刷新CoQA榜单记录:基于对抗训练和知识蒸馏的机器阅读理解方案解析
机器之心发布
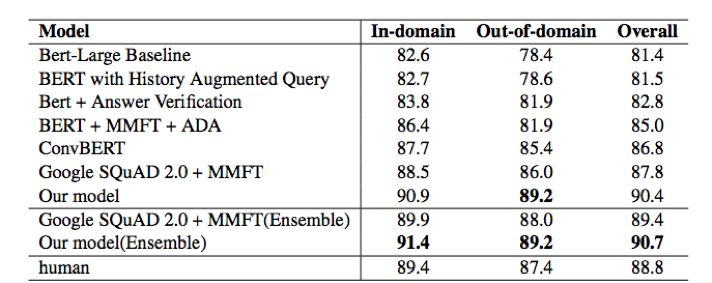
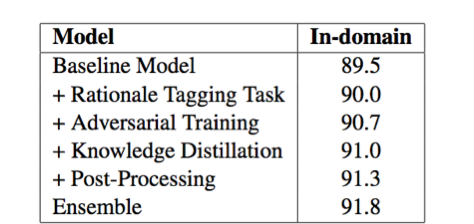
近日,在由斯坦福大学发起的对话式问答挑战赛 CoQA (Conversational Question Answering Challenge )中,追一科技 AI Lab 团队成为榜单第一 [1] ,刷新了之前微软等团队创造的 CoQA 纪录。值得注意的是,团队提交的技术方案中,单模型的各项指标表现首次全面超越人类。
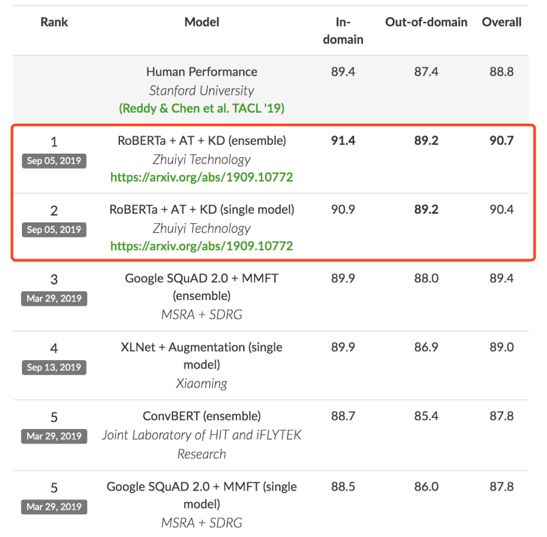
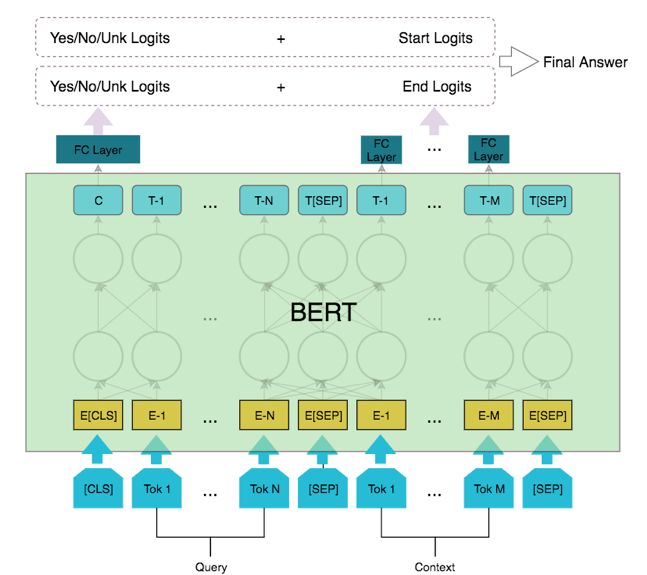
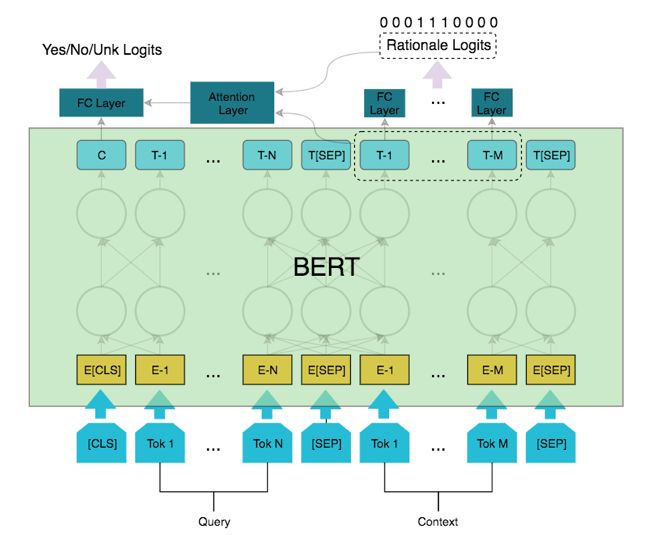
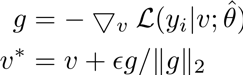

登录查看更多
相关内容
专知会员服务
27+阅读 · 2020年4月5日
专知会员服务
14+阅读 · 2019年11月11日
Arxiv
15+阅读 · 2018年10月11日
Arxiv
4+阅读 · 2018年4月23日


相关VIP内容
专知会员服务
27+阅读 · 2020年4月5日
专知会员服务
14+阅读 · 2019年11月11日
相关资讯
相关论文
Arxiv
15+阅读 · 2018年10月11日
Arxiv
4+阅读 · 2018年4月23日