抗网络(generative adversarial network,GAN)的思想,使用一个自监督的句匹配(sentence matching)为训练agent提供存活/终结信号(survive/terminal signal):即当前的原端和原始目标端进行二分类。训练此判别器(discriminator)也同GAN相同,随机将一半批次的句对使用当前agent进行编辑作为负样本,另一半则是不变作为正样本,环境的分类器需要间断性随着agent的学习更新,直至agent和环境的分类器达成博弈平衡,我们便得到了一个针对受害NMT系统产生对抗样本的生成器。同样类似于flappy bird中的柱子,当agent成功在限制条件下进行编辑,会将分类器的正类likelihood作为每个决策的survive reward,如此激励其在满足语义的限制前提下进行对抗生成。
我们选择了A3C(asynchronous advantage actor critic)作为智能体的实现。如图3,即agent中分别含有用于决策的actor和值函数估计的critic,二者共享编码层,前者以二分类做输出,后者为单值输出。

图3: agent设计
我们的整体流程如图4所示,在每个训练周期中,我们会循环下述三个动作直至系统终结状态或者完成句子编辑:
环境会将当前句子的token和要修改的token作为agent的输入;
agent产生编辑动作修改原端;
环境中的discriminator对修改的句对评估survive/terminal信号,并产生单步反馈。
在agent保持survive完成一轮修改后,会最终得到环境中的NMT的测试性能损失作为阶段反馈。
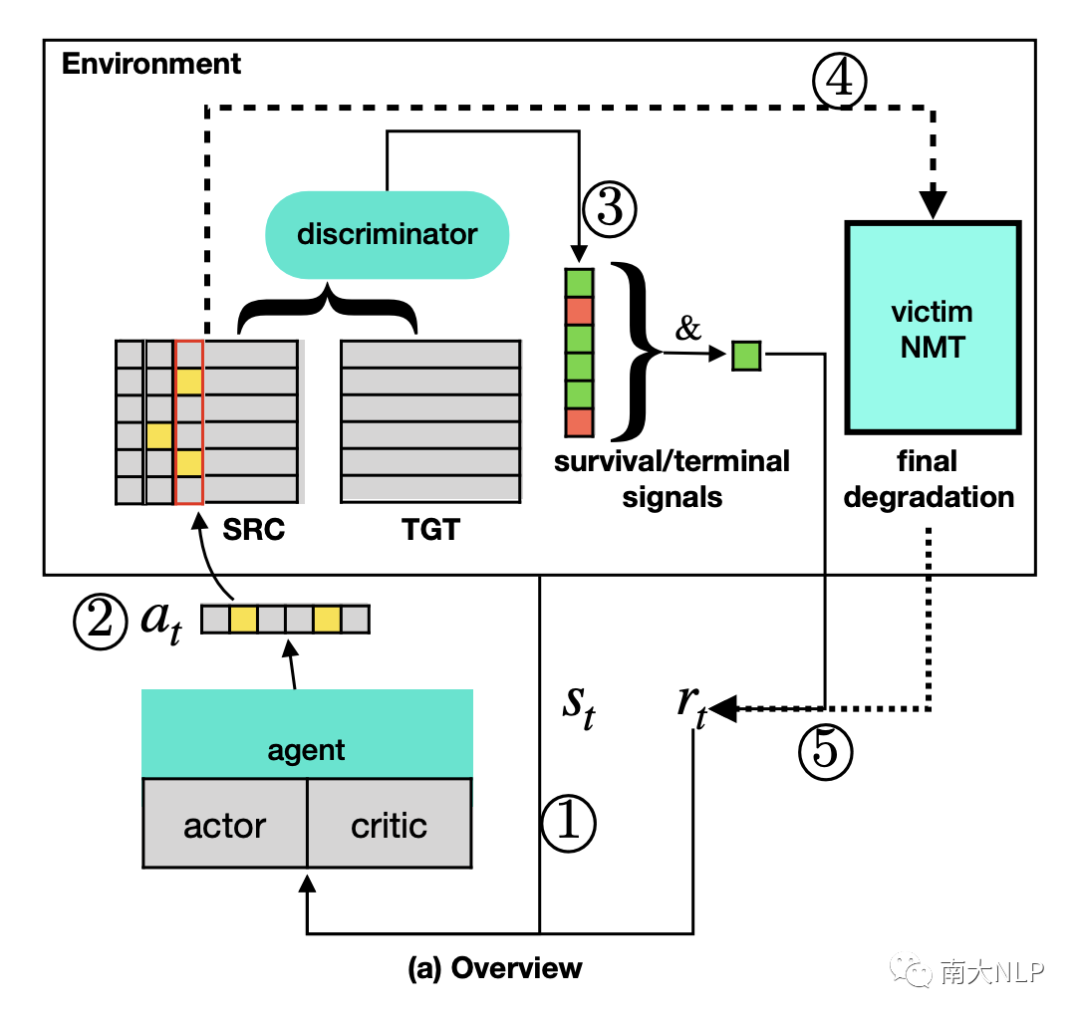
图4: 整体交互流程示意
对于编辑动作我们沿用了基于搜索的文本对抗工作,使用ε距离以内的token作为每个token的candidate(没有候选的会使用UNK作为候选)。训练中为了强化学习的探索,会使用随机策略首先采样是否进行编辑,然后随机选择candidate替换;测试时为确定策略,会选择最佳的动作,并在critic为正时选择距离最近的候选替换,以保证语义近似。
04
—
实验结果与分析
对于受害系统,我们考察了中英、英法、英德的Transformer和RNN-search翻译系统,训练对抗样本生成使用的数据也是训练翻译系统的平行数据。
我们选择了Michel et al. (2019) 基于梯度搜索(gradient search,GS)的方法作为基线对比,同时使用随机噪声插入(random synthetic noise injection,RSNI)作为控制组,对比的指标同样参考Michel et al. (2019), 需要考察公式1的“每编辑的相对性能下降”(relative degradation,RD):即翻译的BLEU相对下降对比原端字符级BLEU的变化;此外由于我们无法使用分类对带噪数据进行语义评估,因此需要人工测评,采样双盲检查语义相似度(human evaluation,HE),范围0-5。

公式1: 每编辑BLEU相对下降
不同于前任工作,我们的工作通过自监督的方式很好地平衡了语义近似度和攻击效果(表1),在维持高HE的前提下达成攻击效果,而基线和对照组除了需要制定攻击比例,还往往会出现为了降低系统指标,而产生严重语义变更的情况(表2)。

表1: 中英翻译上的对抗样本生成实验结果

表2: 基于梯度的搜索方法容易为了实现攻击而明显改变语义
除了效果的优势之外,我们的方法在生成效率上对比梯度搜索有绝对的优势。不同于梯度搜索,对于复杂系统不同修改结果求导的时空开销,我们的agent只需要很小的系统开销直接对策略进行展开即可,如图5,我们的方法对比基线,限定相同内存开销生成性能可以达到至少50倍以上。
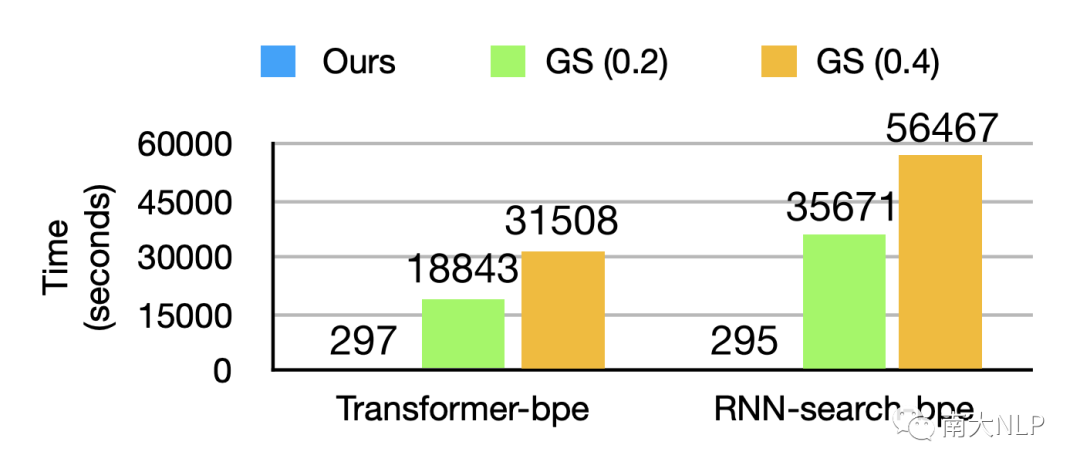
图5: 限定内存的生成800句对抗样本的时间对比
得益于高效率的对抗生成,我们可以产生大量用于抗噪增广的数据对模型进行微调,如表3,我们产生了和训练语料等量的对抗样本进行直接微调训练,可以在对原测试极小的性能损失下,极大强化在对抗数据上的性能。此外我们测试了模型微调前后对IWSLT的测试性能(IWSLT数据并不参与任何训练、微调),可以得到些微提升,说明我们的方法确实强化了模型的鲁棒能力。
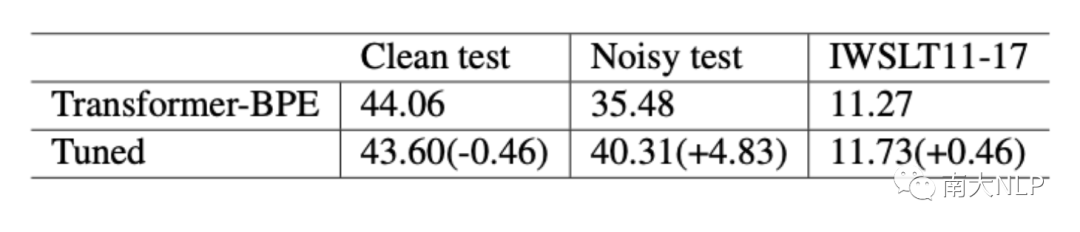
表3: 使用大规模生产的对抗样本直接微调
由于我们的方法是基于对受害系统的不断交互反馈从而习得的攻击偏好,因此我们在不依赖错误特征建模的前提下能通过这些偏好观察系统的弱点。我们统计了攻击涉及的POS,对比对照组RSNI(较随机均匀)和基线GS(有一定程度偏好)可以明显看出系统弱点(图6),比如各类命名实体(N)、数字(M)、后缀(K)等。

图6: 智能体对与中-英Transformer模型攻击的偏好
我们额外尝试了将阶段反馈转置,并忽略会引入UNK的攻击动作来产生“对输入进行细微扰动但是能提高测试性能”的样本。虽然我们暂时无法提高测试的整体性能,但相当部分的样本可以成功达成测试优化。类似对抗样本,我们称其为“强化样本”(表4)。强化样本的意义在于它是不同于微调、需要改变模型参数的鲁棒性探索方向,且强化样本的形式不同于严格的文本预处理纠正,可以允许带噪声。
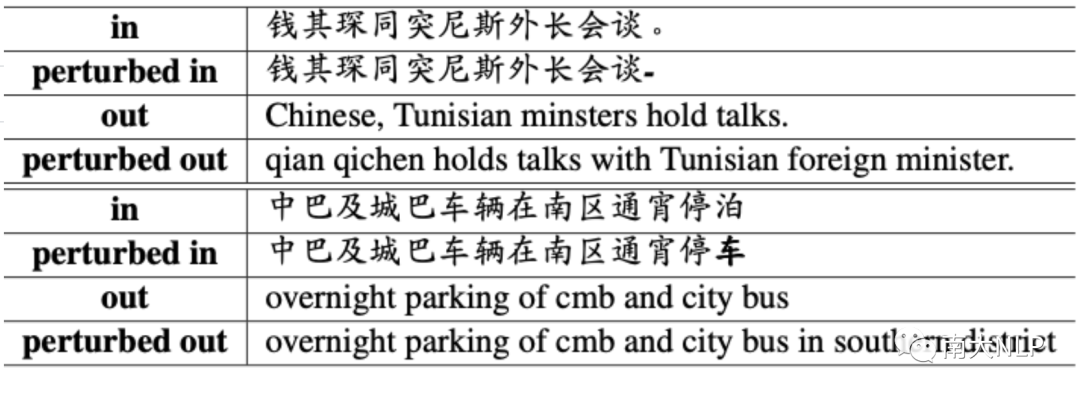
表4: 强化样本示例
05
—
总结
综上,我们通过利用强化学习建模针对机器翻译生产对抗样本,此方法区别于已有问题解决思路,在没有错误特征建模的前提下,能高效生产特定系统的对抗样本,且可以被进一步用于系统的鲁棒性分析和改善。此外,针对“强化样本”的现象,我们会在未来的工作中进一步探索,以求不同的强化系统鲁棒性能的方案。
作者:邹威
编辑:何亮
由于微信平台算法改版,公号内容将不再以时间排序展示,如果大家想第一时间看到我们的推送,强烈建议星标我们和给我们多点点【在看】。星标具体步骤为:
(1)点击页面最上方“深度学习自然语言处理”,进入公众号主页。
(2)点击右上角的小点点,在弹出页面点击“设为星标”,就可以啦。
感谢支持,比心
投稿或交流学习,备注:昵称-学校(公司)-方向,进入DL&NLP交流群。
方向有很多:机器学习、深度学习,python,情感分析、意见挖掘、句法分析、机器翻译、人机对话、知识图谱、语音识别等。

记得备注呦
推荐两个专辑给大家:
专辑 | 李宏毅人类语言处理2020笔记



