【NeurIPS2021】由相似性迁移的弱样本细粒度分类

数据及代码已开源:https://github.com/bcmi/SimTrans-Weak-Shot-Classification
基础种类有强标注(clean label)的图片,而新种类只有弱标注(noisy label)的图片。弱标注的图片可以使用类别名称在公共网站上检索来获得,这是一个有潜力的数据源来支持新种类的学习而不耗费任何的人工标注。研究如何从基础种类向新种类迁移信息,解决新种类训练图片标签噪音的问题。
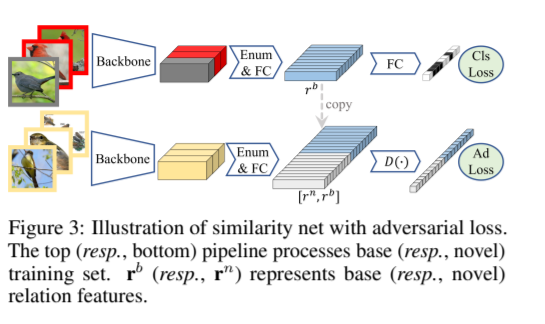
我们方法的训练阶段由两部分组成:在基础种类训练集上学习相似度网络;在新种类数据集上学习主分类器。相似度网络的架构如图3所示,它输入一批图片,然后输出每一对图片之间的相似度分数。其中的枚举层把每一对图片的骨干网络特征拼接起来,称之为关系特征。然后通过全连接层对拼接起来的特征输出相似度分数。相似度分数由分类代价函数监督,如果一对图片是来自于同一个种类,那么就是"相似"种类,反之则为"不相似"种类。如果自由地抽取一批图片,那么绝大多数图片对是来自于不同的种类。所以为了减少相似对和不相似对的不均衡问题,对于每一批图片,我们首先选择少量的种类,然后再从少量的种类中抽取图片。
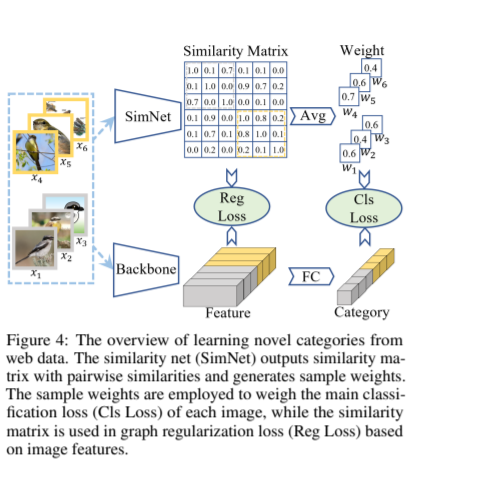
对于单个新种类中网络图片来说,我们可以发现标签正确的样本通常占大多数。当在单个新种类中计算每一对图片的相似度时,我们可以发现标签错误的样本与其他大部分图片都不相似。因此,我们可以根据一张图片是否与其他图片相似来判断它标签的正确与否。对于每一个新种类,我们首先利用预训练好的相似度网络计算该种类中所有图片对的相似度,得到了一个相似度矩阵,然后我们利用某个图片与其他所有图片的相似度的平均作为该图片的代价函数权重。 然后所有图片的权重规范化到均值为1。最后,将图片的权重应用于分类的代价函数中。通过这样的方式,我们对标签错误样本的分类代价函数施加更低的权重。
当直接在新种类训练集上学习的时候,特征图结构,也就是图片特征之间的相似度,被噪声标签所主导。例如,噪声标签的代价函数隐式地拉近具有相同标签的图片的特征距离。然后这样的特征图结构可能被噪声标签所误导,所以我们试图用迁移来的相似度来纠正被误导的特征图结构。具体地,我们使用经典的图正则化来规范特征,使得语义相似的图片对的特征相近。 网络图片主要有两种噪声:异常值和标签翻转。异常值指图片不属于任务中所考虑的任何种类,而标签翻转指图片的真实标签是所考虑种类中的一种。对于标签翻转噪声,上文介绍的样本权重方法直接通过分配更低的权重抛弃了它们。然后图正则化可以利用它们来保持合理的特征图结构和帮助特征学习。方法细节和实验结果请参见论文。
专知便捷查看
便捷下载,请关注专知公众号(点击上方蓝色专知关注)
后台回复“WFGC” 就可以获取《【NeurIPS2021】由相似性迁移的弱样本细粒度分类》专知下载链接







