百度NLP | 神经网络模型压缩技术
百度NLP专栏
作者:百度NLP
引言
近年来,我们在神经网络模型与 NLP 任务融合方面深耕,在句法分析、语义相似度计算、聊天生成等各类方向上,均取得显著的进展。在搜索引擎上,语义相似度特征也成为了相关性排序系统最为重要的特征之一。模型越趋复杂,由最初的词袋模型(BOW)发展至建模短距离依赖关系的卷积神经网络(CNN),建模长距离依赖关系的循环神经网络(RNN),以及基于词与词之间匹配矩阵神经网络(MM-DNN)等等。同时,由于语言复杂、表达多样、应用广泛,为了更好的解决语言学习的问题,我们将更多的 NLP 特征引入 DNN 模型,比如基于 t 统计量的二元结构特征,基于依存分析技术的词语搭配结构特征等。
更复杂的模型、更强的特征以及更多的数据对工业级应用提出了更高的要求,如何有效控制内存、减少计算量以及降低功耗是深度神经网络模型发展面临的重要问题。压缩算法的研究不仅提升了模型的扩展潜力,并且使其具有更广阔的应用场景和巨大的想象空间。
在百度,以搜索场景为例,用于相关性排序的神经网络参数规模达到亿级,而线上环境对计算资源要求严格,模型难以扩展。因此,我们引入了 Log 域量化、多层次乘积量化和多种子随机哈希等模型压缩算法,经实践验证压缩率可以达到 1/8。并且这些方法具有很好的通用性,可以借鉴到各种神经网络应用场景。
Log 域量化压缩
对于 NLP 任务,目前已有的深度神经网络模型中动辄应用百万量级词典,其中 embedding 层的参数占整个模型的绝大部分,所以解决模型内存消耗首先从 embedding 层入手。图 1 是用于相关性排序系统中卷积神经网络模型的 embedding layer 参数的值域分布图:
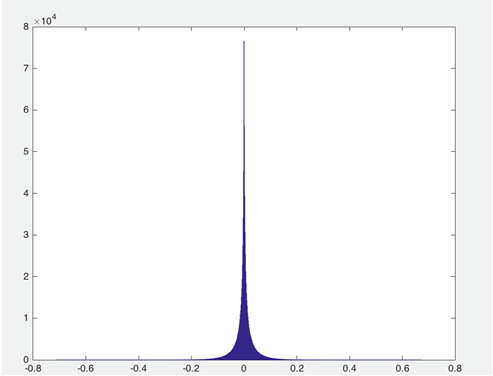
图 1. embedding layer 参数值域分布图
从上述的分布图可以看到数据分布的特点:
1. 参数的值域跨度大;
2. 绝大部分参数集中在较小的区域中,并以 0 为中心呈现山峰的分布。
现在需要对图 1 所示的参数进行量化从而达到压缩的目标,这里的量化是指连续取值(或者大量可能的离散取值)近似为有限多个(或较少的)离散值的过程。如果选择整个值域空间,平均的取若干个量化点,会造成占绝大部分参数的值域范围内只有较少的量化点。如果把量化的范围缩小,则会导致部分重要参数的丢失,同样会对效果造成很大的影响。所以需要找到这样的一种选取量化点的方法:一方面保持原模型值域空间的上限,可以适当去掉 0 附近的参数(剪枝),另一方面参数分布越密集的地方量化点选取越密集。
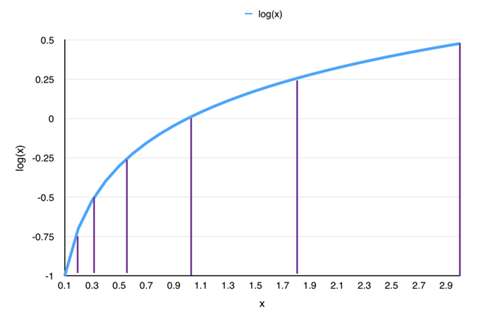
图 2. Log 量化曲线
我们选择在 Log 域上选取量化点以满足上述两个要求。从图 2 可以看出,在 Log 域上平均取量化点,这些点映射到原始参数空间上,量化点越接近 0,就会越密集。具体算法为,首先根据量化的位数(本文统一用 b 来表示量化位数,即最终的量化点数目为2b),从大到小取相应数量的量化点;然后保留原模型值域空间的上限,并剪枝 0 附近的参数。Log 域量化压缩十分有效,其优点在于:在量化位数为 8 的情况下能够做到无损压缩,这意味着深度神经网络模型的 embedding 空间被量化成只有28=256 个离散值;而原模型无需重训。
我们采用这种方法,在百度搜索的深度神经网络语义模型进行了 1/4 无损压缩,即保证线上模型表达能力不变、应用效果持平的前提下,线上所有模型的内存占用减少了 75%。
多层次乘积量化压缩
为了在量化手段上取得更大的压缩率,我们探索了乘积量化压缩。这里的乘积是指笛卡尔积,意思是指把 embedding 向量按笛卡尔积做分解,把分解后的向量分别做量化。和 Log 域量化压缩有所不同,乘积量化压缩主要是在量化单位上有所变化:前者的量化单位是一个数,而后者的量化单位是向量。图 3 所示的例子设置分解后的向量维度为 4,而这 4 维的分解向量通过 K-means 聚类进行量化压缩(设量化位数为 b,则 K-means 中的 K 为 2b),针对这 4 维向量只需存储聚类中心 ID,从而达到压缩的目的。
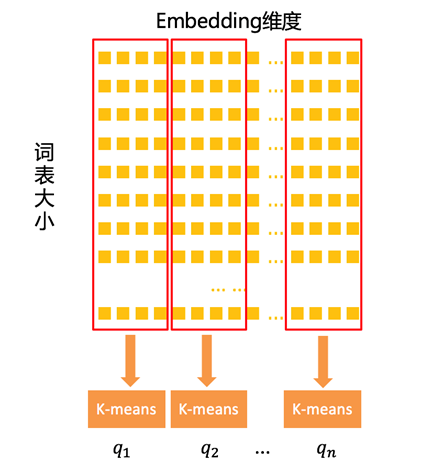
图 3. 乘积量化压缩示意图
基于百度搜索的深度神经网络模型的实验,我们分析并取得了一些结论:
1. 量化向量维度为 1 时可实现 1/4 无损压缩;
2. 量化向量维度为 2 时可实现 1/5 无损压缩;
3. 固定量化的维度,量化位数越大,压缩率越低,模型效果越好;
4. 固定压缩率,随着量化维度的增加,压缩效果先升后降,且在 2 维时取得最好效果。
可见,在单独使用乘积量化的策略的情况下,最多可以实现 1/5 无损压缩,相对于 Log 域量化压缩并没有太大的提升。
为了进一步提高压缩效果,我们引入多层次乘积量化压缩。根据词表中词的重要性,分别应用乘积量化的不同参数。重要的词压缩率低一些,如使用维度为 1、量化位数为 8 的乘积量化;次要一些的词使用压缩率高一些的参数,如维度为 2、量化位数为 8;最不重要的词使用压缩率最高的参数,如维度为 4、量化位数为 12。这种多层次的划分由全自动优化所得。在百度搜索的深度神经网络语义模型应用中,我们通过多层次乘积量化实现了 1/8 无损压缩,并且原始模型无需重训,使用方便。
多种子随机哈希压缩
到目前为止,多层次乘积量化能够实现 1/8 无损压缩。有没有压缩率更大的压缩算法能够支持超大规模 DNN 模型?多种子随机哈希正是这样一种压缩算法:在无损或者可接受的有损范围内,它能够任意配置压缩率,适用于不同应用场景。图 4 是它的示意图:
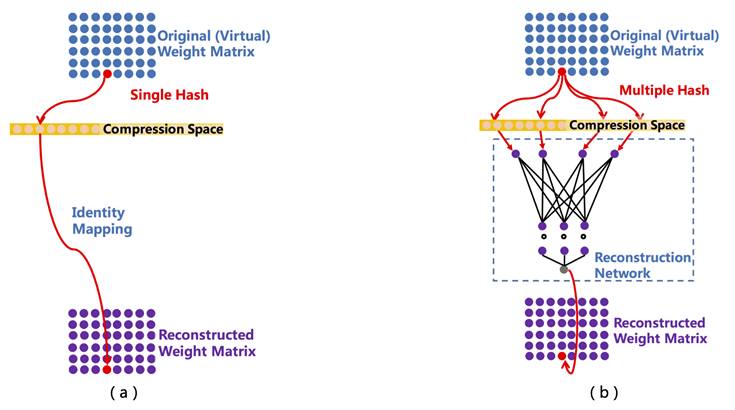
图 4. a)单种子随机哈希压缩算法;b)多种子随机哈希压缩算法
图 4-a)是 Wenlin Chen 在 ICML 2015 发表的「Compressing neural networks with the hashing trick」,它的主要思想是通过单种子的随机哈希函数将原始空间和压缩空间连接起来,并通过设定压缩空间大小来达到配置任意压缩率的目的。但是,在这种方法中压缩率和冲突率成正比(这里的冲突是指原始 embedding 空间不同位置的点落入压缩空间的同一个位置上),而冲突率过大则会使效果有损。图 4-b)是为了降低冲突率而提出的多种子随机哈希压缩算法,它的流程如下:对于一个要解压的参数,首先根据它的位置获得多个随机哈希值,映射至用户配置的压缩空间,并取出相应的哈希值作为轻量级重构神经网络(图 4-b 虚线框内)的输入,该网络的输出则是重构之后的参数值。相对于单种子随机哈希压缩算法,多种子随机哈希压缩算法具有更低的冲突率,并在多个任务中在效果无损情况下取得更高的压缩率。
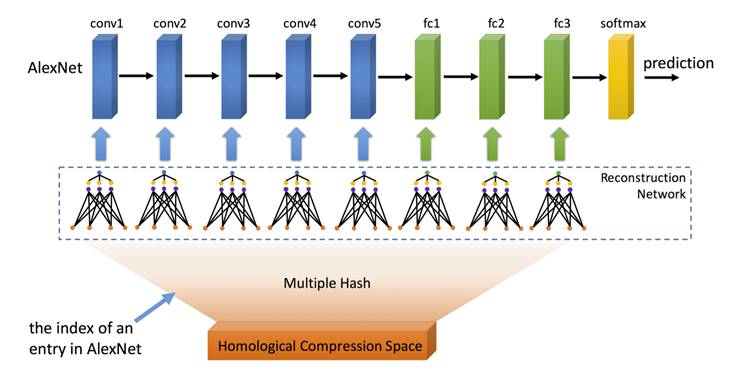
图 5. 同源多种子随机哈希压缩算法
更进一步地,我们将多种子随机哈希压缩算法推广至其他神经网络层,如卷积层、全连通层。但是这样会带来一个问题,不同层的压缩率如何设置。为了解决这个问题,我们提出同源压缩算法,如图 5 所示,即深度神经网络的所有层公用一个压缩空间,而不同层拥有各自的轻量重构神经网络。这种方式不仅方便设置统一的压缩率,而且诸多实验表明具有更好的压缩效果。图 6 是固定网络大小时不同压缩率下的错误率情况,可以看出,在不同数据集、不同深度的模型以及同一压缩率下,相对于单种子随机哈希压缩算法(HashedNets),同源多种子随机哈希压缩算法(HMRH)具有更低的错误率。
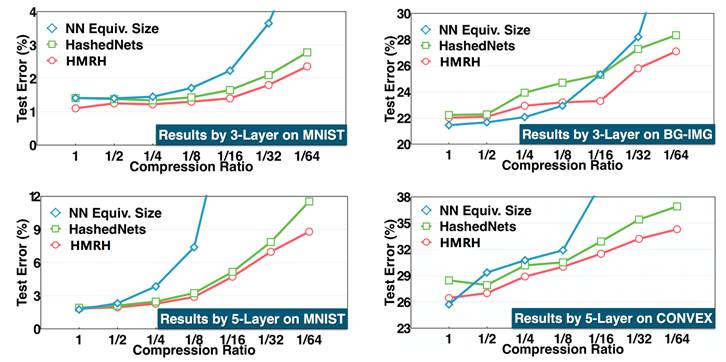
图 6. 固定网络大小时不同压缩率下的错误率
多种子随机哈希压缩算法能够与前面所述的两种压缩算法搭配使用,可实现更大的无损压缩。
总结
至此,我们介绍了 3 种 DNN 模型压缩算法,它们有各自的优点,适用于不同的应用场景:
Log 域量化压缩算法能够实现 1/4 无损压缩,具有普适性,且原始模型无需重训,使用方便。
多层次乘积量化压缩算法则进一步有 1/8 无损压缩率,它根据 embedding 的重要程度来分配不同压缩率的乘积量化,故适用于具有区分度的 embedding 层的 DNN 模型,同样地,原始模型无需重训,使用方便。
多种子随机哈希压缩算法能够配置任意压缩率,需和模型一起训练。它能和 Log 域量化压缩组合达到更大的压缩率,故能支持超大规模的 DNN 模型。举一个极端例子,若给全球 72 亿人每人一个 128 维 embedding,按浮点存储需要约 3.4T 内存,这是巨大的内存开销,而且也难以在普通单机环境下部署。多种子随机哈希压缩算法若设置 25 倍压缩率,再辅以 Log 域量化,可实现 100 倍内存压缩至 34G,使得其能够在普通单机环境部署。甚至在效果有损可接受范围内设置更大的压缩率,可进一步压缩到 1G 以内,支持嵌入式场景应用。
除了内存方面的压缩外,我们在减少深度神经网络模型 CPU/GPU 计算上也做了大量的工作,其中一个典型工作为剪枝算法(Pruning)。它的思路为动态剪枝不重要的连接点与边,使其矩阵乘法计算稀疏化,从而提升前向计算速度。篇幅关系,我们不在这里详细讨论相关的优化方法,有兴趣的同学可以进一步与我们联系交流。

百度NLP专栏扩展阅读:
「百度NLP」专栏主要关注百度自然语言处理技术发展进程,报道前沿资讯和动态,分享技术专家的行业解读与深度思考。

©本文为机器之心专栏,转载请联系本公众号获得授权。
✄------------------------------------------------
加入机器之心(全职记者/实习生):hr@jiqizhixin.com
投稿或寻求报道:editor@jiqizhixin.com
广告&商务合作:bd@jiqizhixin.com
点击阅读原文,查看机器之心官网↓↓↓



