刘挺 | 从知识图谱到事理图谱
本文转载自 AI科技评论。
在“知识图谱预见社交媒体”的技术分论坛上,哈尔滨工业大学刘挺教授做了题为“从知识图谱到事理图谱”的精彩报告。会后AI科技评论征得刘挺教授的同意,回顾和整理了本次报告的精彩内容。

刘挺教授
刘挺教授的报告内容分为四部分:
知识图谱与《大词林》
事理图谱概念的提出
事理图谱国内外相关工作
哈工大在事理图谱方面的探索
知识图谱与《大词林》
知识图谱最早是通过人工搜集数据和标注数据来构建的,随着需求的多样化和精细化(例如,需要获得“XX疾病是否可以被XX药物治疗”,“XX人和XX人之间是否是敌人/朋友”等信息),人工构建的知识图谱越发难以满足用户多种多样的需求。基于此,如何由机器去自动构建大规模的知识图谱已经发展成为热门的研究点。
知识图谱,是基于二元关系的知识库,用以描述现实世界中的实体(或概念,概念是实体的抽象,例如“水果”即为“苹果”的概念)及其相互关系,其基本组成单位是『实体-关系-实体』三元组(triplet),实体之间通过关系相互联结,构成网状结构。通过知识图谱,可以支持用户按主题而不是按字符串检索,从而真正地实现在语义层面上进行信息检索。基于知识图谱的搜索引擎,能够直接向用户反馈结构化的知识,用户不必浏览大量网页,就可以找到自己想要获得的知识。
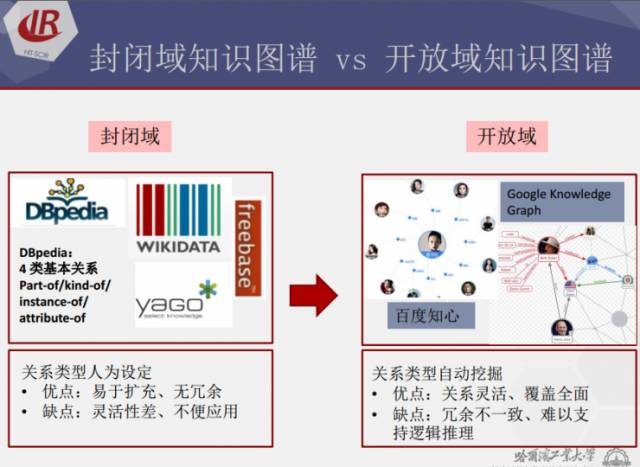
封闭域知识图谱和开放域知识图谱各有优劣
2014年年末,哈工大正式发布《大词林》。现在只需在浏览器中键入www.bigcilin.com,即可访问《大词林》。《大词林》是一种自动从网络中爬取实体及实体的概念以形成基于上下位关系的通用知识图谱。这意味着,如果用户输入的词语不被《大词林》所包含,《大词林》即会实时地到互联网上去搜索,以自动挖掘该词语的上位概念词,并将这些上位概念词整理为层次结构。比如输入“林肯”,《大词林》就会根据“林肯”在网络中出现的语义信息,自动挖掘出“林肯”所具有的多个概念,例如“汽车”、“总统”、“交通工具”、“领袖”等,然后再根据这些概念的抽象程度,将这些概念刻画为层次结构。例如“领袖”相对于“总统”更加抽象,在图中“领袖”的层次就比“总统”更高。
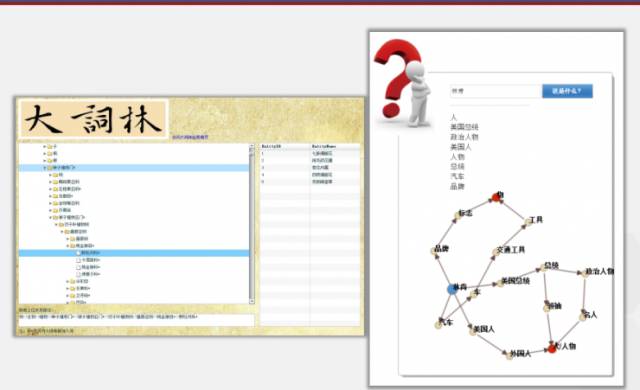
上图左侧为《大词林》层次目录的一部分,其骨架是《同义词词林(扩展版)》。《大词林》选择《同义词词林(扩展版)》作为骨架的原因在于:经过反复的探讨,刘挺教授带领的团队认为词汇应具有两种类型,一种是“实体”与真实的事物相对应,比如具体的人名、地名、机构名;另一种是“概念”,是“实体”的抽象含义,比如“植物”、“水果”等。实体之间具有明显的横向关系,而“实体”和“概念”、“概念”和“概念”之间具有明显的层次关系,因此词汇之间应具有由横向关系和纵向关系所形成的网状结构。基于此,刘挺教授带领的团队将《同义词词林(扩展版)》作为《大词林》层次(纵向)关系构建的骨架。
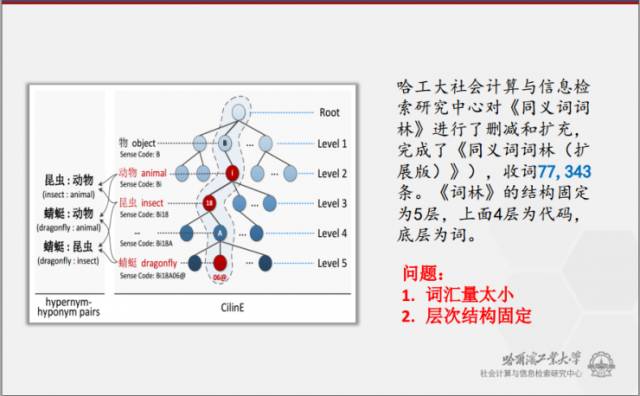
这里简单介绍一下作为《大词林》的骨架-《同义词词林(扩展版)》存在的问题。《同义词词林》的第一个问题是仅具有固定的5层结构,但面对千万级乃至亿万级规模多领域、多样性的词汇,固定的结构显然无法对其进行有效描述;第二个问题是《同义词词林(扩展版)》包含的词语数目非常有限,且大部分为抽象的概念,其规模不到十万词,显然不适合实际应用。基于此,刘挺教授带领的团队决心打破《同义词词林(扩展版)》的上述限制,从而形成了现在的《大词林》。首先,《大词林》的层数是不固定的,其根据词语的抽象程度自动进行层次化;其次,《大词林》中包含了很多具体的实体(例如人名、地名、机构名),其规模是《同义词词林(扩展版)》的数百倍,并且还在不断的扩充。
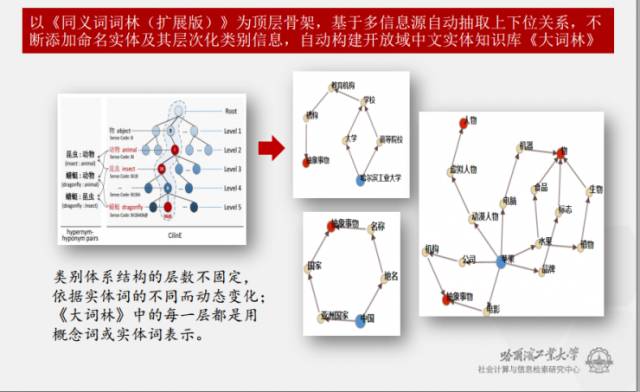
《大词林》的特点在于能够从多种信息源中自动地构造词汇和词汇的上下位关系。这是刘挺教授带领的团队中一名博士生发表的一篇ACL会议论文(该会议是自然语言处理领域的顶级会议,被计算机学会评定为Rank A),这篇论文详细地展示了如何自动的从多信息源里获取实体概念词的技术框架。
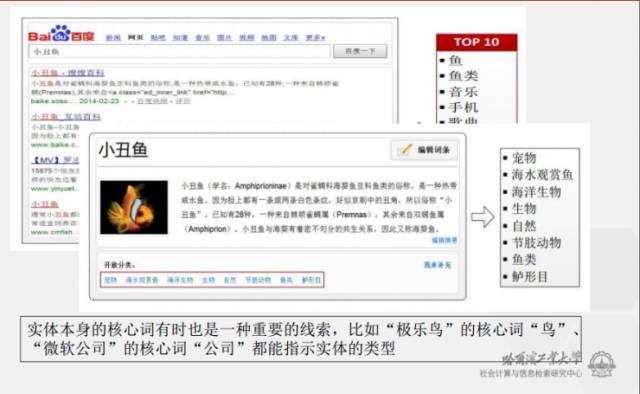
简单来说,获取概念词的来源主要有三个,1)搜索引擎中检索得到的高概率的同现词,2)在线百科的类别标签3)词语的构词法,对于很多词,其后缀即为该词的概念词,例如像微软公司的公司就是微软公司这个实体的概念词。之后,采用排序算法对获取得到的这些候选概念词进行打分,然后截取超过一定阈值的候选概念词保留到《大词林》中。
上面的方法仅仅获取了针对某个词语的概念词,如左图所示。但是,概念词之间是有明显的层次关系的,如右图所示,而《大词林》的特殊之处就在于能够自动形成概念词之间的层次结构。基于上述的处理方案,从《同义词词林(扩展版)》的十万词出发,现在的《大词林》已经成为一个具有千万级词汇量级的知识图谱,并且其规模每天都在不断的增长。
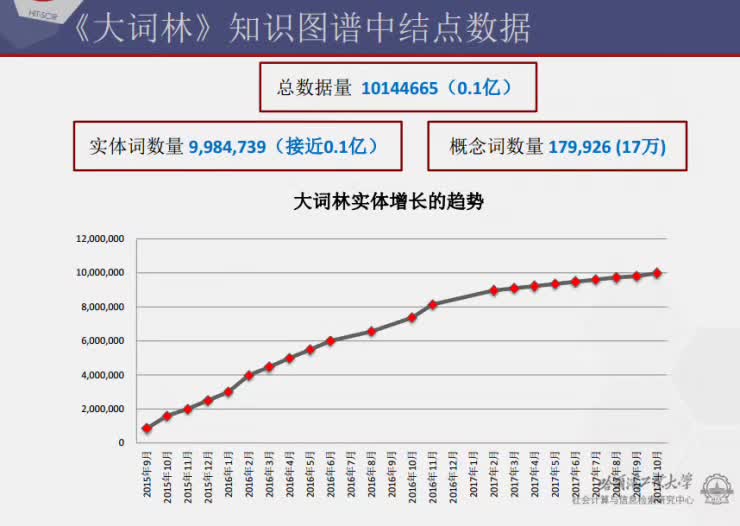
由于《大词林》是自动构建的,因此需要对其质量做一个评估,以判别《大词林》中是不是包含了很多的错误,到底可不可以实用。刘挺教授带领的团队对《大词林》做过抽样评估。结果显示,针对某个词语,找到其概念词的准确率为85%,词语之间的上下位关系识别的准确率为90%。
相比于其他知识图谱,《大词林》主要专注于语言学中词汇的上下位关系的自动构建,是一种语言的知识图谱。当然,目前刘挺教授带领的团队也着手在《大词林》中引入横向关系,相信不久的将来就能看见更加全面的《大词林》。
事理图谱概念的提出
关于事理图谱。现有的知识库普遍是以“概念及概念间的关系”为核心的,缺乏对“事理逻辑”知识的挖掘。刘挺教授团队认为在实际应用中,事理逻辑(事件之间的演化规律与模式)是一种非常有价值的常识知识,挖掘这种知识对我们认识人类行为和社会发展变化规律非常有意义。举个经典例子,北京人买房子,买完房子下一步就是装修,装修完了就会买家具,如果在网上发现有人发微博说他买房子了,装修公司就可以跟上去做广告,这就是一种预测。事理图谱并不是以名词为核心节点的知识库,而是以事件而且是抽象类事件为核心的事理逻辑知识库。举个例子,国家领导人访问另一个国家,这就是一个抽象事件。刘挺教授的团队三年前就提出了事理图谱的概念。

事理图谱只定义两种事件间关系:一种顺承,一种因果,这两种关系都有时间顺序。本质上事理图谱是一个事理逻辑知识库,描述了事件之间的演化规律和模式,可以应用在生活中的很多方面,比如事件预测 ,常识推理,消费意图挖掘,对话生成等等。

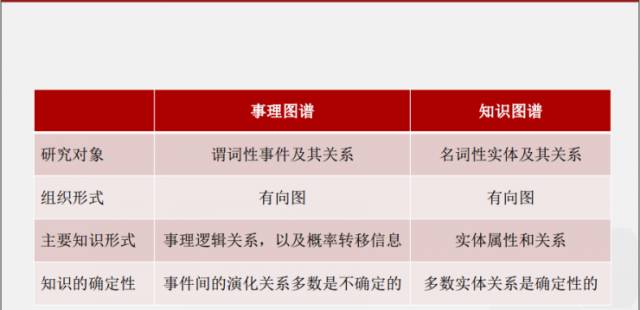
事理图谱与知识图谱的区别,知识图谱研究对象为名词性实体及其关系,事理图谱研究对象是谓词性事件及其关系。知识图谱主要知识形式是实体属性和关系,事理图谱则是事理逻辑关系以及概率转移信息。事件间的演化关系多数是不确定的,而实体之间的关系基本是稳定的。
事理图谱中的事件定义。事理图谱中的事件是一个泛化的抽象的事件,比如吃火锅,去机场 ,看电影都可以,但要是说非常的具体,某年某月干了什么,这就不是事理图谱中存储的知识。但也不能太抽象,比如,去地方,做事情,也不是事理图谱中存储的知识。事件间的关系就两种,一种顺承关系,吃饭,买单,离开餐馆,这就是很常见的事件顺承关系。还有就是因果关系,我们认为因果关系是非常重要的,只有因果关系建立了,才能通过控制因变量去影响结果。

事理图谱有3种典型的拓扑结构, 第一种是链状,顺承关系为典型代表。第二种是树状,这其中有一种事件是心理事件,打算去做某事,并不是真做了;第三种是环状,以打架报复住院为例,循环往复。
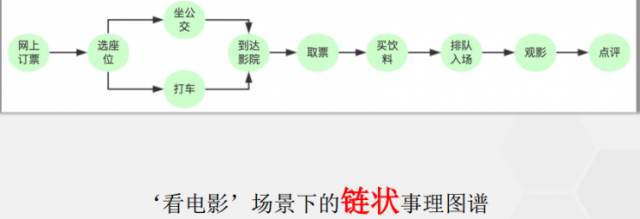
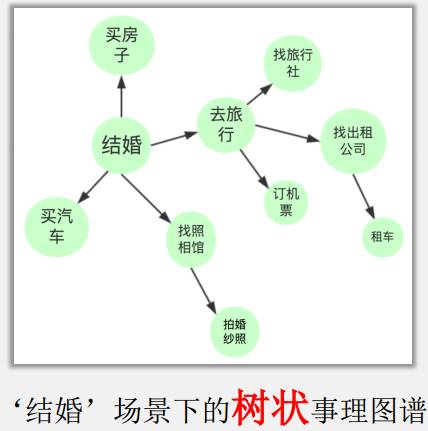
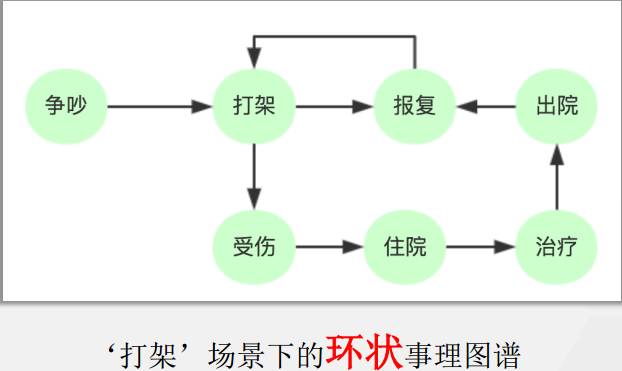
事理图谱国内外相关工作
与事理图谱最相关的两个研究方向是统计脚本学习和事件关系识别。统计脚本学习是与事理图谱非常接近的一个研究领域。1975年,美国学者Schank提出脚本概念;2003年,日本学者提出自动获取脚本的方法;2008年,Dan Jurafsky利用无监督的方法构建事件链,成为该方向一个具有代表性的先驱工作。2014至今,统计脚本相关研究工作进入了复苏和发展阶段。

除此之外,还有一条技术路线是事件间关系(时序和因果)识别。


哈工大在事理图谱的研究
哈工大主要在两个领域进行了事理图谱探索性的工作,一方面是出行领域事理图谱的构建和应用;另一方面是金融领域事理图谱的构建和应用。
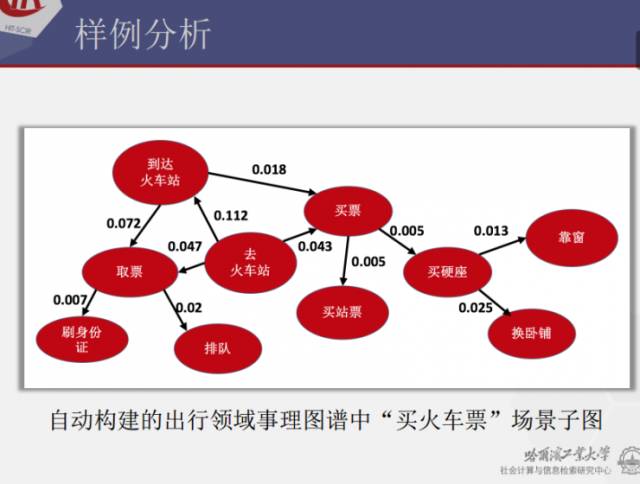
出行事理图谱的潜在应用


出行领域更多是顺承关系,其构建过程包括数据清洗、NLP预处理、事件抽取和泛化、生成候选事件对、顺承关系识别、顺承方向识别。
第二个是金融领域事理图谱。

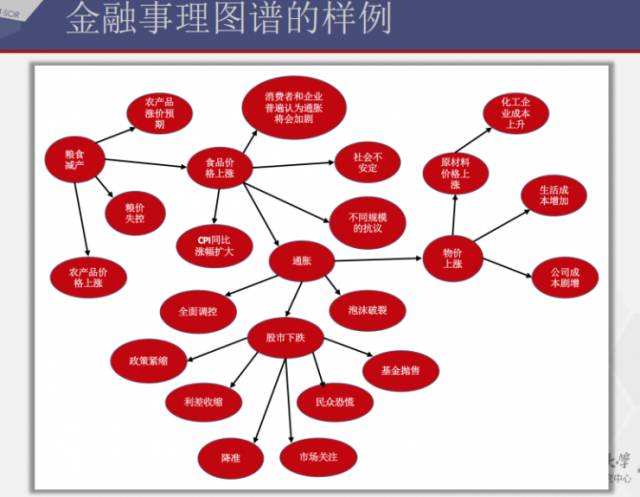
可将金融领域事理图谱应用于股市预测当中。

从知识图谱到事理图谱的总结
刘挺教授的总结:知识图谱在各个领域精耕细作,逐渐显露价值,但知识表示形式有待突破,推理能力有待提高。统计脚本学习和事件关系识别等事理图谱相关研究越来越吸引研究者的关注。以“谓词性短语”为节点,以事件演化(顺承、因果)为边的事理图谱方兴未艾。事理图谱必将在预测、对话等领域发挥重要作用,有力地提升人工智能系统的可解释性。
最后刘挺教授向他的合作者,哈工大社会计算与信息检索研究中心的秦兵教授、刘铭副教授、丁效老师,以及博士生赵森栋、李忠阳、姜天文表示感谢。
以上内容为刘挺教授在CNCC 2017 [ 知识图谱遇见社交媒体 ] 论坛上的精彩报告,AI科技评论获其独家授权整理。

OpenKG.CN
中文开放知识图谱(简称OpenKG.CN)旨在促进中文知识图谱数据的开放与互联,促进知识图谱和语义技术的普及和广泛应用。

点击阅读原文,进入 OpenKG 博客。