ACM MM 2021|复旦大学开源Meta-FDMixup:使用极少的标记目标数据帮助CD-FSL模型学习

极市导读
本文为复旦大学团队在ACM Multimedia2021上的工作,本文提出使用极少一部分target带标注数据来帮助模型的学习。 >>加入极市CV技术交流群,走在计算机视觉的最前沿
一、写在前面
这篇文章是我们团队发在ACM Multimedia2021上的工作,主要是做cross-domain few-shot learning,文章主要提出使用极少一部分target带标注数据来帮助模型的学习。
-
出处:ACM multimedia 2021 -
title:Meta-FDMixup: Cross-Domain Few-Shot Learning Guided by Labeled Target Data -
link:https://arxiv.org/abs/2107.11978 -
code:https://github.com/lovelyqian/Meta-FDMixup -
video:https://www.bilibili.com/video/BV1xT4y1f7B6?spm_id_from=333.999.0.0
目前所有需要用到的splits, codes,models都已开源,欢迎大家多多关注!:(点颗star嘻嘻
二、主要内容
2.1 background
首先介绍一个Cross-domain Few-shot Learning (CD-FSL)这个任务,关于Few-shot Learning (FSL),Domain Adaptation(DA),CD-FSL的直观理解图如下所示:
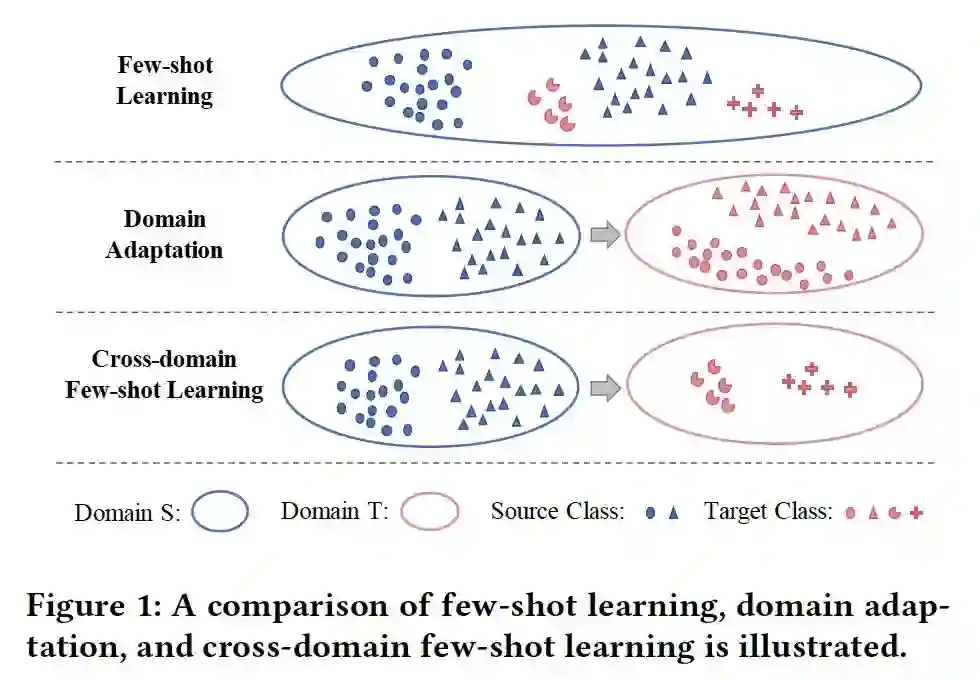
FSL: 经典的小样本学习从源域迁移知识到目标域:1)源域和目标域处于同一个domain(分布基本一致);2)源域和目标域的类别集合的交集为空;3)目标域每个类别的可用样本量极少;
DA: 领域自适应也是从源域迁移知识到目标域:1)源域和目标域之间存在domain gap;2)源域和目标域的类别集合相同;3)目标域每个类别的可用样本量是足够的;
CD-FSL: 在FSL的基础上集合了DA的特点:1)源域和目标域之间存在domain gap;2)源域和目标域的类别集合的交集为空;3)目标域每个类别的可用样本量极少;
可以看到CD-FSL任务是非常challenging的。
2.2 related work
从setting上来看,根据模型训练阶段是否可以获取到target数据,我们基本可以将方法分为:
1)只有source data用于训练;以Feature-wise Transformation (FWT)为代表
2)source data + 大量unlabeled target data;工作Self-training for Few-shot Transfer Across Extreme Task Differences中提出;
这里的第一种setting自然是最接近真实场景但同样也对算法最具挑战的任务,在这样1)可用样本少;2)存在domain gap的情况下,我们认为没有任何来自target的信息,仅仅通过源域数据来提升模型的生成泛化能力确实能带给模型的性能提升是非常有限的。
这里的第二种setting但某些现实情况下是比较合理的,例如从miniImageNet迁移到医疗图像,这种情况下无标注target数据是比较容易获取的。但是当我们的target数据是fine-grained鸟类或者植物,这个setting就不那么容易实现。
2.3 setting motivation
相比之前的两种setting,我们提出了一种更加现实可操作的场景:不管target data是鸟类,植物,还是医疗,获取极少数量的属于target domain标注数据其实并不是一件难事(现有benchamark本身有可以使用的这部分数据,即使没有,人工标注产生极少一部分这样的标注数据代价也不高)。
因此,我们首先提出learning CD-FSL with extremely few labeled target data。为了便于区分,我们将这部分数据成为auxiliary data。
三、learn CD-FSL with extremely few labeled target data
接下来我们介绍我们具体的setting,以及具体如何获取到这部分auxiliary data。
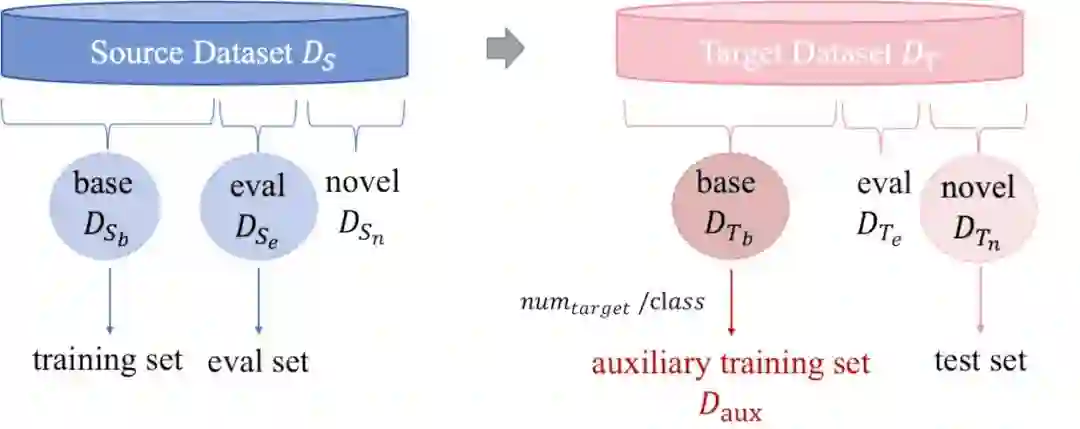
在FWT提出的benchmark中,我们从source datatset迁移知识到target dataset中,而每个dataset都被分成类别不相交的base/eval/novel(具体的原因是因为例如这里的source是mini-Imagenet,mini-Imagenet本身作为FSL的数据集,自然需要disjoint的base/eval以及novel sets,而正如上文所述,现实中我们可以自行进行划分,或者手工标注来实现这样的setting),标准的CD-FSL就是将source base 用于模型训练, source eval 用于模型验证,最终在target novel 上进行模型测试,当然还可以测试模型在source eval 上的性能。
在我们的setting下,我们将未曾被利用起来的target base 做为来自target domain的额外数据,来引导模型的学习。具体而言,对于每个 中的类别,我们随机采样 个样本 (最终方法中, ),这些样本共同构成我们的auxiliary data 。
这里要强调的一点是:由于我们获取 的 本身与测试集 的类别之间就是不存在任何交集的,因此我们并没有破坏基本的CD-FSL setting。
那在我们的定义下,问题变成了:如何利用好 以及 这两部分数据,使得模型在 以及 上达到一个不错的效果。
四、方法介绍Meta-FDMixup
4.1 method motivation
我们刚刚在介绍setting的时候已经把问题提炼出来了,更加直观的解释可以看下图:

这里主要存在的两个难点问题是:
-
原本的source training data 和新引入进行的auxilary data 之间是unbalanced并且disjoint的。unbalanced指的是前者每个类别的样本量充足,而后者每个类别的样本量很少;disjoint的意思是这两个数据的类别集合交集为空。 -
source和target之间依然存在的domain gap问题。
针对以上两个问题,文章给出的思路是:
-
用mixup模块来混合利用这两个unbalanced并且disjoint的数据; -
用disentangle模块来抽取出domain相关的特征和domain无关的特征,最后仅用domain无关的特征进行分类。
4.2 overall framework
整体的网络框架图如下所示:
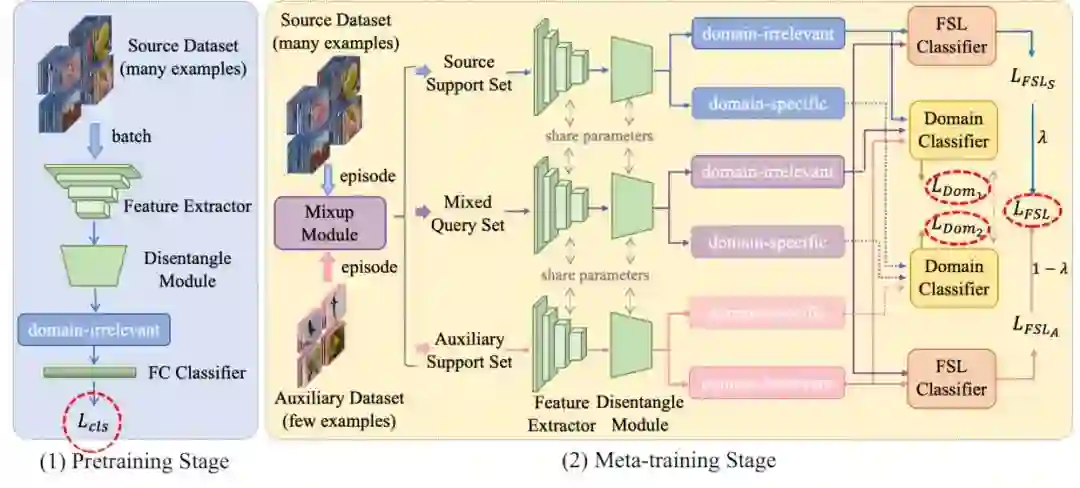
文章主要包括以下五个模块:
-
feature extractor:用于提取整体视觉特征; -
disentangle module:从整体视觉特征中拆解domain-irrelevant以及domain-specific features; -
mixup module:对来自source的training data和auxiliary data进行mixup,以便充分使用各个数据; -
FSL classifier:根据domain-irrelevant features对episode中的query images进行分类,得到分类结果; -
domain classifier:判断输入特征来自哪个domain,进而用于监督disentangle module的学习;
整体的训练过程分为两个部分:1)pretrain;2)meta-train
pretrain阶段:
-
用从source training data中随机采样出来的mini-batch + 经典cross entropy 分类loss 对模型进行训练优化; -
pipeline:minibatch --> feature extractor --> disentangle module,取其中的domain-irrelevant features --> FC classifier --> loss -
这个阶段主要是为了获取更好的特征提取器,让第二阶段的meta-train更加容易些;
meta-train阶段:
-
采用两路episode的采样方式,用meta-learning的方法对模型进行训练优化;
-
pipeline:
1) 随机从source的training data 和auxiliary data 中采样两个episode;
2) 用mixup模块对以 的比例对这两个episode的query set进行混合,保持各自的support sets不变,得到source support set, auxiliary support set,以及mixed query set;
3) 对source support set, auxiliary support set,以及mixed query set这三路都各自依次送入feature extractor以及disentangle module中,获取各自的domain-irrelevant features, domain-specific features;
4) FSL tasks:将source support set和mixed query set送入FSL classifier进行分类,得到小样本分类loss , 由于这里mixed query只包含 比例原始的source query set,我们认为mixed query属于原来GT的置信度为 ,因此这部分的最终loss为 。同理,将auxiliary support set和mixed query set送入FSL classifier进行分类,得到loss为 。最终的小样本分类loss就是 。
5) domain classification tasks:将三个domain-irrelevant features送入到domain classifier中进行分类,这部分分类希望能够混淆domain classifier,得到loss 。将三个domain-specific features送入到domain classifier中进行分类,这里希望domain classifier能够正确分类feature来自哪个domain,得到loss (具体方法后面会介绍)。最终的domain分类loss就是 。
6) 用小样本分类loss + domain分类loss共同优化整个model。
4.3 modules
在我们的五个模块中,特征提取器和小样本分类器分别是ResNet-10以及GNN。
接下来主要介绍其他的三个。
4.3.1 meta-mixup model
原始的mixup处理的是同一类别集合内的数据,我们将其扩展到我们的task中,具体的方法为:
-
由于小样本分类需要依赖可靠的support set来对query set进行分类,所以这里保持source和auxiliary的support set不变,仅仅混合query set。
-
此外,混合比例 不直接用于改变被混合图像的类别标签,而是认为mixed query属于原本类别的置信度有 (虽然从数学上是一致的)。
形象化的表示如下图:
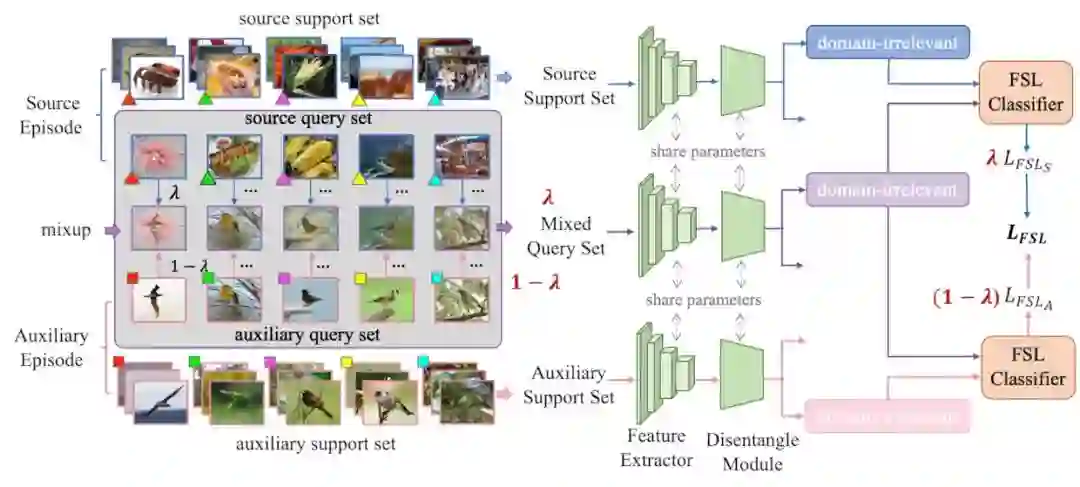
左半部分展示了mixup的过程,可以看到我们的meta-mixup模块对于输入的source episde和auxiliary episode,会获取到source support set,mixed query set,以及auxiliary support set。其中support set保持原来的不动,而mixed query set是由 比例的source query和 比例的target query共同构成的,这里的混合比例 跟原始mixup一致,每次随机从beta分布中采样,即每一轮的 是不一样的,且 。
右边展示了后续的小样本分类过程,基本思路在overall framework里都介绍过了,就是分别拿mixed query跟两个support sets进行分类,最后的loss要乘上各自的置信度 或者是 。
4.3.2 disentangle module and domain classifier
disentangle模块设计:
整个模块的设计参考了VAE的encoder结构,但是我们这里没有用decoder,并且我们会encode出两个latant vector,一个是domain-irrelevant features,另一个是domain specific features。
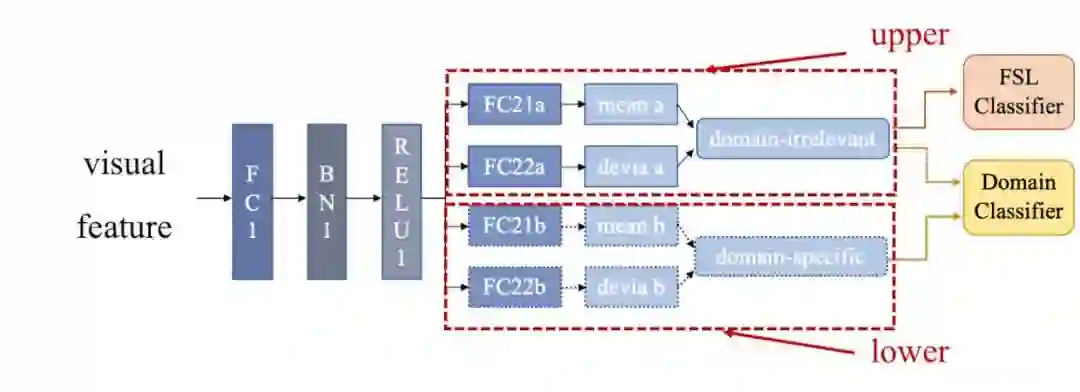
整个想法是:
-
希望domain-irrelevant features 能够混淆domain classifier -
而domain-specific features则能被准备地识别出来自哪个domain -
最后只用domain-irrelevant features来用作FSL分类器的输入。
监督信息:disentangle模块的学习是由domain classifier监督的。
分别用1和0表示source domain/target domain,具体的loss function构成如下:
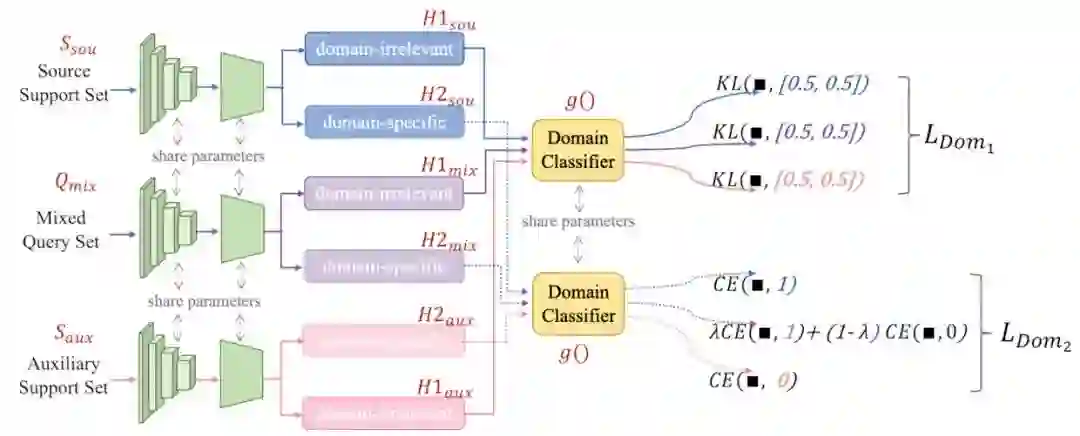
loss的构成跟上面的想法是一致的:
-
的GT是[0.5, 0.5], 用KL散度进行度量; -
的GT是各自的domain label (1或0),用Cross Entropy loss进行度量。
五、实验结果
我们在FWT的benchmark上做了实验,主要对比了几个经典的FSL methods,几个simple but reasonable的baselines,以及FWT (当时很多新的CD-FSL方法还没发表)
5.1 的选择
-
分别试了 = 5, 10, 15, 20的结果
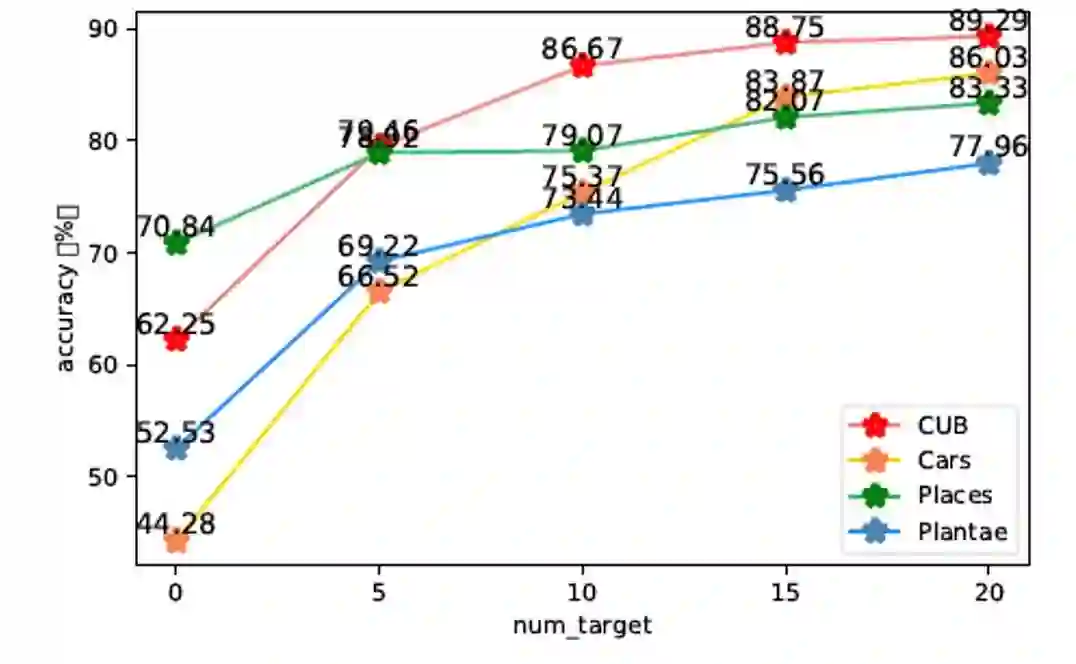
实验结果:
-
整体呈上升趋势; -
有一个边际递减效应,从0-5的增幅最多,后面的增幅减缓; -
考虑到实际结果都现实标注需要产生的代价,所有的setting都选择 。
5.2 主结果
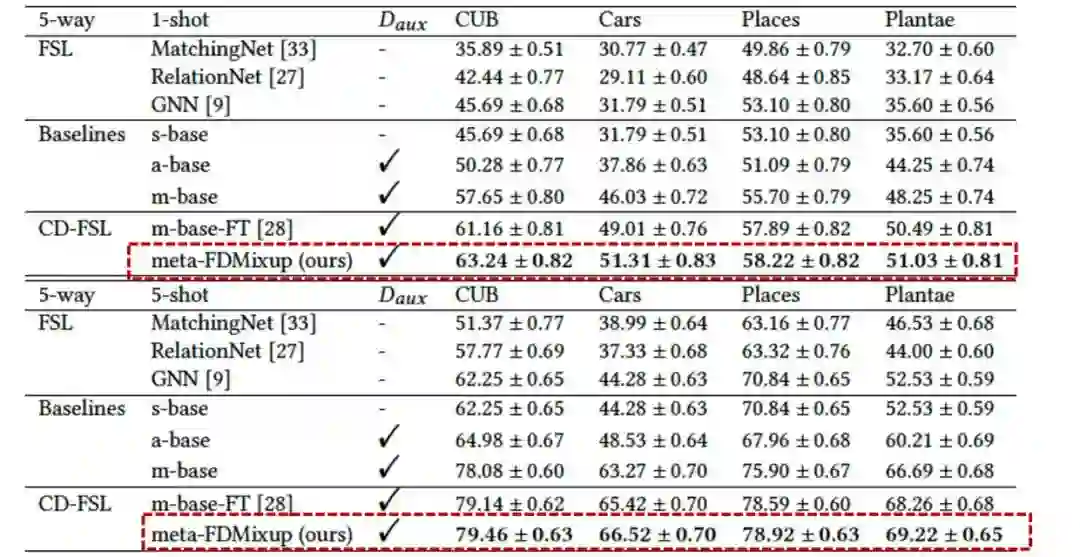
相比于GNN base,不管是1-shot还是5-shot,在四个target dataset上平均达到了15%以上的性能提升。
5.3 可视化
用CAM做了可视化,这个图主要是为了说明target dataset带来了什么,所以对比的是在Imagenet pretrain的feature extractor的方法。
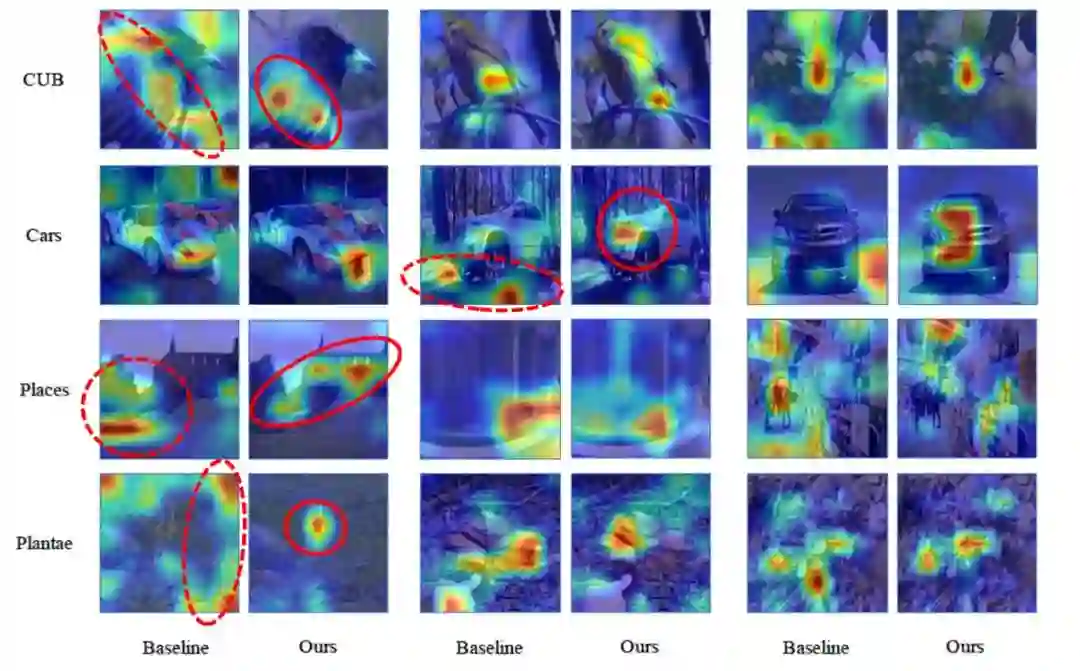
可以发现只在mini-Imagenet上训练的模型会对更加接近mini-Imagenet的东西感兴趣,例如树枝/山/背景等,但是会忽略真正对识别target classes有用的区域。而我们的方法在auxiliary data的帮助下能成功关注到那些关键的区域。
六、写在最后
这篇文章的setting还是挺现实的,也确实能给模型带来很多的性能提升,希望正在考虑CD-FSL方向的大佬们多多关注呀!!!
ps:code都开源了,求star求三连呜呜,如果有引用就更好了!~~
如果觉得有用,就请分享到朋友圈吧!
公众号后台回复“transformer”获取最新Transformer综述论文下载~

# CV技术社群邀请函 #

备注:姓名-学校/公司-研究方向-城市(如:小极-北大-目标检测-深圳)
即可申请加入极市目标检测/图像分割/工业检测/人脸/医学影像/3D/SLAM/自动驾驶/超分辨率/姿态估计/ReID/GAN/图像增强/OCR/视频理解等技术交流群
每月大咖直播分享、真实项目需求对接、求职内推、算法竞赛、干货资讯汇总、与 10000+来自港科大、北大、清华、中科院、CMU、腾讯、百度等名校名企视觉开发者互动交流~




