COCO新纪录64.5mAP!InternImage:注入新机制,扩展DCNv3,探索视觉大模型

极市导读
本文提出了一种新的基于CNN的大尺度基础模型InternImage,它通过类似ViT提升参数量与训练数据等方式取得了大幅性能提升。首个参数达1B、训练数据达400M并取得与ViT相当、甚至更优的CNN方案。 >>极市打榜|18.5G+数据集免费使用,无人机视角的检测算法上新!

论文链接:https://arxiv.org/abs/2211.05778
代码链接:https://github.com/OpenGVLab/InternImage
不同于近来聚焦于大核的CNN方案,InternImage以形变卷积作为核心操作(不仅具有下游任务所需的有效感受野,同时具有输入与任务自适应空域聚合能力)。所提方案降低了传统CNN的严格归纳偏置,同时可以学习更强更鲁棒的表达能力。ImageNet、COCO以及ADE20K等任务上的实验验证了所提方案的有效性,值得一提的是:InternImage-H在COCO test-dev上取得了新的记录65.4mAP。
出发点
通过提升参数量(>1B)、大尺度训练数据(+JFT300),ViT在大尺度模型方面取得了巨大成功,大败CNN、大幅提升了一系列CN任务(含分类、检测以及分割等)的性能边界。尽管如此,作者认为:当加持类似ViT的算子/架构设计、参数提升以及大尺度数据后,CNN基础模型同样可以取得与ViT相当甚至更好的性能。
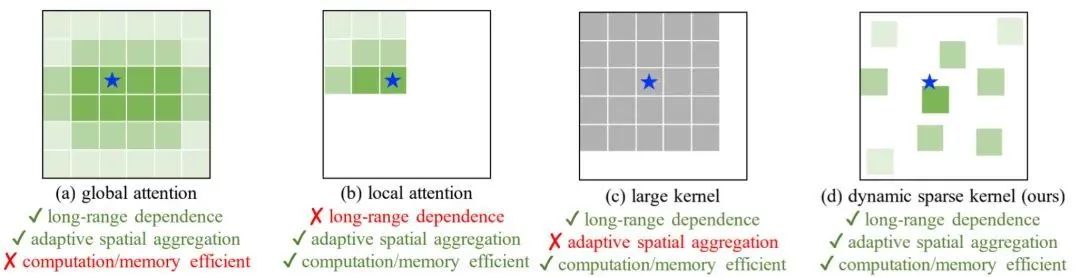
作者首先对CNN与ViT的差异性进行了总结:
-
从算子维度来看,ViT的多头自注意力(MHSA)具有长程建模与自适应空域聚合能力(见上图a); -
从架构维度来看,ViT包含一系列先进的成分,如LN、FFN、GELU等; -
从感受野角度来看,大核卷积方案在性能与模型尺度方面与ViT相比仍存在差距。
作者以DCNv2算子为基础,通过对其扩展得到DCNv3,然后参考ViT从block与架构维度进行定制化得到了本文所提InternImage(见上图d)。本文贡献包含以下三点:
-
提出一种新的大尺度CNN基础模型InternImage,也是 首个参数达1B、训练数据达400M并取得与ViT相当、甚至更优的CNN方案。这说明:对于大尺度模型研究,卷积模型同样是一个值得探索的方向。 -
通过将长程依赖、自适应空域聚合引入到DCNv3,作者成功的对CNN进行了大尺度扩展,同时还对模块定制化、堆叠规则以及缩放策略进行了探索。 -
图像分类、目标检测、语义分割以及实例分割等任务实验结果验证了所提方案的有效性。值得一提的是:InternImage-B仅需ImageNet-1K训练即可取得84.9%的精度(比其他CNN方案至少高出1.1%); 当引入大尺度参数(1B)、大训练数据(427M)后,InternImage-H取得了89.2% ;在COCO任务上, InternImage-H以2.18B参数量取得了65.4%mAP指标,比SwinV2-G高出2.3%,同时参数量少27% 。
本文方案
一种最简单的弥补卷积与MHSA差距的方式:将MHSA的长程依赖与自适应空域聚合引入到常规卷积。作为常规卷积的广义形式,DCNv2空域描述为如下形式:
其中,K表示采样点数,表示第k个采样点的投影权值,表示第k个采样点的调制因子(它通过 进行归一化), 表示预定义的网格采样 表示第 个采样位置的偏移。从上述公式可以看到:
-
对于长程依赖而言, 采样偏移 足够灵活, 可以对短/长程特征进行交互; -
对于自适应聚合而言, 采样偏移 与调制因子 均可学习且与输入x有关。
因此,DCNv2所具有的与MHSA类似优异属性驱动我们基于该算子研发大尺度CNN基础模型。
在已有的实践中,DCNv2往往作为常规卷积的扩展,加载常规卷积的预训练权值后进行微调以达成更优性能。这种使用方式不适用于需要从头开始训练的大尺度视觉基础模型。为解决上述问题,作者对DCNv2进行了如下扩展改进:
-
Sharing weights among convolutional neurons. 类似常规卷积, DCNv2的不同卷积单元具有独立的线性投影权值, 其参数量与内存复杂度与采样点成线性关系, 这无疑会大幅限制其在大尺度模 型方面的高效性。针对于此, 受启发于分离卷积, 作者将原始的卷积权值 th调整为depthwise(对应位置感知调制因子 )与 point-wise(对应采样点间共享投影权值w) 两部分。 -
Introducing multi-group mechanism. 多组/头设计源于组卷积, 但在MHSA中得到广泛应用, 可用于在不同位置从不同表达子空间学习更丰富的信息。受此启发, 作者将空域聚合过程拆分为 组, 每组具有独立的采样偏移 、调制因子 , 促使不同组具有不同的空域聚合模式, 进而产生更强的特征表达能力。 -
Normalizing modulation scalars along sampling points. DCNv2的调制因子通过Sigmoid进行归一化处理,尽管每个调制因子均在[0,1]范围内,但其和并不稳定,从0到K之间变化,这会导致不稳定的梯度。为消除该不稳定问题, 作者将元素级的Sigmoid归一化调整为沿采样点的Softmax归一化。此时,调制因子的综合为1,这使得整个训练过程更为稳定。
通过组合上述改进,DCNv2成功进化到了DCNv3,描述如下:
其中, G表示聚合组数量。对于第 组, 表示位置不相关投影权值, 表示第 个采样点的调制因子且沿维度 通过 softmax 归一化。总而言之, DCNv3 作为 DCN系列的扩展具有以下几个特性:
-
该算子弥补了常规卷积在长程依赖与自适应空域聚合方面的不足; -
相比MHSA与形变注意力,该算子集成了CNN的归纳偏置; -
相比MHSA与重参数大核,受益于稀疏采样,该算子在计算量与内存方面更为高效。
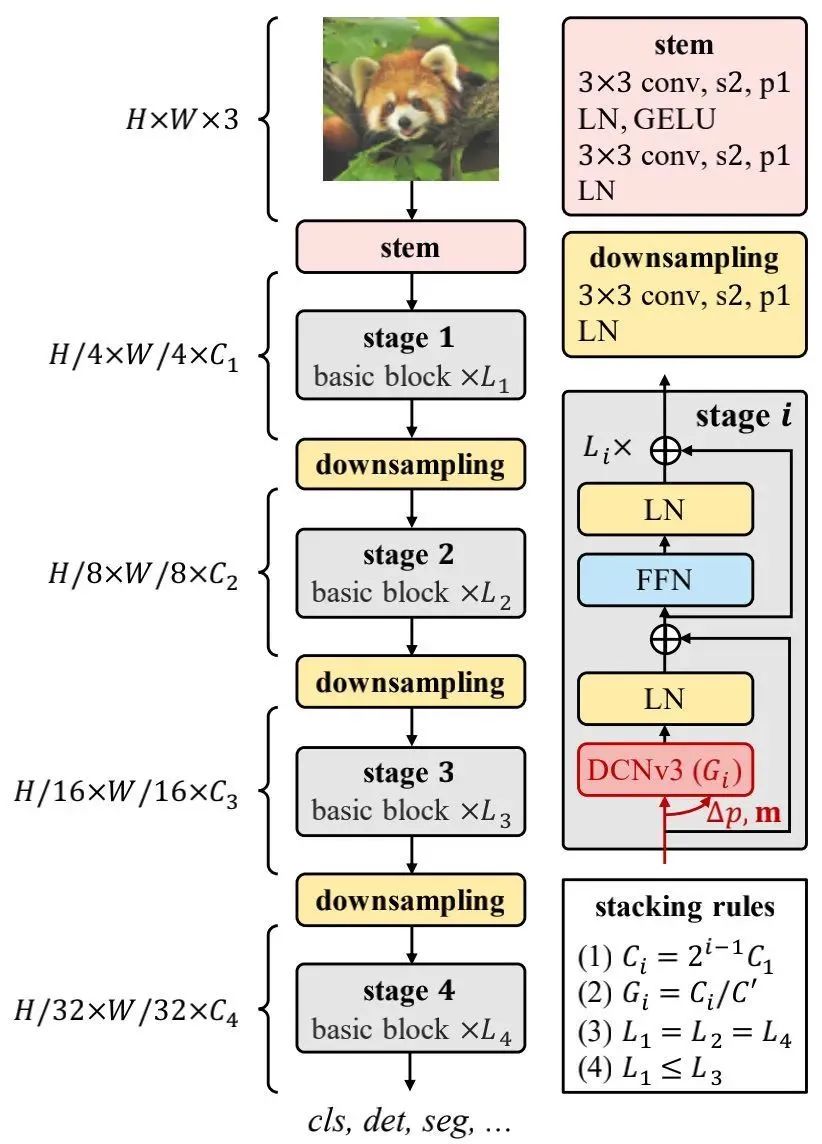
采用DCNv3作为核心算子会带来新的问题:如何构建可以充分利用该算子的模型呢?看上图。
Basic Block 在模块层面,不同于传统CNN常用的BottleNeck,作者采用了ViT的基本模块:加持了更鲜艳的成分(如LN、FFN、GELU),见上图的基本模块示意图,即将ViT模块中的MHSA替换为了DCNv3。需要注意的是:这里采用的post-normalization设置,而非ViT常见的pre-normalization。
Stem & downsampling layers 为获得分层特征,作者采用卷积Stem与下采样层将特征下采样到不同尺度。Stem由两个卷积、两个N、一个GELU构成,卷积核尺寸为3,stride为2,第一个卷积的输出通道维第二个卷积输出通道的一半。下采样层由stride=2的卷积构成,同时后接LN层。
Stacking rules 为更清晰说明模块堆叠过程,作者首先列出了InternImage的超参:
-
: 第i阶段的通道数; -
: 第 阶段DCNv3的组数; -
:第 阶段基本模块的数量。
由于所提模块包含 4 个阶段, 由 12 个超参构成, 该搜萦空间太大了以至于无法详尽的枚举以寻找最佳配置。为减少搜索空间,作者总结出以下 4 条规则:
此时, InternImage仅需 4 个超参 即可进行定义。作者先选择了一 个 参数的模型作为起始模型, 超参空间分别为:
。起始模型的搜索空间仅为 : 我呢?),通过在I mageNet上训练并评估得到了最佳模型配置 。
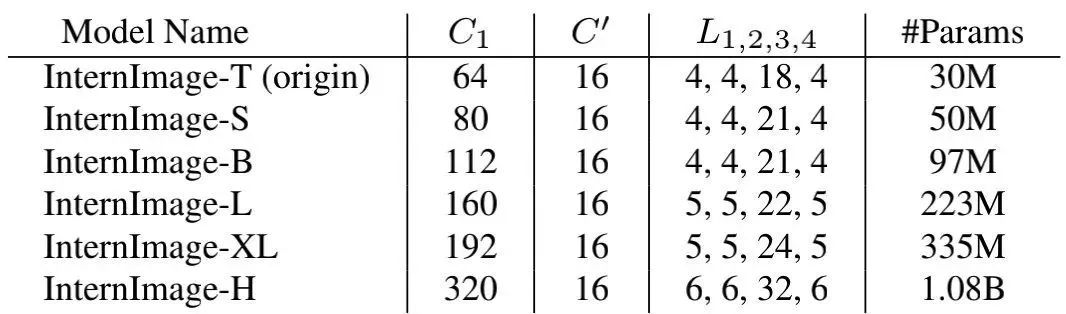
Scaling rules 基于上述最优起始模型, 作者进一步探索了参数缩放规则。具体 来说, 作者考虑了两个缩放维度: 深度 与宽度 并采用 进行缩放。缩放规则定义如下:
其中, 。通过实验, 作者发现最佳缩放配置为详见下表。为进一步探索模型容量, 作者还构建了具有 参数量的InternImage-H.
本文实验
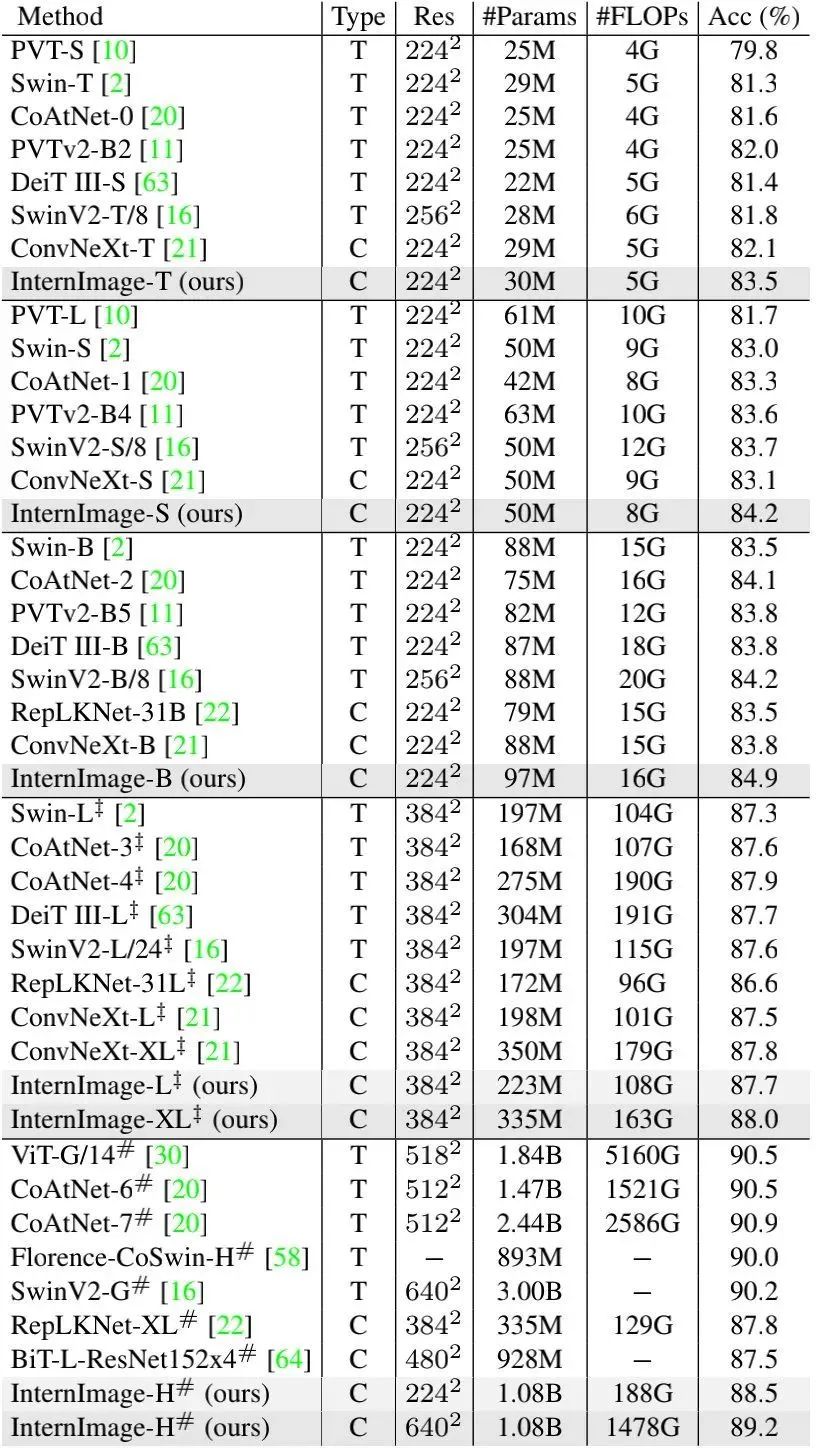
上表给出了不同方案在ImageNet上的性能对比,从中可以看到:
-
在相当参数量与计算消耗时,所提方案具有与其他SOTA ViT与CNN相当、甚至更优的性能; -
InternImage-T取得了83.5%的精度,比ConvNeXt-T高出1.4%,InternImage-S/B比第二方案高出至少0.4% ; -
当采用ImageNet-22K与大尺度数据预训练后, InternImage-XL与InternImage-H的精度提升到了88.0%、89.2% ,优于已有CNN方案,与大尺度ViT的精度差异缩小到了1%。 -
这些结果表明:所提InternImage不仅在常规尺度参数下具有优异性能,同时还可以有效扩展到大尺度参数与数据。
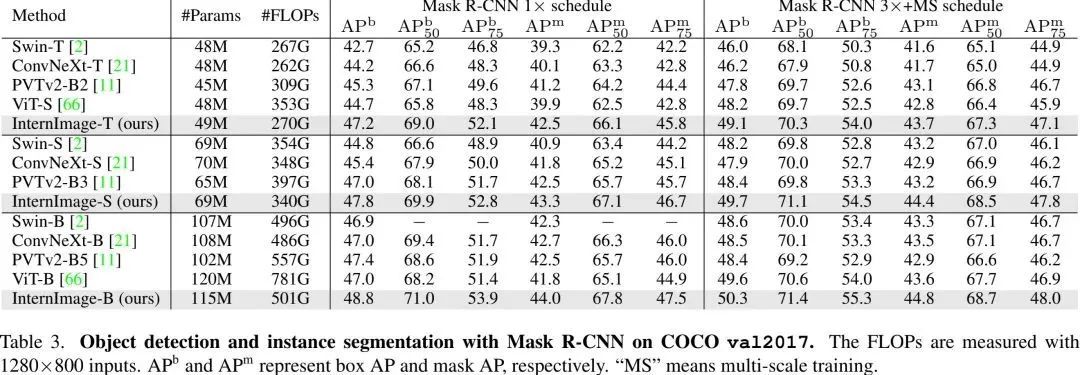
上表给出了Mask R-CNN框架下不同方案的性能对比,可以看到:
-
在目标检测任务方面, 在相当的参数量下,所提方案大幅超越了其他方案。比如, InternImage-T比Swin-T高出4.5mAP,比ConvNeXt-T高出3.0mAP。 -
在实例分割任务方面,InternImage-T取得了42.5 mask AP,比Swin-T高出3.2,比ConvNeXt-T高出2.4.
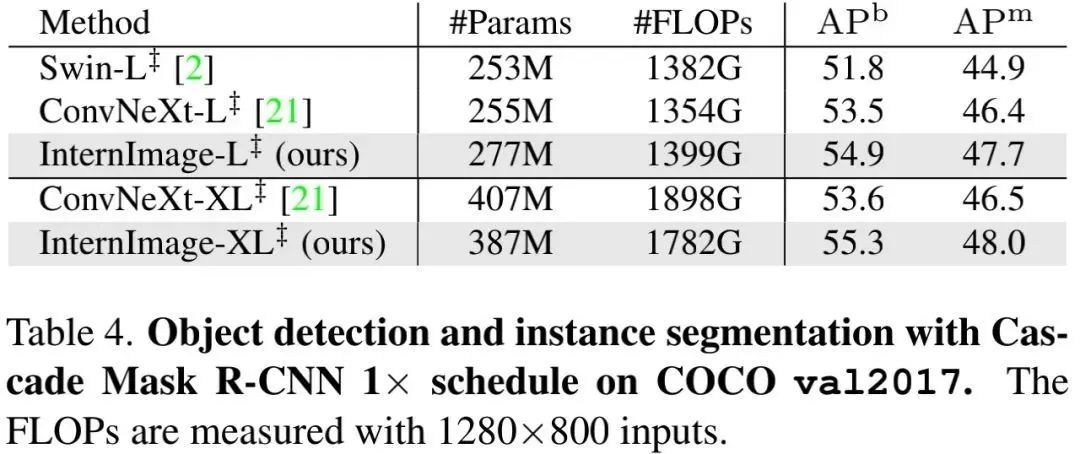
如上表所示,当采用更多参数、更先进的Cascade Mask R-CNN框架后,
-
在目标检测任务上, InternImage-XL取得了55.3mAP,比ConvNeXt-XL高出2.7mAP。 -
在实例分割任务上, InternImage-XL取得了48.0mask AP,比其他方案至少高出1.5 .
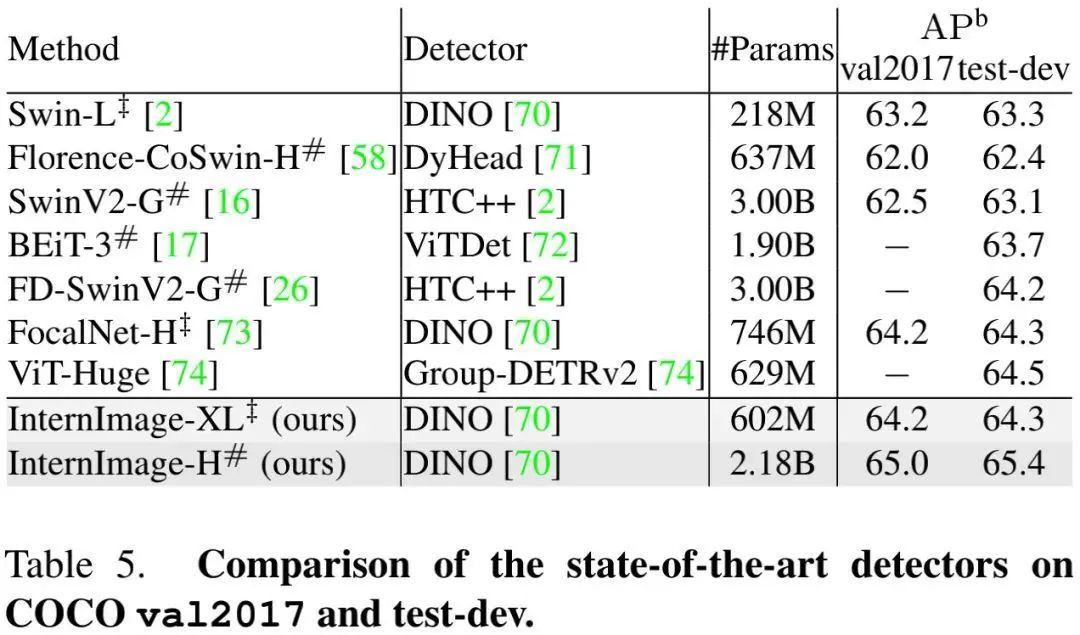
为进一步提升目标检测的性能上限,我们采用了更先进的配置,结果见上表,可以看到:
-
在COCOval2017与test-dev上,所提方案取得了新记录65.0 mAP与65.4mAP; -
相比此前最佳方案FD-SwinV2-G,所提方案指标高出1.2mAP,且参数量少27% 。
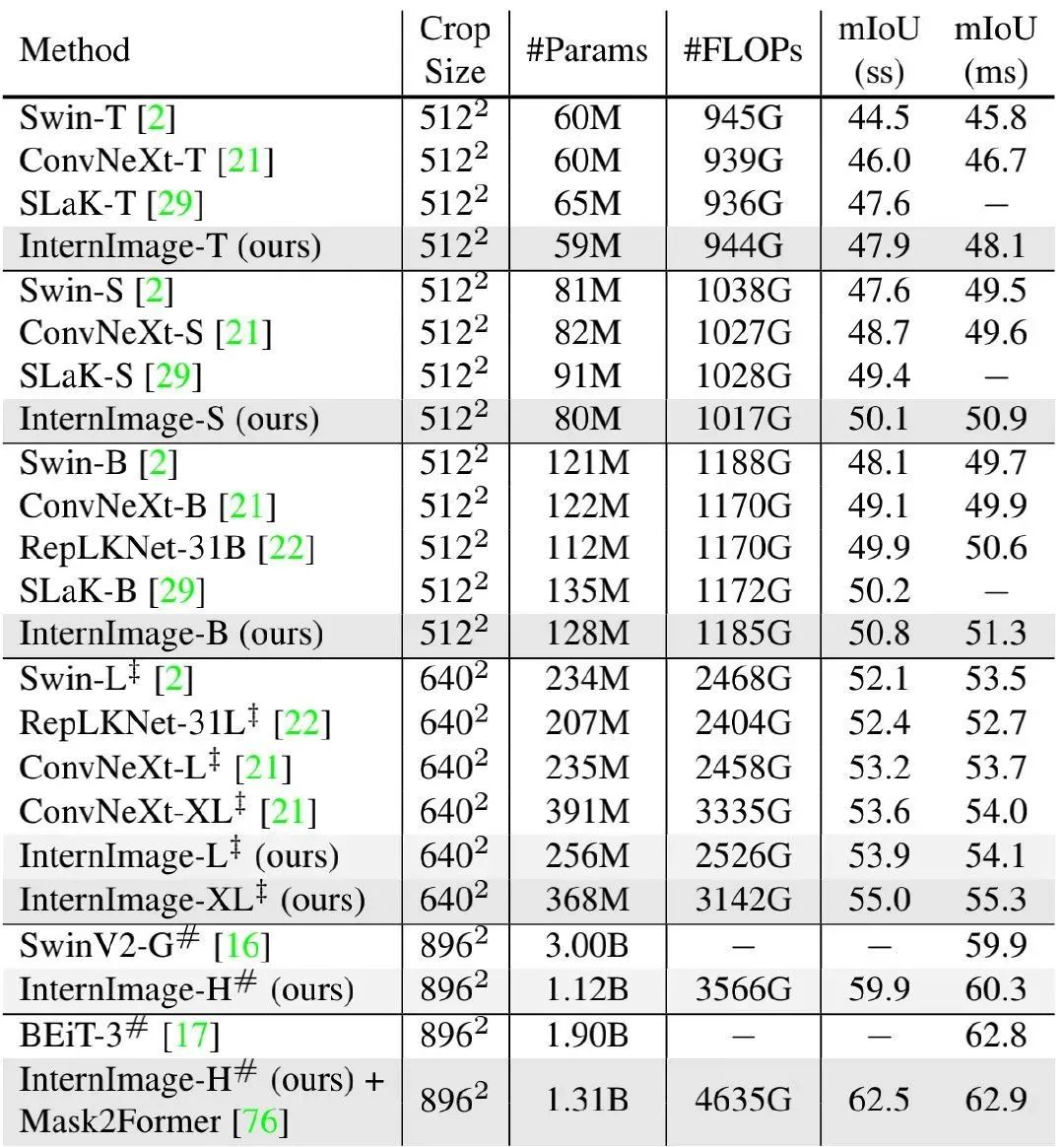
上表给出了ADE20K分割任务上的性能对比,从中可以看到:
-
当采用uperNet框架时,所提方案在不同尺度下均优于其他方案;当采用Mask2Former框架+多尺度测试时,InternImage-H取得了62.9mIoU,比同期方案BEiT-3高0.1mIoU; -
InternImage-B取得了50.8mIoU,比ConvNeXt-B高出1.7mIoU,比RepLKNet-31B高出0.9mIoU; -
InternImage-H取得了60.3mIoU,比SwinV2-G高出0.4mIoU,同时参数量更少(1.2B vs 3.0B)。
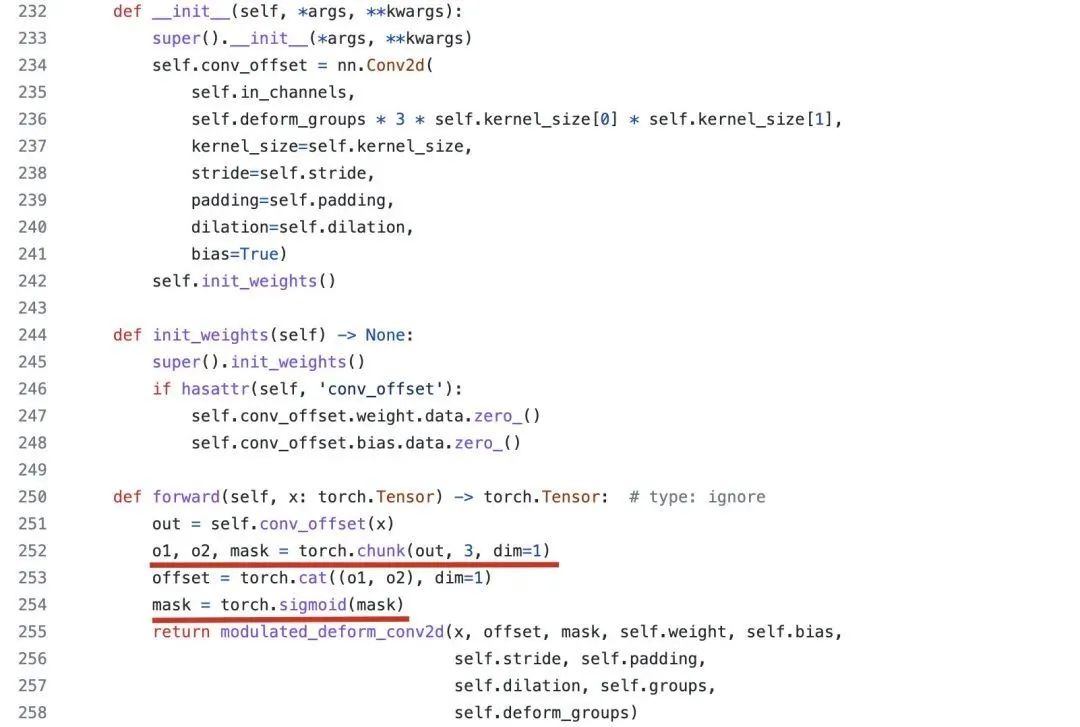
在代码方面,作者尚未开源,不过相比DCNv2,DCNv3更多是体现在引入新机制,如调制因子生成方式、多组机制、规范化方式。可基于MMCV的扩展算子ModulatedDeformConv2dPack进行简单的说明,见下图。DCNv2中的调制因子与偏移通过conv_offset统计计算得到,而调制因子mask采用的是sigmoid激活。而DCNv3则采用depth-wise计算mask,采用point-wise计算offset,通过该操作可以一定程度减少模型参数量。至于sigmoid到softmax的迭代在实现上就更容易了。最后,说一点:DCNv2实际上已经有了多组(见deform_groups)的概念,应该不算是本文新引入的吧。
公众号后台回复“速查表”获取
21张速查表(神经网络、线性代数、可视化等)下载~

“
点击阅读原文进入CV社区
收获更多技术干货
