【论文解读】基于图Transformer从知识图谱中生成文本

论文Text Generation from Knowledge Graphs with Graph Transformers发表于2019年自然语言处理顶级会议之一NAACL,本文将对其进行解读,这是原文链接(https://arxiv.org/pdf/1904.02342.pdf)。
背景
生成表达复杂含义的多句文本需要结构化的表征作为输入,本文使用知识图谱作为输入的表征,研究一个端到端的graph-to-text生成系统,并将其应用到科技类文本写作领域。作者使用一个科技类文章数据集的摘要部分,使用一个IE来为每个摘要提取信息,再将其重构成知识图谱的形式。作者通过实验表明,将IE抽取到知识用图来表示会比直接使用实体有更好的生成效果。
graph-to-text的一个重要任务是从 Abstract Meaning Representation (AMR) graph生成内容,其中图的编码方法主要有graph convolution encoder,graph attention encoder,graph LSTM,本文的模型是graph attention encoder的一个延伸。
数据集
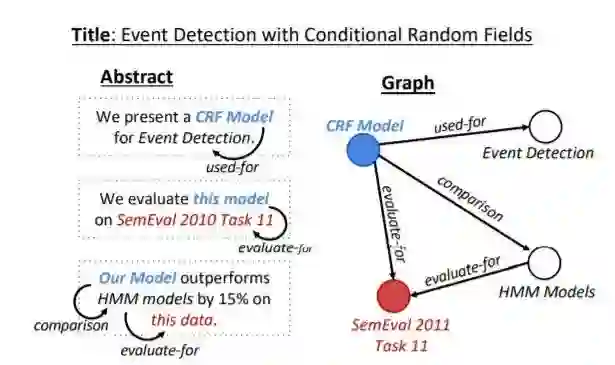
作者构建了一个Abstract GENeration Dataset(AGENDA),该数据包含40k个AI会议的论文标题和摘要。对于数据集中的每篇摘要,首先使用SciIE来获取摘要中的命名实体及实体之间的关系(Compare, Used-for, Feature-of, Hyponymof, Evaluate-for, and Conjunction),随后将得到的这些组织成无连接带标签图的形式。
模型
GraphWriter模型总览
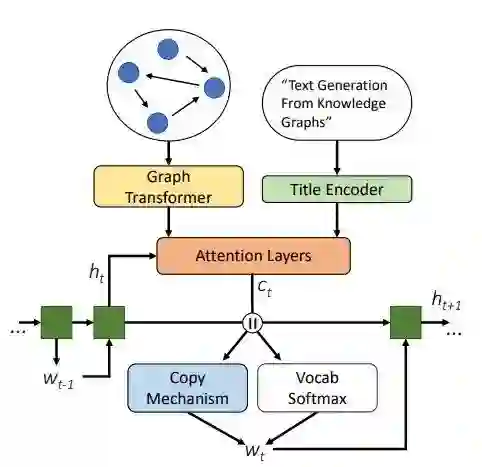
编码器
构建图
将之前数据集中的无连接带标签图,转化为有连接无标签图,具体做法为:原图中的每个表示关系的边用两个节点替代,一个表示正向的关系,一个表示反向的关系;增加一个与所有实体节点连接全局向量节点,该向量将会被用来作为解码器的初始输入。下图中 表示实体节点, 表示关系, 表示全局向量节点
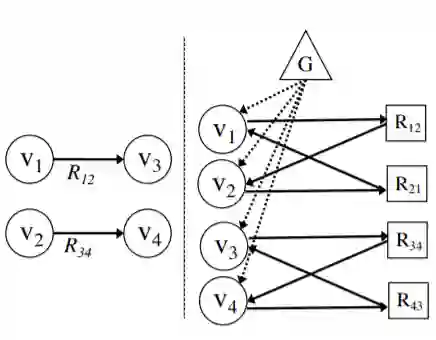
最终得到的有连接,无标签图为G=(V,E),其中V表示实体/关系/全局向量节点,E表示连接矩阵(注意这里的G和V区别上述图中的G和v)。
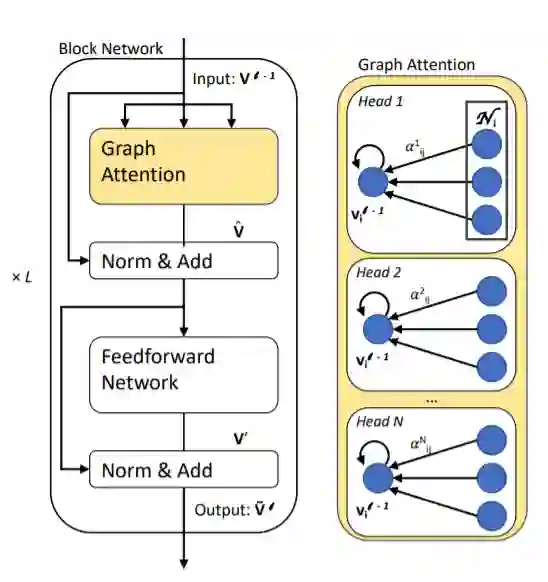
Graph Transformer
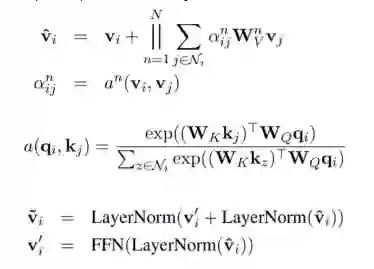
解码器
在每个时间步t使用隐藏状态 来计算图和标题的上下文向量 和 ,其中 通过 使用多头注意力得到,
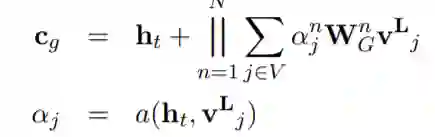
也通过类似的方式得到,最终的上下文向量是两者的叠加 。随后使用类似pointer-network的方法来生成一个新词或复制一个词,
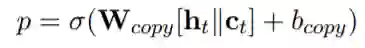
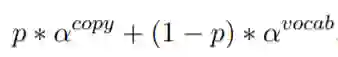
实验
实验包含自动和人工评估,在自动评估中,GraphWriter代表本篇文章的模型,GAT中将Graph Transformer encoder使用一个Graph Attention Network替换,Entity Writer仅使用到了实体和标题没有图的关系信息,Rewriter仅仅使用了文章的标题,

从上图可以看到,使用标题,实体,关系的模型(GraphWriter和GAT)的表现要显著好于使用更少信息的模型。在人工评估中,使用Best-Worst Scaling,

[1] Koncel-Kedziorski R, Bekal D, Luan Y, et al. Text generation from knowledge graphs with graph transformers[J]. arXiv preprint arXiv:1904.02342, 2019.

推荐阅读
征稿启示| 200元稿费+5000DBC(价值20个小时GPU算力)
完结撒花!李宏毅老师深度学习与人类语言处理课程视频及课件(附下载)
模型压缩实践系列之——bert-of-theseus,一个非常亲民的bert压缩方法
文本自动摘要任务的“不完全”心得总结番外篇——submodular函数优化
斯坦福大学NLP组Python深度学习自然语言处理工具Stanza试用
关于AINLP
AINLP 是一个有趣有AI的自然语言处理社区,专注于 AI、NLP、机器学习、深度学习、推荐算法等相关技术的分享,主题包括文本摘要、智能问答、聊天机器人、机器翻译、自动生成、知识图谱、预训练模型、推荐系统、计算广告、招聘信息、求职经验分享等,欢迎关注!加技术交流群请添加AINLPer(id:ainlper),备注工作/研究方向+加群目的。

阅读至此了,分享、点赞、在看三选一吧🙏





