CS231n 课后作业第二讲 : Assignment 2(含代码实现)| 分享总结

CS231n 是斯坦福大学开设的计算机视觉与深度学习的入门课程,授课内容在国内外颇受好评。其配套的课后作业质量也颇高,因此雷锋网 AI 研习社在近期的线上公开课上请来了一位技术大牛为大家来讲解这门课的配套作业。
本文根据 AI 研习社公开课上的直播视频内容整理而成,主要介绍 CS231n 课后作业第二套 Assignment 2 的完成思路与重点部分代码实现。如果你还没开始听 CS231n,可直接点击课程链接观看回放视频。
王煦中,CS 硕士,主要研究方向为自然语言处理与深度学习。知乎专栏喵神大人的深度工坊(http://t.cn/RTc9wfy )作者,日语及 ACGN 爱好者。
分享主题
CS231n 课后作业第二讲 : Assignment 2(含代码实现)作业链接:https://github.com/Observerspy/CS231n
分享提纲
Part 1 Fully-connected Neural Network
Part 2 Batch Normalization
Part 3 Dropout
Part 4 Convolutional Networks
Part 5 Tensorflow on CIFAR-10
第一部分分享主要是全连接神经网络,这里主要是对代码进行模块化,把每一层都抽象出来,分别实现每一层的前向和反向部分,实现多层神经网络。第二和第三部分讲的是神经网络中两个的重要技巧,对网络训练有很大的提升。本次作业中比较难的部分是卷积神经网络的实现,包括正向和反向的推导过程。
第一个部分是对代码的模块化处理,实现从两层到多层神经网络。

关于 Update rules
第一个改变是加入了动量更新,也就是惯性。第二个是 RMSProp(自适应学习率),第三个是 Adam(两者结合),其实是上面两个方法的结合,如果拿不准使用哪个方法,就用 Adam。

为什么需要 BN(Batch Normalization )?
传统机器学习往往需要对输入数据做一个归一化,通常使用的是零均值和方差归一,这样会保证输入的数据特征会有比较好的分布,使得算法可以比好好的学习。对于深度学习神经网络,使用 BN 使得每一层分布都保持在良好范围内。

BN 的原理
在求均值,求方差,归一化这三步做完之后,每一层的数据分布都是标准正太分布,导致其完全学习不到输入数据的特征。BN 第四步中最关键的是两个参数,这两个参数对归一化后的分母进行缩放和平移,通过网络自己学习平移和缩放来保留一定的特征。

训练过程
前向就是计算 minibatch 的均值和方差,然后对 minibatch 做 normalize 和 scale、shift。测试的时候没有 minibatch,通过使用基于 momentum 的指数衰减,从而估计出均值和方差。

反向过程

BN 的作用
可以有效减缓过拟合,减小不好的初始化影响,可以用大一点的学习率。通常放在激励函数前效果好一点。
Dropout 原理
训练时以概率 P 保留神经元,测试时所有神经元都参与。通常在测试的时候使用 inverted dropout 多移除一个 p 保证训练预测分布的统一。
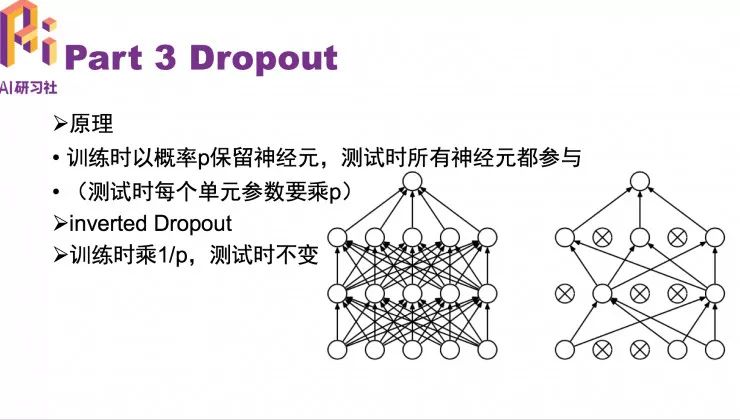
Dropout 的作用
可以有效缓解过拟合,通常 dropout 放在激励函数的后面或者全连接层后。
接下里来看怎么实现一个卷积神经网络

卷积神经网络通常有三个单元结构,分别是卷积核,激活函数,池化层。先看卷积核,首先明确输入 x 和卷积核的形状 (数量,通道,高,宽)。
卷积核
这里的卷积和通信原理里的卷积还是稍有区别的,在这里其实只是卷积核和相应的区域进行元素乘,然后求和,课程官网给的说明十分形象生动。

也就是每个卷积核分别在每个通道上和对应区域进行元素乘,然后求和,对应图中:(-3(通道 1 元素乘后求和) + -1(通道 2 元素乘后求和) + 0 (通道 3 元素乘后求和))(三个通道求和) + 1(bias_0) = -3(out 的第一个格子里的值)
所以,关键问题就是根据步长如何确定 x 对应区域,这里需要对 Hnew(下标 i)和 Wnew(下标 j)进行双循环。选好区域直接和每个卷积(下标 k)核作元素乘就行了,注意 sum 的时候我们其实是在(C, H, W)上作的,因此 axis=(1, 2, 3)。这时候一个输出 out[:, k , i, j] 就计算好了。
所以上述一共套了 i, j ,k 三层循环,循环完毕后 out 再加上 bias 就行了。注意 b 的形状 (F,),因此要先把 b 扩展成和 out 一样的形状:b[None, :, None, None](None 相当于 np.newaxis)
以上就是前向计算,接下来是反向计算。
反向计算首先明确我们要求什么。求 dx,dw 和 db。

卷积核的三个导数具体的求解过程,请关注 AI 慕课学院视频回放(http://www.mooc.ai/open/course/440 )。
池化层
pooling 同样有步长,确定输出形状的公式,计算输出形状并初始化,max pooling 顾名思义就是取这个 pooling 大小区域内的 max 值。注意 axis=(2, 3)。

反向和 ReLU、DropOut 是类似的,也就是说只有刚才前向通过的才允许继续传递梯度。

max_mask 形状是 (HH, WW),为了和 x_padded_mask 形状对应也要扩展。然后 dout 和这个 temp_binary_mask 元素乘即可。同样注意 dout 是由 i,j 确定的,因此形状需要扩展。
以前我们做的 BN 形状是 (N, D),这里不过是将 (N, C, H, W)reshape 为 (N*H*W, C)。

最后进入 TensorFlow
这里强调一点,在使用 BN 时请务必注意:在你的优化器上套上下面图中的两行代码,另外需要注意 tf.layers.batch_normalization() 中的 is_training(是一个 tf.placeholder)在训练和测试时的设置,如果要使用 dropout 也是类似的。

以上就是本次的课后作业指导分享。
AI 慕课学院提供本次视频回放(http://www.mooc.ai/open/course/440 ),欢迎观看。
微信公众号:AI 研习社(ID: okweiwu)定期邀请各路大神直播分享,关注后第一时间与嘉宾直播互动。

NLP 工程师入门实践班:基于深度学习的自然语言处理
三大模块,五大应用,手把手快速入门 NLP
海外博士讲师,丰富项目经验
算法 + 实践,搭配典型行业应用
随到随学,专业社群,讲师在线答疑
▼▼▼

新人福利
关注 AI 研习社(okweiwu),回复 1 领取
【超过 1000G 神经网络 / AI / 大数据,教程,论文】
CS231n 2017 今天正式开课!双语字幕版独家上线!
▼▼▼



