哈工大刘铭:开放式知识图谱的自动构建技术

分享嘉宾:刘铭博士 哈尔滨工业大学
编辑整理:盛泳潘 重庆大学
出品平台:DataFunTalk
导读:大家好,我是来自于哈尔滨工业大学社会计算与信息检索研究中心的刘铭,很高兴能有机会和大家分享我的技术报告。本文包括以下几方面内容:
人工智能发展历程
命名实体识别
关系的自动识别
实体缺失属性的自动补全
01
人工智能发展历程
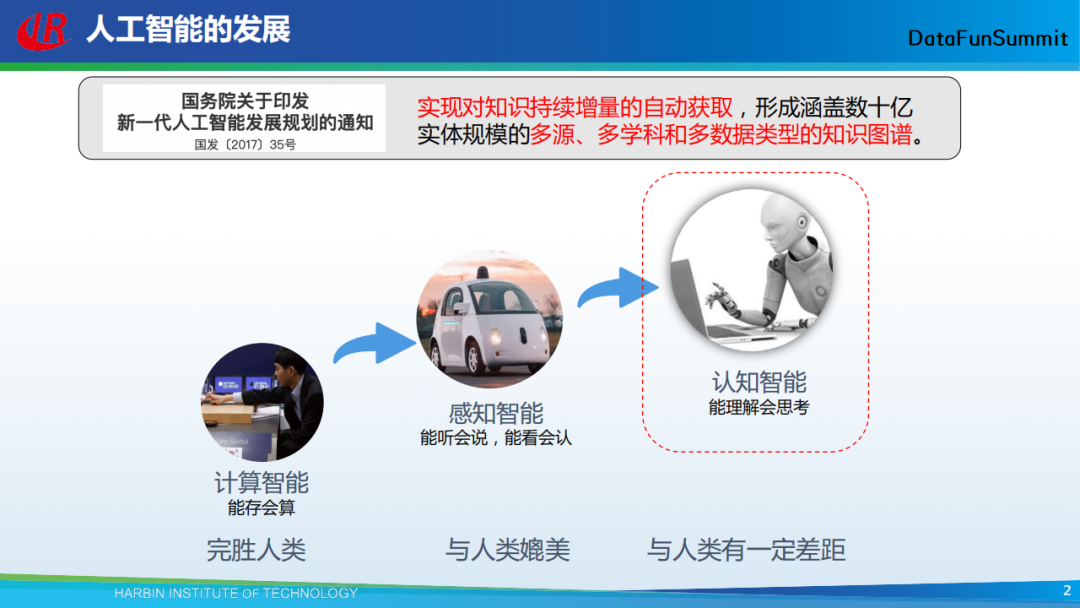
首先给大家介绍一下人工智能发展的历程,其主要可归结为3个重要的阶段:第一个阶段是计算智能,第二个阶段是感知智能,第三个阶段是认知智能。在前两个阶段,计算机能够做的像人类一样,甚至比人类做的更好。在第三个阶段,计算机还远远达不到人类的水平。很多研究者们发现,通过知识的使用,可以有效地提升计算机的认知水平。在国务院2017年印发的“新一代人工智能发展规划的通知”中,明确提出:实现对知识持续增量的自动获取,形成涵盖数十亿实体规模的多源、多学科和多数据类型的知识图谱。同时,知识图谱也是实现机器认知智能的基石。
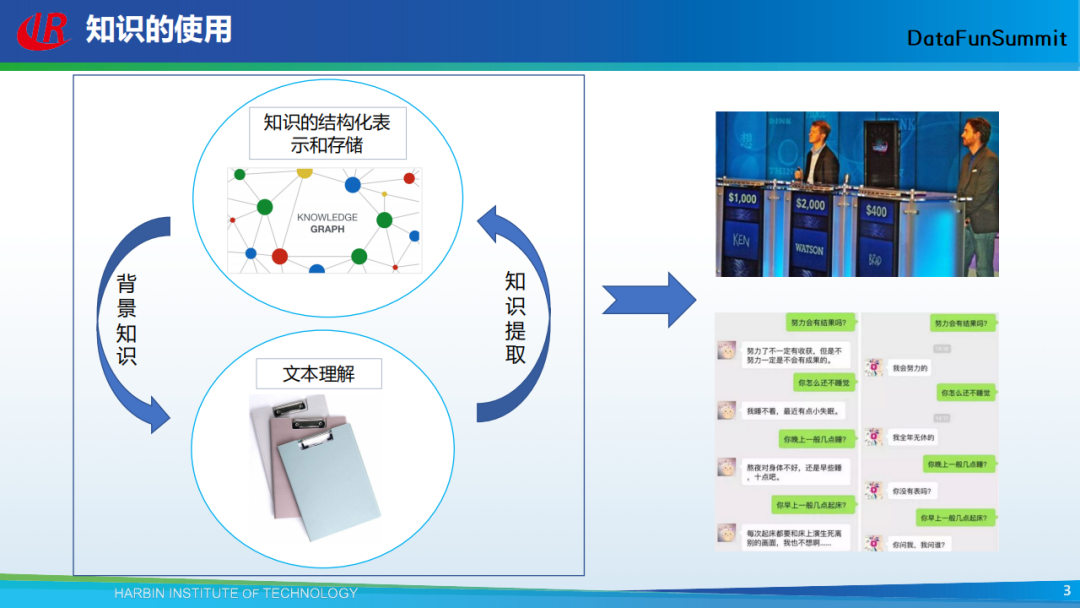
对于知识的使用一般有两种方式,一种是从文本中抽取知识,并将其形成结构化的知识库;另一种是通过知识图谱帮助我们更好地去理解文本。我们还可以将知识更好地应用于对话、问答等上层应用。今天我的报告主要从如何从非结构化的文本中抽取知识,形成知识库这一方面来展开。
02
命名实体识别
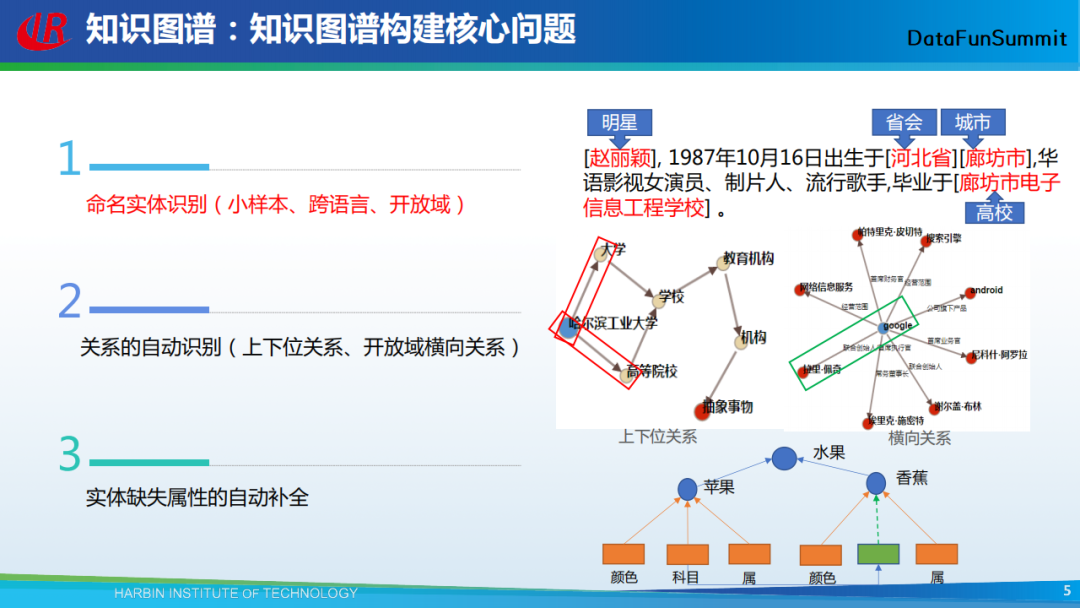
简单地来说,知识图谱就是由实体、关系所组成的网状结构。因此,关于知识图谱构建的问题主要包括以下三方面的问题:
如何去识别实体;
如何去自动识别关系;
如何去补全实体的属性。
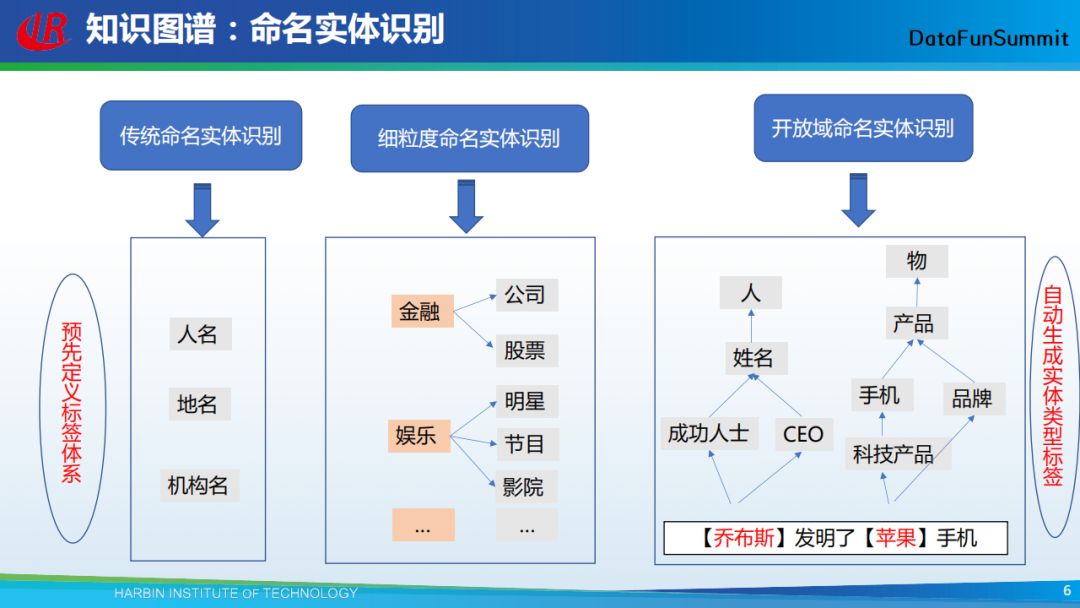
命名实体识别主要可分为传统命名实体识别、细粒度命名实体识别与开放域命名实体识别三类。第一类指的是从输入的文本中将人名、地名、机构名识别出来。传统的命名实体识别方法只能识别出有限的实体,在很多任务上的效果都不理想,然后就出现了第二类命名实体识别。简单而言,这类识别主要是在不同的领域下识别专有的命名实体。这两类命名实体识别方法需要预先定义实体的类别标签。与上述两类方法对应的是开放域命名实体识别,即从文本自动挖掘实体的细粒度类别标签。在上图的例子中,假设已从“乔布斯发明了苹果手机”这个句子中识别出“乔布斯”和“苹果”是两个命名实体,接下来要做的,就是针对这两个实体,找到它们的细粒度类别标签。通过开放域命名实体识别方法,可以自动生成实体的类别标签。
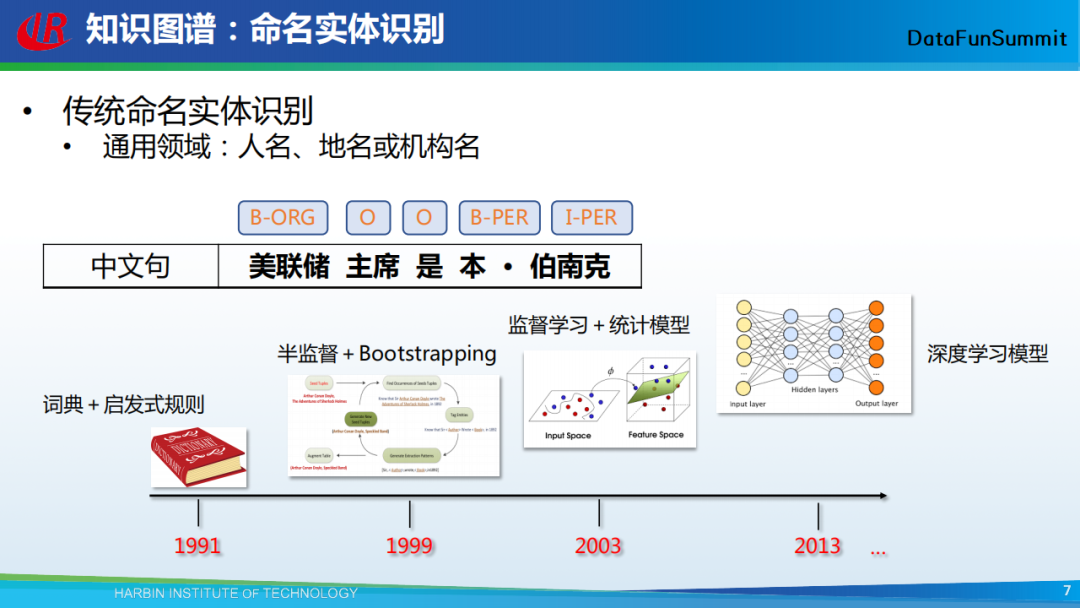
首先从传统的命名实体识别讲起。传统的命名实体识别就是从输入文本中去识别出人名、地名、机构名,在上图示例中,输入的中文句子为:“美联储主席是本•伯南克”,从中可识别出:“美联储”是一个机构,“本•伯南克”是一个人名。对于命名实体识别的研究已经持续了很长一段时间,最早可追溯至1991年,彼时提出可利用词典+启发式规则进行命名实体识别,低召回率是这类方法面临的最大问题;接下来,有研究者提出可以使用半监督+bootstrapping的方法来做,识别更多的实体以获得更多的数据;当数据充分后,在2003年提出了通过统计模型来做命名实体识别;到2013年以后,在该领域主要采用深度学习的模型来做,并且取得了令人兴奋的效果。
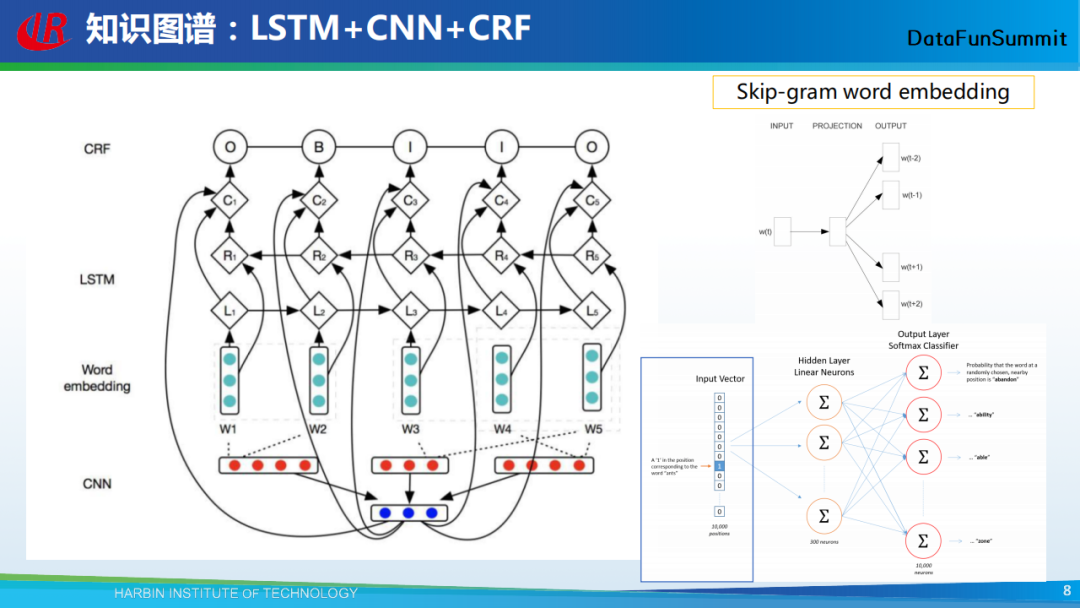
传统的命名实体识别中最流行的方法即为LSTM+CNN+CRF这个模型,该模型中,表示层是LSTM+CNN。现在很多的模型将上述表示层替换为了预训练语言模型,并取得了更好的效果。输入一般为独热向量(one-hot),但是这种表示存在高维稀疏问题。很容易影响模型的性能。当前的一些研究也在探索如何将独热向量转换为低维稠密的向量。

很多研究者对上述讲述的模型进行了扩展,并且将它们用在了不同的任务或领域上。这里给大家分享一个我们做的工作,即跨语言的命名实体识别(请见《Improving Low Resource Named Entity Recognition using Cross-lingual Knowledge Transfer. IJCAI 2018》)。该工作的主要思路是,借助于英文丰富的资源来帮助中文实体识别。由于不同语言之间包含互补的实体线索,在上图示例中,中文中的“本”很少作为实体,但是其英文翻译“Ben”却经常作为实体。因此,我们可以利用双语词典作为桥梁丰富源语言的语义表示,构建一个词典映射函数来学习未登录词的跨语言语义表示。
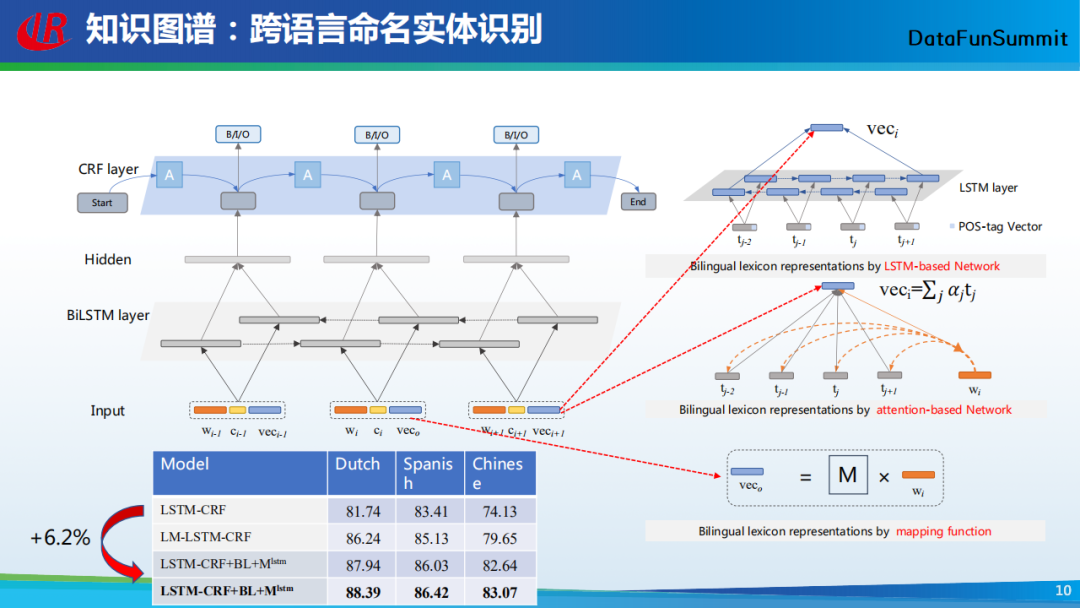
该图为上述模型的整体架构,我们可以看到,这个模型依然采用了双向LSTM(BiLSTM) +CRF的架构。不同的是输入层的词语表示,其中最左边的橙色表示词语在当前语言下的嵌入表示(即通常所用的词嵌入),中间的黄色为词语的位置向量,最右边的蓝色表示词语的跨语言表示。那么如何获得词语的跨语言表示呢?我们可以通过跨语言词典获得词语的跨语言翻译。再者,通过跨语言词典将当前词语翻译为特定语言的向量时,往往会有多个结果,但只有1-2个结果与当前的上下文是一致的。因此,我们可利用注意力机制来学习词语在当前语境下的、最合适的翻译向量。当然,还有一种情况,即对于跨语言词典无法翻译的词语,这时我们会去学一个映射矩阵,进而将词语从源语言映射到目标语言。通过以上三种表示,我们可以获得词语的跨语言表示。实验结果表明,相较于其它基线方法,我们的模型在多种语言上获得了性能的提升。
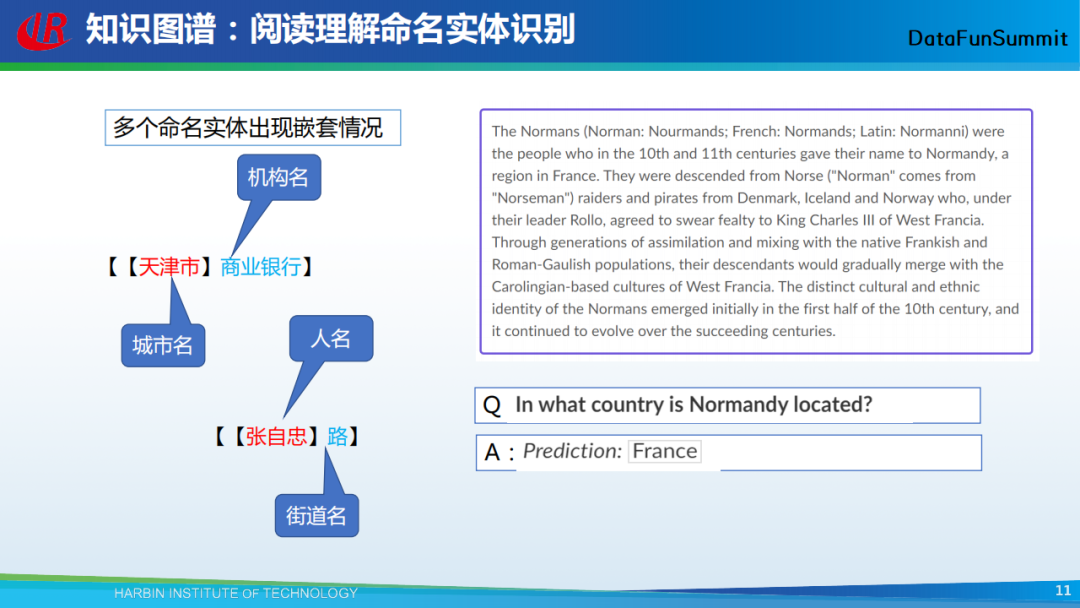
以上为第一个想和大家分享的命名实体识别方案。接下来,我将为大家介绍一种较为流行的、基于阅读理解的命名实体识别方法。在讲这个方法之前,我首先给大家介绍一下命名实体识别中可能会遇到的一个显著问题,即命名实体嵌套问题。
如上图示例(左),这两个例子中都包括一个短实体和一个长实体。在第一个例子中,“天津市”是一个城市,“天津市商业银行”是一个机构;在第二个例子中,“张自忠”是一个人名,“张自忠路”是一个街道名。我们可以利用阅读理解的框架去解决这个问题。简单而言,该方法的输入是一篇章或句子,如果我们想知道这个篇章中有哪些地名实体,那么我们可以构造一个问题,即“在当前篇章中有哪些地名”,模型返回的即为所有与地名相关的实体。当然,在上图示例中,我们构造的问题是:“诺曼底位于哪个国家(In what country is Normandy located)?”,返回的结果即为该问题的识别答案:“法国(Prediction: France)”。

结合上述方法,我们就可以去识别嵌套的命名实体。通过提出不同的问题,就可以得到不同类型的实体,进而解决嵌套实体的问题。这里面也留下了一个问题,即我们如何去构建相应的问题。由于我们需要识别的实体类型还是比较多的,那么如何才能根据不同的实体类型构建相应的问题。针对这一问题,上图为我们提供了一些思路,我们可以写一些模板,进而根据实体的类型自动构建相应的问题。
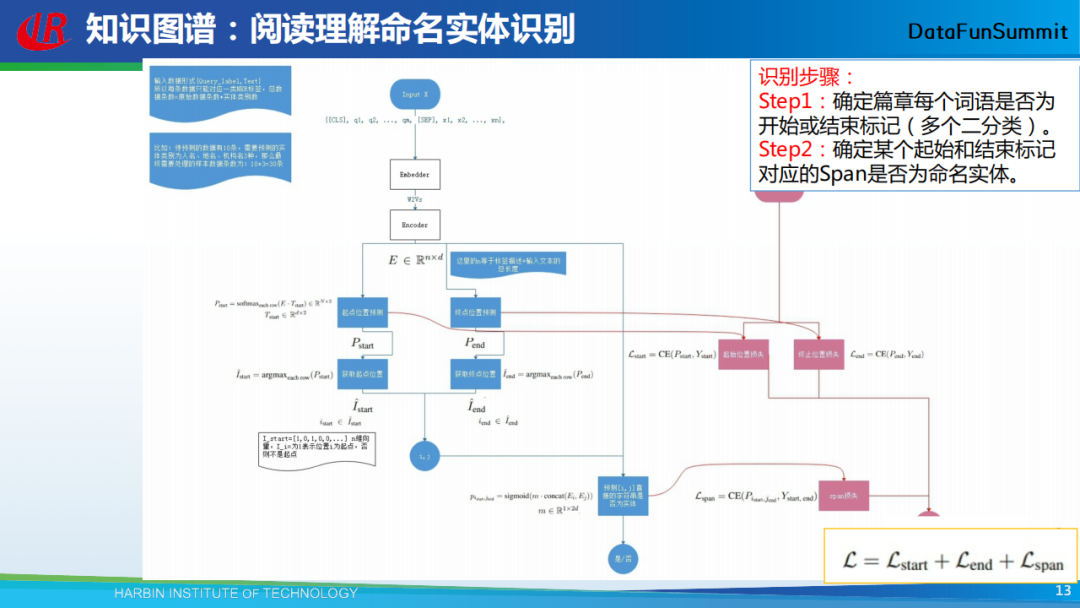
以上为该阅读理解方法的整体框架,这里我主要给大家说明该框架的主要思想,当我们提出一个问题后,应该如何获得对应的答案呢,可以采用以下步骤:首先确定篇章每个词语是否为开始或结束标记(多个二分类问题);然后确定某个起始和结束标记对应的候选实体(Span)是否为命名实体。因此,在模型中需设计三个损失函数(loss),对应图中的三个粉红色矩形。第一个loss代表答案开始位置的损失,第二个loss代表答案终止位置的损失,第三个loss代表这个答案是否是一个正确答案。
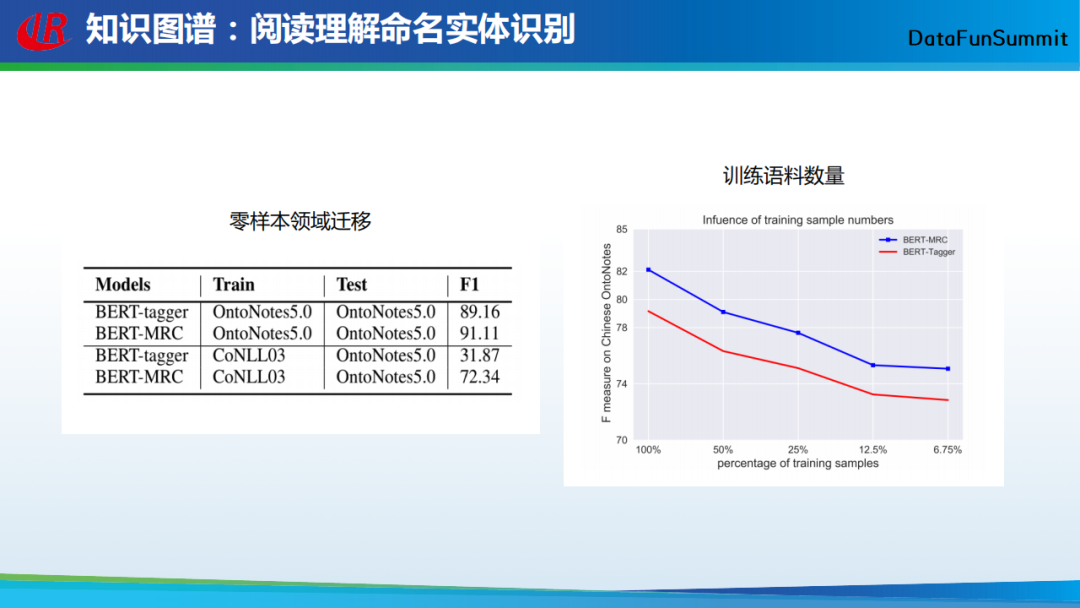
以上为这篇文章的实验结果,在零样本的领域迁移实验中,作者在一个语料上训练,在另外一个语料上测试。从实验结果中可以看出,相较于预训练模型,基于阅读理解的方法取得了不错的性能提升;在对训练语料需求数量的实验中,可以看出,该方法所需的训练语料数量明显降低。通过以上两个实验可以得到一个直观的结论,即基于阅读理解框架的命名实体识别方法可以在少量训练语料的前提下获得高质量的结果。

在上述方法中,我们需要预先定义实体的类型,我们还可以从另一角度做命名实体识别,即先找到实体,再识别实体的类型,称为开放域命名实体识别。为什么要做开放域命名实体识别呢?就是因为:实体的类型很多,我们无法穷举全部;实体的类别间有层次关系。因此,我们希望模型能够从输入的文本中识别所包含的全部实体,并自动生成实体的类别标签。
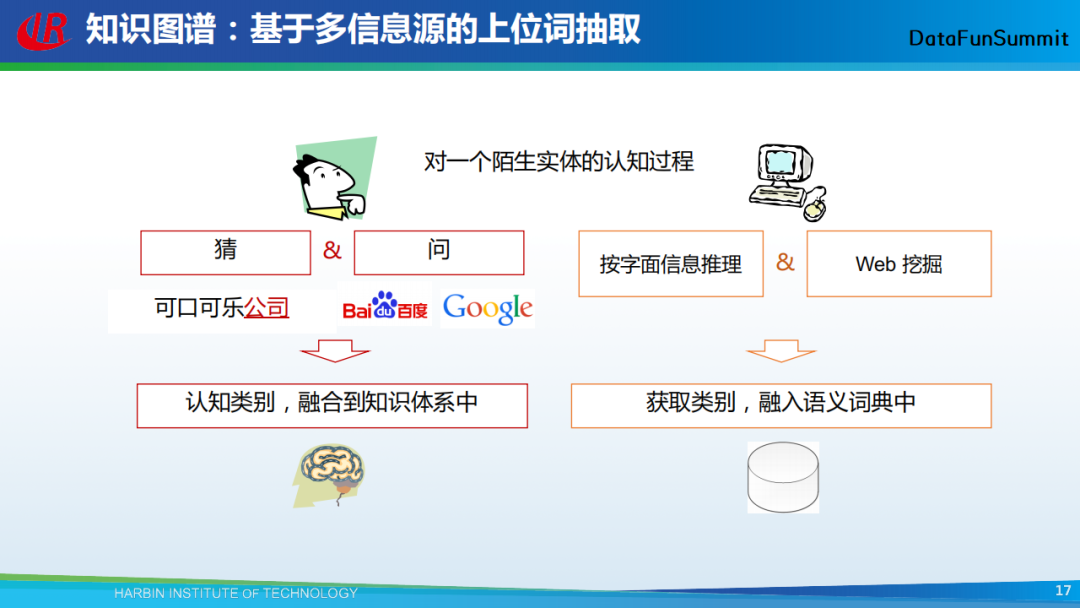
我在这里介绍一种基于多信息源的实体类型(上位词)抽取方法。模拟一个人对一个陌生实体的认知过程:首先将该实体输入搜索引擎,发现与它共现的词语,这个共现的词语很可能代表实体的类别;第二种方法是通过词典去查这个实体的类型;第三种方法是通过核心词来识别。例如,对于“可口可乐公司”这个实体词,它的核心词是“公司”,故我们可通过该核心词,识别“可口可乐公司”这个实体词的类型是“公司”。
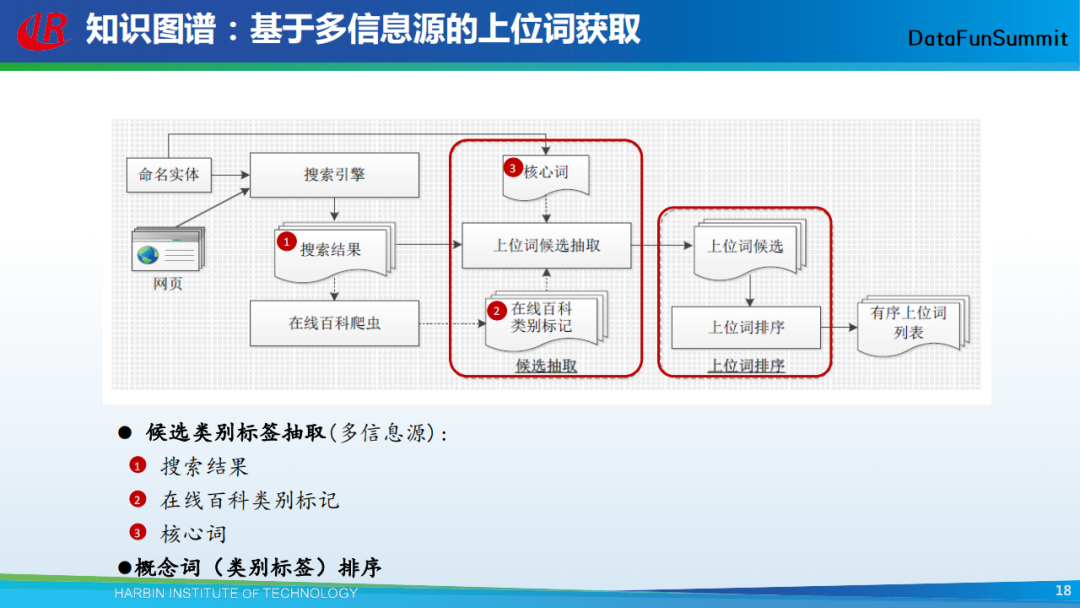
据此,我们提出了基于多信息源的上位词获取方法,其主要包含两个步骤:
从多个信息源中去获取实体的候选类别标签,信息源包括:搜索结果、在线百科类别标记、核心词;
然后通过排序方法将这些候选类别标签进行排序。这里的排序方法往往是一些启发式规则,例如,某个实体是从多个信息源中提取到的,我们就认为它是一个正确的类别标签。
基于这种方法,我们可依次得到训练数据中的正例与反例。
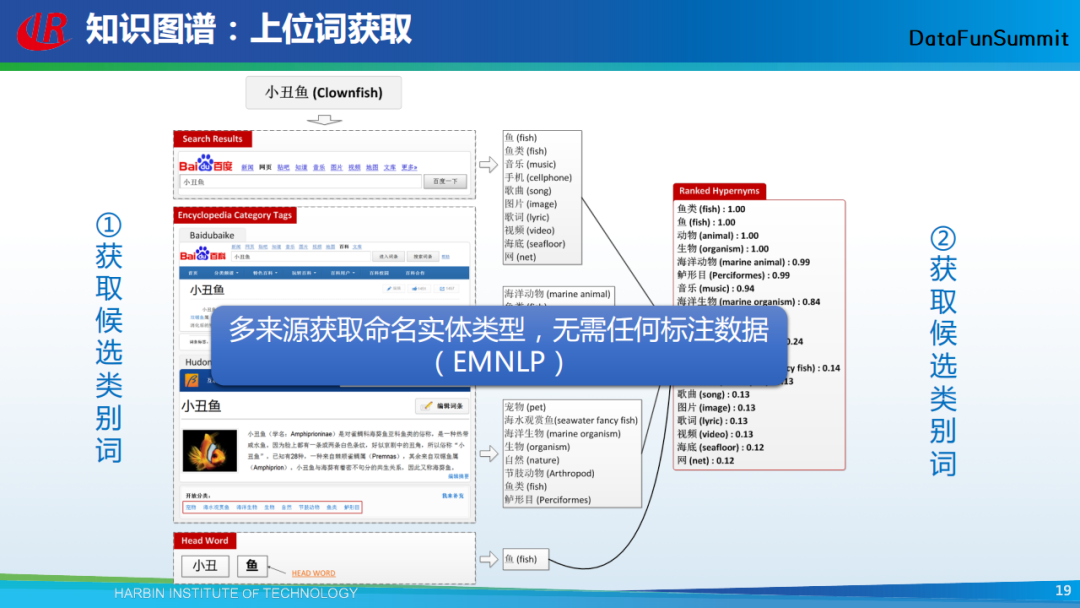
以上通过一个例子展示了通过上述方法得到的实验结果。以“小丑鱼”为例,可以从多个数据源中得到它的类别标签,然后通过启发式的规则对这些标签进行排序。最终可以看到,排在前面的标签即为小丑鱼的真正上位词。这种方法的好处是:可以从多数据源中获取命名实体的类别标签而无需任何标注数据。
03
关系的自动识别
接下来和大家简要分享如何来识别实体之间的关系。
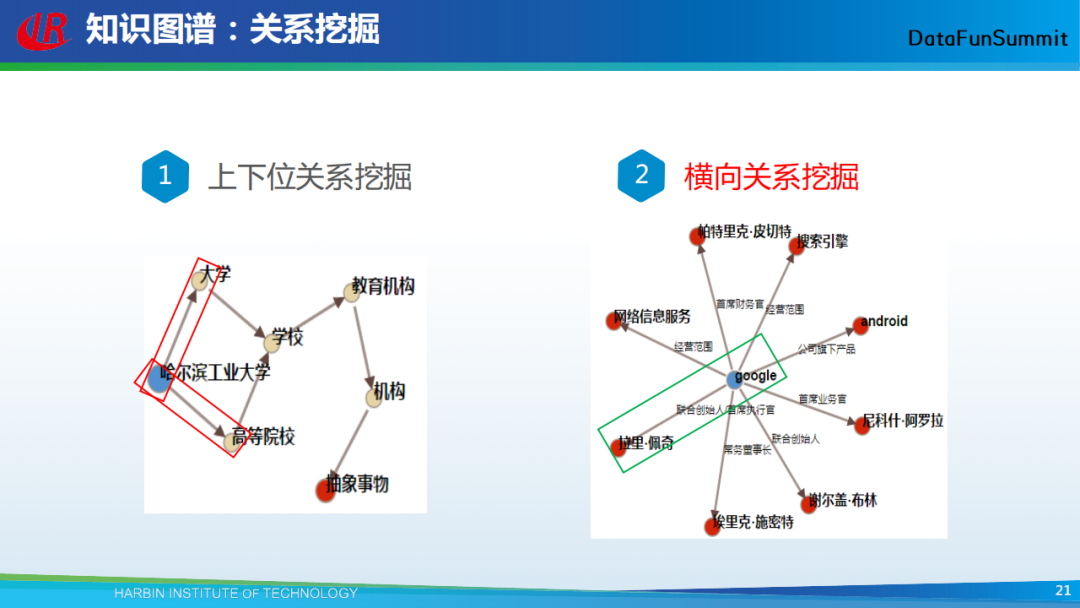
知识图谱中的关系主要包括两类:一类是上下位关系,一类是横向关系。前者指的是实体与其概念词,以及概念词和其上位概念词之间的联系;后者指的是实体间的关系。对于上下位关系的挖掘主要包括两种方案:一种是通过训练具有潜在上下位关系的词向量来判断它们之间的语义关系;另外一种是直接将实体间的上下位关系当成是横向关系来看待。在今天的报告中,我将主要给大家分享实体之间横向关系的挖掘。
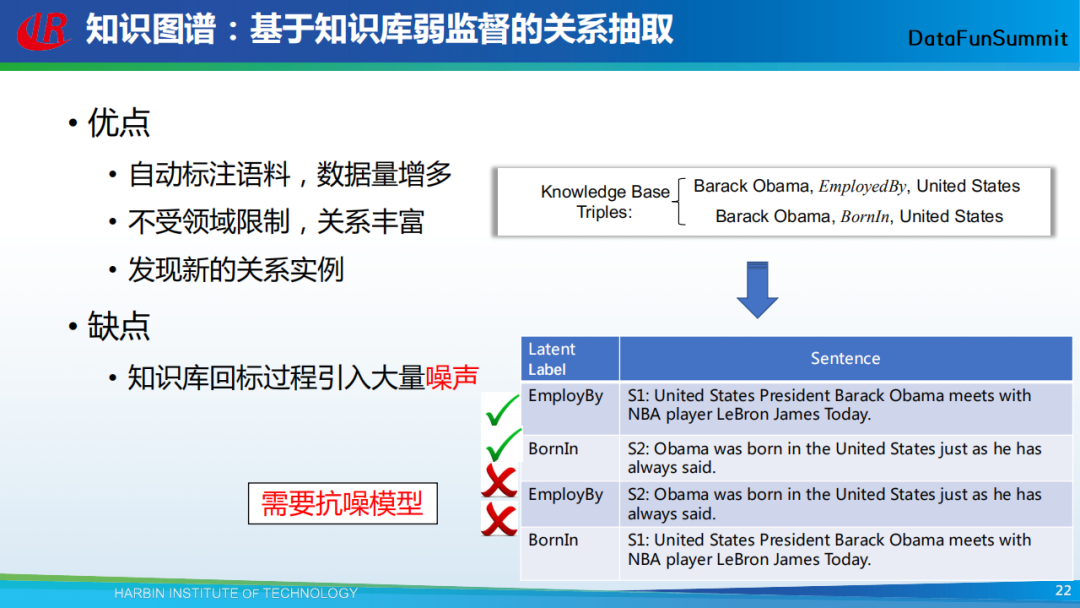
在知识图谱中,实体关系的类型非常丰富。基于弱监督的方案是关系抽取中一类重要的方法,该方法首先从知识库中抽取一系列的三元组,然后利用它们去回标文本,这样就可以得到大量不受领域限制的训练数据。总的来说,这种回标方法的好处主要有:自动标注语料,数据量多;不受领域限制,关系丰富;可以发现新的关系实例。同时缺点也很明显,即回标过程会引入大量噪声。如在上图示例中,表格中的前两个回标结果是正确的,后两个回标结果就是错误的。所以,我们需要抗噪模型。
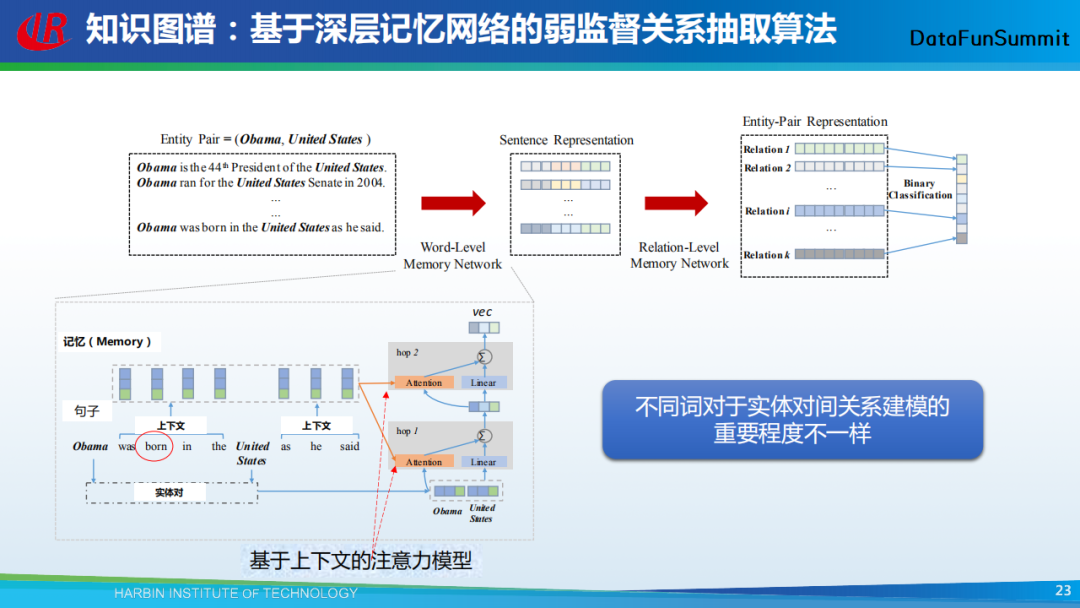
这里我们介绍一个自己的工作,即一种基于深层记忆网络的弱监督关系抽取算法。该方法包括两个层次,第一层为单词级别的记忆网络(word-level memory network),用于将一个句子编码为一个向量;第二层为关系级别的记忆网络(relation-level memory network),用于给句子进行分类,即判断该句子是否包含了指定类型的关系。在单词级别的记忆网络中,我们发现不同的词对于实体对间关系建模的重要程度不一样。例如,在描述出生关系时,born这个单词就很重要。因此,我们引入注意力机制来刻画上下文中不同单词对于挖掘目标实体对间关系的重要程度。
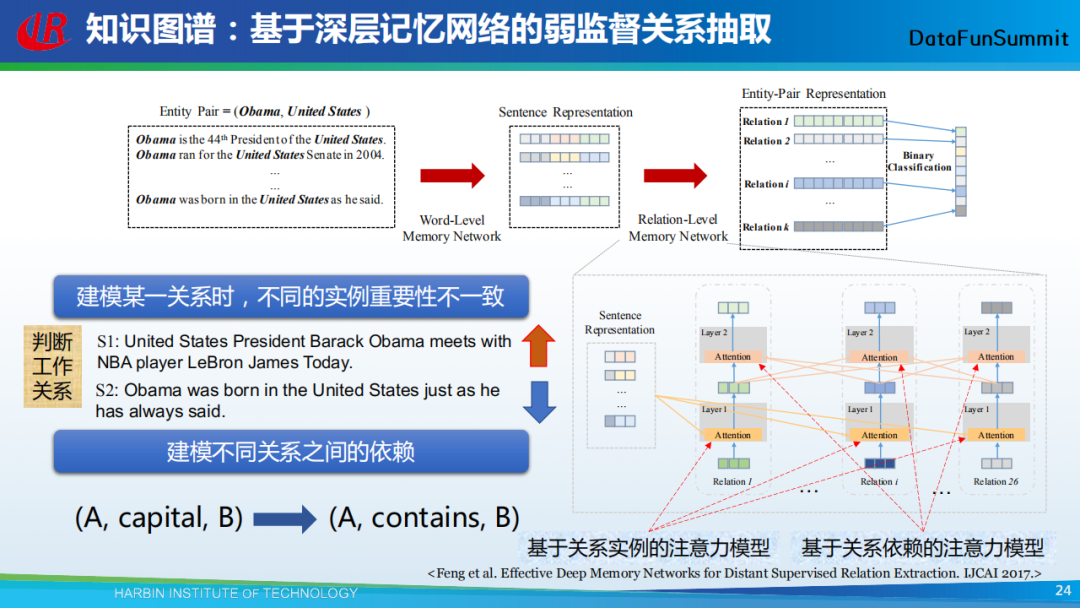
第二层我们要做的是给句子进行分类,如上图所示。左边为输入的句子表示,在对句子进行关系分类时,我们观察到两种现象:
建模某一个关系时,不同句子实例的重要性不一致。例如上图示例,在判断工作关系时,第一个句子的重要性要优于第二个句子;
建模不同关系之间的依赖。例如上图示例,A是B的首都,即(A,capital,B),那么隐含着A包含B,即(A,contains,B)。
据此,我们提出了两种注意力机制,第一种是基于关系实例的注意力机制,其目的在于刻画不同句子对于指定关系的重要程度;第二种是基于关系依赖的注意力机制,其目的在于刻画不同关系之间的依赖性。
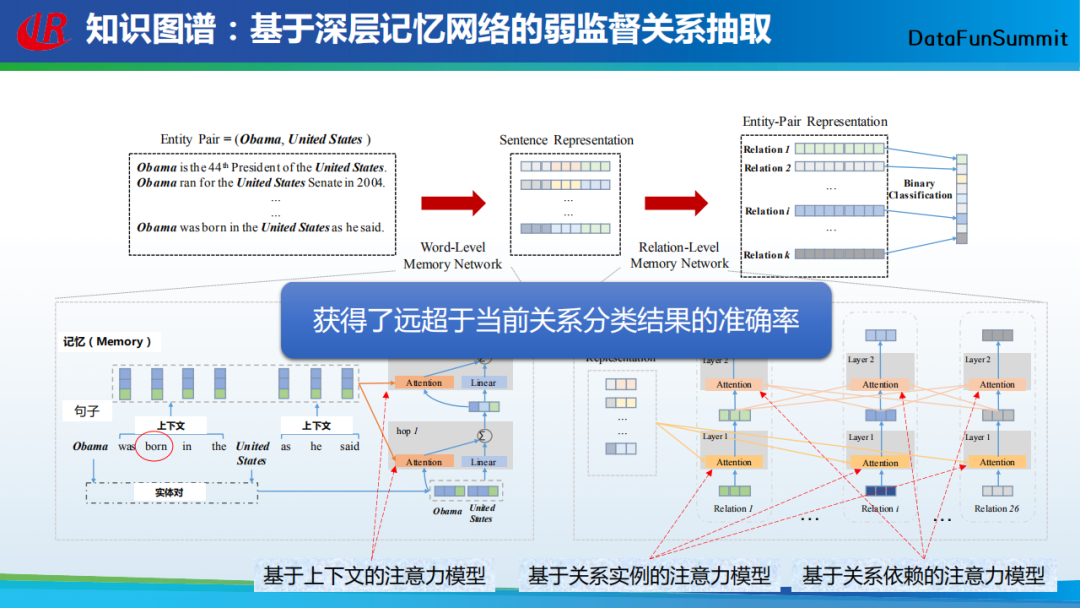
将以上提到的单词级别的记忆网络(word-level memory network)与关系级别的记忆网络(relation-levelmemory network)结合在一起,就形成了基于深层记忆网络的弱监督关系抽取模型。实验结果表明,该模型获得了远超于当前分类结果的准确率(关于实验的细节部分,我在这里就不再赘述)。
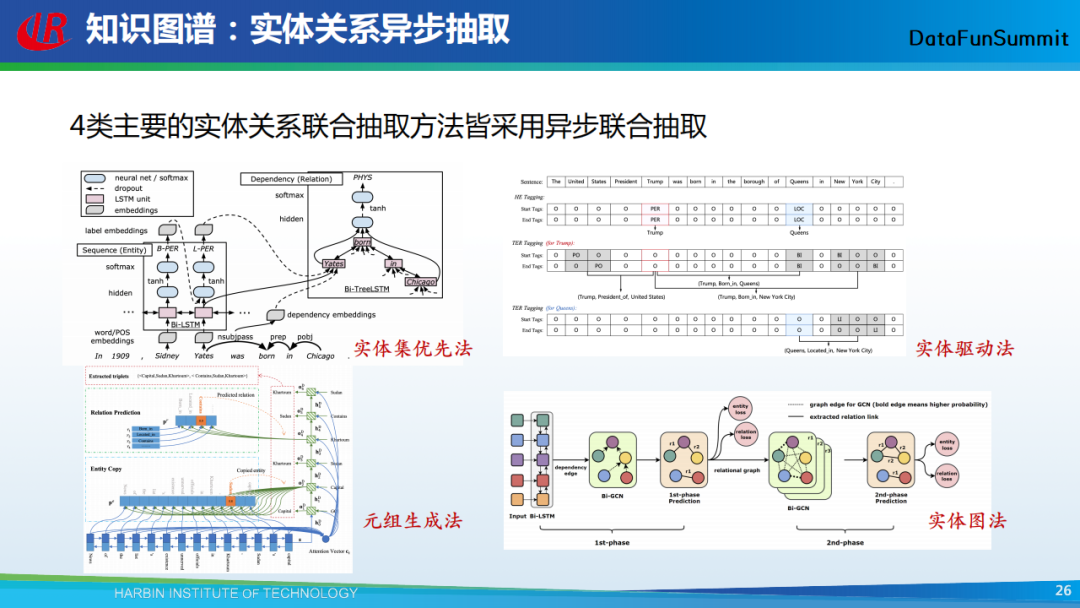
在知识图谱构建的过程中,主要就是挖掘实体及其关系,然后将它们组织成关系三元组。之前给大家讲的方法均采用的是异步抽取的方法,即将实体关系的抽取分为两个阶段,首先抽取实体,然后抽取实体间的关系,这也是当前的主流抽取方法,如上图中提到的实体集优法、实体驱动法、元组生成法和实体图法。
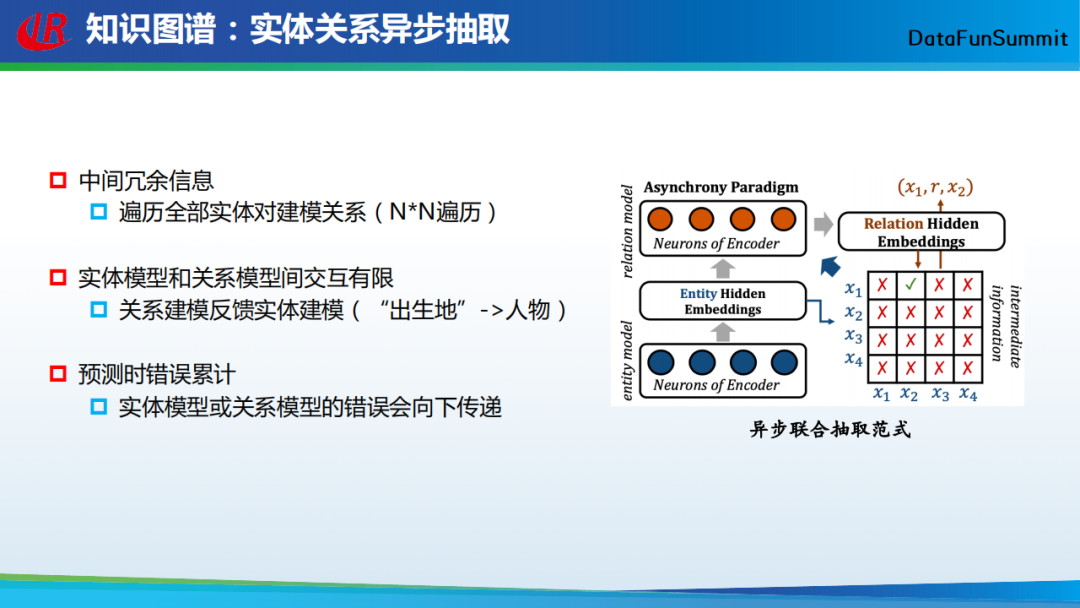
这种异步的方法主要存在以下三方面的问题:
中间冗余信息。需要遍历全部实体对建模关系(N*N遍历);
实体模型和关系模型交互有限。事实上关系建模的结果可以反馈给实体建模(“出生地”关系的头实体应为“人物“类型的实体);
预测时错误累计。由于异步抽取采用串联的方式,因此实体模型或关系模型的错误会向下传递。

基于以上问题,我们提出一种同步联合抽取模型,将实体与关系一起抽取,其主要包含两个动机。动机1:关系扮演重要的角色,不应只作为输出层的预测类别标签,而应将其嵌入至抽取的过程。因此,我们可采用阅读理解的框架,将关系作为输入,在句子中查询是否有满足该关系的头实体和尾实体;动机2:重叠元组的关系类别通常是不同的。重叠元组是关系抽取中的一类重要问题。例如,“奥巴马”这个实体可以同时出现在(美国,总统,奥巴马)与(奥巴马,出生于,檀香山市)这两个三元组中。我们发现:关系可以解码大多数重叠三元组,以关系而非实体为驱动可以应对重叠元组的问题。相应地,通过逐次输入关系描述,模型每次仅关注一种关系的头尾实体的抽取。

基于上述动机,我们提出了一种实体关系联合抽取模型。在模型左边,针对输入的句子,通过模板可自动生成关系的描述,该描述可作为问题,输入句子则视为篇章,抽取到的答案即为满足该关系的头尾实体。这个架构共分为四个子任务,分别为:关系类别判定(二分类问题)、命名实体识别(NER)、元组头实体识别、元组尾实体识别。通过以上任务,我们便可得到关系三元组的抽取结果。实验结果表明,我们提出的模型性能超过了目前最新的同步抽取模型(关于实验的细节部分,我在这里就不再赘述)。
04
实体缺失属性的自动补全
以上讲述了关系抽取。在知识图谱中,实体有相应的描述信息,即它的属性。接下来,将给大家简要介绍如何去找实体的属性。
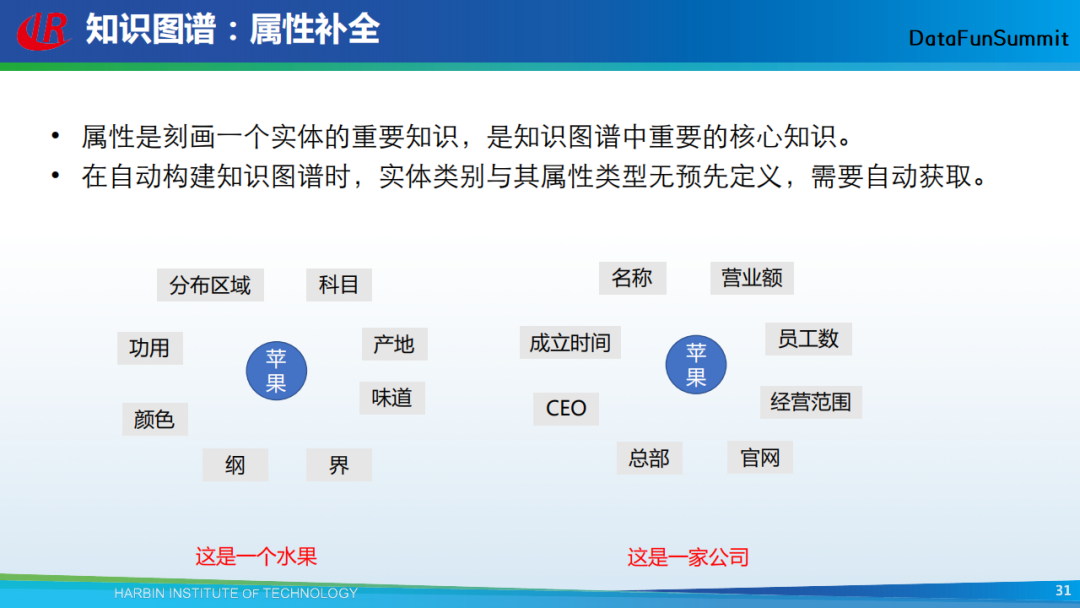
属性是刻画一个实体的重要知识。如上图中的示例(左),通过苹果的属性(如科目、产地、味道等),我们知道这里的苹果是一种水果;在示例(右)中,通过苹果的属性(如名称、成立时间、CEO等),我们知道这里的苹果是一家公司。在自动构建知识图谱时,实体类别与其属性类型无预先定义,需要自动获取。

那么,我们如何来挖掘实体的属性呢?其中一种方案是,我们可以借助已有的词典来帮助我们获得实体的属性。如上图为例,我们的做法是,从知识图谱《大词林》(《大词林》是由我们中心构建的国内规模最大的开放域知识图谱,其中包含了实体、关系以及概念)中随机抽取了687,392个实体,然后在百度百科中进行搜索,我们希望将百科中实体的属性补充到《大词林》相应的实体上去。然而,我们发现:针对《大词林》中的实体,在百度百科中只有395,327个实体具有至少一个属性,292,065个实体没有属性(即属性的覆盖率为57.51%)。产生这一问题的原因其实也很简单,即不同知识图谱中的实体可能是有交叉的,并不一定能完全覆盖。
针对这一问题,我们发现在很多情况下,可以利用实体的上位词进行属性补全。如上图示例,“健胃止痛片”包含在百度百科中,因此我们可以抽取获得它的属性信息(如是否处方药、药品类型、剂型、规格等)作为“祛止痛片”的属性。我们发现这两种止痛片拥有相同的上位词,即它们属于同一个概念,因此自然可以将“健胃止痛片”的属性链接到“祛止痛片”上。如此,我们就产生了一个想法:如果两个实体共享相同的上位词,那么就可以完成相互间的属性推荐。
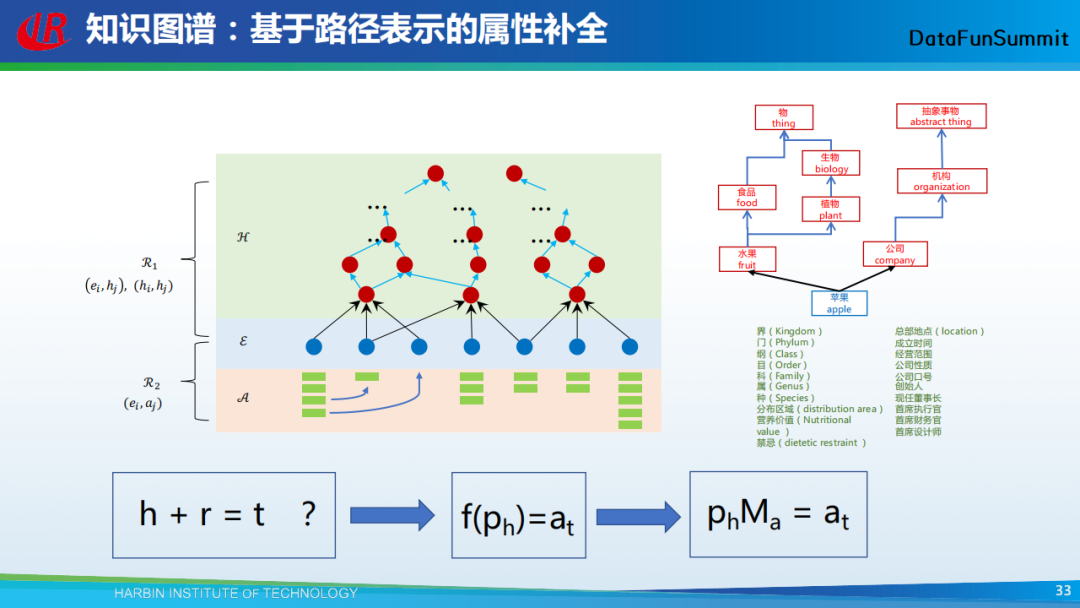
以上为上述方法的示意图。左边部分,底下的绿色矩形代表实体的属性,中间蓝色的圆圈代表实体,它们上面的红色圆圈代表实体的概念,概念之间也具有上下位关系。我们考虑通过TransE的方式(h+r=t)为实体推荐属性,h代表概念路径,r代表实体,t代表属性。然而,在很多情况下,实体是否具有属性与其本身无关,而只与该实体之上的概念有关。例如,苹果具有颜色的属性,这和苹果自身(的标签)无关,而和苹果是一个水果是有关系的。因此,我就将实体去掉了,转而判断概念与属性间的相互关系。
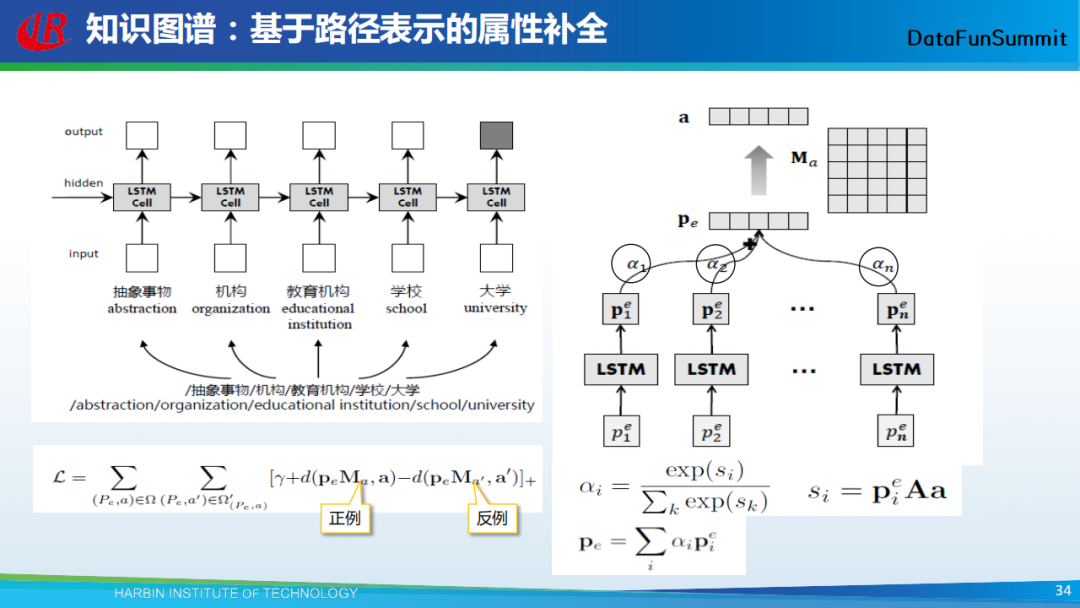
基于上述想法,我们提出了以上处理流程。通过LSTM,我们会为每个概念的路径生成相应的向量表示,我们发现在训练样本中,我们知道某个属性是属于某个实体的,但并不知道其属于这个实体的哪个概念,所有我们采用注意力机制(Attention)来为多条概念路径分配权重,最终形成实体的概念表示。最后通过打分函数完成实体的属性推荐任务。
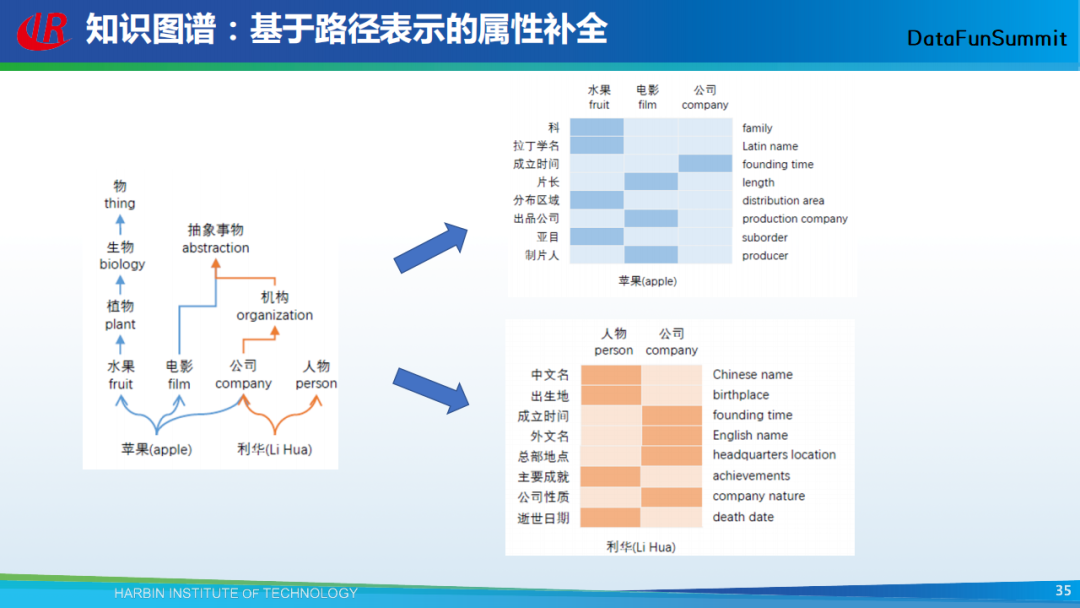
上图为一个具体的例子,我们可以将属性映射到相应的实体所述的概念上。

以上给大家了分享了我们在知识图谱构建中所采用的一些主流方法。接下来,我还想用几页PPT给大家分享我们现在正在做的另外一项工作——条件性知识图谱。在做知识图谱时,我们主要是从文本中来抽取一系列的三元组,它们也被称为事实知识。然而这些事实知识并不总是成立,例如在上图中,我们从文本中抽取得到(奥巴马,总统,美国),但是这个事实目前是不成立的。据此,我们希望抽取到的三元组能够包含两种知识,一种是事实知识,一种是条件知识(通过条件来限定事实知识)。在以上图例中,对应的条件知识即为(第五任总统,任职,2007-2012)。

再次以上图为例,我们可以从这段文本中抽取得到事实三元组和条件三元组,将它们组合后可形成条件知识图谱。
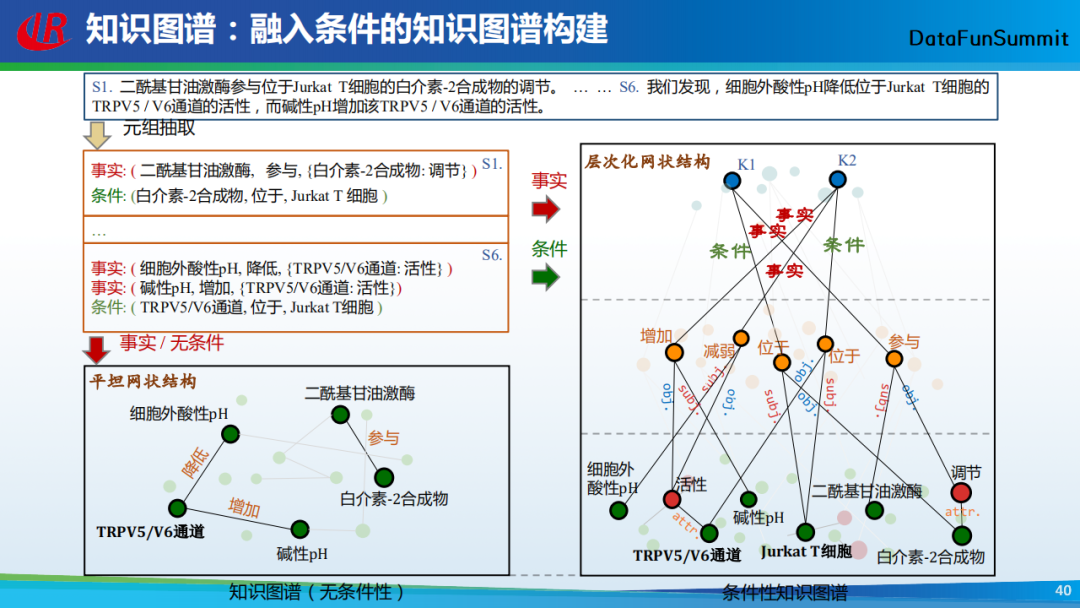
上图底部(左)是传统的知识图谱(无条件性),上图底部(右)是条件性知识图谱,它主要包括三层:最底下一层是实体属性层,表现了所有实体和属性的关联;中间是关系层,这里我们将关系也作为一个节点;最上面的是知识层,由条件和事实三元组构成,表明这些事实是在某些条件的约束下才成立。
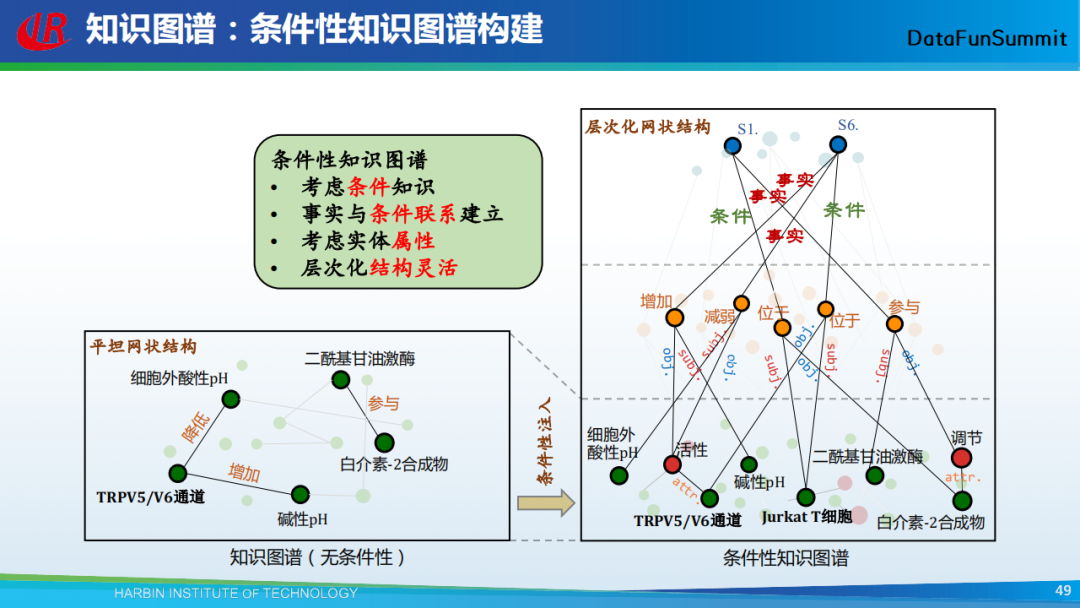
条件知识图谱的优点在于:
考虑条件知识;
事实与条件相互关联;
层次化结构灵活。

以上给出我们提出的动态多输入多输出模型,它将从文本中抽取事实和/或条件三元组的任务建模为一个序列标注问题。即给定一个句子,其中的每个词语将被分配一个标签,该标签表示它在三元组中的角色,即是否为事实/条件三元组的头实体/尾实体等。
今天的分享就到这里,谢谢大家。
在文末分享、点赞、在看,给个3连击呗~
分享嘉宾:

专知便捷查看
便捷下载,请关注专知公众号(点击上方蓝色专知关注)
后台回复“知识图谱” 就可以获取《知识图谱专知资料合集》专知下载链接







