深度学习初探:使用Keras创建一个聊天机器人
【导读】本篇文章将介绍如何使用Keras(一个非常受欢迎的神经网络库来构建一个Chatbot)。首先我们会介绍该库的主要概念,然后将逐步教大家如何使用它创建“是/否”应答机器人。我们将利用Keras来实现Sunkhbaatar等人的论文“End to End Memory Networks”中的RNN结构。

论文地址:
https://arxiv.org/pdf/1503.08895.pdf
这个任务很有趣,我们要学习如何将研究工作中获得的知识,转化为可以实现目标(创建“是/否”应答机器人来回答特定问题)的实际模型。
如果这是你第一次尝试实现NLP模型,请不要害怕; 我将带领你走完每一步,并在最后放上代码链接。为了获得最佳学习体验,我建议您先阅读文章,再浏览代码,同时浏览文章附录部分。
Keras:基于Python的简易神经网络库
Keras是一个开源的高级库,用于开发神经网络模型。它由谷歌的深度学习研究员FrançoisChollet开发。它的核心原则是建立一个神经网络,对其进行训练,然后使用它来进行预测。对于任何具有基本编程知识的人来说,Keras很容易就能学会,同时Keras允许开发人员完全自定义ANN的参数。
Keras实际上只是一个可以运行在不同的深度学习框架之上的接口,如CNTK,Tensorflow或Theano。它的工作原理与所使用的后端无关,不管你使用哪种框架作为底层,Keras都可以运行。
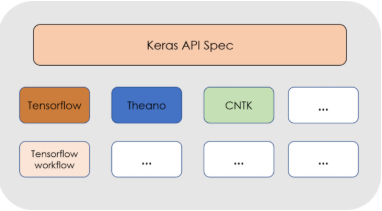
在神经网络中,特定层中的每个节点都采用前一层输出的加权和,对它们应用数学函数,然后将结果传递给下一层。
使用Keras,我们可以创建表示不同的层,也可以轻松定义这些数学运算和层中的节点数。这些不同的层用一行代码就能创建完成。
创建Keras模型的步骤如下:
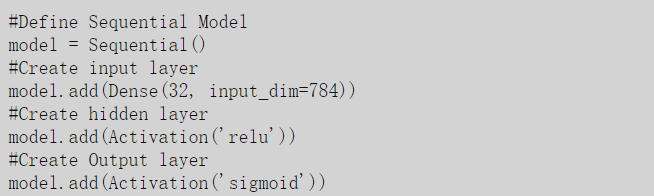
步骤1:首先我们必须定义一个网络模型,大多数时候网络是序列模型:网络将被定义为一系列层,每个层都可以自定义大小和激活函数。在这些模型中,第一层将是输入层,需要我们自己定义输入的大小。然后可以添加其他我们需要的层,最终到达输出层。
步骤2:创建网络结构后,我们必须编译它,将我们先前定义的简单层序列转换为一组复杂的矩阵运算,它将展示模型的行为方式。然后,我们必须定义将用于训练网络的优化算法,并选择将被最小化的损失函数。
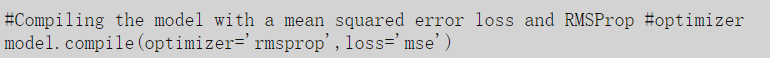
步骤3:完成上述操作后,我们可以训练或调整网络,使用的方法是反向传播算法。
步骤4:网络训练完成后,我们可以用它来预测新数据。
正如您所看到的,使用Keras构建网络是相当容易的,所以我们将使用它来创建我聊天机器人!上面使用的代码块不代表实际的具体神经网络模型,它们只是每个步骤的示例,以帮助说明如何使用Keras API构建神经网络。
您可以在官方网页上找到有关Keras的所有文档以及如何安装它。
项目:使用递归神经网络构建Chatbot
让我们使用神经网络来构建一个Chatbot!大多数情况下,神经网络结构比标准结构“输入-隐藏层-输出”更复杂。有时我们想构建一个自己的神经网络,有时我们也希望能实现在论文中看到的模型。在这篇文章中,我们将根据Sukhbaatar等人的论文“End to End Memory Networks”构建神经网络模型。并且,我们会教大家如何保存训练模型,这样就不必每次想要使用我们构建的模型进行预测时都要重新训练网络。让我们开始吧!
模型:灵感
如前所述,本文中使用的RNN取自“End to End Memory Networks”一文,因此我建议您在继续之前先看一下它。本文实现了类似RNN的结构,该结构使用注意力模型来解决RNN的长期记忆问题。
注意力模型因其在机器翻译等任务中取得的非常好的结果而引起了广泛的关注。它们解决了先前提到的RNN长序列和短期记忆的问题。想想一个人如何将长句从一种语言翻译成另一种语言?一般是将句子分成较小的块并逐个翻译,而不是一次性翻译完句子。因为对于很长的句子很难完全记住它然后立刻翻译它。

注意机制就是这样做的。在每个时间点上,模型会给予输入句子中与我们试图完成的任务更相关的那些部分更高的权重。这就是名称的来源:它注重更重要的事情。上面的例子说明了这一点; 翻译句子的第一部分,输出时也要查看相对应的部分,而不是整个句子的翻译。
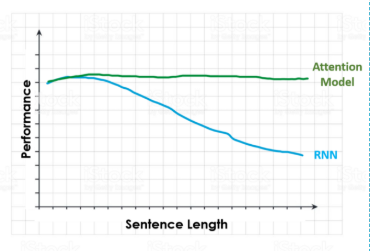
下图显示了当我们增加了输入句子的长度时,RNN与Attention模型的性能变化。当面对一个很长的句子,并要求执行一项特定的任务时,RNN在处理完所有句子之后可能已经忘记了它所拥有的第一个输入。
现在我们知道了什么是注意力模型,让我们看看我们将要使用的模型的结构。对模型输入xi(句子),关于这样的句子的查询q,并输出答案a,“是/否”。
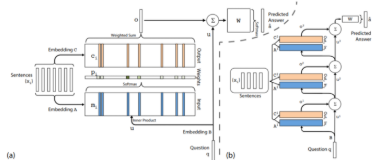
在上图的左侧部分,我们可以看到该模型的单层的表示。针对每个句子计算两个不同的嵌入A和C。此外,查询或问题q使用B来嵌入表示。
A的嵌入是由问题的嵌入u的内积计算得来的。最后,我们使用来自C(ci)的嵌入以及从点积获得的权重或概率pi来计算输出向量o。利用这个输出向量o、权重矩阵W和问题的嵌入u,最终可以计算预测的答案。
为了构建整个网络,我们只需在不同的层上重复这些过程,使用前一层的预测输出作为下一层的输入。如上图的右侧部分。接下来我们会用python实现模型来帮助你更好的理解。
数据:情节,问题和答案
2015年,Facebook提出了bAbI数据集和20个用于测试bAbI项目中文本理解和推理的任务(详细描述参照https://arxiv.org/abs/1502.05698#)。
每项任务的目标是挑战跟机器文本相关的某一方面,测试学习模型的不同功能。在这篇文章中,我们将挑战其中一项任务,“具有单一支持事实的QA”。
下面显示了这种QA机器人的预期行为示例:
FACT: Sandra went back to the hallway. Sandra moved to the office.
QUESTION: Is Sandra in the office?
ANSWER: yes
数据集分为训练集(10k实例)和测试集(1k实例),其中每个实例都有一个事实,一个问题,以及该问题的“是/否”答案。
现在我们已经知道了数据结构,我们需要构建它的词汇表。在自然语言处理模型中,词汇表一般是是模型知道并理解的一组单词。如果在构建词汇表之后,模型在句子中看到一个不在词汇表中的单词,它将在其句子向量上给它一个0值,或者将其表示为未知。
VOCABULARY:
'.', '?', 'Daniel', 'Is', 'John', 'Mary', 'Sandra', 'apple','back','bathroom', 'bedroom', 'discarded', 'down','dropped','football', 'garden', 'got', 'grabbed', 'hallway','in', 'journeyed', 'kitchen', 'left', 'milk', 'moved','no', 'office', 'picked', 'put', 'the', 'there', 'to','took', 'travelled', 'up', 'went', 'yes'
由于我们的训练数据没有很多变化(大多数问题使用相同的动词和名词,但使用不同的组合),我们的词汇量不是很大,但在中等大小的NLP项目中,词汇量可能非常大。
我们要建立一个词汇表,我们应该只使用训练数据;测试数据应在机器学习项目的最开始时与训练数据分开,直到需要评估已选择和调整的模型的性能时才触及。
在构建词汇表后,我们需要对数据进行向量化。由于我们使用普通单词作为模型的输入,而计算机只能处理数字,我们需要一种方法来将单词组成的句子表示成数字组成的向量。
句子向量化有很多方法,比如Bag of Words模型或Tf-Idf,但是,为简单起见,我们将使用索引向量化技术。即我们为词汇表中的每个单词提供唯一索引。
VECTORIZATION INDEX:
'the': 1, 'bedroom': 2, 'bathroom': 3, 'took': 4, 'no': 5, 'hallway': 6, '.': 7, 'went': 8, 'is': 9, 'picked': 10, 'yes': 11, 'journeyed': 12, 'back': 13, 'down': 14, 'discarded': 15, 'office': 16, 'football': 17, 'daniel': 18, 'travelled': 19, 'mary': 20, 'sandra': 21, 'up': 22, 'dropped': 23, 'to': 24, '?': 25, 'milk': 26, 'got': 27, 'in': 28, 'there': 29, 'moved': 30, 'garden': 31, 'apple': 32, 'grabbed': 33, 'kitchen': 34, 'put': 35, 'left': 36, 'john': 37}
考虑到向量化是使用随机种子来开始的,所以即使你使用与我相同的数据,也可能会得到不同的索引。别担心,这不会影响项目的结果。另外,我们词汇中的单词有大写和小写; 当进行这种向量化时,所有的单词都会变成小写表示。
在此之后,由于Keras的工作方式,我们需要填充句子。什么意思?这意味着我们需要搜索最长句子的长度,将每个句子转换为该长度的向量,并用零填充每个句子的单词数和最长句子的单词数之间的差距。
执行此操作后,数据集的随机句子应如下所示:
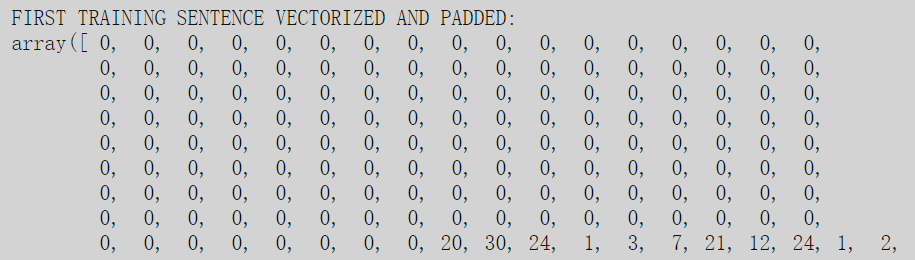
如图所示,除了最后(它的句子比最长的句子要短得多)有值之外,其他都是零。这些非零数字代表句子的不同单词的索引:20是表示单词Mary的索引,30表示移动,24表示,1表示,3表示浴室,依此类推。实际的句子是:

准备好了数据,我们就可以开始构建我们的神经网络了!
神经网络:构建模型
创建网络的第一步是在Keras中创建输入的占位符,在我们的例子中是情节和问题。在训练集批次被放入模型之前,由它们来占位。

它们必须与要提供的数据具有相同的维度。如果我们在创建占位符时不知道批数据,可以将其留空。
现在我们要创建文章A,C和B中提到的嵌入。嵌入将整数(单词的索引)转换为考虑了上下文的维度向量。Word embedding广泛用于NLP,并且是近年来该领域取得如此巨大进步的技术之一。
#Create input encoder A:
input_encoder_m = Sequential()
input_encoder_m.add(Embedding(input_dim=vocab_len,output_dim = 64))
input_encoder_m.add(Dropout(0.3))#Outputs: (Samples, story_maxlen,embedding_dim) -- Gives a list of #the lenght of the samples where each item has the
#lenght of the max story lenght and every word is embedded in the embbeding dimension
上面的代码是本文中完成的嵌入之一(A嵌入)的一个例子。像Keras一样,我们首先定义模型(Sequential),然后添加嵌入层和dropout层,通过随机关闭节点来降低模型过拟合的可能性。
一旦我们为输入句子创建了两个嵌入,并为问题创建了嵌入,我们就可以开始定义模型中发生的操作。如前所述,我们通过在问题的嵌入和情节的嵌入之间进行点积来计算注意力,然后进行softmax。下面显示了该操作的步骤:

在此之后,我们需要将输出o和匹配矩阵相加,然后使用此输出和问题的向量计算出提问的答案。

最后,添加模型的其余层,添加LSTM层(而不是文中的RNN),dropout层和最终的softmax来计算输出。

请注意,输出的向量的大小是词汇量的数量(即模型已知的词数的长度),其中除了”是”和“不是”的索引外,所有位置都应为归零。
从数据中学习:训练模型
现在我们构建好了模型,开始训练模型!
model = Model([input_sequence,question], answer)
model.compile(optimizer='rmsprop',loss='categorical_crossentropy', metrics = ['accuracy'])
通过这两行,我们对模型进行了最终的完善,并对其进行编译,即通过指定优化器,损失函数和要优化的度量来定义将在后台进行的所有数学运算。
现在是时候训练模型了,在这里我们需要定义模型的输入(输入情节,问题和答案),我们将为模型提供的批数据大小(即一次训练输入多少数据) ,以及我们准备训练模型的次数(模型训练数据更新权重的次数)。我使用了1000个epoch获得了98%的准确度,但即使只有100到200个epoch,也能得到非常好的结果。
训练可能需要一段时间,它取决于您的硬件。完成训练后,你可能会想知道“每次我想使用模型时我都要等很长时间吗?”答案是,不。Keras可以将权重和所有配置保存下来。如下所示:

如果想要使用保存的模型,只需要简单的加载:
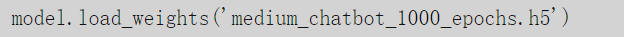
现在模型已经训练完成,用新数据来测试它的表现!
观察结果:测试和运行
观察模型在测试集上的表现
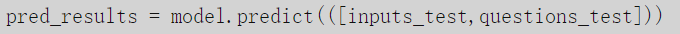
如前所述,这些结果是一个数组,它的每个位置是词汇表中每个单词的概率,这些概率就是问题的答案。如果我们查看这个数组的第一个元素,我们将看到一个词汇量大小的向量,除了对应答案的单词位置,向量中的元素几乎都是0。
其中,如果我们选择数组最高值的索引,然后查看它对应的单词,我们应该能得出答案是肯定的还是否定的。
我们现在可以做的一件有趣的事情是创建我们自己的情节和问题,并将它们提供给机器人,看看它给的答案!

我创建了一个情节和一个和机器之前看到过的问题很像的问题,并且在将其调整为神经网络希望机器人回答'是'的格式。
让我们尝试不同的输入。

这次的答案是:"当然,为什么不呢?"
开个玩笑,我没有尝试那个情节/问题组合,因为包含的许多单词都不在我们的词汇表中。此外,机器只知道如何说'是'和'不是',并且通常不会给出任何其他答案。但是,通过更多的训练数据和其他的一些方法,可以轻松实现这一目标。
享受AI,感谢阅读!
代码链接:
https://github.com/jaimezorno/Deep-Learning-for-NLP-Creating-a-Chatbot/blob/master/Deep%20Learning%20for%20NLP-%20Creating%20a%20chatbot.ipynb
-END-
专 · 知
专知,专业可信的人工智能知识分发,让认知协作更快更好!欢迎登录www.zhuanzhi.ai,注册登录专知,获取更多AI知识资料!

欢迎微信扫一扫加入专知人工智能知识星球群,获取最新AI专业干货知识教程视频资料和与专家交流咨询!

请加专知小助手微信(扫一扫如下二维码添加),加入专知人工智能主题群,咨询技术商务合作~

专知《深度学习:算法到实战》课程全部完成!560+位同学在学习,现在报名,限时优惠!网易云课堂人工智能畅销榜首位!

点击“阅读原文”,了解报名专知《深度学习:算法到实战》课程




