加拿大研究员使用自然语言对抗生成中国古诗词
自然语言对抗生成:
加拿大研究员使用GAN生成中国古诗词
来源:arXiv
编译:文强
【导读】今日 arXiv 最火论文之一,作者包括著名的《深度学习》(Deep Learning)一书的作者 Aaron Courville。论文用 GAN 解决自然语言处理问题,“在中国诗词数据集上取得目前最好结果”。研究人员表示,他们为训练 GAN 生成自然语言提供了一种直接有效的方法。作者表示,接下来他们想探索 GAN 在 NLP 其他领域的应用,比如非目标导向的对话系统。
对抗生成网络(GAN)是眼下的热词,而使用 GAN 做自然语言处理(NLP)则一直是业界关注的问题。日前,包括“Deep Learning”一书作者、CIFAR Fellow Aaron Courville 在内的加拿大研究人员在 arXiv 上传论文《自然语言对抗生成》 “Adversarial Generation of Natural Language”,称为训练 GAN 生成自然语言提供了一种直接而有效的方法。
作者表示,而其简单之处在于,向判别器提供来自生成器的概率分布序列和对应于真实数据分布的 1-热矢量序列(a sequence of 1-hot vectors),强制判别器对连续值进行运算。
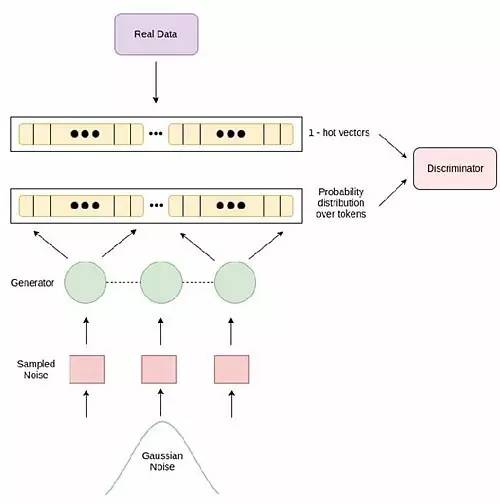
论文提出的模型架构。
此外,论文还提供了定量和定性的评估方法,展示了有可能对高级句子特征(如情绪和问题)进行文本的条件生成。
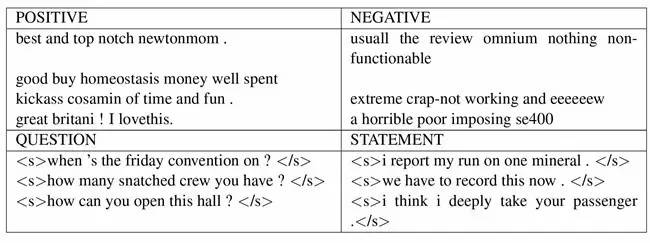
论文中给出的文本条件生成示例:上面一行是使用亚马逊网站带有“积极”和“消极”属性的评论数据集作为训练数据生成的样本,下面一行则是有同样数据集中带有“问题”特征的条件生成样本。
作者表示,接下来他们想探索 GAN 在 NLP 其他领域的应用,比如非目标导向的对话系统。

摘要
生成对抗网络(GAN)近来在计算机视觉界引起了很多注意,在图像生成方面取得了令人印象深刻的结果。但是,从噪音中对抗生成自然语言的进展与在图像生成方面的进展并不相称,仍远远落后于基于似然的方法(likelihood based methods)。本文中,我们单一以 GAN 为目标,生成自然语言。论文引入了一个简单的基准,解决了离散输出空间问题,不依赖于梯度估计函数(gradient estimator),并在一个中国诗词数据集上取得了当前最好的结果。论文还提供了从无上下文和随机上下文无关文法(probabilistic context-free grammar)生成句子的定量结果,以及语言建模的定性结果。论文还描述了一个能够根据句子条件特征生成序列的条件版本(conditional version)。
作者介绍,语言模型一般是通过测量模型下样本与真实数据分布的似然进行评估的。然而,使用 GAN,测量模型本身的似然是不可能的,因此他们采取了其他方法,通过测量模型样本在真实数据分布下的似然对结果进行评估。
作者将实验分为 4 类:
生成语言,这些语言属于 CFG 样本数据集(toy CFG),以及从 Penn Treebank 推导而来的 PCFG (Marcus et al., 1993) 数据集
生成中国诗词,与 (Yu et al., 2016) 和 (Che et al., 2017) 的结果进行比较
生成包含简单英语句子的语言,这些句子来自于 1-billion-word 和 Penn Treebank 数据集
使用 Conditional GAN,生成带有情绪(sentiment)和问题(question)等属性的句子。
实验结果
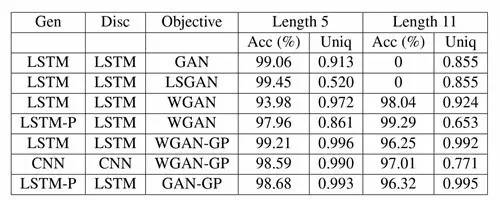
表 1(见上)展示了实验1 中,句子生成定量分析的结果。Acc 和 Uniq 分别表示精确度(Accuracy)和独特度(Uniqueness),LSTM-P 表示带有 output peephole 的 LSTM。WGAN-GP 和 GAN-GP 表示在训练过程中采用了梯度惩罚(gradient penalty,GP)的模型。
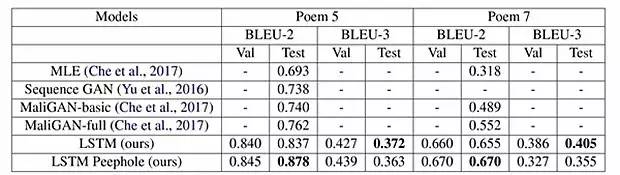
从表 2(见上)中可见,在五言诗和七言绝句中,作者提出的方法 BLEU 得分都是最高的。

1-billion word 数据集字和词级别上的生成结果。

Penn Treebank 和 CMU-SE 数据集在字级别(Word level)上的生成结果。




