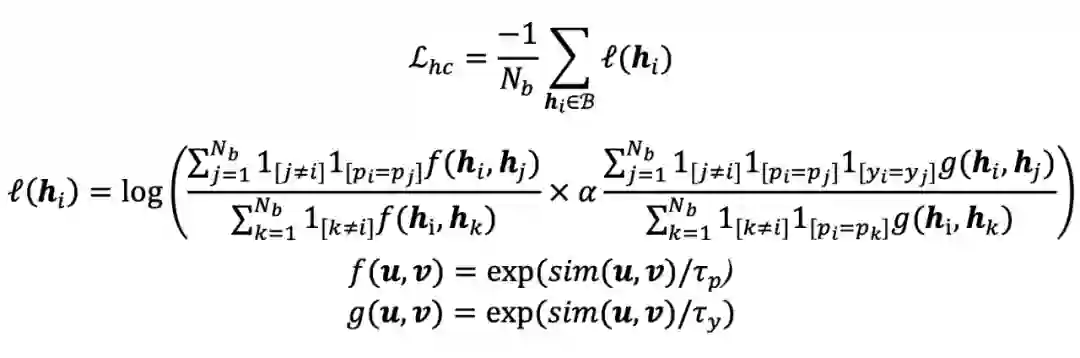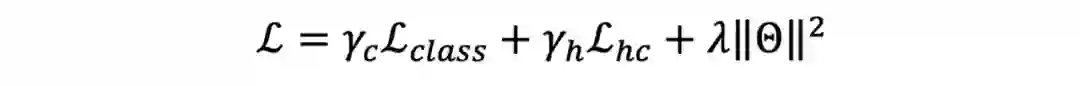©PaperWeekly 原创 · 作者 | 梁斌、陈子潇
单位 | 哈尔滨工业大学(深圳)
研究方向 | 情感分析、立场检测
零样本立场检测(zero-shot stance detection)旨在通过已知目标/主题(target/ topic)的训练数据来对包含未知目标的测试数据进行立场检测。由于测试目标对于训练数据来说是未知的,所以零样本立场检测的一个重要挑战是需要从训练数据中学习可迁移的立场特征信息来对测试集中的未知目标进行立场检测。 在这个工作中,我们针对该任务提出了一种非常简单且有效的对比学习框架。具体地,我们巧妙地使用一个代理任务(pretext task)来辅助未知目标(target)的立场检测。该代理任务的目的是为每一个训练样本生成一个额外的标签(label),标记了该训练样本的立场表达(stance expression)是目标无关(target-invariant)或特定于目标(target-specific)。 因为,在这个任务中,之所以能预测训练集未见过的目标的立场,是天然存在一些可以修饰任何目标的立场表达,我们称之为目标无关的立场表达(target-invariant stance expression)。而另外一些,则可认为是只对某个(或某些)目标起效,我们称之为特定于目标(目标相关)的立场表达(target-specific stance expression)。 随后通过结合代理任务和原本的 label 信息,我们提出了一种基于代理任务的分层对比学习框架(PT-HCL),能使模型在区分出目标无关与相关的基础上区分样本的立场特征表示。最终在三个常用的公开数据集上的结果表明,我们提出的框架取得了目前最佳的性能。 同时,我们的方法也能直接迁移至少样本立场检测(few-shot stance detection)和跨目标立场检测(cross-target stance detection)任务,并取得最佳性能。此外,我们的方法无需任何额外的外部知识或监督信号,也能很好地迁移至其他的零样本分类任务。
论文信息:
Bin Liang, Zixiao Chen, Lin Gui, Yulan He, Min Yang, Ruifeng Xu*. Zero-Shot Stance Detection via Contrastive Learning, The 31th Web Conference (TheWebConf 2022), Apr. 2022.
论文地址: http://www.hitsz-hlt.com/paper/Zero-Shot-Stance-Detection-via-Contrastive-Learning-WWW2022.pdf 代码地址: https://github.com/HITSZ-HLT/PT-HCL
给定已标注的源目标立场检测数据集
,其中
表示源目标数据中的目标,
是对应的立场标签,
和
是源目标数据集和位置目标数据集的样例数量,数据集
和
间没有交集。零样本立场检测任务的目标是基于
中每条面向已知源目标
的句子
,训练一个立场检测模型,用于预测
中每条面向未知目标
的句子
的立场。因此,该任务的的一个重要挑战是需要从训练数据中学习可迁移的立场特征信息来对测试集中的未知目标进行立场检测。
针对该挑战,我们发现训练数据中天然存在一些立场表达特征是可以修饰所有目标的,而另外一些则只能用来修饰某个或某些特定目标。我们称前者为目标无关的立场表达 (target-invariant stance expression),后者为特定于目标 (目标相关)的立场表达 (target-specific stance expression)。
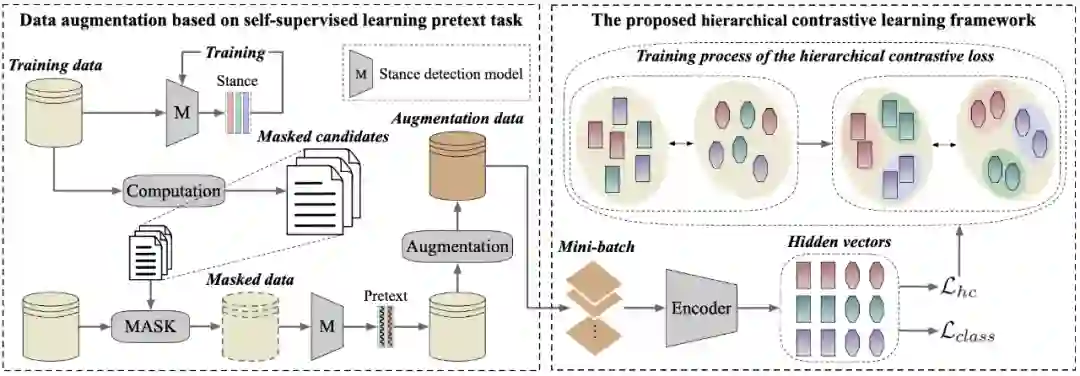
基于该发现,我们提出了一种借助代理任务(pretext task)来区分这两种立场表达特征的分层对比模型,从而使模型能更好地利用可迁移立场特征来进行未知目标的立场检测,提升零样本立场检测的性能。我们提出的 PT-HCL(Pretext Task-based Hierarchical Contrastive Learning)模型框架如图 1 所示:
▲ 图1:基于代理任务的分层对比学习框架图。渐变色图形代表隐藏向量,不同类型的图形代表不同的立场类型,不同颜色的图形代表不同的立场类别。
为了在零样本立场检测任务中有效区分目标相关立场表达和目标无关立场表达以学习到可迁移的立场特征,我们构思了一个基于自监督学习过拟合模型的数据增强方案。直观地,对于一个句子,如果我们掩盖掉其中与目标高度相关的词语,其立场表达仍然维持不变的话,那么这个句子就可以认为是包含了目标无关的立场表达特征。反之,其立场表达则是目标相关的。
基于此,我们首先在源目标数据集上训练一个对该数据集预测准确率接近 100% 的立场检测模型。然后我们将每一条训练数据中的目标相关词(target-related words)使用 [MASK] token 进行代替,形成重构数据。随后我们将这些重构数据重新输入到训练好的立场检测模型来预测它们的立场类别。
因为我们将该立场检测模型训练到足够好(准确率接近 100%),所以对于每一条重构数据,如果它的预测立场类别维持不变,那我们可以认为该数据是目标无关的,并标注一个额外的“target-invariant”增强类别。反之标注一个额外的“target-specific”增强类别。由于我们方法的通用性,我们可以使用任何适合的方法来生成目标相关词,例如 TF-IDF,相似度度量,以及主题模型等。
我们希望模型在学习过程中在能够充分区别不同的立场类型(“target-invariant”或“target-specific”)的基础上有效区分不同立场类别的向量表示。因此,我们设计了一个简单且有效的分层对比学习框架,通过对比学习的作用,使模型在向量分布空间上对立场类型和立场类别进行区分,从而有效利用代理任务辅助零样本立场检测。
在一个大小为
的 mini-batch B 中,对于一个锚点(anchor)样本
,我们基于不同的温度系数 τ 设计了一种新颖的分层对比损失函数来提升模型对特征信息的学习,公式如下:
其中,
为样本 i 的立场类型,
为样本 i 的立场类别。
是一个指示函数,当且仅当 i=j 时取值为 1。sim(·) 为余弦相似度函数。
和
是两个控制特征向量区分程度的温度系数。其中
,代表模型在学习过程中对立场特征类型的区分度要强于立场类别。此外,
用来控制对比损失中立场类型和立场类别的贡献程度,即在区分立场类型的基础上区分立场类别。随后,基于分层对比损失函数,我们结合立场检测交叉熵损失,得到最终的损失函数:
其中
和
为用来控制损失函数系数的可调节超参数,
代表所有可训练参数,
为
正则化系数。
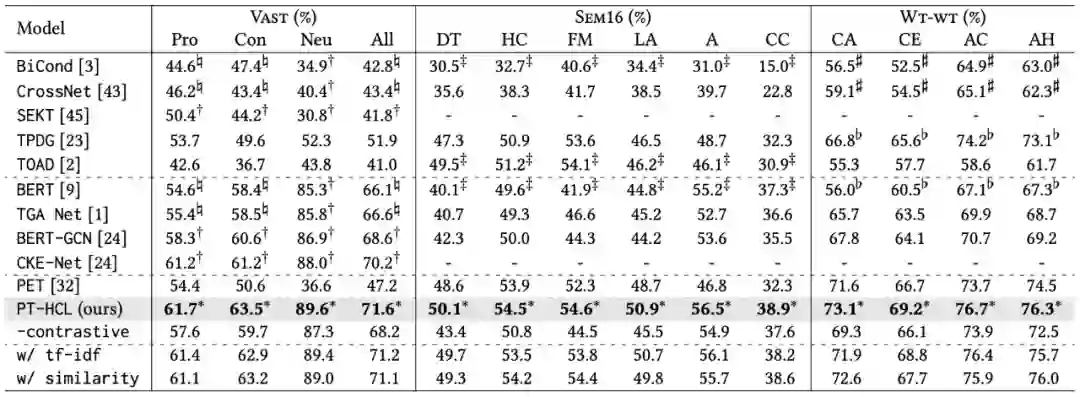
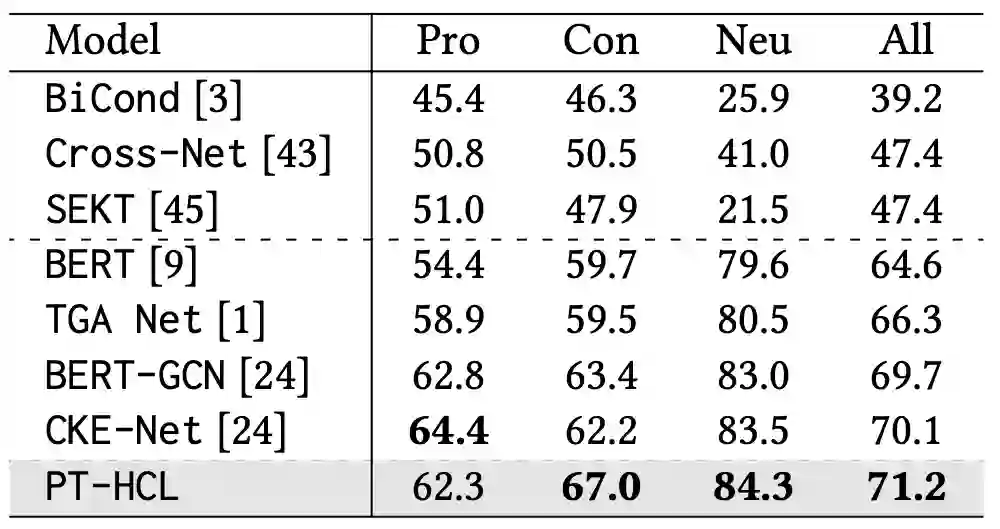
我们在 3 个公开的零样本立场检测数据集(VAST、SEM16 和 WT-WT)中进行对比实验。实验结果显示我们提出的 PT-HCL 方法在所有零样本立场检测数据集中的各项性能指标都达到了最优。
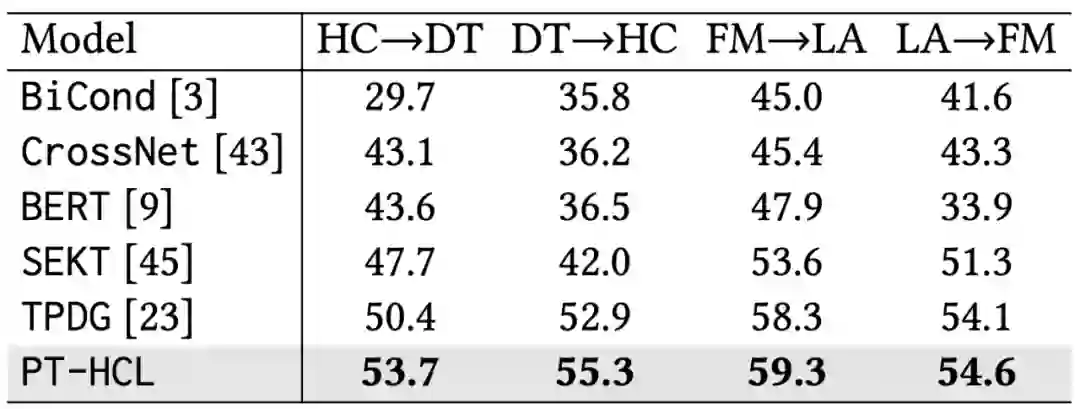
随后,我们将提出的方法应用到少样本立场检测和跨目标立场检测任务中。实验结果表明,我们的方法可以直接作用于少样本立场检测和跨目标立场检测任务,并取得最优性能。
▲ 表2:VAST数据集上的少样本立场检测实验结果
▲ 表3:SEM16数据集上的跨目标立场检测实验结果
结论
本文针对零样本立场检测提出了一种非常简单且有效的对比学习框架:基于代理任务的分层对比学习(PT-HCL)方法。该方法借助一个代理任务(pretext task)确定训练数据的立场表达类型:即立场表达是特定于目标(目标相关)还是无关于目标(目标无关)。随后,我们设计了一种新颖的分层对比学习损失函数,使模型在区分立场表达类型的基础上区分样本的立场类别。
实验结果表明,本文提出的方法在不同数据集的零样本立场检测任务中都取得了最优性能。同时,我们的方法也能直接迁移至少样本立场检测(few-shot stance detection)和跨目标立场检测(cross-target stance detection)任务,并取得最佳性能。此外,我们的方法无需任何额外的外部知识或监督信号,也能很好地迁移至其他的零样本分类任务。
梁斌(1993-),哈尔滨工业大学(深圳)计算机学院博士研究生,主要研究方向包括情感分析、立场检测、文本挖掘。E-mail: bin.liang@stu.hit.edu.cn
陈子潇(1998-),哈尔滨工业大学(深圳)计算机学院硕士研究生,主要研究方向为立场检测。E-mail: chenzixiao@stu.hit.edu.cn
感谢 TCCI 天桥脑科学研究院对于 PaperWeekly 的支持。TCCI 关注大脑探知、大脑功能和大脑健康。
如何才能让更多的优质内容以更短路径到达读者群体,缩短读者寻找优质内容的成本呢?答案就是:你不认识的人。
总有一些你不认识的人,知道你想知道的东西。PaperWeekly 或许可以成为一座桥梁,促使不同背景、不同方向的学者和学术灵感相互碰撞,迸发出更多的可能性。
PaperWeekly 鼓励高校实验室或个人,在我们的平台上分享各类优质内容,可以是最新论文解读 ,也可以是学术热点剖析 、科研心得 或竞赛经验讲解 等。我们的目的只有一个,让知识真正流动起来。
📝 稿件基本要求:
• 文章确系个人原创作品 ,未曾在公开渠道发表,如为其他平台已发表或待发表的文章,请明确标注
• 稿件建议以 markdown 格式撰写,文中配图以附件形式发送,要求图片清晰,无版权问题
• PaperWeekly 尊重原作者署名权,并将为每篇被采纳的原创首发稿件,提供业内具有竞争力稿酬 ,具体依据文章阅读量和文章质量阶梯制结算
📬 投稿通道:
• 投稿邮箱: hr@paperweekly.site
• 来稿请备注即时联系方式(微信),以便我们在稿件选用的第一时间联系作者
• 您也可以直接添加小编微信(pwbot02 )快速投稿,备注:姓名-投稿
△长按添加PaperWeekly小编
🔍
现在,在「知乎」 也能找到我们了
进入知乎首页搜索「PaperWeekly」
点击「关注」 订阅我们的专栏吧