阿里淘外商业化广告工程架构实践

分享嘉宾:项铮 阿里 高级技术专家
编辑整理:Hoh Xil
内容来源:大鱼技术沙龙
出品平台:DataFun
注:欢迎转载,转载请留言。
导读:大型广告系统工程方面的主要挑战就是海量数据,快速响应,数据实时和高可用度的要求。本次分享介绍了阿里创新事业群智能营销平台在如何构建高性能、高可用、高效率,低成本的广告系统架构方面所做的诸多工作及实践经验。主要包括:
❶ 智能营销平台的业务
❷ 投放引擎的概念以及在广告平台所处的位置
❸ 重点介绍我们在广告工程架构中遇到的技术挑战和解决思路,以及我们的一些经验
——智能营销平台简介——

智能营销平台依托于阿里创新事业群和阿里大文娱的媒体矩阵 ( 包括神马搜索、UC 头条、优酷、阿里文学、PP 助手、豌豆荚等 ),可以覆盖1亿+的日活用户,在广告主侧,有 10W+ 的活跃广告主,年收入超过百亿,成为阿里淘外变现的主力军。
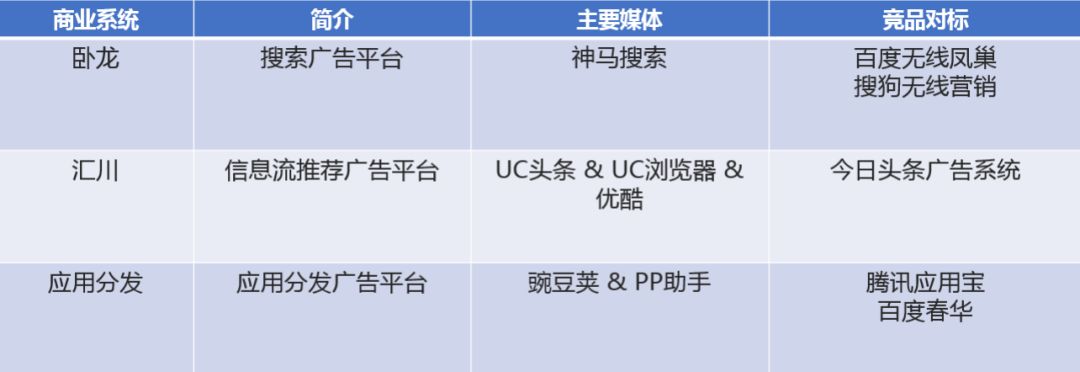
我们的智能营销平台有三大广告系统:
卧龙:搜索广告平台,主要承载神马搜索的搜索广告业务。
汇川:信息流推荐广告平台,属于展示类广告,主要承载 UC 头条、UC 浏览器以及优酷信息流。
应用分发:应用分发广告平台。
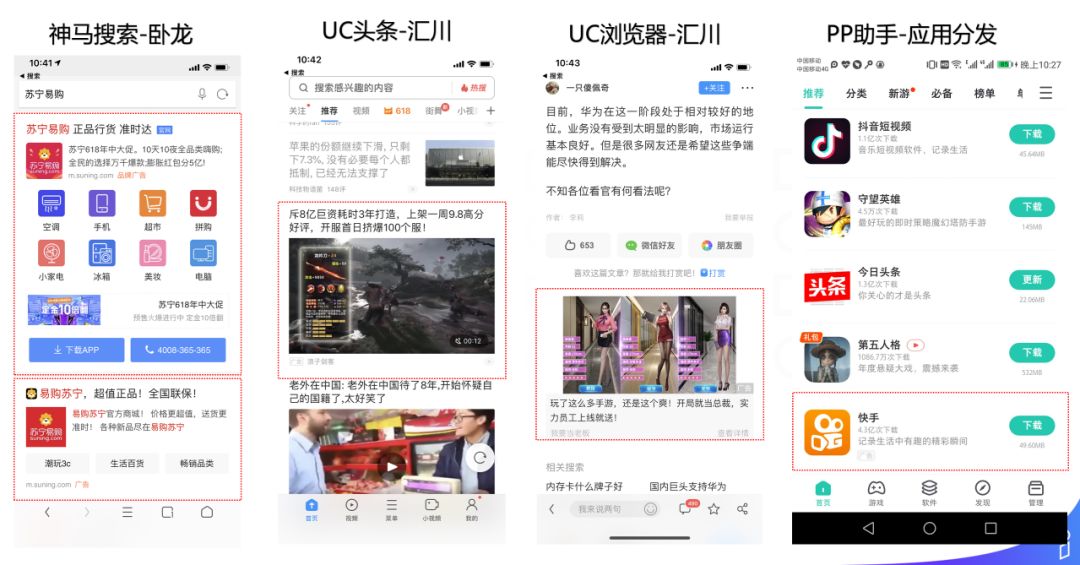
这是我们的广告在媒体上的展现情况:
依托于三大广告平台,覆盖了搜索,信息流,网盟,应用分发等多样的媒体场景,提供了包括 CPT,CPC,CPM,oCPC,oCPM,CPA 等多种多样丰富的玩法,构建了丰富的商业产品矩阵。
——投放引擎简介——
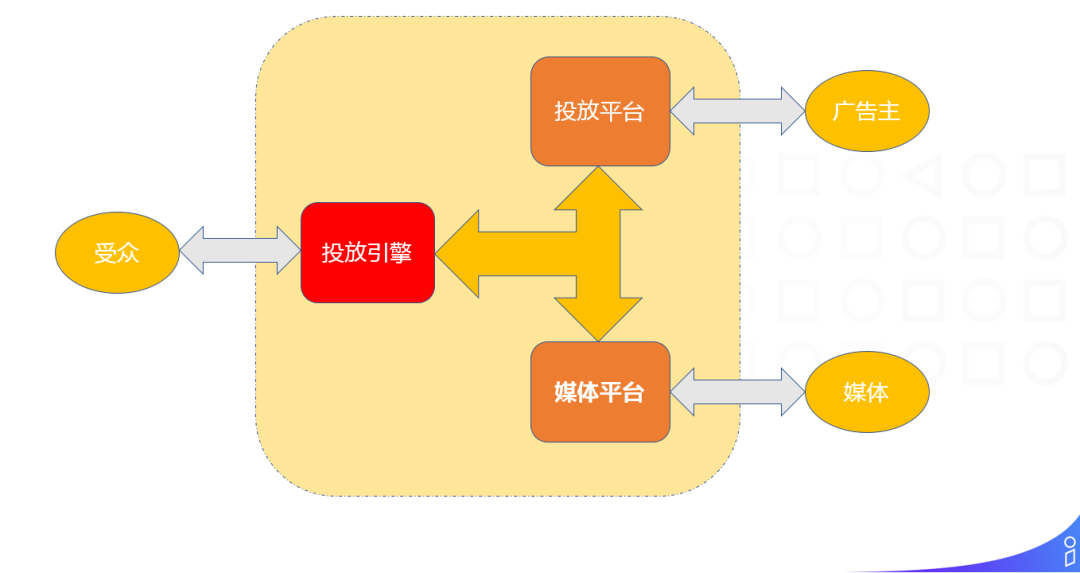
上图明确了投放引擎在整个广告平台中所处的位置。可以看到投放引擎属于偏前端 ( 面向受众 ) 的位置,直接向广告受众 ( 网民 ) 投放广告,进而产生收益。可以说投放引擎的效果直接影响广告平台的收益。
❶ 搜索广告引擎
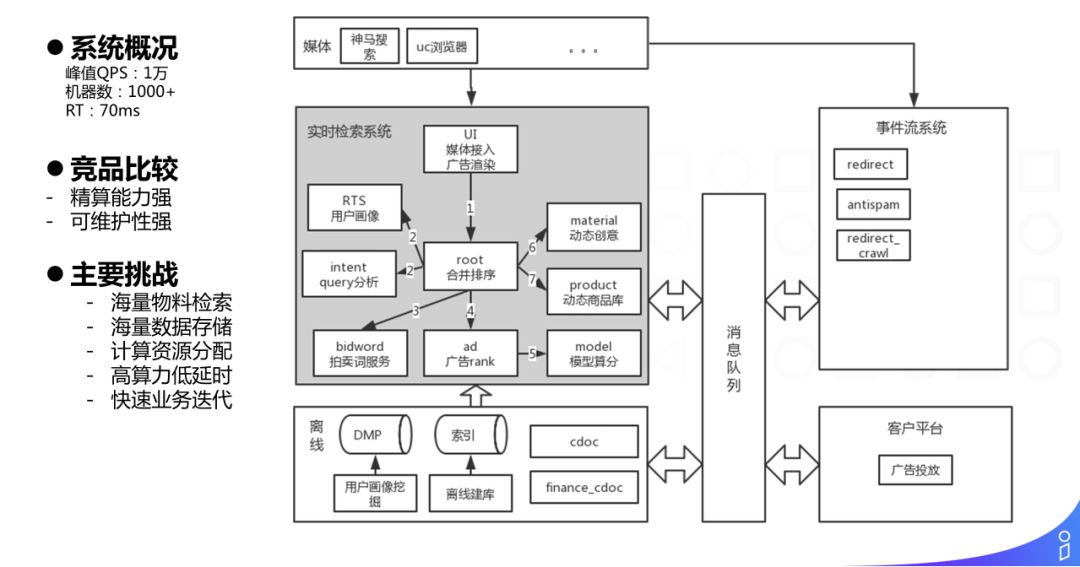
搜索广告架构的典型特点就是系统本身复杂度比较高,简单介绍搜索广告的业务流程:
用户在媒体上发起广告请求 ( 输入 query ) -> 在 UI 接入层完成请求解析 -> 获得用户画像 -> 对用户的 query 进行 query 分析 -> 获取拍卖词服务,召回相应的拍卖词 -> 在 ad 边做相应的召回和检索 -> 模型算分完成粗排 -> 动态创意及商品创意构造 -> 模型算分完成精排及定价 -> 广告创意构建及渲染 -> 返回给用户。
与竞品相比,我们的特点主要体现在精算能力比较强:通过广告正排信息下沉到倒排模块,使得我们的模型精算能力很强,可以计算比较大的广告候选集 ( 超过 1W ),远超竞品,达到了更好的业务效果。
关于我们面临的挑战,稍后会详细介绍。
❷ 展示广告引擎
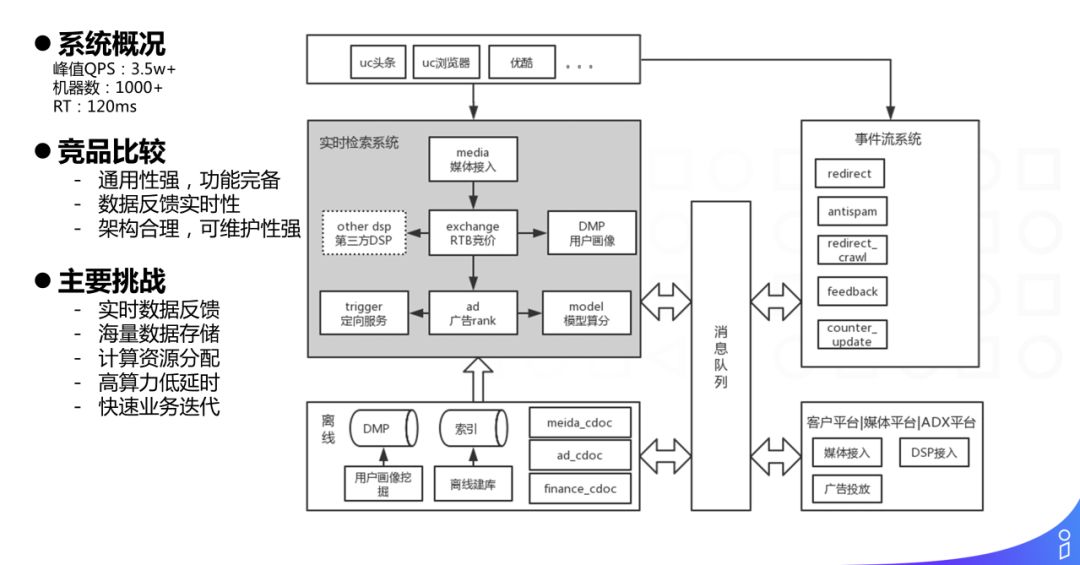
这是我们从0到1实现的一套通用的展示类广告系统。和其他典型的展示类广告系统架构类似,分为上层的 SSP,中间层的 ADX,最底层的 DSP。
与竞品相比较:
① 我们的架构通用性很好。通过复用该广告架构,成功支撑了应用分发的变现业务。
② 其次是数据反馈实时性。我们在媒体渠道广告位、广告主四层账户结构、实验分桶、展点消等多个叉乘维度上的数据统计实时性,可以做到秒级别,对控制超投和匀速消费等功能,提供了很好的保证。
——主要挑战及解决思路——
❶ 主要挑战

海量数据规模:百亿级的广告物料数据,1亿+的日活用户产生的用户行为+基础特征+标签兴趣数据,还包括了海量的广告图片,创意素材等数据。
高性能:高算力和低延时,通俗的讲就是要在尽可能短的时间里计算尽可能多的候选广告。尽可能短的时间就是低延时的要求,这里一般业界都是 200ms 的最大延时;计算尽可能多的候选广告就是高算力。
高可用:广告系统的正常运行分分钟都是钱,需要保证7*24小时的不间断服务。
迭代效率:是工程架构的水平。笼统的讲,就是如何通过组件化,服务化,平台化的思想,提高广告业务开发和策略迭代的效率。主要包括三方面:
① 业务上:发现业务开发上的痛点、共性点、或未来的瓶颈点,进行抽象
② 代码上:拆解交织繁杂的代码逻辑,抽象出基础公共模块组件
③ 架构上:抽象统一通用的技术,框架,服务和平台,便于别的团队或业务使用和扩展
❷ 整体思路
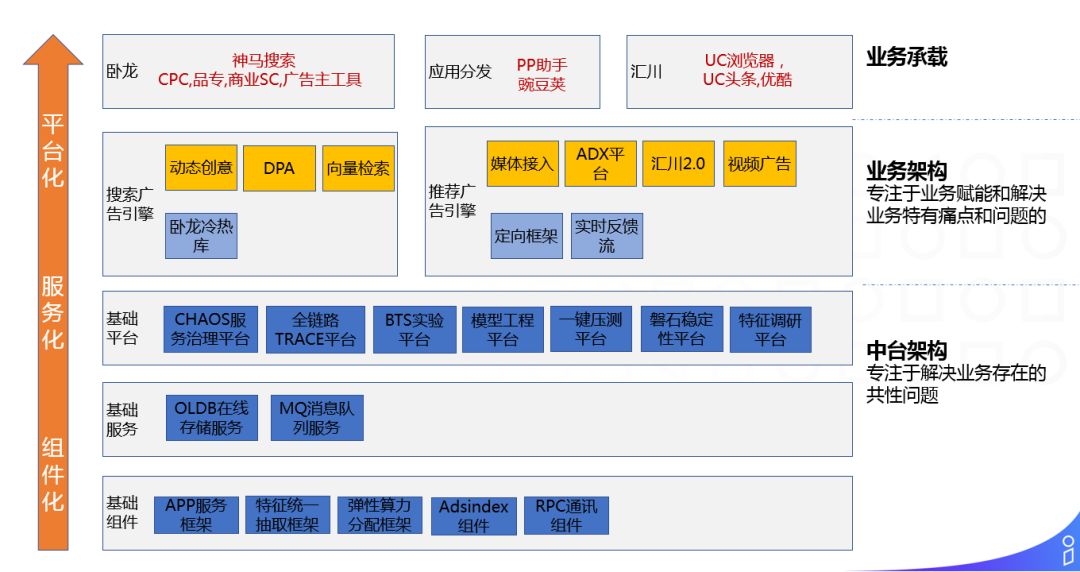
广告工程架构整体的思路主要从两方面开展,分别是业务架构和中台架构。
业务架构:专注于业务赋能和解决业务特有痛点和问题。比如在搜索广告中会做一些动态创意,商品检索库等事情。对于展示类广告,比如媒体接入平台以及广告交易平台 ADX 等,都是展示类广告所需要做的事情;另一方面通过针对性的架构优化解决业务的特有问题 ( 如冷热库,定向框架,实时反馈流等 ),综合来推动业务的发展。
中台架构:专注于解决广告业务或者广告工程所存在的共性问题,通过组件化 -> 服务化 -> 平台化发展来解决。例如:
① 基础组件:APP 服务框架、特征统一抽取框架、弹性算力分配框架、Adsindex 组件、RPC 通讯组件。
② 基础服务:满足业务海量数据存储需求的 OLDB 在线存储系统,以及 MQ 消息队列服务。
③ 基础平台:CHAOS 服务治理平台,全链路 TRACE 平台,BTS 实验平台,模型工程平台,一键压测平台,磐石稳定性平台,特征调研平台。
接下来会从海量数据规模、高性能、高可用、迭代效率四个方面分别谈一下我们的解决思路和实践经验:
❸ 海量数据规模
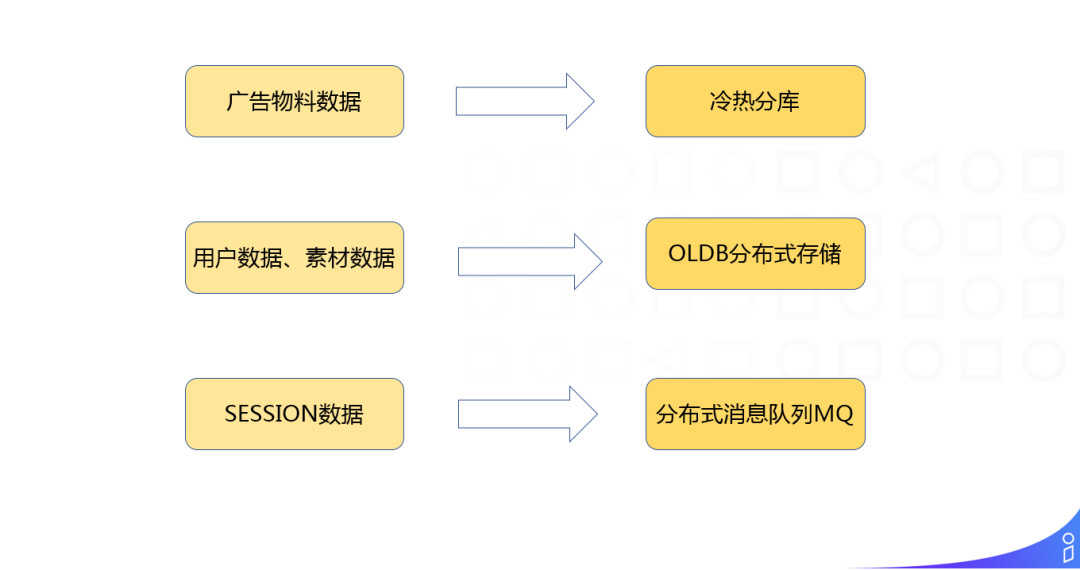
海量数据规模,主要包括3部分:
广告物料数据:搜索广告所特有的,对应的解决方案是冷热分库。
用户数据、素材数据:通过 OLDB 分布式存储来存储这些数据。
SESSION 数据:持久化的存储放在 Hadoop 或者集团内的 ODPS 上,但是如何从检索系统中实时的获取到,我们使用的是分布式消息队列 MQ。
❶ 冷热分库
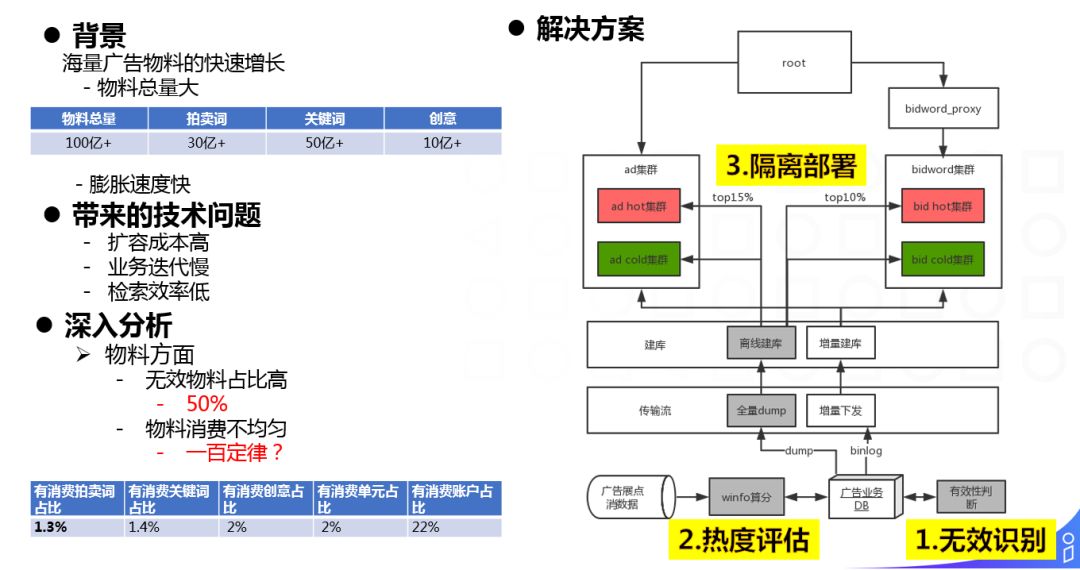
背景:冷热分库的背景就是在搜索广告系统中特有的海量广告物料的快速增长。搜索广告中物料主要来源于广告主的四层账户物料和拍卖词,物料的增加主要来自于广告主的买词和新增创意行为。可以想象,随着广告主规模的扩大,物料一定是海量,并且快速膨胀的。
带来的技术问题:
① 扩容成本高:大家可以看看这张表格,这是17年底的大致情况。随着机器规模的扩大,以往依赖切库增加分片扩容的处理方式难以为继下去。
② 业务迭代慢:数据增长带来建库时间的增加,搜索广告最长的建库达到14小时,留给业务变更上线的时间很短,一定程度上影响了业务的迭代。
③ 检索效率低:进一步影响了业务效果。
深入分析:
① 无效物料占比高。这里的无效是指由于财务,账户,审核,投放状态等原因无法正常投放的物料。这部分物料的占比达到将近50%,浪费了我们系统的计算资源。
② 物料消费有极度的不均匀问题。我这边总结就是一百定律。也就是1%的物料占我们整体的消费的将近100%。
解决方案:
基于上述两点信息,我们的整体解决思路就是在抛出无效物料的基础上,根据价值分对物料进行冷热物理隔离。加载少量高价值物料的热集群使用更多的副本\更长的截断时间和截断数,保证检索基本不会被截断;加载其余低价值物料的冷集群使用更少的副本/更短的截断时间和截断数。旨在通过这种方式,使用更少的机器成本承接更多物料,同时提升在线检索的有效性与性能,进而实现提升广告收益。其流程主要分3步:
① 无效物料识别、逻辑删除
② 物料热度评估、冷热分离
③ 物理隔离部署、业务透明
❷ OLDB
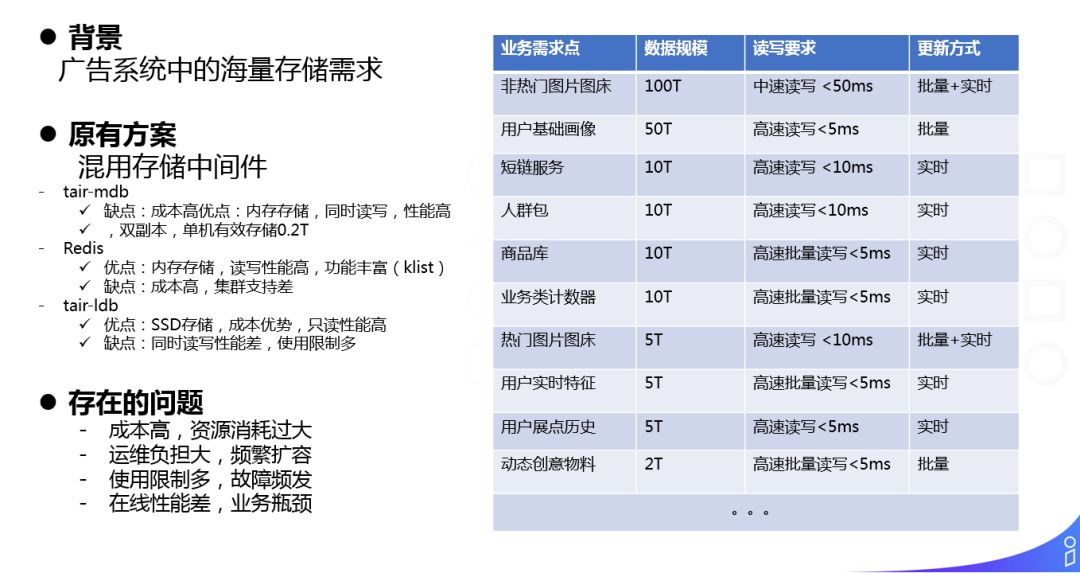
背景:这是我们广告系统中所面临的不同的存储需求,每种存储需求都有不一样的数据规模、读写要求和更新方式。
原有方案:
采用混用存储中间件的方式,如:
-tair-mdb
优点:内存存储,同时读写,性能高,双副本,单机有效存储 0.2T
缺点:成本高
-Redis
优点:内存存储,读写性能高,功能丰富 ( klist )
缺点:成本高,集群支持差
-tair-ldb
优点:SSD 存储,成本优势,只读性能高
缺点:同时读写性能差,使用限制多
存在的问题:
成本高,资源消耗过大
运维负担大,频繁扩容
使用限制多,故障频发
在线性能差,业务瓶颈
问题总结:混用存储中间件的方案,无法有效的支持业务的迭代发展。
我们的经验:有开发过基于 SATA 的图床存储系统 OLDB 的经验。
目标:开发一块基于 SSD 的在线存储系统,完成存储架构的统一。
要求:
① 低成本。以 SSD 为存储介质替代内存,成本缩减
② 高性能。读写毫秒级延时
③ 读写隔离,实时更新。支持实时更新,支持同时读写
④ 功能完善。支持复杂数据结构,如 KV,kList,kCounter 等,支持批量操作
这里我们核心是采用了 nrw 机制和短时超时重试机制。使用 nrw 保证数据的一致性,使用短时超时重试来解决 SSD 所存在的抖动问题。
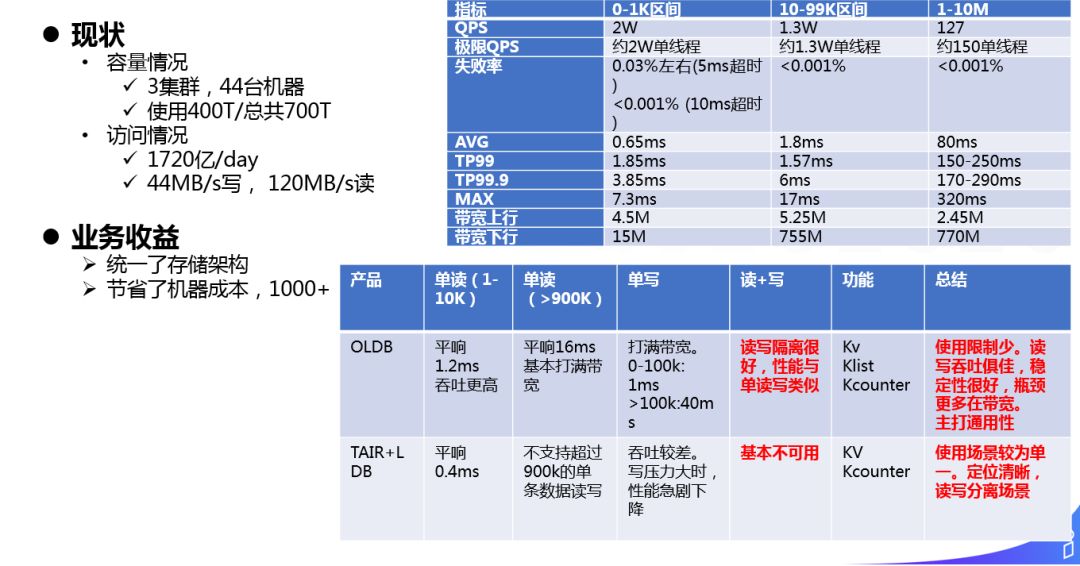
上图为 OLDB 上线后 ( 和 TAIR+LDB 对比 ) 的使用情况:
容量情况:
-集群,44台机器
-使用 400T/总共 700T
访问情况:
-1720亿/day
-44MB/s 写, 120MB/s 读
业务收益:
-统一了存储架构
-节省了机器成本,1000+
❹ 高性能
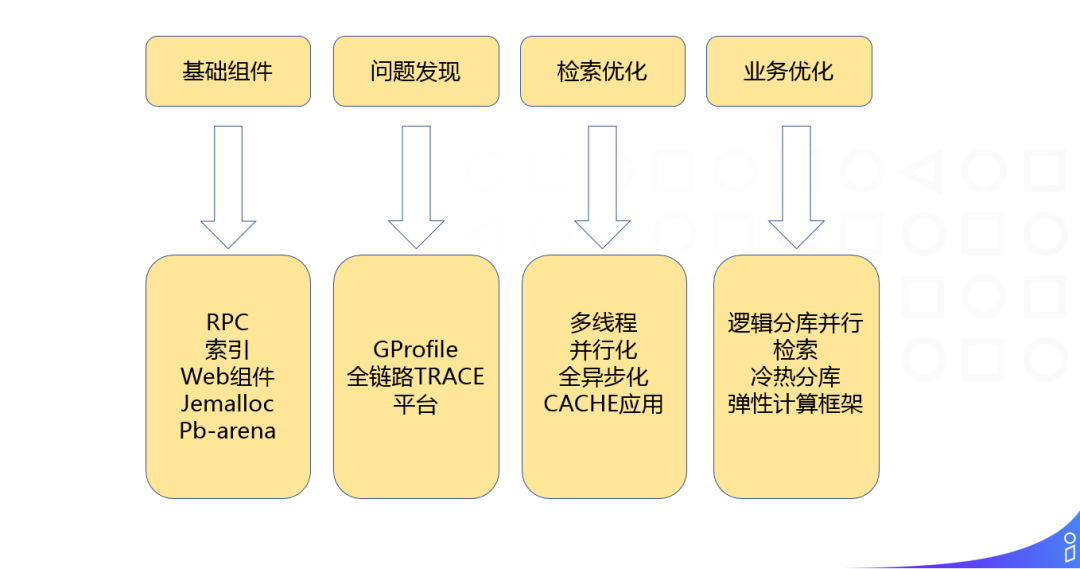
高性能,主要指高算力和低延时,主要包括4部分:
① 基础组件:RPC、索引、Web 组件、Jemalloc、Pb-arena
② 问题发现:GProfile -> 全链路 TRACE 平台
③ 检索优化:多线程手段、并行化加速、全异步化、应用 CACHE
④ 业务优化:逻辑分库并行检索、冷热分库、弹性计算框架
❶ 全链路 TRACE 系统
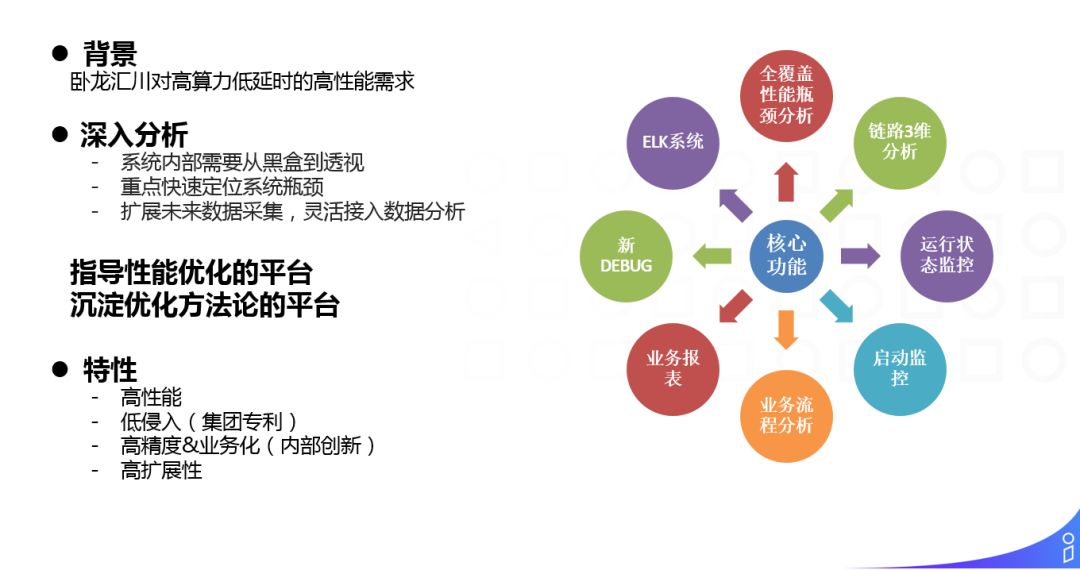
全链路 TRACE 系统就是让我们的系统从黑盒变成透视状态。早先我们对系统的分析,主要通过压测、日志、GProfile 等方式去采集,但是我们基于 Google 的论文,实现了 TRACE 以后,可以细化到 RPC 层或者函数级做监控,计算每个函数或者 RPC 单次调用的时长,以及汇总调用时长,可以非常方便的发现性能上的热点。
主要特点:
① 高性能,单次插入调用<4μs
② 低侵入,嵌入 RPC 对用户无感,函数级调用也是通过无参数 SDK 的方式,对使用者非常友好
③ 高精度&业务化,可以重点对整个系统中 TP90 或者 TP99 这样高耗时的请求做针对性的分析,发现高耗时的 PV 存在热点的消耗是如何的,而之前更多的是从整个系统角度做分析
④ 高扩展性
TRACE 的目的:
① 指导性能优化
② 沉淀优化方法论
❷ 弹性计算框架
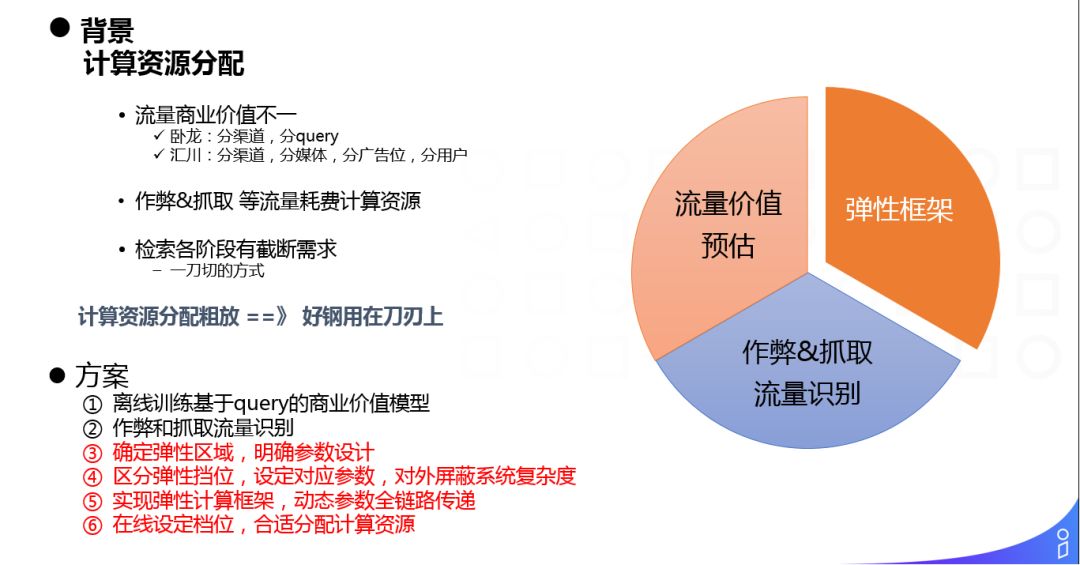
弹性计算框架是广告业务所特有的一些问题。
背景就是我们如何分配计算资源:
① 流量商业价值不一:
搜索广告:分渠道,分query,价值不一
展示广告:分渠道,分媒体,分广告位,分用户,价值不一
② 作弊 & 抓取等流量耗费计算资源
③ 检索各阶段有截断需求。比如召回,我们遍历的广告数目,还有粗排、精排,我们模型计算的广告数量,这些都有一些截断需求。
目标:如何把好钢用在刀刃上。
方案:
① 离线训练基于 query 的商业价值模型,判断流量的商业价值
② 作弊和抓取流量识别
上面都是兄弟部门做的事情,对于广告工程来说,主要是:
③ 确定弹性区域,明确参数设计
④ 区分弹性挡位,设定对应参数,对外屏蔽系统复杂度
⑤ 实现弹性计算框架,动态参数全链路传递
⑥ 在线设定档位,合适分配计算资源
这样我们用有限的资源,在不同质量的流量之间做平衡,达到 offer 高算力的目标。
❺ 高可用
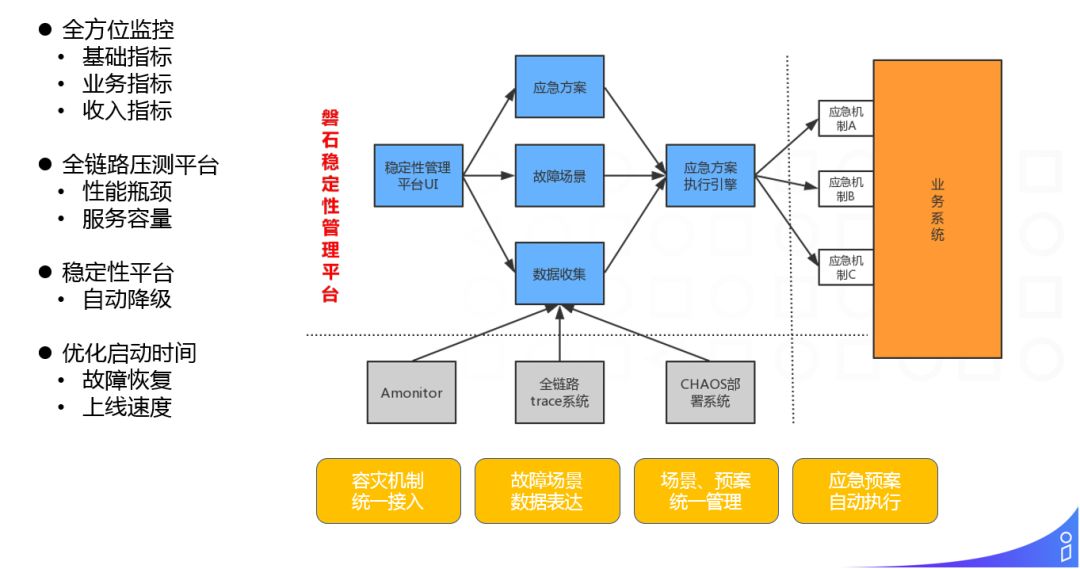
高可用,比较清晰,就是发现问题->解决问题->故障恢复,当发现故障时,我们该如何处理,如何快速恢复。这里说几点:
① 全方位监控:监控包括基础的 CPU,内存,网络,I/O 等监控;业务层的 QPS,水位等;在广告业务中我们还有一些收入上的指标监控。
② 全链路压测平台:帮助我们找到性能瓶颈,并且探底服务容量。
③ 稳定性平台:提供自动降级功能。如:
提供容灾机制的标准规范接入方式
故障场景的数据化表达
故障场景和容灾应急预案统一管理
应急预案的自动执行
优化启动时间:保证在故障出现的时候,能够快速的恢复。
❻ 高效率

迭代效率是工程架构的水平。笼统的讲,就是如何通过组件化,服务化,平台化的思想,提高广告业务开发和策略迭代的效率:
① 业务上:发现业务开发上的痛点、共性点、或未来的瓶颈点,进行抽象。
② 代码上:拆解交织繁杂的代码逻辑,抽象出基础公共模块组件。
③ 架构上:抽象统一通用的技术,框架,服务和平台,便于别的团队或业务使用和扩展。
通过向量检索平台解决向量建库,线上检索召回等问题
通过服务治理平台解决资源管理,应用管理,数据管理,监控报警等问题
❶ 模型工程平台
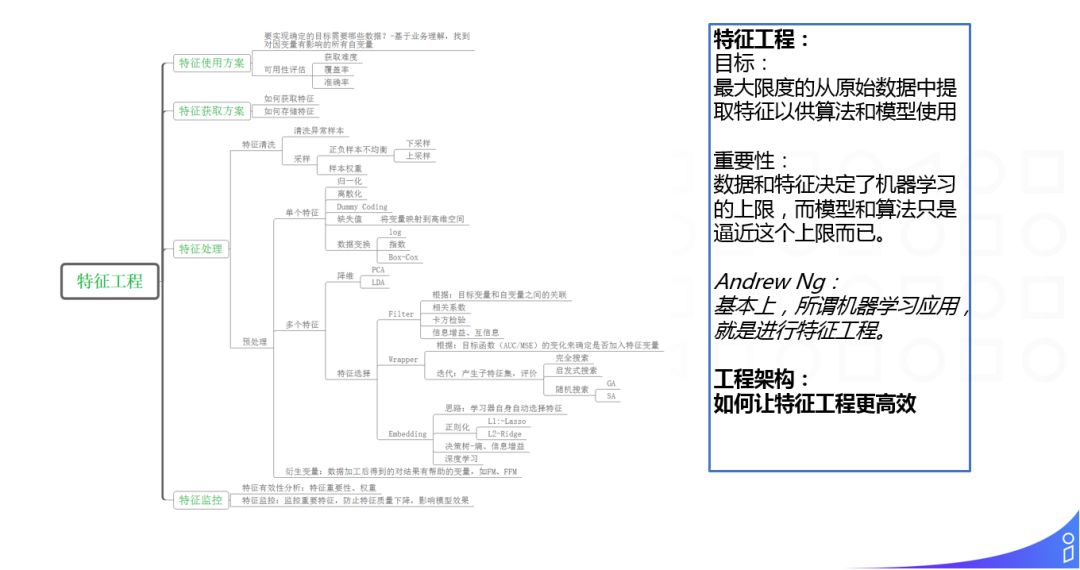
首先明确下特征工程的概念和重要性,引用 Andrew Ng 的一段话 "基本上,所谓机器学习应用,就是进行特征工程",Andrew Ng 说的话虽然可能有些绝对,但也从一个侧面说明了特征工程的重要性。
工程架构实际上是如何让特征工程更加高效。
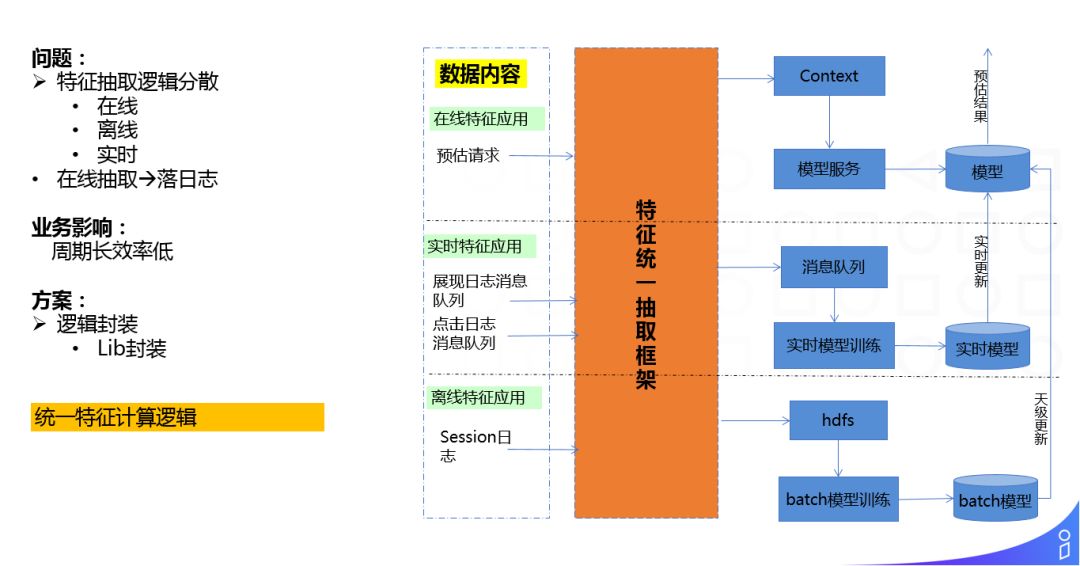
特征这块最主要的问题就是抽取逻辑分散:在线,离线,实时这三个场景下我们有三套不同的抽取逻辑,并且因为可维护性比较差,在离线抽取特征的结构存在着8%的 diff,这就导致后续几乎所有的特征调研都走的是在线抽取+落日志的这种抽取方式,对业务的影响就是特征调研需要攒数据,周期长并且效率低。
这块我们的解决方式使用过 lib 的方式做了逻辑封装,一套代码,到处使用,统一了特征计算逻辑。
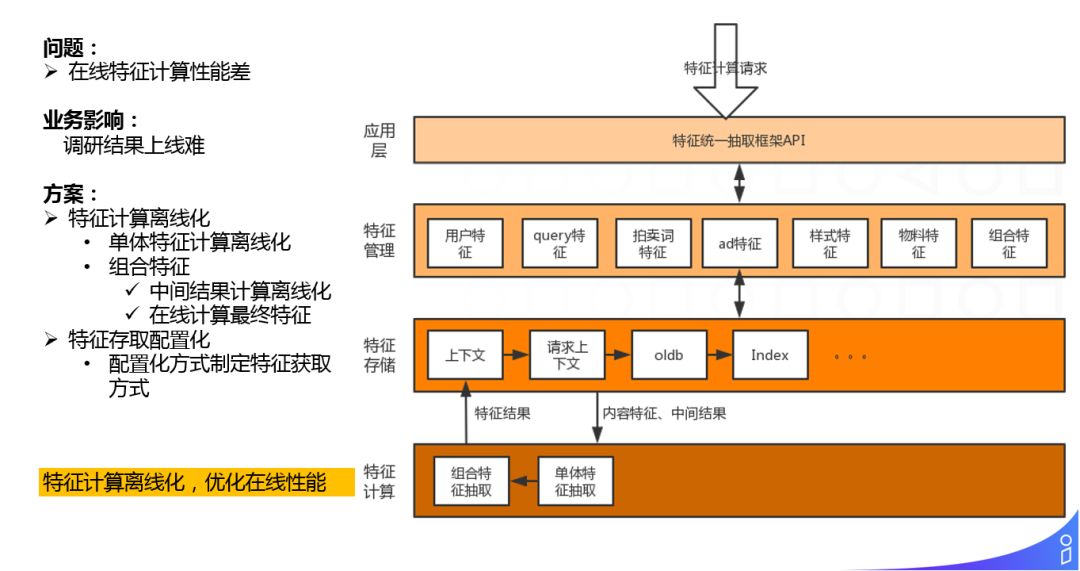
再有就是特征逻辑复杂,在线抽取性能差的问题,这导致了我们的很多特征技术即使调研完成后很有效果,也因为在线性能的原因难于全量上线。
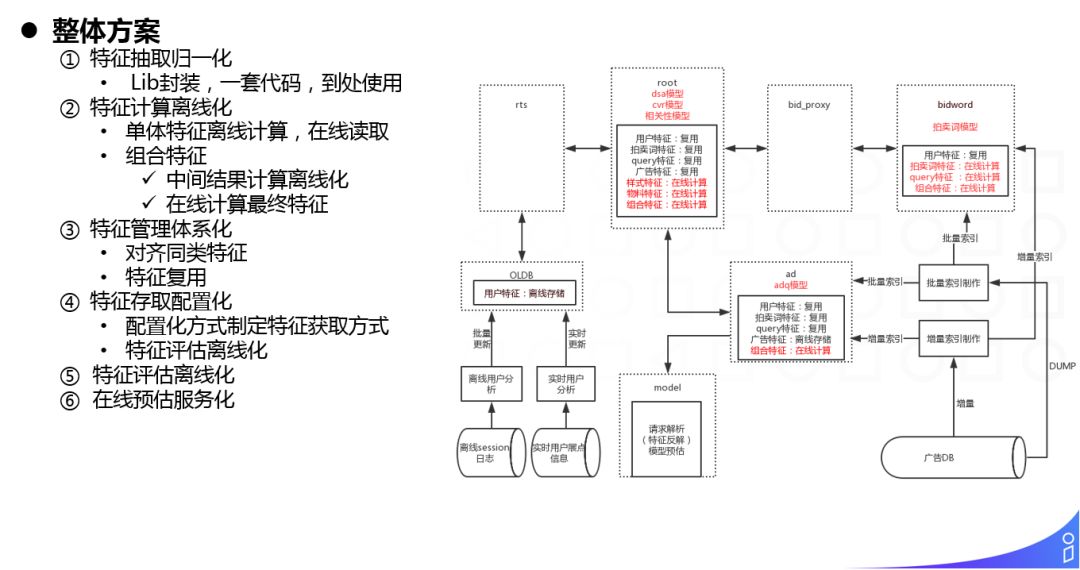
对于这块的我们主要通过特征计算离线化的方式进行优化,大家可以看一下我们系统中用到的主要特征,例如用户特征,query 特征,拍卖词特征,ad... 这些特征都是单体特征,对于这类特征,我们通过离线计算,在线获取的方式进行了优化,对于组合特征,我们离线计算好中间结果,只对最后的 combine 环节做在线计算,最大优化性能。此外,我们还通过插件配置化的定义特征获取的方式,提升了这块的工作效率。
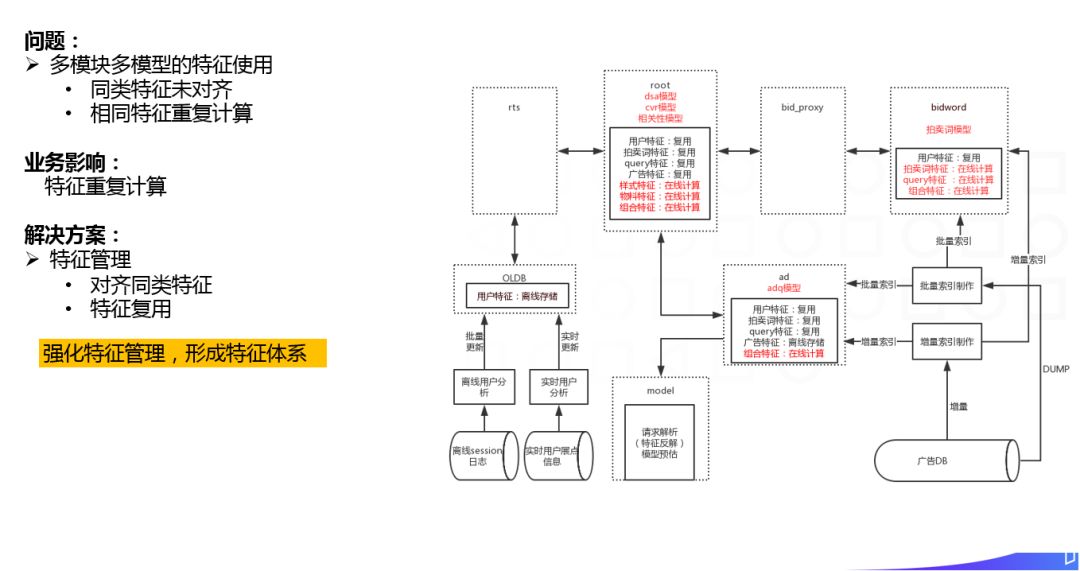
对于多模型的特征使用问题。以我们的卧龙系统为例,比如我们的 root 模块和 ad 模块,都使用到了广告特征,属于同类特征。但 root 的 dsa 模块中广告特征的抽取逻辑和 ad 模块中的抽取逻辑由于历史的原因可能不一致,这就是同类特征的未对齐问题。还有就是即使特征的抽取逻辑完全一致,但实际上也是重复抽取了两次,存在冗余的计算。
对这块我们主要通过强化特征管理,形成了统一的特征体系来解决,相同的特征会在模块间传递,避免重复抽取。
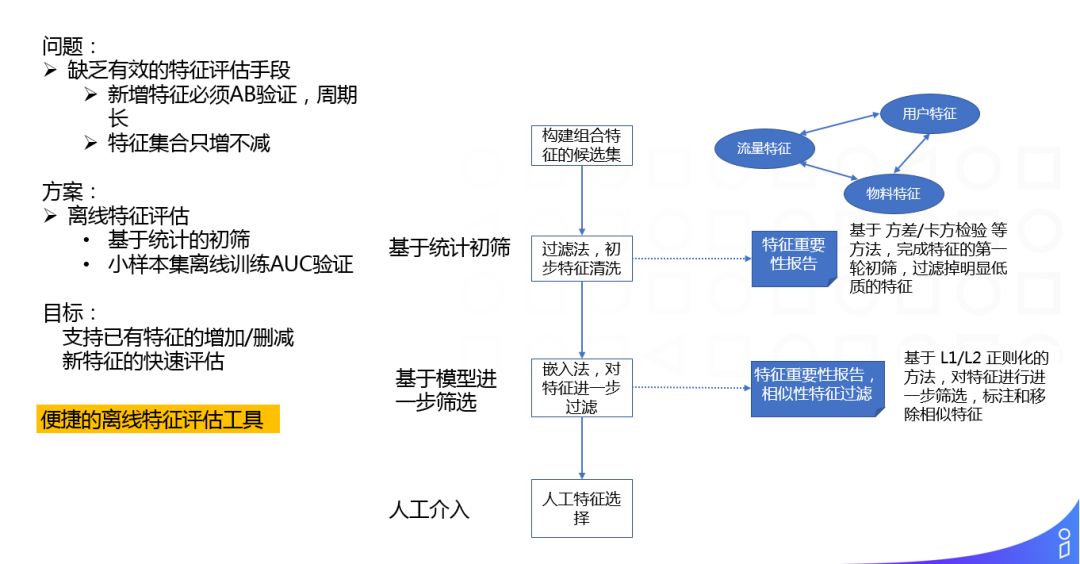
还有就是我们提供了一套简单的离线特征评估工具,可以基于小样本集评估特征的质量,避免把所有特征调研的验证工作都带到线上。
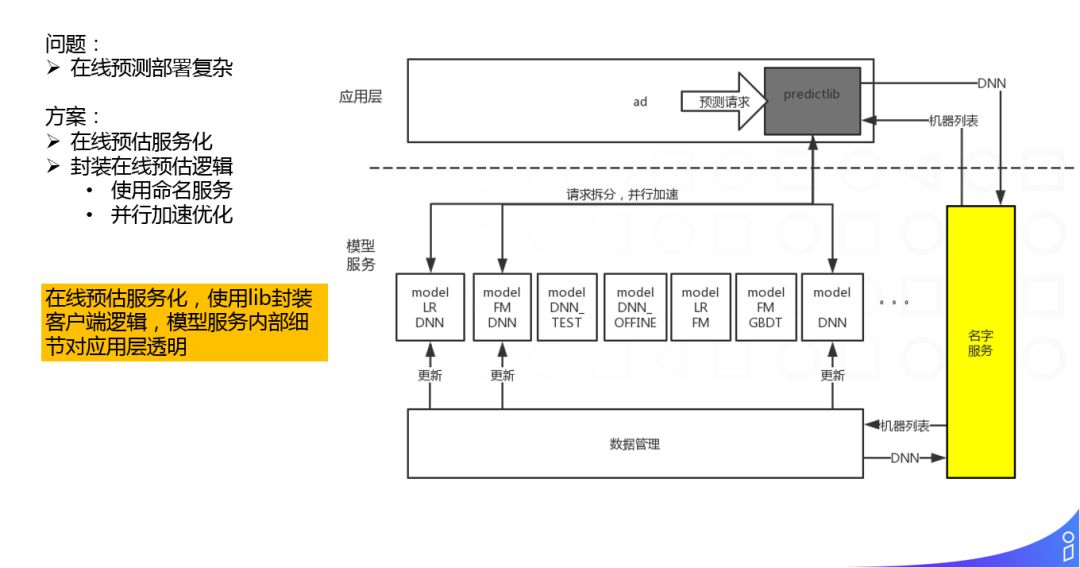
最后就是在线预估部分,我们通过 lib 封装了在线预估的逻辑,内部使用名字服务确定模型到具体机器的依赖,并且做了并行等加速优化,将在线预估以服务化的方式输出,对应用方屏蔽了具体部署的细节。
模型工程平台小结,如上。
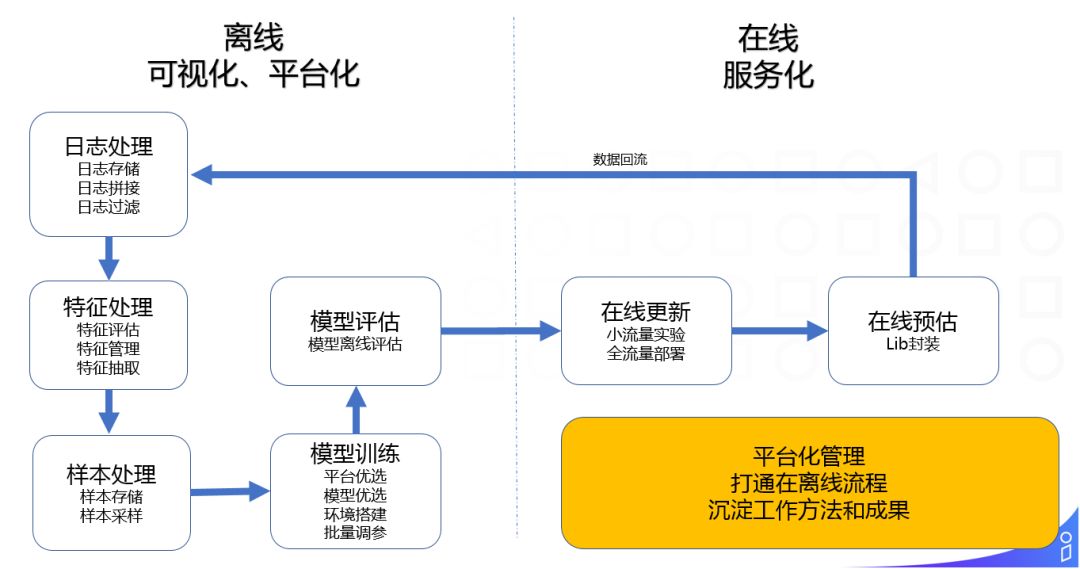
通过模型工程平台化的管理,在整个模型工程的离线处理从日志处理->特征处理->样本处理->模型训练->模型评估,做了集中化的管理和可视化的操作;其次,我们打通了在离线的流程,比如使用者在模型训练出来后,可以一键上线;最后,模型工程平台成为我们沉淀工作方法和成果的平台。
❷ 服务治理平台
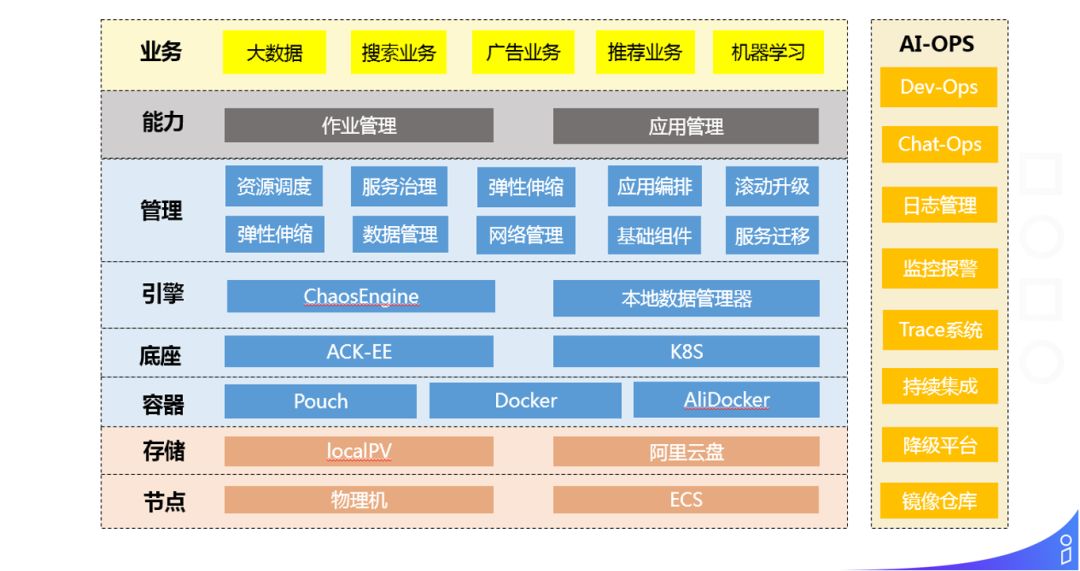
最后是我们的服务治理平台,在容器层主要使用的是 Docker,一层调度主要使用的是 K8S,二层调度使用的是 ChaosEngine 和本地数据管理器,很好的支持了资源调度、弹性伸缩、服务治理、数据管理、应用管理等。通过服务治理平台,我们的上线效率,数据管理,扩容效率相比之前有了很大的提升。目前,服务治理平台不仅仅是一个提效平台,也在做一些如成本优化方面的工作。包括:在线和离线的混部;在线业务潮汐的伸缩容,弹性伸缩,将节省出来的机器应用到模型训练所需要的 MPI 集群和 Hadoop 集群等等。
本次的分享就到这里,谢谢大家。
▬▬
PS:想加入阿里大鱼技术沙龙的小伙伴,欢迎关注本文公众号,后台回复关键词:[小师妹],加阿里大文娱小师妹的微信号进群,更有相关的职位推荐哦。


项铮
——END——
文章推荐:
社群交流:
欢迎加入 DataFunTalk 计算广告交流群,与小伙伴们一起讨论计算广告相关问题。加管理员微信 ( 微信号:DataFunTalker ) 或识别下方二维码,回复:计算广告,会自动拉你进群。

一个「在看」,一段时光!👇





