BiLSTM+CRF命名实体识别:达观杯败走记(下篇)

一 :今日吐槽
在整理BiLSTM+CRF命名实体识别下篇的过程中,我发现了两个问题。
一是用到的torchcrf这个包会自动给标签加上<start>和<end>的转移概率。
这意味着我们无需手动给标签前后加<start>和<end>,标签到id的映射中,也无需加这两个标记。
样本前后也不用加这两个标记的。
当然,这和CRF层的代码实现有关,不能一概而论。
二是模型评估用的是token(字)级别的评估方法,也就是按每个字的标签是否预测正确来评估,比较宽松。
更严谨的是实体级别的评估方法,同时考虑实体边界和实体类型。
所以换成了一种比较权威的评估方法:用CoNLL-2000的评估脚本来评估。
大型翻车现场。
取消关注。
拉黑。
别...... 人生已经如此的艰难 ......
以后保证把文章写完了,思路理清楚了再发,我保证!
二:内容预告
BiLSTM+CRF命名实体识别的上篇已经介绍了数据预处理中需要注意的地方,根据上面提到的第一点,已经把代码进行了修改。
本文是BiLSTM+CRF命名实体识别的下篇,介绍模型的构建、训练、评估和预测,使用的深度学习框架为pytorch。
使用CoNLL-2000的脚本评估模型的结果如下,测试集上F1宏平均为0.976,验证集上最好的F1值为0.9784。
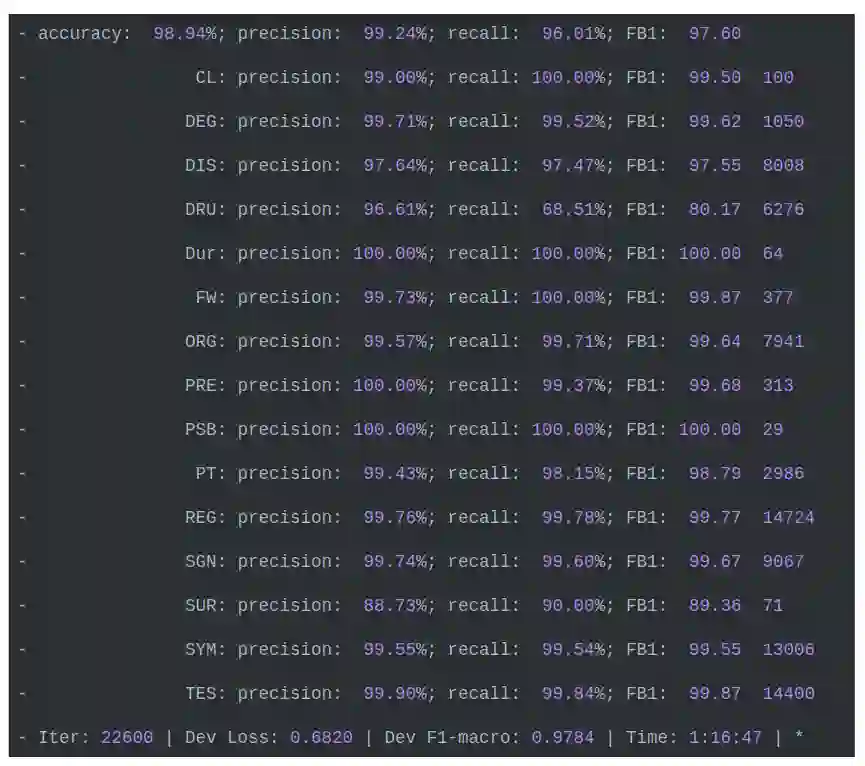
在网上找一个医疗相关的句子,测试结果如下:
{'entities': [{'end': 7, 'start': 5, 'type': 'ORG', 'word': '心脏'},
{'end': 10, 'start': 8, 'type': 'ORG', 'word': '血管'},
{'end': 40, 'start': 36, 'type': 'DIS', 'word': '心血管病'}],
'string': '循环系统由心脏、血管和调节血液循环的神经体液组织构成,循环系统疾病也称为心血管病。'}代码已经修改,github地址如下,包含完整的数据:
https://github.com/DengYangyong/medical_entity_recognize
本文主要关注以下两点:
BiLSTM+CRF的损失怎么计算
实体识别模型怎么评估
三:模型的构建
下面的模型结构图来自原论文,但是少画了一个线性层,这个线性层在BiLSTM层之上,CRF层之下。
论文中说加了线性层可以极大地提升模型效果。
Additionally, we observed that adding a hidden layer between ci and the CRF layer marginally improved our results.
所以模型从输入到输出一共四层:
embedding层——BiLSTM层——Linear层——CRF层。
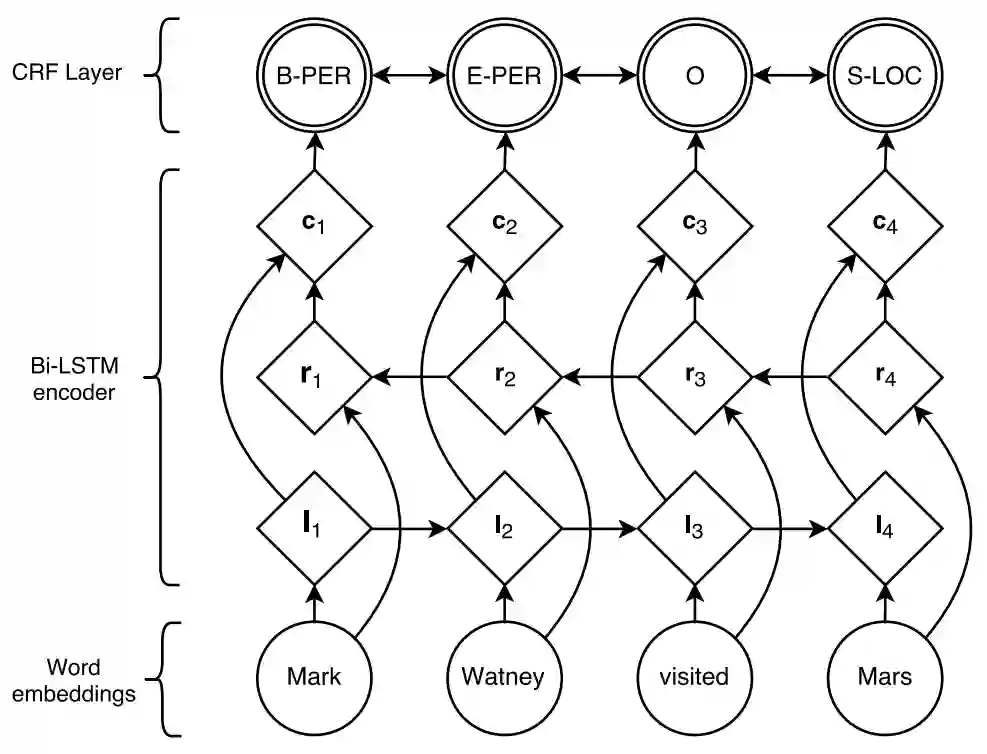
模型构建的代码主要参考了这个github,感谢作者:
https://github.com/Alic-yuan/nlp-beginner-finish
但是作者没使用预训练的字向量,没加入分词特征,没有对Loss做MASK,模型评估使用的是token级别的方法。
CRF模型用的现成的python库:pytorch-crf,我下载了代码,保存为torchcrf.py文件,不用安装,直接调用就行。
这个库是基于AllenNLP实现的CRF包,用pytorch写的,用来计算CRF的损失和进行维特比解码,非常方便。
之前看的一些代码,眉毛胡子一把抓,把CRF模型和BiLSTM模型混在一起,看的人头大。
所以这次把CRF模型独立出来,也就是pytorch-crf这个库,结构就比较清晰了。
BiLSTM+CRF模型的代码如下:
import torch
import torch.nn as nn
import torch.optim as optim
from model.torchcrf import CRF
class NERLSTM_CRF(nn.Module):
def __init__(self, config, char2id, tag2id, emb_matrix):
super(NERLSTM_CRF, self).__init__()
self.hidden_dim = config.hidden_dim
self.vocab_size = len(char2id)
self.tag_to_ix = tag2id
self.tagset_size = len(tag2id)
""" pdding_idx=0,也就是让pad标记不更新 """
self.char_emb = nn.Embedding.from_pretrained(
emb_matrix,freeze=False, padding_idx=0
)
self.seg_emb = nn.Embedding(
self.vocab_size, config.seg_dim, padding_idx=0
)
self.emb_dim = config.char_dim + config.seg_dim
self.dropout = nn.Dropout(config.dropout)
self.lstm = nn.LSTM(
self.emb_dim, self.hidden_dim // 2, num_layers=1,
bidirectional=True, batch_first=True
)
""" 得到发射矩阵 """
self.hidden2tag = nn.Linear(self.hidden_dim, self.tagset_size)
self.crf = CRF(self.tagset_size,batch_first=True)
def forward(self, char_ids,seg_ids,mask=None):
""" 把字向量(100维)和词长度特征向量(20维),拼接 """
embedding = torch.cat(
(self.char_emb(char_ids),self.seg_emb(seg_ids)), 2
)
outputs, hidden = self.lstm(embedding)
outputs = self.dropout(outputs)
outputs = self.hidden2tag(outputs)
""" 预测时,得到维特比解码的路径 """
return self.crf.decode(outputs, mask)
def log_likelihood(self, char_ids, seg_ids, tag_ids, mask=None):
embedding = torch.cat(
(self.char_emb(char_ids),self.seg_emb(seg_ids)), 2
)
outputs, hidden = self.lstm(embedding)
outputs = self.dropout(outputs)
outputs = self.hidden2tag(outputs)
""" 训练时,得到损失 """
return - self.crf(outputs, tag_ids, mask)首先看embedding层。
self.char_emb用于获取输入序列的字向量,加载了预训练的100维字向量,并在训练的过程中微调。
self.seg_emb用于获取分词的长度特征的向量,维度设置为20维,权重随机初始化。
还记得分词的长度特征吧:
句子:
"循环系统由心脏、血管和调节血液循环的神经体液组织构成"
分词结果:
['循环系统', '由', '心脏', '、', '血管', '和', '调节', '血液循环', '的', '神经', '体液', '组织', '构成']
长度特征:
[1, 2, 2, 3, 0, 1, 3, 0, 1, 3, 0, 1, 3, 1, 2, 2, 3, 0, 1, 3, 1, 3, 1, 3, 1, 3]
在训练和预测时,会把这两个向量拼接成120维的向量,送入BiLSTM层。
注意这两个embedding都传入了一个参数 padding_idx=0,这也是这一种MASK操作。
在上篇中,我们说了,需要准备一个MASK矩阵,对<pad>标记进行MASK,不参与Loss的计算,也不参与梯度的更新。
其实embedding层也需要做MASK,让<pad>标记对应的词向量元素均为0,不参与神经网络的正向传播和反向传播。
在pytorch中对embedding做MASK,可以通过设定padding_idx参数的值为<pad>的编号,自动实现,无需准备MASK矩阵。
那你又要问了,对Loss进行MASK也可以通过传入一个参数直接搞定啊?
比如在计算交叉熵损失的函数中,传入参数:ignore_index=0(0就是<pad>的id)。
criterion = nn.CrossEntropyLoss(ignore_index=0)没错,如果这次的模型是BiLSTM的模型,没加CRF,那么直接用以上的函数计算损失,无需另外准备一个MASK矩阵。
但这次的模型加了CRF层,损失是用pytorch-crf这个库计算的,需要自己准备一个MASK矩阵。
看下面的代码,是需要传入一个MASK矩阵的。
class CRF(nn.Module):
def forward(
self,
emissions: torch.Tensor,
tags: torch.LongTensor,
mask: Optional[torch.ByteTensor] = None,
reduction: str = 'sum',
) -> torch.Tensor:
...
def decode(self, emissions: torch.Tensor,
mask: Optional[torch.ByteTensor] = None) -> List[List[int]]:
...把embedding层得到的120维向量送入BiLSTM层,把前向LSTM(比如128维)和后向LSTM(比如128维)的output拼接(如256维)。
如果batch=First,那么输出的维度是:
(batch, seq_length, num_directions * hidden_size)
接着把LSTM的输出送入Linear层,得到发射矩阵,也就是观测序列(句子)到标签序列(实体标签)的发射矩阵,维度是:
(batch_size, seq_length, num_tags)
如果是训练,那么直接用发射矩阵和真实标签去计算Loss,用于更新梯度。
这需要用到CRF中的forward函数。
如果是预测,那么就用发射矩阵去进行维特比解码,得到最优路径(预测的标签)。
这需要用到CRF中的decode函数。
所谓的CRF层,其实也就是一些可学习的参数,如下图:
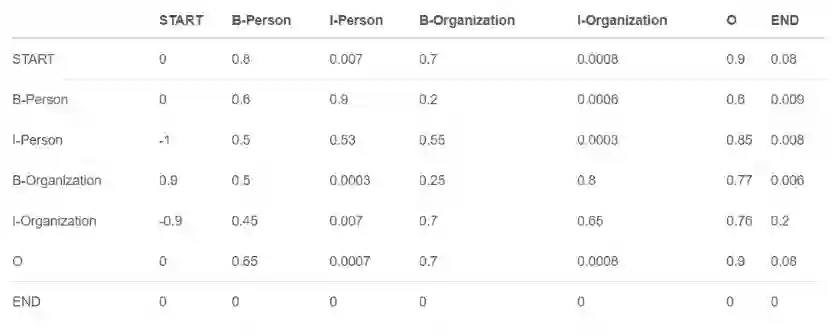
我仔细看了这个库的代码,才发现原来这个库会把自动添加<start>和<end>的转移概率,这也就意味着,我们无需在标签中手动加入这两个标记,同样样本的前后也无需添加这两个标记。
补救措施就是:在建立字、标签到id的映射时,去掉这两个标记,还有样本和标签前后都不要加这两个标记。
class CRF(nn.Module):
"""Conditional random field."""
def __init__(self, num_tags: int, batch_first: bool = False) -> None:
if num_tags <= 0:
raise ValueError(f'invalid number of tags: {num_tags}')
super().__init__()
self.num_tags = num_tags
self.batch_first = batch_first
""" 这个库里面会自动添加<start>和<end>的转移概率,
所以无需再手动在样本和标签前后加入<start>和<end>标记 """
self.start_transitions = nn.Parameter(torch.empty(num_tags))
self.end_transitions = nn.Parameter(torch.empty(num_tags))
""" 转移概率矩阵,tags不包含<start>和<end>标记 """
self.transitions = nn.Parameter(torch.empty(num_tags, num_tags))
self.reset_parameters()四:模型的训练
开始训练模型。
首先加载数据集,把样本和标签都转化为id。
然后产生batch训练数据。为了使用CoNLL-2000的评估脚本,我把BatchManager的代码改了一点(后面会介绍),每个batch包含样本、样本的id,标签的id和MASK矩阵。
chars, char_ids, seg_ids, tag_ids, mask = batch接着初始化模型,并设为用GPU训练。
按照上面说的,item到id的映射中已经去掉了<start>和<end>,
char_to_id
{'<pad>': 0, '<unk>': 1, '0': 2, ',': 3, ':': 4, '。': 5, '无': 6, '、': 7, '常': 8, ...}
tag_to_id
{'<pad>': 0, 'O': 1, 'I-TES': 2, 'I-DIS': 3, 'I-SGN': 4, 'B-TES': 5, 'E-TES': 6, ...}用F1宏平均作为early stop的监控指标,同时使用了学习率衰减和梯度截断。
config.steps_check设为了100,也就是每100个batch在验证集上跑一次,如果F1值有提高,那就保存模型,并在测试集上测试并打印结果。
那损失是怎么计算出来的呢?
验证集和测试集上的F1值是怎么算的呢?
def train():
""" 1: 加载数据集,把样本和标签都转化为id"""
if os.path.isfile(config.data_proc_file):
with open(config.data_proc_file, "rb") as f:
train_data,dev_data,test_data = pickle.load(f)
char_to_id,id_to_char,tag_to_id,id_to_tag = pickle.load(f)
emb_matrix = pickle.load(f)
logger.info("%i / %i / %i sentences in train / dev / test." % (len(train_data), len(dev_data), len(test_data)))
else:
train_data,dev_data,test_data, char_to_id, tag_to_id, id_to_tag, emb_matrix = build_dataset()
""" 2: 产生batch训练数据 """
train_manager = BatchManager(train_data, config.batch_size)
dev_manager = BatchManager(dev_data, config.batch_size)
test_manager = BatchManager(test_data, config.batch_size)
model = NERLSTM_CRF(config, char_to_id, tag_to_id, emb_matrix)
model.train()
model.to(device)
optimizer = optim.Adam(model.parameters(), lr=config.lr, weight_decay=config.weight_decay)
""" 3: 用early stop 防止过拟合 """
total_batch = 0
dev_best_f1 = float('-inf')
last_improve = 0
flag = False
start_time = time.time()
logger.info(" 开始训练模型 ...... ")
for epoch in range(config.max_epoch):
logger.info('Epoch [{}/{}]'.format(epoch + 1, config.max_epoch))
for index, batch in enumerate(train_manager.iter_batch(shuffle=True)):
optimizer.zero_grad()
""" 计算损失和反向传播 """
_, char_ids, seg_ids, tag_ids, mask = batch
loss = model.log_likelihood(char_ids,seg_ids,tag_ids, mask)
loss.backward()
""" 梯度截断,最大梯度为5 """
nn.utils.clip_grad_norm_(parameters=model.parameters(), max_norm=config.clip)
optimizer.step()
if total_batch % config.steps_check == 0:
model.eval()
dev_f1,dev_loss = evaluate(model, dev_manager, id_to_tag)
""" 以f1作为early stop的监控指标 """
if dev_f1 > dev_best_f1:
evaluate(model, test_manager, id_to_tag, test=True)
dev_best_f1 = dev_f1
torch.save(model, os.path.join(config.save_dir,"medical_ner.ckpt"))
improve = '*'
last_improve = total_batch
else:
improve = ''
time_dif = get_time_dif(start_time)
msg = 'Iter: {} | Dev Loss: {:.4f} | Dev F1-macro: {:.4f} | Time: {} | {}'
logger.info(msg.format(total_batch, dev_loss, dev_f1, time_dif, improve))
model.train()
total_batch += 1
if total_batch - last_improve > config.require_improve:
""" 验证集f1超过5000batch没上升,结束训练 """
logger.info("No optimization for a long time, auto-stopping...")
flag = True
break
if flag:
break BiLSTM+CRF的损失由发射矩阵和转移矩阵计算而得。
输入一个句子,预测的标签序列(路劲)有很多条,而正确的标签序列是其中的一条。
每条标签序列都可以计算一个分数,由句子中每个字和标签对应的发射概率,以及标签之间的转移概率,加和而成,公式如下:
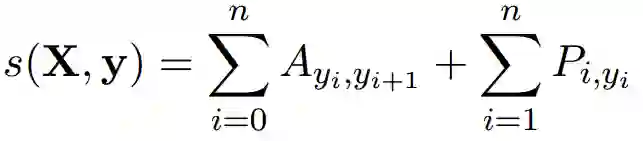
P是发射矩阵,size为n×k,k为真实标签的个数,不包括<start>和<end>。
A为转移矩阵,size为(k+2)×(k+2),需要加上<start>和<end>。
同样我们可以算出正确的标签序列的分数,一般把这个分数叫做 Gold Score。
用Gold Score和所有可能路径的分数,算一个softmax的概率,显然我们要让正确的标签序列的概率最大。
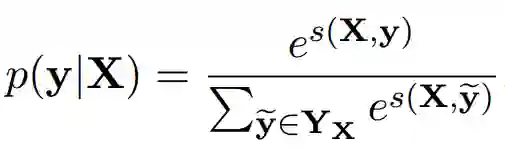
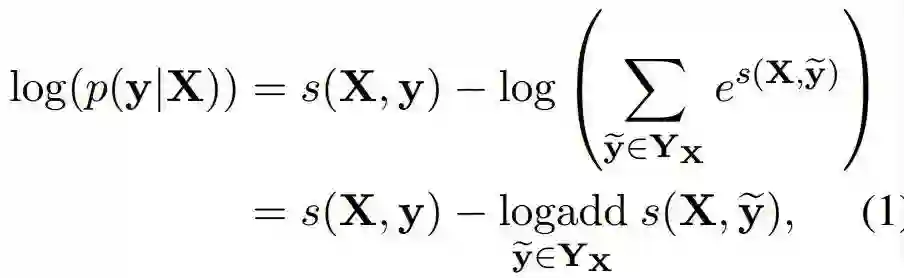
为了方便求解,在等式左右两边加了log,同时用动态规划来计算。
再加一个负号,作为Loss,让Loss最小化。
具体细节可参考:
BiLSTM上的CRF,用命名实体识别任务来解释CRF(2)损失函数
现在我们再回到是否加<start>和<end>这个问题上来。
从损失函数的公式可以看到,样本前后可以不加这两个标记,标签序列是要加的。
命名实体识别可以看作是token(字)级别或实体级别的多分类,评估指标还是Precision,Recall和F1值。
所以从token和实体两个角度来看,命名实体识别的评测方式分为两种,一是基于所有token标签的评测,二是考虑实体边界+实体类型的评测。
基于所有token标签的评测,是一种宽松匹配的方法,就是把所有测试样本的真实标签展成一个列表,把预测标签也展成一个列表,然后直接计算Precision、Recall和F1值。
考虑实体边界和实体类型的评测方法,是一种精准匹配的方法,只有当实体边界和实体类别同时被标记正确,才能认为实体识别正确。
考虑实体边界和实体类型的方法实现起来比较复杂,千万不要为难自己,直接用别人写好的包就行。
用的比较多的是CoNLL-2000的一个评估脚本,原本是用Perl写的,网上有python的实现,支持IOBES格式。
这次就是参考了这个python版的实现:
https://github.com/spyysalo/conlleval.py

原代码是把文本、真实标签和预测标签用空格拼接,写入一个预测结果文件,再直接加载该文件进行评估,并写入一个评估结果文件。
预测结果文件的格式如下:
无 O O
长 B-PT B-PT
期 I-PT I-PT
外 I-PT I-PT
地 I-PT I-PT
居 I-PT I-PT
住 I-PT I-PT
史 E-PT E-PT
。 O O
无 O O
家 B-DIS B-DIS
族 I-DIS I-DIS
性 I-DIS I-DIS
遗 I-DIS I-DIS
传 I-DIS I-DIS
病 E-DIS E-DIS
史 O O
。 O O所以在准备数据和生成batch的时候,我们也需要拆成字的样本,而不仅是id和MASK矩阵。
class BatchManager(object):
def __init__(self, data, batch_size):
def sort_and_pad(self, data, batch_size):
@staticmethod
def pad_data(data):
"""
构造一个mask矩阵,对pad进行mask,不参与loss的计算
另外,除了id以外,字本身,因为用CoNLL-2000的脚本评估时需要,所以也加上。
"""
batch_chars = []
batch_chars_idx = []
batch_segs_idx = []
batch_tags_idx = []
batch_mask = []
max_length = max([len(sentence[0]) for sentence in data])
for line in data:
chars, chars_idx, segs_idx, tags_idx = line
padding = [0] * (max_length - len(chars_idx))
""" CoNLL-2000的评估脚本需要用到 """
batch_chars.append(chars + padding)
batch_chars_idx.append(chars_idx + padding)
batch_segs_idx.append(segs_idx + padding)
batch_tags_idx.append(tags_idx + padding)
batch_mask.append([1] * len(chars_idx) + padding)
batch_chars_idx = torch.LongTensor(batch_chars_idx).to(device)
batch_segs_idx = torch.LongTensor(batch_segs_idx).to(device)
batch_tags_idx = torch.LongTensor(batch_tags_idx).to(device)
batch_mask = torch.tensor(batch_mask,dtype=torch.uint8).to(device)
return [batch_chars, batch_chars_idx, batch_segs_idx, batch_tags_idx, batch_mask]
def iter_batch(self, shuffle=True):另外为了在训练过程中能够进行测试,并打印测试结果,需要对conlleval.py中的report函数进行一点修改,不再是保存为一个评估结果文件,而是放在一个列表里。
def report_notprint(counts, out=None):
if out is None:
out = sys.stdout
overall, by_type = metrics(counts)
c = counts
final_report = []
line = []
line.append('processed %d tokens with %d phrases; ' %
(c.token_counter, c.found_correct))
line.append('found: %d phrases; correct: %d.\n' %
(c.found_guessed, c.correct_chunk))
final_report.append("".join(line))
if c.token_counter > 0:
line = []
line.append('accuracy: %6.2f%%; ' %
(100.*c.correct_tags/c.token_counter))
line.append('precision: %6.2f%%; ' % (100.*overall.prec))
line.append('recall: %6.2f%%; ' % (100.*overall.rec))
line.append('FB1: %6.2f\n' % (100.*overall.fscore))
final_report.append("".join(line))
for i, m in sorted(by_type.items()):
line = []
line.append('%17s: ' % i)
line.append('precision: %6.2f%%; ' % (100.*m.prec))
line.append('recall: %6.2f%%; ' % (100.*m.rec))
line.append('FB1: %6.2f %d\n' % (100.*m.fscore, c.t_found_guessed[i]))
final_report.append("".join(line))
return final_report训练过程中打印的测试结果如下:
好,介绍完了conlleval.py这个包的使用,我们回来看模型的评估部分代码。
首先计算得到预测的标签和损失。
为了使用CoNLL-2000的实体识别评估脚本,我们需要按其要求的格式来处理预测的标签,即:家 B-DIS B-DIS 这种形式。
def evaluate_helper(model, data_manager, id_to_tag):
with torch.no_grad():
total_loss = 0
results = []
for batch in data_manager.iter_batch():
chars, char_ids, seg_ids, tag_ids, mask = batch
batch_paths = model(char_ids,seg_ids,mask)
loss = model.log_likelihood(char_ids, seg_ids, tag_ids,mask)
total_loss += loss.item()
""" 忽略<pad>标签,计算每个样本的真实长度 """
lengths = [len([j for j in i if j > 0]) for i in tag_ids.tolist()]
tag_ids = tag_ids.tolist()
for i in range(len(chars)):
result = []
string = chars[i][:lengths[i]]
""" 把id转换为标签 """
gold = [id_to_tag[int(x)] for x in tag_ids[i][:lengths[i]]]
pred = [id_to_tag[int(x)] for x in batch_paths[i][:lengths[i]]]
""" 用CoNLL-2000的实体识别评估脚本, 需要按其要求的格式保存结果,
即 字-真实标签-预测标签 用空格拼接"""
for char, gold, pred in zip(string, gold, pred):
result.append(" ".join([char, gold, pred]))
results.append(result)
aver_loss = total_loss / (data_manager.len_data * config.batch_size)
return results, aver_loss 接着调用评估脚本,计算每类实体的Precision、Recall和F1值,如果是测试的话,打印测试结果,如上图所示。
def evaluate(model, data, id_to_tag, test=False):
""" 得到预测的标签(非id)和损失 """
ner_results, aver_loss = evaluate_helper(model, data, id_to_tag)
""" 用CoNLL-2000的实体识别评估脚本来计算F1值 """
eval_lines = test_ner(ner_results, config.save_dir)
if test:
""" 如果是测试,则打印评估结果 """
for line in eval_lines:
logger.info(line)
f1 = float(eval_lines[1].strip().split()[-1]) / 100
return f1, aver_loss预测部分比较简单,加载训练好的模型,将文本转化为id,并提取分词特征,送入模型中进行维特比解码,得到预测的路径(标签的id),再转化为标签。
维特比算法这里就不提了。
def predict(input_str):
with open(config.map_file, "rb") as f:
char_to_id, id_to_char, tag_to_id, id_to_tag = pickle.load(f)
""" 用cpu预测 """
model = torch.load(os.path.join(config.save_dir,"medical_ner_f1_0.976.ckpt"),
map_location="cpu"
)
model.eval()
if not input_str:
input_str = input("请输入文本: ")
_, char_ids, seg_ids, _ = prepare_dataset([input_str], char_to_id, tag_to_id, test=True)[0]
char_tensor = torch.LongTensor(char_ids).view(1,-1)
seg_tensor = torch.LongTensor(seg_ids).view(1,-1)
with torch.no_grad():
""" 得到维特比解码后的路径,并转换为标签 """
paths = model(char_tensor,seg_tensor)
tags = [id_to_tag[idx] for idx in paths[0]]
pprint(result_to_json(input_str, tags))
if __name__ == "__main__":
if config.train:
train()
else:
input_str = "循环系统由心脏、血管和调节血液循环的神经体液组织构成,循环系统疾病也称为心血管病。"
predict(input_str)最后用result_to_json这个函数,对预测进行进行规范输出,得到的结果如下。
输出了提取的实体、类别以及在句中的位置边界。
{'entities': [{'end': 7, 'start': 5, 'type': 'ORG', 'word': '心脏'},
{'end': 10, 'start': 8, 'type': 'ORG', 'word': '血管'},
{'end': 40, 'start': 36, 'type': 'DIS', 'word': '心血管病'}],
'string': '循环系统由心脏、血管和调节血液循环的神经体液组织构成,循环系统疾病也称为心血管病。'}好了,这个模型的介绍到此为止,更多的代码细节,感兴趣的同学自己去跑跑。
参考资料:
1:《Neural Architectures for Named Entity Recognition》
2:《BiLSTM上的CRF,用命名实体识别任务来解释CRF(2)损失函数》
3:https://github.com/spyysalo/conlleval.py
4:https://github.com/Alic-yuan/nlp-beginner-finish
END
推荐阅读
斯坦福大学NLP组Python深度学习自然语言处理工具Stanza试用
太赞了!Springer面向公众开放电子书籍,附65本数学、编程、机器学习、深度学习、数据挖掘、数据科学等书籍链接及打包下载
数学之美中盛赞的 Michael Collins 教授,他的NLP课程要不要收藏?
模型压缩实践系列之——bert-of-theseus,一个非常亲民的bert压缩方法
关于AINLP
AINLP 是一个有趣有AI的自然语言处理社区,专注于 AI、NLP、机器学习、深度学习、推荐算法等相关技术的分享,主题包括文本摘要、智能问答、聊天机器人、机器翻译、自动生成、知识图谱、预训练模型、推荐系统、计算广告、招聘信息、求职经验分享等,欢迎关注!加技术交流群请添加AINLPer(id:ainlper),备注工作/研究方向+加群目的。






