【案例分析】京东大数据赋能业务,揭秘用户画像最佳实践
本文是 李爱华老师 的 京东大数据赋能业务,揭秘用户画像最佳实践 课程课件,未经允许,禁止转载。
推荐课程:
9月19日 京东大数据赋能业务,揭秘用户画像最佳实践
分享内容:
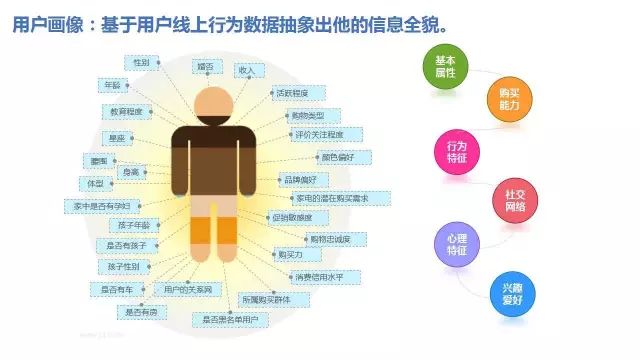
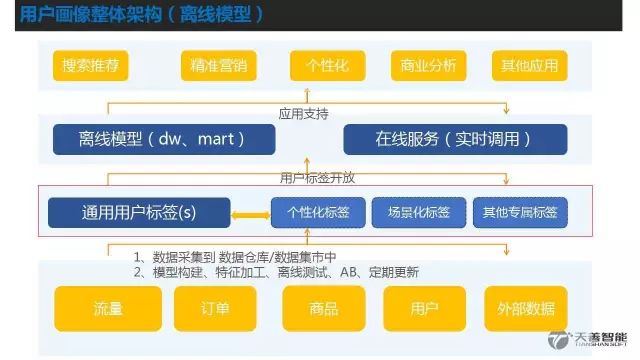
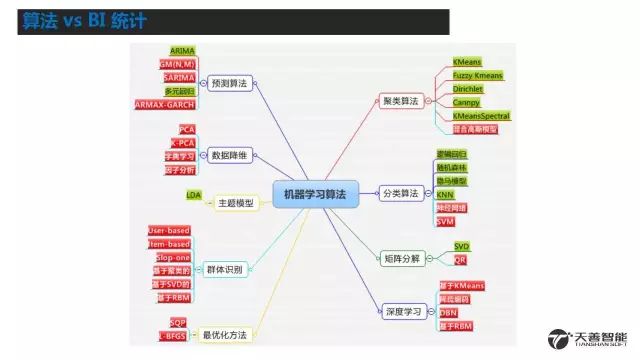
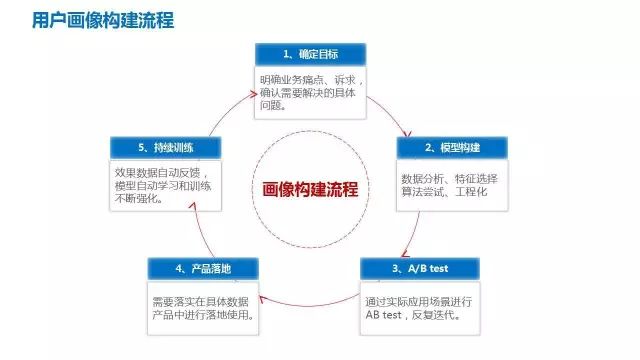
1、京东用户画像技术架构介绍(侧重整体介绍,让大家有个相对清晰的概念。)
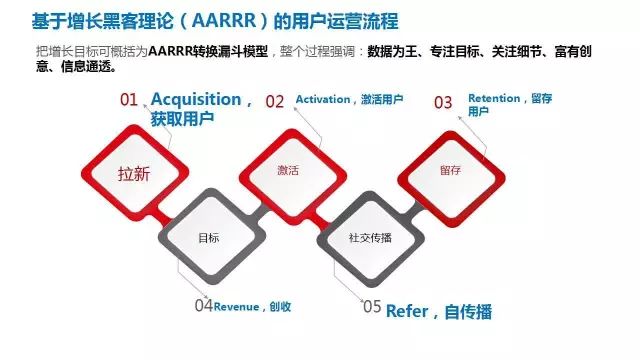
2、京东用户画像到底该怎么玩?(Growth Hacker用户运营理论,全站画像 VS 品类/品牌/渠道/频道/店铺/场景等细分维度画像。)
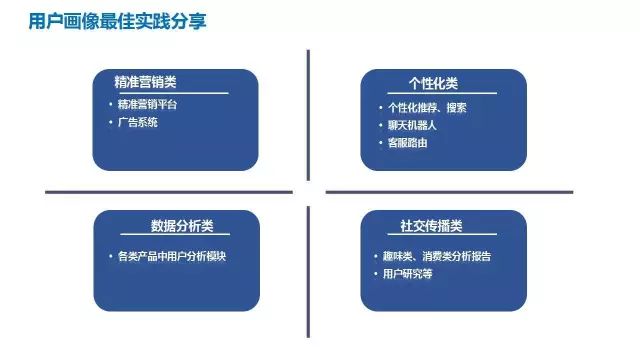
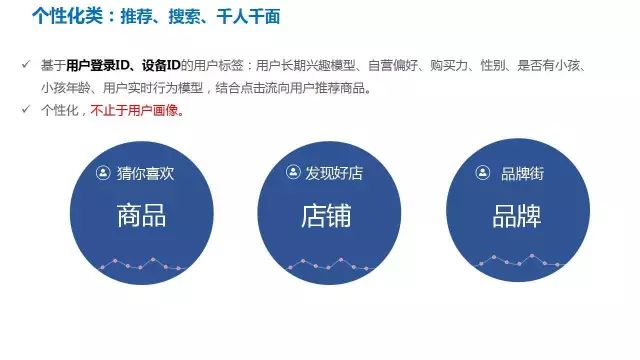
3、京东用户画像在电商场景中的最佳实践(营销端&运营端)
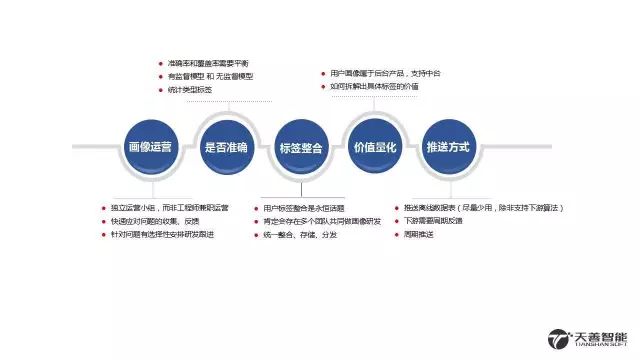
4、那些年我们踩过的坑。(经验教训)
5、用户画像发展方向。








延展阅读:基于自然语言识别下的流失用户预警
来源:全球人工智能
在电商运营过程中,会有大量的用户反馈留言,包括吐槽的差评,商品不满的地方等等,在用户运营生态中,这部分用户是最有可能流失也是最影响nps的人群,通过对其评价的语义分析,每日找出潜在的流失人群进行包括"电话回访","补券安慰","特权享受"等行为,有效的降低了用户的流失。根据实际的业务营销效果,在模型上线后,abtest检验下模型识别用户人群进行营销后的流失率比随意营销下降9.2%,效果显著。
当前文本文义识别存在一些问题:
(1)准确率而言,很多线上数据对特征分解的过程比较粗糙,很多直接基于df或者idf结果进行排序,在算法设计过程中,也是直接套用模型,只是工程上的实现,缺乏统计意义上的分析;
(2)文本越多,特征矩阵越稀疏,计算过程越复杂。常规的文本处理过程中只会对文本对应的特征值进行排序,其实在文本选择中,可以先剔除相似度较高的文本,这个课题比较大,后续会单独开一章进行研究;
(3)扩展性较差。比如我们这次做的流失用户预警是基于电商数据,你拿去做通信商的用户流失衡量的话,其质量会大大下降,所以重复开发的成本较高,这个属于非增强学习的硬伤,目前也在攻克这方面的问题。
首先,我们来看下,整个算法设计的思路:
1.通过hive将近期的用户评价hadoop文件下载为若干个text文件
2.通过R语言将若干个text整合读取为一个R内的dataframe
3.利用R里面的正则函数将文本中的异常符号‘#!@¥%%’,英文,标点等去除
(这边可以在hive里面提前处理好,也可以在后续的分词过程中利用停顿词去除)
4.文本分词,这边可以利用R中的Rwordseg,jiebaR等,我写这篇文章之前看到很多现有的语义分析的文章中,Rwordseg用的挺多,所以这边我采用了jiebaR
5.文本分词特征值提取,常见的包括互信息熵,信息增益,tf-idf,本文采取了tf-idf,剩余方法会在后续文章中更新
6.模型训练
这边我采取的方式是利用概率模型naive bayes+非线性模型random forest先做标签训练,最后用nerual network对结果进行重估
(原本我以为这样去做会导致很严重的过拟合,但是在实际操作之后发现,过拟合并不是很严重,至于原因我也不算很清楚,后续抽空可以研究一下)下面,我们来剖析文本分类识别的每一步
1.定义用户属性
首先,我们定义了已经存在的流失用户及非流失用户,易购的用户某品类下的购买周期为27天,针对前60天-前30天下单购物的用户,观察近30天是否有下单行为,如果有则为非流失用户,如果没有则为流失用户。提取每一个用户最近一次商品评价作为msg。
2.文本合成
通过hive -e的方式下载到本地,会形成text01,text02...等若干个文本,通过R进行文本整合:
| #先设置文本路径 path <- "C:/Users/17031877/Desktop/Nlp/answer/Cmsg" completepath <- list.files(path, pattern = "*.txt$", full.names = TRUE) #批量读入文本 readtxt <- function(x) { ret <- readLines(x) #每行读取 return(paste(ret, collapse = "")) #通过paste将每一行连接起来 } #lappy批量操作,形成list,个人感觉对非关系数据,list处理更加便捷 msg <- lapply(completepath, readtxt) #用户属性 user_status <- list.files(path, pattern = "*.txt$") #stringsAsFactors=F,避免很多文本被读成因子类型 comment <- as.data.frame(cbind(user_status, unlist(msg)),stringsAsFactors = F) colnames(comment) <- c("user_status", "msg") |
基础的数据整合就完成了。

3.数据整理
也可以看到,基础数据读取完成后,还是很多评论会有一些不规则的数据,包括‘#¥%……&’,英文,数字,下面通过正则、停顿词的方式进行处理:
3.1正则化处理
| #直接处理 comment$msg <- gsub(pattern = " ", replacement ="", comment$msg) #gsub是字符替换函数,去空格 comment$msg<- gsub("[[:digit:]]*", "", comment$msg) #清除数字[a-zA-Z] comment$msg<- gsub("[a-zA-Z]", "", comment$msg) #清除英文字符 comment$msg<- gsub("\\.", "", comment$msg) #清除全英文的dot符号 -------------------------------------------------------------------------------------------------- #如果是常做nlp处理,可以写成函数打包,后期直接library就可以了 #数值删除 removeNumbers = function(x){ ret = gsub("[0-9]","",x) return(ret) } #字符删除 removeLiters = function(x){ ret = gsub("[a-z|A-Z]","",x) return(ret) } #各种操作符处理,\s表示空格,\r表示回车,\n表示换行 removeActions = function(x){ ret = gsub("\\s|\\r|\\n", "", x) return(ret) } comment$msg=removeNumbers(comment$msg) comment$msg=removeLiters(comment$msg) comment$msg=removeActions (comment$msg) |
这边需要对正则化里面的一些表示有所了解,详细可以百度,一般我都是具体需求具体去看,因为太多,自己又懒,所以没记
3.2停顿词
| #加载jiebaR包 library(jiebaR) #找jiebaR存停顿词的地方,自行将需要处理掉的符号存进去,我这边是C:/Program Files/R/R-3.3.3/library/jiebaRD/dict/stop_words.utf8 tagger<-worker(stop_word="C:/Program Files/R/R-3.3.3/library/jiebaRD/dict/stop_words.utf8") |
至于位置可以通过直接输入worker()查看,
当前的是没有stop_word的,所有词存储的位置在:C:/Program Files/R/R-3.3.3/library/jiebaRD/dict/下
4.文本分词
| #jieba 分词,去除停顿词 library(jiebaR) tagger<-worker(stop_word="C:/Program Files/R/R-3.3.3/library/jiebaRD/dict/stop_words.utf8") words=list() for (i in 1:nrow(comment)){ tmp=tagger[comment[i,2]] words=c(words,list(tmp)) } |
直接先分词,但是分词结果会存在很多只有一个字比如‘的’、‘你’、‘我’等或者很多无意义的长句‘中华人民共和国’、‘长使英雄泪满襟’等,需要把这些词长异常明显无意义的词句去掉。
| #词长统计 whole_words_set=unlist(words) whole_words_set_rank=data.frame(table(whole_words_set)) whole_words_set_dealed=c() for (i in 1:nrow(whole_words_set_rank)){ tmp=nchar(as.character(whole_words_set_rank[i,1])) whole_words_set_dealed=c(whole_words_set_dealed,tmp) } whole_words_set_dealed=cbind(whole_words_set_rank,whole_words_set_dealed) whole_words_set_dealed=whole_words_set_dealed[whole_words_set_dealed$whole_words_set_dealed>1&whole_words_set_dealed$whole_words_set_dealed<5,] whole_words_set_dealed=whole_words_set_dealed[order(whole_words_set_dealed$Freq,decreasing=T),] #words的删除异常值,排序 whole_words_set_sequence=words key_word=nrow(words) for (i in 1:key_word){ for (j in 1:length(words[[i]])){ tmp=ifelse(nchar(words[[i]][j])>1 & nchar(words[[i]][j])<5,words[[i]][j],'') whole_words_set_sequence[[i]][j]=tmp } } for (i in 1:key_word){ whole_words_set_sequence[[i]]=whole_words_set_sequence[[i]][whole_words_set_sequence[[i]]!=''] } |
5.tf-idf词特征值重要性排序
首先,我们大致看一下排序的数据依旧:
TF = 某词在文章中出现的次数/文章包含的总词数(或者文章有价值词次数)
DF = (包含某词的文档数)/(语料库的文档总数)
IDF = log((语料库的文档总数)/(包含某词的文档数+1))
这边的+1是为了避免(语料库的文档总数)/(包含某词的文档数)=1,log(1)=0,使得最后的重要性中出现0的情况,与有意义的前提相互驳斥。
TF-IDF = TF*IDF
分别看下,里面的每一项的意义:
TF,我们可以看出,在同一个评论中,词数出现的越多,代表这个词越能成为这篇文章的代表,当然前提是非无意义的助词等。
IDF,我们可以看出,所以评论中,包含目标词的评论的占比,占比数越高,目标词的意义越大,假设1000条评论中,“丧心病狂”在一条评论里面重复了10次,但是其他999条里面一次也没有出现,那就算“丧心病狂”非常能代表这条评论,但是在做文本集特征考虑的情况下,它的价值也是不大的。
下面,我们来看代码:
| #tfidf_partone 为对应的tf tdidf_partone=whole_words_set_sequence for (i in 1:key_word){ tmp1=as.data.frame(prop.table(table(whole_words_set_sequence[[i]]))) tdidf_partone[[i]]=tmp1 } #tdidf_partfour 为对应的idf tdidf_parttwo=unique(unlist(whole_words_set_sequence)) tdidf_max=length(tdidf_parttwo) tdidf_partthree=tdidf_parttwo for (i in 1:tdidf_max){ tmp=0 aimed_word=tdidf_parttwo[i] for (j in 1:key_word){ tmp=tmp+sum(tdidf_parttwo[i] %in% whole_words_set_sequence[[j]]) } tdidf_partthree[i]=log(as.numeric(key_word)/(tmp+1)) } tdidf_partfour=cbind(tdidf_parttwo,tdidf_partthree) tdidf_partfive=tdidf_partone colnames(tdidf_partfour)<-c('Var1','Freq1') for (i in 1:key_word){ tdidf_partfive[[i]]=merge(tdidf_partone[[i]],tdidf_partfour,by=c("Var1")) } #计算tf-idf结果,并排序key_word tdidf_partsix=tdidf_partfive for (i in 1:key_word){ tmp=tdidf_partfive[[i]][,2:3] tdidf_partsix[[i]][,2]=as.numeric(tmp[,1])*as.numeric(tmp[,2]) tdidf_partsix[[i]]=tdidf_partsix[[i]][order(tdidf_partsix[[i]][,2],decreasing=T),][] } key_word=c() for (i in 1:key_word){ tmp=tdidf_partsix[[i]][1:5,1] key_word=rbind(key_word,as.character(tmp)) } |
理论上讲,如果这边数据存储方式用的是data.frame的话,可以利用spply、apply等批量处理函数,这边用得是list的方式,对lpply不是很熟悉的我,选择了for的循环,后续这边会优化一下,这样太消耗资源了。
6.模型训练
这边,我最后采取的是概率模型naive bayes+非线性模型random forest先做标签训练,最后用nerual network对结果进行重估方式,但是在训练过程中,我还有几种模型的尝试,这边也一并贴出来给大家做参考。
6.1数据因子化的预处理
这边得到了近400维度的有效词,现在将每一维度的词遍做一维的feature,同时,此处的feature的意义为要么评论存在该词,要么评论中不存在该词的0-1问题,需要因子化一下。
#整合数据 for (i in 1:names_count){ |
6.2数据切分训练测试
这边就不适用切分函数了,自己写了一个更加快速。
| n_index=sample(1:nrow(feature_matrix),round(0.7*nrow(feature_matrix))) train_feature_matrix=feature_matrix[n_index,] test_feature_matrix=feature_matrix[-n_index,] |
6.3模型训练
(1)backpropagation neural network
这边需要用网格算法对size和decay进行交叉检验,这边不贴细节,可以百度搜索详细过程。
library(nnet) correction_train=nrow(result_combind_train[result_combind_train[,1]==result_combind_train[,2],])/nrow(result_combind_train) |
(2)Linear Support Vector Machine
这边需要用网格算法对cost进行交叉检验,这边不贴细节,可以百度搜索详细过程。
| library(e1071) svmfit <- svm(label~., data=train_feature_matrix, kernel = "linear", cost = 10, scale = FALSE) # linear svm, scaling turned OFF #train数据集效果 svmfit.predict_train=predict(svmfit, train_feature_matrix, type = "probabilities") result_combind_train=cbind(as.numeric(as.character(train_feature_matrix$label)),as.numeric(as.character(svmfit.predict_train))) correction_train=nrow(result_combind_train[result_combind_train[,1]==result_combind_train[,2],])/nrow(result_combind_train) #test数据集效果 svmfit.predict_test = predict(svmfit,test_feature_matrix,type = "class") result_combind_test=cbind(as.numeric(as.character(test_feature_matrix$label)),as.numeric(as.character(svmfit.predict_test))) correction_test=nrow(result_combind_test[result_combind_test[,1]==result_combind_test[,2],])/nrow(result_combind_test) |
(3)贝叶斯分类器
这边我没调参,我觉得这边做的好坏在于数据预处理中剩下来的特征词
| library(e1071) sms_classifier <- naiveBayes(train_feature_matrix[,-1], train_feature_matrix$label) #train数据集效果 sms.predict_train=predict(sms_classifier, train_feature_matrix) result_combind_train=cbind(as.numeric(as.character(train_feature_matrix$label)),as.numeric(as.character(sms.predict_train))) correction_train=nrow(result_combind_train[result_combind_train[,1]==result_combind_train[,2],])/nrow(result_combind_train) #test数据集效果 sms.predict_test = predict(sms_classifier,test_feature_matrix) result_combind_test=cbind(as.numeric(as.character(test_feature_matrix$label)),as.numeric(as.character(sms.predict_test))) correction_test=nrow(result_combind_test[result_combind_test[,1]==result_combind_test[,2],])/nrow(result_combind_test) |
(4)随机森林
这边因为是最后的整合模型,需要调参的地方比较多,首先根据oob确定在mtry=log(feature)下的最优trees数量,在根据确定的trees的数量,反过来去确定mtry的确定值。除此之外,还需要对树的最大深度,子节点的停止条件做交叉模拟,是整体模型训练过程中最耗时的地方
library(randomForest) #train数据集效果 |
就单模型下的test集合的准确率如下:

整体上看,nnet是过拟合的,所以在测试集上的效果折扣程度最大;naive bayes模型的拟合效果应该是最弱的,但是好在它的开发成本低,逻辑简单,有统计意义;svm和randomforest这边的效果不相上下。本次训练的数据量在20w条左右,理论上讲再扩大数据集的话,randomforest的效果应该会稳定,svm会下降,nnet会上升。
(5)模型集成
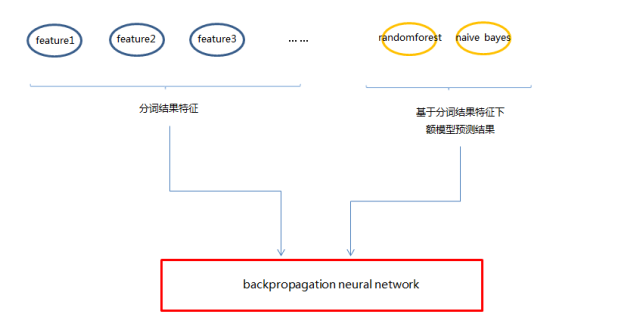
这边的train_data的准确率在92.1%,test_data的准确率在84.3%,与理想的test_data90%以上的准确率还是有差距,所以后续准备:
1.细化流失用户的定义方式,当前定义过于笼统粗糙
2.以RNN的模型去替代BpNN去做整合训练,探索特征到特征本身的激活会对结果的影响
3.重新定义词重要性,考虑互信息熵及isolation forest的判别方式
最后谢谢大家的阅读。
作者:沙韬伟,苏宁易购高级算法工程师。曾任职于Hewlett-Packard研究室、滴滴出行。主要研究方向包括自然语言、机器学习和风控深度学习。目前专注于基于集成模型下的用户行为模式的识别。
作者:slade_sal
链接:http://www.jianshu.com/p/413cff5b9f3a

新一代技术+商业操作系统:
AI-CPS OS
在新一代技术+商业操作系统(AI-CPS OS:云计算+大数据+物联网+区块链+人工智能)分支用来的今天,企业领导者必须了解如何将“技术”全面渗入整个公司、产品等“商业”场景中,利用AI-CPS OS形成数字化+智能化力量,实现行业的重新布局、企业的重新构建和自我的焕然新生。
AI-CPS OS的真正价值并不来自构成技术或功能,而是要以一种传递独特竞争优势的方式将自动化+信息化、智造+产品+服务和数据+分析一体化,这种整合方式能够释放新的业务和运营模式。如果不能实现跨功能的更大规模融合,没有颠覆现状的意愿,这些将不可能实现。
领导者无法依靠某种单一战略方法来应对多维度的数字化变革。面对新一代技术+商业操作系统AI-CPS OS颠覆性的数字化+智能化力量,领导者必须在行业、企业与个人这三个层面都保持领先地位:
重新行业布局:你的世界观要怎样改变才算足够?你必须对行业典范进行怎样的反思?
重新构建企业:你的企业需要做出什么样的变化?你准备如何重新定义你的公司?
重新打造自己:你需要成为怎样的人?要重塑自己并在数字化+智能化时代保有领先地位,你必须如何去做?
AI-CPS OS是数字化智能化创新平台,设计思路是将大数据、物联网、区块链和人工智能等无缝整合在云端,可以帮助企业将创新成果融入自身业务体系,实现各个前沿技术在云端的优势协同。AI-CPS OS形成的数字化+智能化力量与行业、企业及个人三个层面的交叉,形成了领导力模式,使数字化融入到领导者所在企业与领导方式的核心位置:
精细:这种力量能够使人在更加真实、细致的层面观察与感知现实世界和数字化世界正在发生的一切,进而理解和更加精细地进行产品个性化控制、微观业务场景事件和结果控制。
智能:模型随着时间(数据)的变化而变化,整个系统就具备了智能(自学习)的能力。
高效:企业需要建立实时或者准实时的数据采集传输、模型预测和响应决策能力,这样智能就从批量性、阶段性的行为变成一个可以实时触达的行为。
不确定性:数字化变更颠覆和改变了领导者曾经仰仗的思维方式、结构和实践经验,其结果就是形成了复合不确定性这种颠覆性力量。主要的不确定性蕴含于三个领域:技术、文化、制度。
边界模糊:数字世界与现实世界的不断融合成CPS不仅让人们所知行业的核心产品、经济学定理和可能性都产生了变化,还模糊了不同行业间的界限。这种效应正在向生态系统、企业、客户、产品快速蔓延。
AI-CPS OS形成的数字化+智能化力量通过三个方式激发经济增长:
创造虚拟劳动力,承担需要适应性和敏捷性的复杂任务,即“智能自动化”,以区别于传统的自动化解决方案;
对现有劳动力和实物资产进行有利的补充和提升,提高资本效率;
人工智能的普及,将推动多行业的相关创新,开辟崭新的经济增长空间。
给决策制定者和商业领袖的建议:
超越自动化,开启新创新模式:利用具有自主学习和自我控制能力的动态机器智能,为企业创造新商机;
迎接新一代信息技术,迎接人工智能:无缝整合人类智慧与机器智能,重新
评估未来的知识和技能类型;
制定道德规范:切实为人工智能生态系统制定道德准则,并在智能机器的开
发过程中确定更加明晰的标准和最佳实践;
重视再分配效应:对人工智能可能带来的冲击做好准备,制定战略帮助面临
较高失业风险的人群;
开发数字化+智能化企业所需新能力:员工团队需要积极掌握判断、沟通及想象力和创造力等人类所特有的重要能力。对于中国企业来说,创造兼具包容性和多样性的文化也非常重要。
子曰:“君子和而不同,小人同而不和。” 《论语·子路》云计算、大数据、物联网、区块链和 人工智能,像君子一般融合,一起体现科技就是生产力。
如果说上一次哥伦布地理大发现,拓展的是人类的物理空间。那么这一次地理大发现,拓展的就是人们的数字空间。在数学空间,建立新的商业文明,从而发现新的创富模式,为人类社会带来新的财富空间。云计算,大数据、物联网和区块链,是进入这个数字空间的船,而人工智能就是那船上的帆,哥伦布之帆!
新一代技术+商业操作系统AI-CPS OS作为新一轮产业变革的核心驱动力,将进一步释放历次科技革命和产业变革积蓄的巨大能量,并创造新的强大引擎。重构生产、分配、交换、消费等经济活动各环节,形成从宏观到微观各领域的智能化新需求,催生新技术、新产品、新产业、新业态、新模式。引发经济结构重大变革,深刻改变人类生产生活方式和思维模式,实现社会生产力的整体跃升。
产业智能官 AI-CPS
用“新一代技术+商业操作系统”(AI-CPS OS:云计算+大数据+物联网+区块链+人工智能),在场景中构建状态感知-实时分析-自主决策-精准执行-学习提升的认知计算和机器智能;实现产业转型升级、DT驱动业务、价值创新创造的产业互联生态链。


长按上方二维码关注微信公众号: AI-CPS,更多信息回复:
新技术:“云计算”、“大数据”、“物联网”、“区块链”、“人工智能”;新产业:“智能制造”、“智能驾驶”、“智能金融”、“智能城市”、“智能零售”;新模式:“案例分析”、“研究报告”、“商业模式”、“供应链金融”、“财富空间”。
点击“阅读原文”,访问AI-CPS OS官网
本文系“产业智能官”(公众号ID:AI-CPS)收集整理,转载请注明出处!
版权声明:由产业智能官(公众号ID:AI-CPS)推荐的文章,除非确实无法确认,我们都会注明作者和来源。部分文章推送时未能与原作者取得联系。若涉及版权问题,烦请原作者联系我们,与您共同协商解决。联系、投稿邮箱:erp_vip@hotmail.com





