深度 | 可视化线性修正网络:看Fisher-Rao范数与泛化之间的关系
选自inFERENCe
作者:Ferenc Huszár
机器之心编译
参与:程耀彤、思源
深度模型的泛化性能一直是研究的主题。最近,Twitter 的机器学习研究员 Ferenc Huszár 发表了一篇文章专门讨论泛化与 Fisher-Rao 范数之间的关系,它先分析了提出 Fisher-Rao 度量方法的论文,包括带偏置项和不带偏置项的分段线性网络的可视化,然后再讨论了其它如 Fisher-Rao 范数是否会成为有效的正则化器等问题。
在上周发布的关于泛化之谜的文章之后,有研究者向我介绍了最近将 Fisher-Rao 范数度量与泛化联系起来的工作:
Tengyuan Liang, Tomaso Poggio, Alexander Rakhlin, James Stokes (2017) Fisher-Rao Metric, Geometry, and Complexity of Neural Networks:https://arxiv.org/abs/1711.01530
合著者 Sasha Rakhlin 的这篇关于泛化的简短材料也是值得关注的,尽管我必须承认很多关于学习理论的引用都有所丢失。虽然我不够理解第四节中所描述的有界性证明,但我想我已经理解了大概,所以我将尝试在下面的部分总结要点。另外,我想补充一些图表,它们能帮助我理解作者所使用的受限模型和这种限制引起的「梯度结构」。
基于范数的容量控制
本文的主要观点与 Bartlett (1998) 的结果是一致的,他观察到在神经网络中,泛化与权重的大小有强相关,而与权重的数量没有多大关系。这个理论的基础是使用诸如权值衰减、甚至提前终止等技术,因为两者都可以被看作是保持神经网络权重向量有较小值的方法。根据一个神经网络权重向量的大小量级或范数而推理其泛化能力称为基于范数的容量控制。
Liang 等人(2017)的主要贡献是提出 Fisher-Rao 范数作为衡量网络权重有多大的指标,从而作为网络泛化能力的度量方法。它的定义如下:
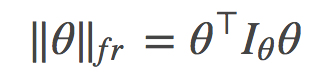
其中 I 是 Fisher 信息矩阵:

Fisher 信息矩阵有很多形式,因此 Fisher-Rao 范数的形式取决于期望的分布情况。经验样本 x 和 y 都来自经验数据分布。模型从数据中抽取样本 x,若假定损失是概率模型的对数损失,那么我们可以从这个模型中抽样 y。
重要的是,Fisher-Rao 范数是依赖于数据分布的(至少是 x 的分布)。它在参数重设时也是不变的,这意味着如果有两个参数 θ_1 和 θ_2 实现相同的功能,那么它们的 FR 范数就是相同的。最后,这是一个与平坦度相关的度量,因为 Fisher 信息矩阵在某些条件下逼近损失函数的 Hessian 矩阵。
本论文主要观点:
在不带偏置项的修正线性网络中,Fisher-Rao 范数有一个更容易计算和分析的等价形式。
以前提出的其它用于限制模型复杂性的范数可以用 Fisher-Rao 来界定。
对于没有修正的线性网络(实际上只是一个线性函数),Rademacher 复杂性可以用 FR 规范来界定,且边界不依赖于层数或每层单元的数量。这表明 Fisher-Rao 范数可能是泛化性能非常好的间接度量方法。
作者没有证明更一般模型的泛化边界,但是该论文基于与其它范数的关系提供了直观的论点。
作者还做了大量的实验来展示 FR 规范如何与泛化性能相关联。他们研究了一般 SGD 和 二阶随机法 K-FAC。他们研究了如果我们将标签随机地混合到训练中会发生什么,并发现最终解决方案的 FR 范数似乎能追踪到泛化差距。
这里仍然有一些未解决的问题,例如解释是什么具体使 SDG 选择更好的极小值,以及该极小值如何伴随着批量大小的增加而变化。
不带偏置项的修正神经网络
我认为能在这篇论文中扩展的地方,就是作者研究特定模型类型(不带偏置项的修正神经网络)的一些细节。这种限制最终保证了一些非常有趣的属性,而不伤害网络的经验性能(所以作者声明并在一定程度上证明了这一点)。
首先我们可以可视化具有偏置项的修正多层感知器的输出数据。我使用了 3 个隐藏层,每个层都有 15 个 ReLU 单元,并且使用了 PyTorch 默认的随机初始化。网络的输入是 2D 的,输出是 1D 的,所以我可以很容易的绘制梯度的等高面:

图 1:带偏置项的修正神经网络
左图显示函数本身。它旁边的图分别显示了该损失函数对 x_1 和 x_2 的梯度。该函数是分段线性的(这很难观察,因为有很多的线性块),这意味着梯度是分段恒定的(这在视觉上更明显)。
f 的分段线性结构变得更加明显,我们在 f 本身的等高面(红—蓝)上叠加了梯度的等值线图(黑色)。

这些函数显然非常灵活,通过增加更多的层数,线性块的数量呈指数增长。重要的是,如果我把函数的输出作为 θ 的两个成员的函数绘制,保持 x 固定,上面的图看起来非常相似。
现在让我们看看当我们从网络中删除所有的偏置项仅保留权重矩阵时会发生什么:
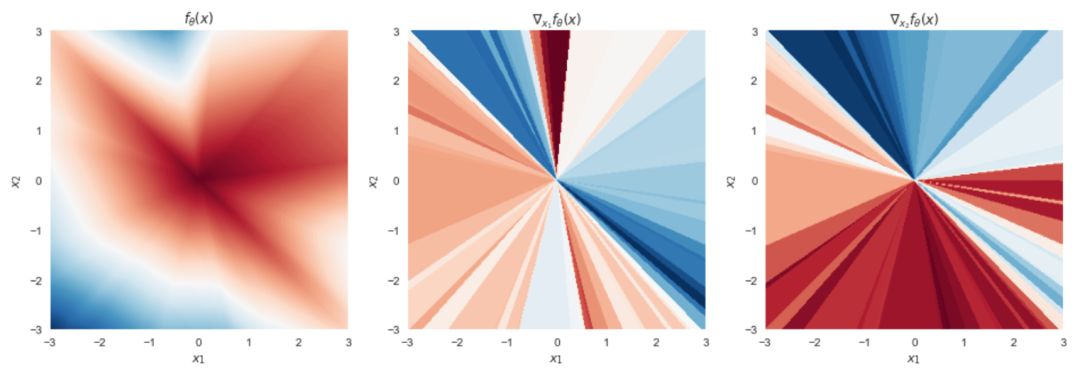
图 2:不带偏置项的修正神经网络
哇,现在函数看起来很不一样,不是吗?在 x=0 时,它总是等于 0。它由楔形(或在更高维度,广义金字塔形)区域组成,在这个区域中函数是线性的,但每个楔形的斜率是不同的。然而表明仍然是连续的。让我们再来做一张叠加图:

从这些图中不太清楚,为什么像这样的函数能够模拟数据,以及为什么如果我们添加偏置项会得到更一般的分段线性函数。在高维上理解是有帮助的,因为高维度中两个随机采样的数据点落入同样的「pyramind」(即共享相同的线性区域)的概率是非常小的。除非你的数据有一定结构,使得对于很多数据点同时可能发生这种情况,否则我想你不需要担心。
此外,如果我的网络有三个输入维度,但是我只用两个维度 x_1 和 x_2 来编码数据并固定第三个坐标 x_3=1,我可以在我的输入上实现相同类型的功能。这被称为使用齐次坐标,而一个具有齐次坐标且不带偏置项的网络在其所能建模的函数方面,几乎与有偏置的网络一样强大。下面是一个使用齐次坐标时,不带偏置项的修正神经网络例子。

图 3:不带偏置项的修正神经网络,齐次坐标
这是因为第三个变量 x_3=1 乘以它的权重实际上成为了第一个隐藏层的偏置。第二个观察结果是,我们可以将 f_θ (x) 作为特定层权重矩阵的函数,保持其它所有的权重和输入相同,函数的行为与输入是 x 时的行为完全相同。如果我把它绘制为一个权重矩阵的函数(即使权重矩阵很少是 2D 的,所以我不能真的把它绘制出来),在 f 中我们将观察到相同的辐射形状。
梯度结构
作者指出,这些函数满足以下公式:
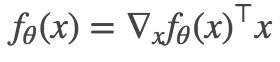
此外,我认为这些都是上述等式成立的唯一连续函数,但我把它留给聪明的读者来证明或反驳。注意到网络输入和权重矩阵之间的对称性,可以建立一个关于参数 θ 的相似等式:
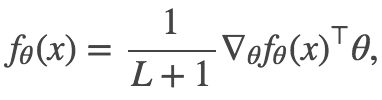
其中 L 是层级数。
为什么是这样的?
以下是我的解释,与作者给出的简单证明略有不同。正如讨论的那样,一个通常的修正线性网络对于 x 是分段线性的。当我们改变 θ 时,线性分段的边界和斜率随之改变。若我们固定 θ,那么只要 x 和一些 x_0 落在相同的线性区域内,函数在 x 处的值等于它在 x_0 的泰勒展开式:

现在,如果我们不使用偏置项,所有的线段总是楔形的,并且它们在原点 x=0 处相遇。所以,我们可以把上述泰勒级数的极限作为 x_0→0 时的极限。(我们只能从技术上取极限,因为函数在 x=0 处不可微分。)因为 f_θ (0)=0,我们发现
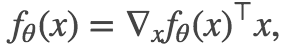
就像我们想要的那样。现在将 l 层的权重 θ (l) 视为后续层级网络的输入,而将前一层的激活视为权重乘以这些输入,我们可以推导出由 θ (l) 表示的类似公式:
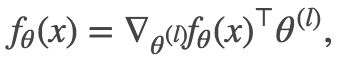
对所有层 l=1…L+1 应用此公式,并取平均值,我们得到:
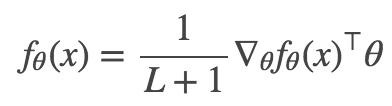
我们根据隐藏层 L 加上输出层得到了 L+1 层。
Fisher-Rao 范数的表达式
使用上面的公式和链式法则,我们可以简化 Fisher-Rao 范数的表达式:
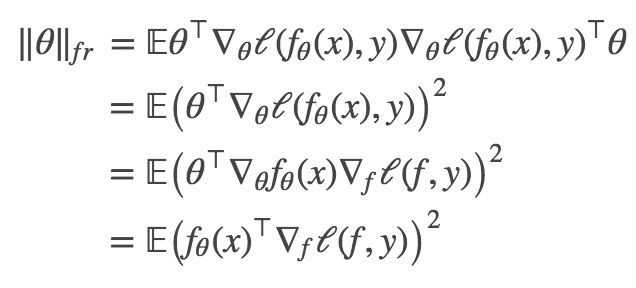
在这种形式中我们可以很清楚地看出,Fisher-Rao 范数只取决于函数 f_θ (x) 的输出和损失函数的性质。这意味着如果两个参数 θ_1 和 θ_2 实现相同的输入-输出函数 f,他们的 F-R 范数将是相同的。
总结
我认为这篇文章对修正线性网络的几何结构提出了一个非常有趣的见解,并强调了几何学信息和基于范数的泛化之间的一些有趣的联系。
我认为目前缺少的是解释为什么 SGD 能够找到低 F-R 范数的解决方案,或一个解决方案的 F-R 范数是如何被 SGD 的批量大小影响的(如果有的话)。另一个缺少的是 F-R 范数是否能够成为一个有效的正则化器。似乎对于没有任何偏置参数的特定类型网络,模型的 F-R 范数可以相对便宜地计算并作为正则化项加入损失函数,因为我们已经计算了网络的前向传播。

原文地址:http://www.inference.vc/generalization-and-the-fisher-rao-norm-2/
本文为机器之心编译,转载请联系本公众号获得授权。
✄------------------------------------------------
加入机器之心(全职记者/实习生):hr@jiqizhixin.com
投稿或寻求报道:editor@jiqizhixin.com
广告&商务合作:bd@jiqizhixin.com



