DeepLab v2及调试过程
今天我们开始说说语义分割第二个系列,DeepLab V2。说这个之前,我们先说说FCN的一些简单知识。
图像语义分割,简单而言就是给定一张图片,对图片上的每一个像素点分类。
图像语义分割,从FCN把深度学习引入这个任务到现在,一个通用的框架已经大概确定了。即前端使用FCN全卷积网络输出粗糙的label map,后端使用CRF条件随机场/MRF马尔科夫随机场等优化前端的输出,最后得到一个精细的分割图。
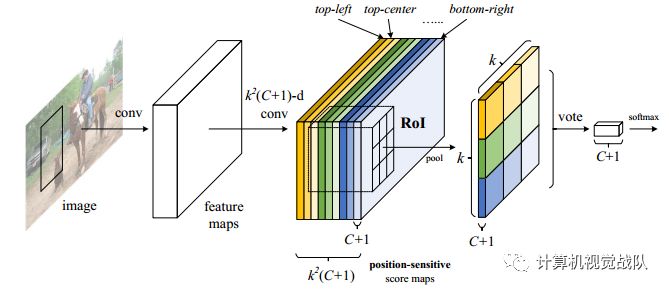
上图示基于区域的全卷积框架图,而且这也是第一次用于目标检测的全卷积网络,最后的效果得到了很好的效果

图像语义分割,从FCN把深度学习引入这个任务到现在,一个通用的框架已经大概确定了。即前端使用FCN全卷积网络输出粗糙的label map,后端使用CRF条件随机场或者MRF马尔科夫随机场等优化前端的输出,最后得到一个精细的分割图。
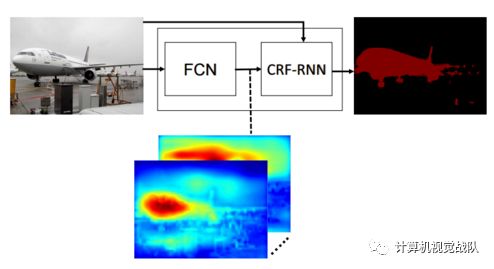
我们为什么需要FCN?
分类网络通常会在最后连接几层全连接层,它会将原来二维的矩阵(图片)压扁成一维的,从而丢失了空间信息,最后训练输出一个标量,这就是我们的分类标签。
而图像语义分割的输出需要是个分割图,且不论尺寸大小,但是至少是二维的。所以,流行的做法是丢弃全连接层,全部换上全卷积层,而这就是全卷积网络了。
具体定义请参看论文:《Fully Convolutional Networks for Semantic Segmentation》
FCN结构
在FCN论文中,作者的FCN主要使用了三种技术:
卷积化(Convolutional)
上采样(Upsample)
跳层连接(Skip Layer)
卷积化即是将普通的分类网络,比如VGG16,ResNet50/101等网络丢弃全连接层,换上对应的卷积层即可。
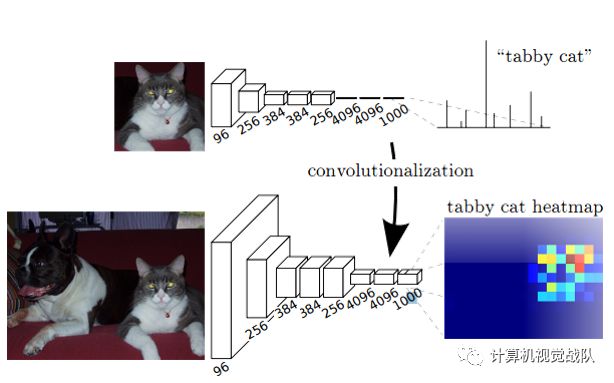
上采样即是反卷积(Deconvolution)。当然关于这个名字不同框架不同,Caffe和Kera里叫Deconvolution,而tensorflow里叫conv_transpose,在信号与系统这门课上,我们学过反卷积有定义,不是这里的上采样。
所以叫conv_transpose更为合适。
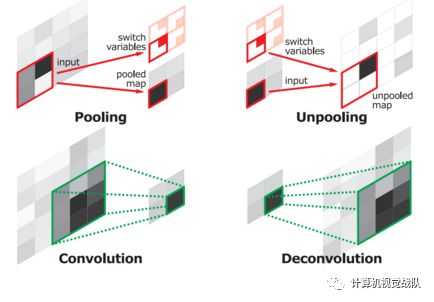
众所诸知,池化会缩小图片的尺寸,比如VGG16 五次池化后图片被缩小了32倍。为了得到和原图等大的分割图,我们需要上采样/反卷积。反卷积和卷积类似,都是相乘相加的运算。只不过后者是多对一,前者是一对多。而反卷积的前向和后向传播,只用颠倒卷积的前后向传播即可。所以无论优化还是后向传播算法都是没有问题。上池化的实现主要在于池化时记住输出值的位置,在上池化时再将这个值填回原来的位置,其他位置填0。图解如下:
但是,虽然文中说是可学习的反卷积,但是作者实际代码并没有让它学习,可能正是因为这个一对多的逻辑关系。代码如下:
layer { name: "upscore" type: "Deconvolution" bottom: "score_fr" top: "upscore" param { lr_mult: 0 } convolution_param { num_output: 21 bias_term: false kernel_size: 64 stride: 32 } }
可以看到lr_mult被设置为了0.
跳层连接的作用就在于优化结果,因为如果将全卷积之后的结果直接上采样得到的结果是很粗糙的,所以作者将不同池化层的结果进行上采样之后来优化输出。具体结构如下:
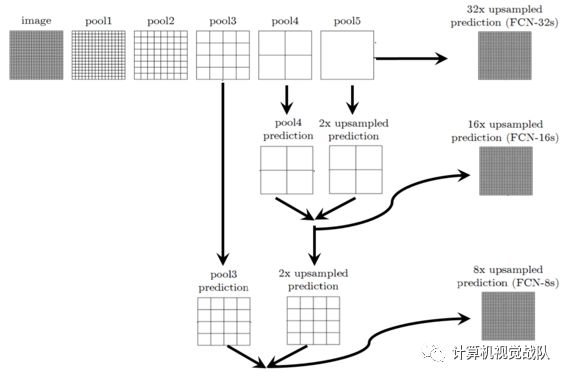
不同上采样得到的结果对比如下:
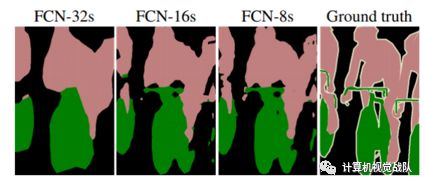
当然,你也可以将pool1, pool2的输出再加上采样作为输出。不过,作者说了这样得到的结果提升并不大。FCN是深度学习应用于图像语义分割的开山之作,所以得了CVPR2015的最佳论文。但是,还是有一些处理比较粗糙的地方,具体和后面对比就知道了。
DeepLab V2
DeepLab: Semantic Image Segmentation with Deep Convolutional Nets, Atrous Convolution, and Fully Connected CRFs
深度卷积网络用于语义分割的三个挑战:
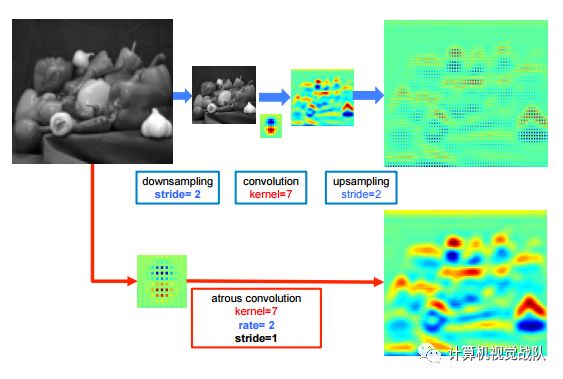
特征分辨率下降。主要由于重复池化和下采样造成,作者移除了最后几个最大池化层下采样操作,并对滤波器进行上采样,在非零的滤波器值之间加入空洞,称为atrous卷积。 atrous卷积示意图为:
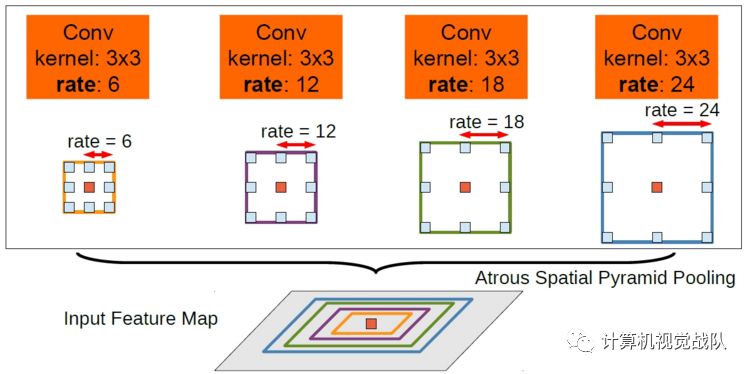
多尺度目标。一般将不同尺度的图像输入DCNN,但计算量增加。作者根据SPP的思想,在给定特征层使用不同的采样率进行重采样,使用具有不同采样率的平行atrous卷积层实现,称为atrous SPP(ASPP)。atrous SPP方法示意图如下图所示:
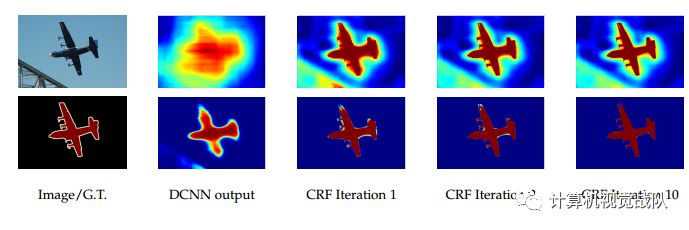
DCNN的不变性,导致定位准确率下降。基于对象的分类器要求对形变不变,影响了分割准确性,hpyer-column有被用来消除这个问题。作者使用全连接的条件随机场(CRF)获取细节信息。CRF被广泛用于语义分割,通过组合多路低层次分类器的信息,如边缘,superpixels等。CRF用于增强边缘信息示意图:
DeepLab模型的结构如下图所示:
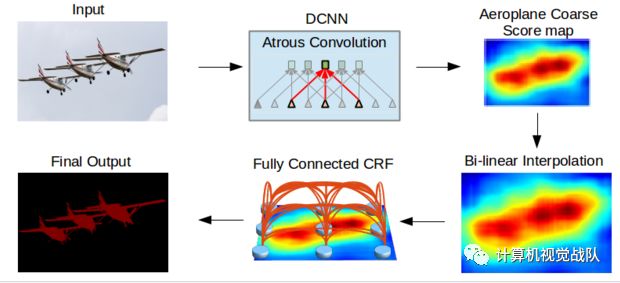
对VGG-16,ResNet-101进行一些改动用于语义分割:
所有的全连接层变为卷积层
使用atrous卷积层提高特征分辨率,这样可以每8个像素计算一个特征响应,之后双向性插值上采样8倍到原始图像分辨率,输入到CRF精修分割结果。
实验结果
使用不同的技巧对结果的增强

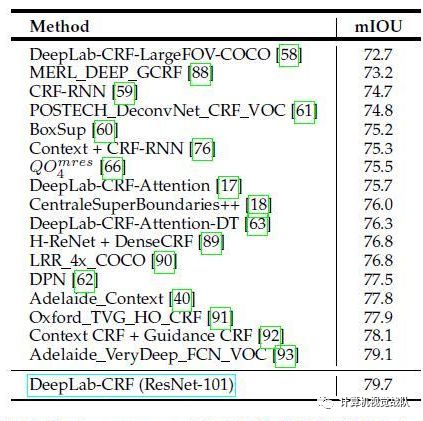
与其他方法在VOC2012上的比较
PASCAL-Context的结果:

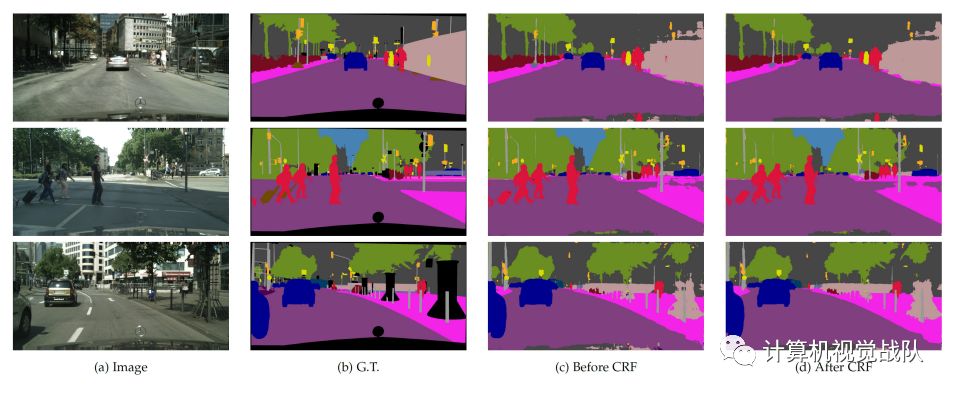
城市景观结果
PASCAL-Person-Part
人体六个部位Head, Torso,Upper/Lower Arms and Upper/Lower Legs分割

但是本方法也有产生错误的情况,如下:

提出的模型无法捕捉物体的精细边界,例如自行车和椅子。我们假设有些文献的编解码结构可以通过利用解码器路径中的高分辨率特征映射来缓解这一问题。





